







MapReduce
Lab 地址
论文地址
https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/mapreduce-osdi04.pdf
工作原理
简单来讲,MapReduce是一种分布式框架,可以用来处理大规模数据。该框架抽象了两个接口,分别是Map和Reduce函数:

凡是符合这个模式的算法都可以使用该框架来实现并行化,执行流程如下图所示。
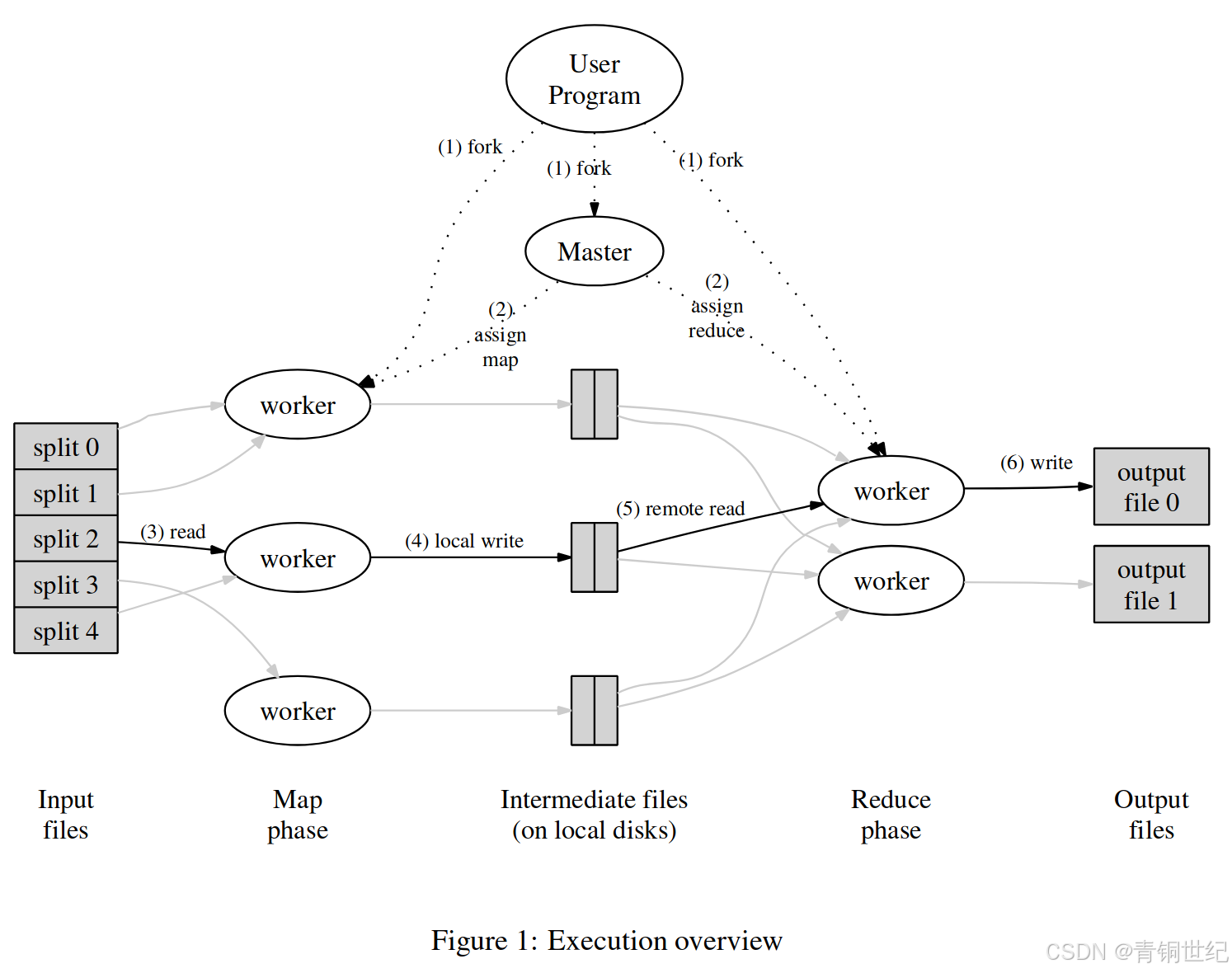
整个框架分为Master和Worker,Master负责分配map和reduce任务,Worker负责向Master申请任务并执行。执行流程如下:
Map阶段:
- 输入是大文件分割后的一组小文件,通常大小为16~64MB。
- Worker向Master申请任务,假设得到map任务in0。
- Worker开始执行map任务,将文件名和文件内容作为参数传入map函数中,得到kv list.
- 最后Worker将kv list分割成reduceNum份(超参数),要求使得具有相同key的kv对在一份中。可以通过hash值%reduceNum实现分割,然后输出到文件中,下图的0-*
Reduce阶段:
- 输入当前reduce的序号id,从map阶段的输出中选出*-id的文件,也就是将hash值%reduceNum值相同的kv对取出,这样可以保证具有相同key的kv对只用一次处理。
- 将所有的kv对根据键值排序,使得相同key的kv对能够连续排列,方便合并。
- 之后合并相同key的kv对,然后将每个key和其对应的value list输入reduce函数,得到合并的结果,再将其输出到文件中。
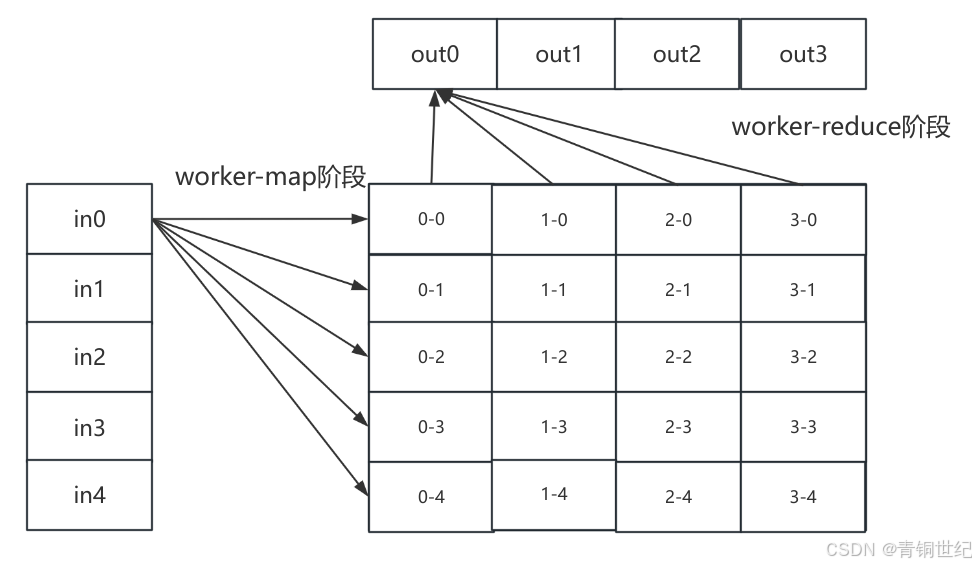
本文介绍了大致思想,详细内容请参考原论文。
代码详解
rpc.go
package mr
//
// RPC definitions.
//
// remember to capitalize all names.
//
import (
"fmt"
"os"
"strconv"
)
const (
MAP = "MAP"
REDUCE = "REDUCE"
DONE = "DONE"
)
//
// example to show how to declare the arguments
// and reply for an RPC.
//
type ApplyArgs struct {
WorkerID int
LastTaskType string
LastTaskID int
}
type ReplyArgs struct {
TaskId int
TaskType string
InputFile string
MapNum int
ReduceNum int
}
// Add your RPC definitions here.
// Cook up a unique-ish UNIX-domain socket name
// in /var/tmp, for the coordinator.
// Can't use the current directory since
// Athena AFS doesn't support UNIX-domain sockets.
func coordinatorSock() string {
s := "/var/tmp/5840-mr-"
s += strconv.Itoa(os.Getuid())
return s
}
// 构造文件名
func tmpMapResult(workerID int, taskID int, reduceId int) string {
return fmt.Sprintf("tmp-worker-%d-%d-%d", workerID, taskID, reduceId)
}
func finalMapResult(taskID int, reduceID int) string {
return fmt.Sprintf("mr-%d-%d", taskID, reduceID)
}
func tmpReduceResult(workerID int, reduceId int) string {
return fmt.Sprintf("tmp-worker-%d-out-%d", workerID, reduceId)
}
func finalReduceResult(reduceID int) string {
return fmt.Sprintf("mr-out-%d", reduceID)
}
worker.go
package mr
import (
"fmt"
"hash/fnv"
"io"
"log"
"net/rpc"
"os"
"sort"
"strings"
)
// Map functions return a slice of KeyValue.
type KeyValue struct {
Key string
Value string
}
// for sorting by key.
type ByKey []KeyValue
// for sorting by key.
func (a ByKey) Len() int { return len(a) }
func (a ByKey) Swap(i, j int) { a[i], a[j] = a[j], a[i] }
func (a ByKey) Less(i, j int) bool { return a[i].Key < a[j].Key }
// use ihash(key) % NReduce to choose the reduce
// task number for each KeyValue emitted by Map.
func ihash(key string) int {
h := fnv.New32a()
h.Write([]byte(key))
return int(h.Sum32() & 0x7fffffff)
}
// main/mrworker.go calls this function.
func Worker(mapf func(string, string) []KeyValue,
reducef func(string, []string) string) {
// Your worker implementation here.
id := os.Getegid()
// log.Printf("worker %d start working", id)
lastTaskId := -1
lastTaskType := ""
loop:
for {
args := ApplyArgs{
WorkerID: id,
LastTaskType: lastTaskType,
LastTaskID: lastTaskId,
}
reply := ReplyArgs{}
ok := call("Coordinator.ApplyForTask", &args, &reply)
if !ok {
fmt.Printf("call failed!\n")
continue
}
// log.Printf("reply: %v", reply)
lastTaskId = reply.TaskId
lastTaskType = reply.TaskType
switch reply.TaskType {
case "":
// log.Println("finished")
break loop
case MAP:
// log.Printf("worker %d get map task %d", id, reply.TaskId)
doMapTask(id, reply.TaskId, reply.InputFile, reply.ReduceNum, mapf)
case REDUCE:
// log.Printf("worker %d get reduce task %d", id, reply.TaskId)
doReduceTask(id, reply.TaskId, reply.MapNum, reducef)
}
}
// uncomment to send the Example RPC to the coordinator.
// CallExample()
}
// send an RPC request to the coordinator, wait for the response.
// usually returns true.
// returns false if something goes wrong.
func call(rpcname string, args interface{}, reply interface{}) bool {
// c, err := rpc.DialHTTP("tcp", "127.0.0.1"+":1234")
sockname := coordinatorSock()
c, err := rpc.DialHTTP("unix", sockname)
if err != nil {
log.Fatal("dialing:", err)
}
defer c.Close()
err = c.Call(rpcname, args, reply)
if err == nil {
return true
}
fmt.Println(err)
return false
}
func doMapTask(id int, taskId int, filename string, reduceNum int, mapf func(string, string) []KeyValue) {
file, err := os.Open(filename)
if err != nil {
log.Fatalf("%s 文件打开失败! ", filename)
return
}
content, err := io.ReadAll(file)
if err != nil {
log.Fatalf("%s 文件内容读取失败! ", filename)
}
file.Close()
kvList := mapf(filename, string(content)) // kv list
hashedKvList := make(map[int]ByKey)
for _, kv := range kvList {
hashedKey := ihash(kv.Key) % reduceNum
hashedKvList[hashedKey] = append(hashedKvList[hashedKey], kv)
}
for i := 0; i < reduceNum; i++ {
outFile, err := os.Create(tmpMapResult(id, taskId, i))
if err != nil {
log.Fatalf("can not create output file: %e", err)
return
}
for _, kv := range hashedKvList[i] {
fmt.Fprintf(outFile, "%v\t%v\n", kv.Key, kv.Value)
}
outFile.Close()
}
// log.Printf("worker %d finished map task\n", id)
}
func doReduceTask(id int, taskId int, mapNum int, reducef func(string, []string) string) {
var kvList ByKey
var lines []string
for i := 0; i < mapNum; i++ {
mapOutFile := finalMapResult(i, taskId)
file, err := os.Open(mapOutFile)
if err != nil {
log.Fatalf("can not open output file %s: %e", mapOutFile, err)
return
}
content, err := io.ReadAll(file)
if err != nil {
log.Fatalf("file read failed %s: %e", mapOutFile, err)
return
}
lines = append(lines, strings.Split(string(content), "\n")...)
}
for _, line := range lines {
if strings.TrimSpace(line) == "" {
continue
}
split := strings.Split(line, "\t")
kvList = append(kvList, KeyValue{Key: split[0], Value: split[1]})
}
sort.Sort(kvList)
outputFile := tmpReduceResult(id, taskId)
file, err := os.Create(outputFile)
if err != nil {
log.Fatalf("can not create output file: %e", err)
return
}
for i := 0; i < len(kvList); {
j := i + 1
key := kvList[i].Key
var values []string
for j < len(kvList) && kvList[j].Key == key {
j++
}
for k := i; k < j; k++ {
values = append(values, kvList[k].Value)
}
res := reducef(key, values)
fmt.Fprintf(file, "%v %v\n", key, res)
i = j
}
file.Close()
// log.Printf("worker %d finished reduce task", id)
}
coordinator.go
package mr
import (
"fmt"
"log"
"math"
"net"
"net/http"
"net/rpc"
"os"
"sync"
"time"
)
type Task struct {
id int
inputFile string
worker int
taskType string
deadLine time.Time
}
type Coordinator struct {
// Your definitions here.
mtx sync.Mutex
inputFile []string
reduceNum int
mapNum int
taskStates map[string]Task
todoList chan Task
stage string
}
// Your code here -- RPC handlers for the worker to call.
// an example RPC handler.
//
// the RPC argument and reply types are defined in rpc.go.
func (c *Coordinator) ApplyForTask(args *ApplyArgs, reply *ReplyArgs) error {
// process the last task
if args.LastTaskID != -1 {
taskId := createTaskId(args.LastTaskID, args.LastTaskType)
c.mtx.Lock()
if task, ok := c.taskStates[taskId]; ok && task.worker != -1 { // 排除过期任务
// log.Printf("worker %d finish task %d", args.WorkerID, task.id)
if args.LastTaskType == MAP {
for i := 0; i < c.reduceNum; i++ {
err := os.Rename(tmpMapResult(task.worker, task.id, i), finalMapResult(task.id, i))
if err != nil {
log.Fatalf("can not rename %s: %e", tmpMapResult(task.worker, task.id, i), err)
}
}
} else if args.LastTaskType == REDUCE {
err := os.Rename(tmpReduceResult(task.worker, task.id), finalReduceResult(task.id))
if err != nil {
log.Fatalf("can not rename %s: %e", tmpReduceResult(task.worker, task.id), err)
}
}
delete(c.taskStates, taskId)
if len(c.taskStates) == 0 {
c.shift()
}
}
c.mtx.Unlock()
}
// assign the new task
task, ok := <-c.todoList
if !ok {
return nil
}
reply.InputFile = task.inputFile
reply.MapNum = c.mapNum
reply.ReduceNum = c.reduceNum
reply.TaskId = task.id
reply.TaskType = task.taskType
task.worker = args.WorkerID
task.deadLine = time.Now().Add(10 * time.Second)
// log.Printf("assign %s task %d to worker %d", task.taskType, task.id, args.WorkerID)
c.mtx.Lock()
c.taskStates[createTaskId(task.id, task.taskType)] = task
c.mtx.Unlock()
return nil
}
// start a thread that listens for RPCs from worker.go
func (c *Coordinator) server() {
rpc.Register(c)
rpc.HandleHTTP()
//l, e := net.Listen("tcp", ":1234")
sockname := coordinatorSock()
os.Remove(sockname)
l, e := net.Listen("unix", sockname)
if e != nil {
log.Fatal("listen error:", e)
}
go http.Serve(l, nil)
}
// 改变当前的状态
func (c *Coordinator) shift() {
// 加锁状态
if c.stage == MAP {
// log.Printf("Map Task finished")
c.stage = REDUCE
// 分配reduce task
for i := 0; i < c.reduceNum; i++ {
task := Task{
id: i,
worker: -1,
taskType: REDUCE,
}
c.todoList <- task
c.taskStates[createTaskId(i, REDUCE)] = task
}
} else if c.stage == REDUCE {
close(c.todoList)
c.stage = DONE
}
}
// main/mrcoordinator.go calls Done() periodically to find out
// if the entire job has finished.
func (c *Coordinator) Done() bool {
// Your code here.
c.mtx.Lock()
defer c.mtx.Unlock()
return c.stage == DONE
}
// create a Coordinator.
// main/mrcoordinator.go calls this function.
// nReduce is the number of reduce tasks to use.
func MakeCoordinator(files []string, nReduce int) *Coordinator {
c := Coordinator{
mtx: sync.Mutex{},
inputFile: files,
reduceNum: nReduce,
mapNum: len(files),
taskStates: make(map[string]Task),
todoList: make(chan Task, int(math.Max(float64(nReduce), float64(len(files))))),
stage: MAP,
}
for i, file := range files {
task := Task{
id: i,
inputFile: file,
worker: -1,
taskType: MAP,
}
c.todoList <- task
c.taskStates[createTaskId(i, MAP)] = task
}
// 回收任务
go c.collectTask()
c.server()
return &c
}
func createTaskId(id int, taskType string) string {
return fmt.Sprintf("%d-%s", id, taskType)
}
// worker执行过期后回收任务
func (c *Coordinator) collectTask() {
for {
time.Sleep(500 * time.Millisecond)
c.mtx.Lock()
if c.stage == DONE {
c.mtx.Unlock()
return
}
for _, task := range c.taskStates {
if task.worker != -1 && time.Now().After(task.deadLine) {
// task is expired
task.worker = -1
// log.Printf("task %d is expired", task.id)
c.todoList <- task
}
}
c.mtx.Unlock()
}
}
运行说明
mrcoordinator
cd src/main/
go build -buildmode=plugin ../mrapps/wc.go
rm mr-out*
go run mrcoordinator.go pg-*.txt
mrworker
cd src/main/
go run mrworker.go wc.so
测试结果
bash test-mr.sh
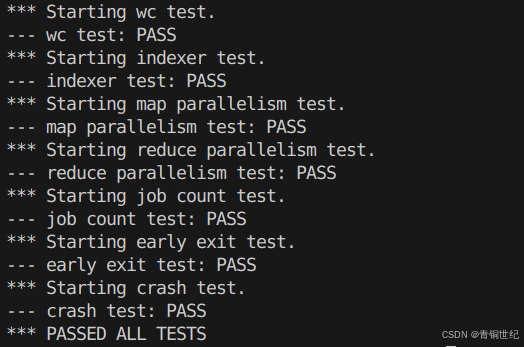
MIT6.5840 课程Lab完整项目















 2880
2880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









