






数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。
目录
图的存储结构简介
一方面,由于图的结构比较复杂,任意两个顶点都可能存在联系,因此无法以数据元素在存储区中的物理位置来表示元素之间的关系,而图没有顺序存储结构,但其中可以借助二维数组来表示元素之间的关系。即采用邻接矩阵表示法。另一方面,由于图的任意两个顶点都可能存在和邻接多重表,应根据实际需要的不同选择不同的存储结构。
1.邻接矩阵
1.邻接矩阵表示法
邻接矩阵是表示顶点之间相邻关系的矩阵。设G(V,E)是具有n个顶点的图,则G的邻接矩阵是具有如下性质的n阶方阵。
例如:
其中,表示边上的权值;
表示计算机允许的、大于所有边上权值的数。例如下图表示一个有向网和它的邻接矩阵。

有向图N
邻接矩阵
2.采用邻接矩阵表示图
这里我们采用C++来表示这段代码,为了更好的迎合教材,所以采用了大量的替换符,本段代码为替换符及头文件部分。
#include <iostream>
using namespace std;
#define OK 1
#define ERROR 0
#define INFEASIBLE -1
#define OVERFLOW -2
typedef int Status;
#define MaxInt 32767 //表示极大值,即∞
#define MVNum 100 //最大顶点数
typedef int VerTexType;//假设顶点的数据类型为整型
typedef int ArcType; //假设边的权值类型为整型接下来是创建邻接表部分,我们在结构体中定义一个整型的顶点数组用来存放顶点的值,然后在定义一个二维数组存储邻接矩阵中的值,最后在定义两个变量来存储图的点数与边数。
typedef struct
{
VerTexType vexs[MVNum]; //顶点表
ArcType arcs[MVNum][MVNum]; //邻接矩阵
int vexnum,arcnum; //图的当前点数和边数
}AMGraph;由于我们在插入函数中需要用到查找位置函数,所以我们在这个部分是事先定义声明好查找位置函数。
Status LocateVex(AMGraph G,VerTexType v) //查询顶点v在图G中的下标位置
{
for(int i=0;i<G.vexnum;i++){
if(G.vexs[i]==v){
return i;
}
}
}然后是图的输入部分。首先输入总顶点数和总边数进入for循环继续输入图中相关点的信息。然后再调用查询位置函数对每个顶点进行精准赋值;
我们这段代码是对无向图的输入,那么有向图的输入和其大体流程相同,只需要删掉G.arcs[n][m]=1这段代码,使其变成单向赋值就可以。
Status CreateUDG(AMGraph &G){
cin>>G.vexnum>>G.arcnum;//输入总顶点数,总边数
for(int i=0;i<G.vexnum;i++){
cin>>G.vexs[i];//输入点的信息
}
int v1,v2;
int m,n;
for(int j=0;j<G.arcnum;j++){
cin>>v1>>v2;//输入一条边依附的顶点
int m=LocateVex(G,v1);
int n=LocateVex(G,v2);
G.arcs[m][n]=1;
G.arcs[n][m]=1;
}
return OK;
}接下来是输出部分,只需要简单的套用两个for循环,再次不进行过多赘述。
Status PrintAMGraph(AMGraph G){
for(int i=0;i<G.vexnum;i++){
for(int j=0;j<G.vexnum;j++){
cout<<G.arcs[i][j]<<" ";
}
cout<<"\n";
}
return OK;
}最后是主函数部分
int main()
{
AMGraph G;
//调用利用邻接矩阵创建无向图的函数CreateUDG
CreateUDG(G);
//调用输出邻接矩阵的函数PrintAMGraph
PrintAMGraph(G);
return 0;
}3.邻接矩阵表示法的优缺点
(1)优点:
1.便于判断两个顶点间是否有边,即根据A[i][j]=0或1来判断。
2.便于计算各个顶点的度。对于无向图,邻接矩阵第i行元素之和就是顶点vi的度;对于有向图,第i行元素之和就是顶点vi的出度,第i行元素之和就是顶点的入度。
(2)缺点:
1.不便于增加和删除顶点。
2.不便于统计边的数目,需要查找邻接矩阵所有元素才能统计完毕,时间复杂度为O()。
3.空间复杂度高。如果是有向图,n个顶点需要个单元存储边。如果是无向图,因其邻接矩阵是对称的所以同样需要大量的存储空间,这对于稀疏图而言尤其浪费空间。
2.邻接表
1.邻接表表示法
邻接表是图的一种链式存储结构。在邻接表中,对图中的每个顶点Vi建立一个单链表,把与Vi相邻接的顶点放在这个链表中。邻接表中每个单链表的第一个节点存放有关顶点的信息,把这一节点看成链表的表头,其余节点存放有关边的信息,这样邻接表便由两部分组成,表头节点表和边表。
(1)表头节点表:由所有表头节点以顺序结构的形式存储,以便可以随机访问任一顶点的边链表。表头节点包括数据域和链域两部分。
(2)边表:由表示图中顶点关系的2n个边链表构成。边链表中边界点包括邻接点域、数据域、和链域3个部分。

以下为邻接表示意图:
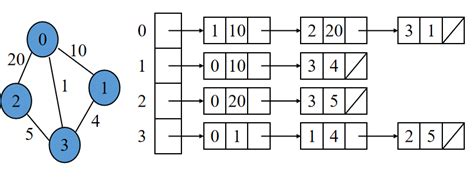
2.采用邻接表表示法创建无向图
同样是C++,同样是替换符及头文件部分
#include <iostream>
using namespace std;
#define MVNum 100 //最大顶点信息
#define OK 1
typedef char VerTexType;
typedef int OtherInfo;接下来是创建邻接表部分,邻接表的存储结构比较特殊,我们用到三个结构体来进行存储,第一个用来存储边节点,以及向下的指针域和有关信息,第二个用来存储顶点信息以及指针域,第三个顺接第二个结构题来声明邻接表,然后定义顶点数与边数。
typedef struct ArcNode { //边结点
int adjvex; //该边所指向顶点的位置
struct ArcNode *nextarc; //指向下一条边的指针
OtherInfo info; //和边相关的信息
}ArcNode;
typedef struct VNode {
VerTexType data; //顶点信息
ArcNode *fristarrc; //指向第一条依附该顶点
} VNode,AdjList[MVNum];
typedef struct {
AdjList vertices; // 邻接表
int vexnum; //图的当前顶点数
int arcnum; //图的当前边数
}ALGraph;同样是查找位置函数,与邻接矩阵大同小异,如此不做过多赘述。
int LocateVex(ALGraph G,VerTexType v) {
for (int i = 0; i < G.vexnum; i++)
if (G.vertices[i].data == v)
return i;
return -1;
}然后就是算法的核心以及输入部分,这里运用了指针的头插法,以及大量的for循环来输入邻接表的信息。
int CreateUDC(ALGraph &G) {
//采用邻接表表示法,创建无向图G
int i, k;
//输出总顶点数,总边数
cin >> G.vexnum >> G.arcnum;
cout << endl;
for (i = 0 ; i < G.vexnum; i++) { //输入各点,构建表头结点
cin >> G.vertices[i].data;
G.vertices[i].fristarrc = NULL; //初始化表头结点的指针域为NULL
}
cout << endl;
for (k = 0; k < G.arcnum; k++) {
VerTexType v1, v2;
int i, j;
cin >> v1 >> v2; //输入一条边依附的两个顶点
i = LocateVex(G, v1); j = LocateVex(G, v2); //确定v1和v2在G中的位置,即顶点在G.vertices(邻接表)中的序号
ArcNode *p1 = new ArcNode; //生成一个新的边结点*p1
p1->adjvex = j; //邻接点序号为j
p1->nextarc = G.vertices[i].fristarrc; G.vertices[i].fristarrc = p1; //将新节点*p1插入vi的边表头部
ArcNode *p2 = new ArcNode; //生成另一个对称的新的边结点*p2
p2->adjvex = i; //邻接点序号为i
p2->nextarc = G.vertices[j].fristarrc; G.vertices[j].fristarrc = p2; //将新结点*p2插入顶点Vj的边表头部
}
return OK;
}最后是主函数部分,其中囊括了输出函数。
int main(){
ALGraph G;
CreateUDC(G);
int i;
cout << endl;
for (i = 0; i < G.vexnum; i++) {
VNode temp = G.vertices[i]; //将G的顶点信息付给temp
ArcNode *p = temp.fristarrc; //将顶点信息temp中的边信息给p
if ( p == NULL)
{
cout << G.vertices[i].data;
cout << endl;
}
else {
cout << temp.data;
while (p)
{
cout << "->";
cout << p->adjvex;
p = p->nextarc;
}
}
cout << endl;
}
return 0;
}3.邻接表表示法的优缺点
(1)优点
1.便于增加和删除顶点。
2.便于统计边的数目,按顶点顺序查找所有边表可得到边的数目,时间复杂度为O(n+e)
3.空间效率高,由于针对有向图和无向图有不同的存储方式所以更加适合存储稀疏图。
(2)缺点
1.不便于判断顶点之间是否有边,要判定vi和vj之间是否有边,就需要查找第i个边表。
2.不便于计算各个顶点的度,求顶点的入度(出度)比较容易,那么求顶点的出度(入度)就比较困难。
3.小总结
本次内容主要了讲解了数据结构中的一些基础知识点,主要内容顺序表的有关知识本篇内容都为数据结构的基本思想,若想更深的理解以及体会,还请大家在日常学习中多多努力,希望大家学有所成。















 2450
2450











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











