






再来是千年的千年
不变是眷恋的眷恋
飞越宇宙无极限
我们永不说再见
——超兽武装
完整代码见:SnowLegend-star/6.s081 at lazy (github.com)
Eliminate allocation from sbrk() (easy)
顾名思义,就是去掉sbrk()中调用growproc()的部分。1s完事儿。
Lazy allocation (moderate)
part02是为了修复part01挖的那个坑。代码实现在课上也是讲过的,这里粗略看一遍hints就行:
1、你可以在usertrap()中查看r_scause()的返回值是否为13或15来判断该错误是否为页面错误

老实说这个hint1真是说晚了,应该在page table那个lab就提出的。到这我才真正理解scause、spec、stval那几个寄存器真正的用法。可以看到scause值为12、13、15时都是页表相关的问题。
2、stval寄存器中保存了造成页面错误的虚拟地址,你可以通过r_stval()读取
3、参考***vm.c***中的uvmalloc()中的代码,那是一个sbrk()通过growproc()调用的函数。你将需要对kalloc()和mappages()进行调用
模仿uvmalloc()在usertrap中写一个分配页表的函数体就行。
4、使用PGROUNDDOWN(va)将出错的虚拟地址向下舍入到页面边界
这里有个坑,就是PGROUNDDOWN(va)这句的位置是有讲究的。但是part02检测不出来,part02只是测试了是否成功分配页表,而没有测试va的位置合法性。我去,原来没问题,是我冤枉了这句代码。

5、当前uvmunmap()会导致系统panic崩溃;请修改程序保证正常运行
6、如果内核崩溃,请在***kernel/kernel.asm***中查看sepc
7、使用pgtbl lab的vmprint函数打印页表的内容
这个hint放在part03比较好,由于part02用不到vmprint(),搞得我咋part03都忘记这个hint了。
8、如果您看到错误“incomplete type proc”,请include“spinlock.h”然后是“proc.h”
这个hint也应该放在part03。
growproc()修改如下
int
growproc(int n)
{
uint sz;
struct proc *p = myproc();
sz = p->sz;
// if(n > 0){
// if((sz = uvmalloc(p->pagetable, sz, sz + n)) == 0) {
// return -1;
// }
// } else if(n < 0){
// sz = uvmdealloc(p->pagetable, sz, sz + n);
// }
p->sz = sz + n;
if(n > 0){
if((sz = uvmalloc(p->pagetable, sz, sz + n)) == 0) {
return -1;
}
} else if(n < 0){
sz = uvmdealloc(p->pagetable, sz, sz + n);
}
return 0;
}Lazytests and Usertests (moderate)
这个part03我觉得可以算是半步hard难度了,要修改的小地方太多了。而且这部分给的几个hints有点隐晦,让人有点摸不着头脑。还是从分析hints着手:
1、Handle negative sbrk() arguments.
这个部分我在part02就已想实现了,但是感觉在usertrap内部实现不了,就先搁置一旁。想不到part03又要实现。抱着试一试的心态我把growproc()内部的uvmdealloc()搬过来试了下,还真的是这么实现的。
2、Kill a process if it page-faults on a virtual memory address higher than any allocated with sbrk().
这句话还是比较容易理解的,问题是在哪里实现呢?我想了许久还是没什么头绪,遂依然在usertrap内部添加判断,也可行。
3、Handle the parent-to-child memory copy in fork() correctly.
这句就显得十分晦涩了,乍一看还以为是要求我们在fork()进行适当的修改。我去翻了下《CSAPP》,看到里面说使用“写时复制”后,父进程和子进程都应该被标记为只读。如果真是这样也太麻烦了,那part03绝对是hard难度。一阵挠头发现仍然没有思路后,就先跳过这句了。我想着既然有这个hint,那测试点应该会涉及到这句话的实现测试。先把大体框架完成进行测试再说。
4、Handle the case in which a process passes a valid address from sbrk() to a system call such as read or write, but the memory for that address has not yet been allocated.
这个hint的要求一目了然,不过我开始也是不知道从哪里着手。权且跳过。
5、Handle out-of-memory correctly: if kalloc() fails in the page fault handler, kill the current process.
连着被前面的hints折磨,终于是看到了个通俗易懂又易于实现的hint。我兴高采烈地掉进了一个小坑:
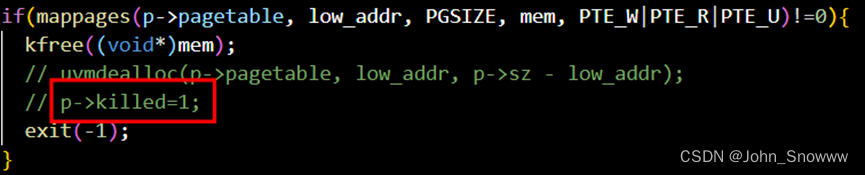
usertrap内部的我都是用p->killed=1来终止进程的,自以为这种写法相当的地道。但在修改vm.c的walk()时发现貌似不能用p->killed=1这个操作来终止进程,于是灵机一动想到终止进程不是可以用exit(-1)吗?后来我还测试了下能不能在usertrap中把p->killed=1和exit(-1)互换。
可恶的是lazytests貌似不能检查这两者的差异,搞得我还以为上述两种方法是等价的。为后面usertests的报错埋下伏笔。
6、Handle faults on the invalid page below the user stack.
这句话也有点语焉不详,后来才发现就是检查va是不是溢出到了guard page。和hint2差不多,一个是判断是否超出上界,一个则是防止va溢出到了下界。
OK,把hints过完了一遍可以开始测试了。第一个报错如下:
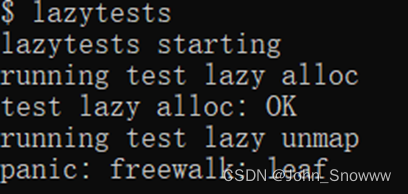
在前面搞多了注释“panic:xxx”的操作之后,我下意识地就是来一手掩耳盗铃,直接把上述panic给注释了,发现没有效果才开始认真思考到底是什么原因。
查看出错的freewalk()发现是uvmunmap()没有彻底删除叶子表项导致这个painc。这时候就得用vmprint()检查一番了,有一说一官方不提供vmprint()我不认可。输出结果如下:
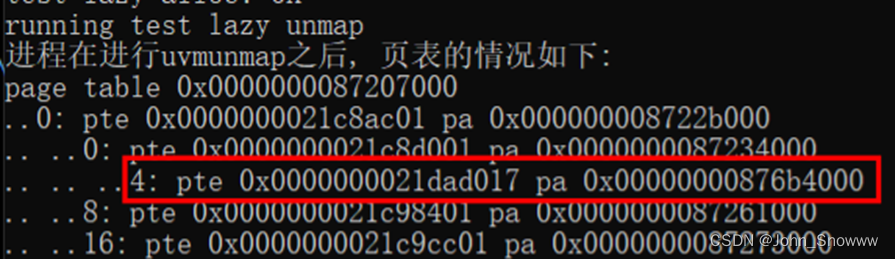
可以发现确实是有个叶子页表项没完全删除,我自己分析uvmunmap()和walk()半天不见思路,又问了下GPT是什么情况。都没得到想要的原因。在发现pagetable只有这一个异常的叶子pte后,我决定直接在freewalk()内部把这个pte删去。果然可行。
解决这个小问题后,我突然对如何解决hint3来了思路。遂在uvmcopy()来了收掩耳盗铃,注释掉了两句panic。因为父进程用sbrk()申请了堆空间之后,如果不立即使用这部分新空间,“写时分配”机制会维持PTE_V=0的状态。这时候调用fork()来生成子进程,子进程在复制父进程的空间layout就会遇到这部分父进程申请的新空间。所以得忽略PTE_V=0的判别,仍然将新空间复制到子进程的空间中。
完成上述步骤就可以通过lazytests了,接下来开始攻关usertests。遇到的第一个问题就给我难住了:

为了探究到底是什么原因导致的报错,我把sbrkmuch()仔细看了几遍。发现这个函数内部倒是没报错,是内核出了问题。而且有些测试虽然OK了,也是有类似的usertrap报错:
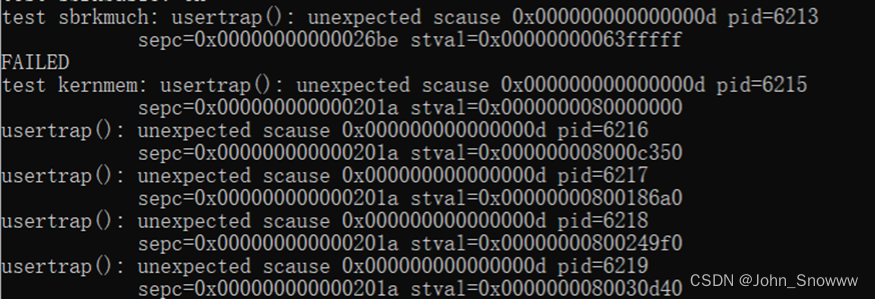
在发现scause无一例外都是d之后,我尝试了把scause=13也加入usertrap的页表分配中,问题由此得以解决。
else if(r_scause()==15 || r_scause()==13)接下来就是处理最麻烦的部分了,也就是hint4:处理这种情形:进程从sbrk()向系统调用(如read或write)传递有效地址,但尚未分配该地址的内存。
 我最初的想法是在scause==8的那部分也加入页表分配的内容,发现这样会导致重映射。
我最初的想法是在scause==8的那部分也加入页表分配的内容,发现这样会导致重映射。
![]()
然后我又想可不可以直接在sys_write()和sys_read()添加页表分配。事实证明这种方法是可行的,但是如果测试的系统调用过多,岂不是要重写每个系统调用函数,治标不治本。由于午觉没睡好有点犯困了,就去网上找了下简便方法。
处理第4种情况,即系统调用(比如write)传入的虚拟地址对应的内存并没有被分配。
首先搞清楚函数执行流程,在调用write后系统trap到内核态,执行copyin来把用户程序va处的内容复制到内核空间,此时若va处并未分配内存,walkaddr会返回0导致系统调用失败。因此我们要做的就是在walkaddr中分配内存。
处理进程将有效地址从sbrk()传递给系统调用(例如读取或写入),但尚未分配该地址的内存的情况
由于write是系统调用,在内核中访问用户地址空间出现异常不会进入usertrap()函数,内核访问用户地址空间首先要找到和虚拟地址对应的物理地址,walkaddr完成这个工作,当pte不存在或者pte无效,返回0 但是这种情况在lazy allocation中是允许的
所以针对这个问题需要在walkaddr()函数进行和usertrap中相同的操作,为访问地址分配内存并映射到页表
上面两段话可谓是醍醐灌顶,可以从根源上解决类似的问题。我们在walkaddr()内部进行和usertrap相似的操作,区别是在walkaddr()中我们操作的对象是传入的va,而非usertrap中的stval。
最后一个小问题是边界判断。

这里如果不加等号就会报下列错误。这个报错和问题代码看起来可谓是毫无关联,让我一番好找。
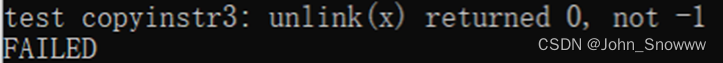
修改后的walkaddr()如下
uint64
walkaddr(pagetable_t pagetable, uint64 va)
{
pte_t *pte;
uint64 pa;
if(va >= MAXVA)
return 0;
pte = walk(pagetable, va, 0);
if(pte == 0 || (*pte & PTE_V)==0 ){
struct proc *p=myproc();
//由于write是系统调用,在内核中访问用户地址空间出现异常不会进入usertrap()函数
uint64 mem;
if(va >= p->sz) //这里如果用low_addr > maxva就无法通过unmap测试
return 0;
if(va < p->trapframe->sp ) //即出错的地址位于guard page
return 0;
mem=(uint64)kalloc();
if(mem==0){
return 0;
}
else{
va = PGROUNDUP(va); //加不加都行
memset((void *)mem, 0, PGSIZE);
if(mappages(p->pagetable, va, PGSIZE, mem, PTE_W|PTE_R|PTE_U)!=0){
kfree((void*)mem);
return 0;
}
}
}
if((*pte & PTE_U) == 0)
return 0;
pa = PTE2PA(*pte);
return pa;
}修改后的usertrap()如下
else if(r_scause()==15 || r_scause()==13){ //如果是出现缺页错误
uint64 mem;
// uint64 low_addr=PGROUNDDOWN(r_stval());//这里提早向下舍入low_addr是不是有问题啊?
uint64 low_addr=r_stval();
// printf("page fault %p\n", r_stval());
if(low_addr >= p->sz) //这里如果用low_addr > maxva就无法通过unmap测试
// p->killed=1 ;
exit(-1);
if(low_addr < p->trapframe->sp ) //即出错的地址位于guard page
// p->killed=1;
exit(-1);
mem=(uint64)kalloc();
if(mem==0){
// uvmdealloc(p->pagetable, low_addr, p->sz - low_addr);
//用killed参数来杀死进程,而不是直接return 用kill的方式会导致 test copyinstr3: unlink(x) returned 0, not -1
// p->killed=1;
exit(-1); //用exit(-1)也可以,一步到位
}
else{
memset((void *)mem, 0, PGSIZE);
low_addr=PGROUNDDOWN(low_addr);
if(mappages(p->pagetable, low_addr, PGSIZE, mem, PTE_W|PTE_R|PTE_U)!=0){
kfree((void*)mem);
// uvmdealloc(p->pagetable, low_addr, p->sz - low_addr);
// p->killed=1;
exit(-1);
}
}
}














 1087
1087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









