







什么是邻接表?
- 邻接表(Adjacency List)是图的一种顺序存储与链式存储结合的存储方法。
- 对于图G中的每个顶点
Vi,将所有邻接于Vi的顶点Vj链成一个单链表,这个单链表就称为顶点Vi的邻接表,再将所有顶点的邻接表表头放到数组中,就构成了图的邻接表。 - 在邻接表表示中,包括两种结点结构。
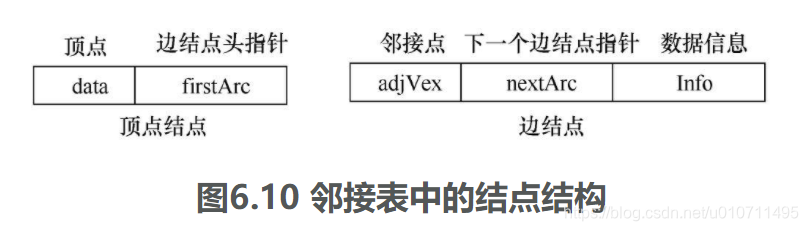
- 一个是
顶点结点,每个顶点结点由2个域组成,其中data域存储顶点Vi的名或其相关信息,firstArc指向顶点Vi的第一个邻接点的边结点;- - 第二个是
边结点,边结点由3个域组成。其中abjVex域存放与Vi邻接的点的序号,nextArc指向Vi下一个邻接点的边结点,info域存储和边或弧相关的信息,如权值,如图6.10所示
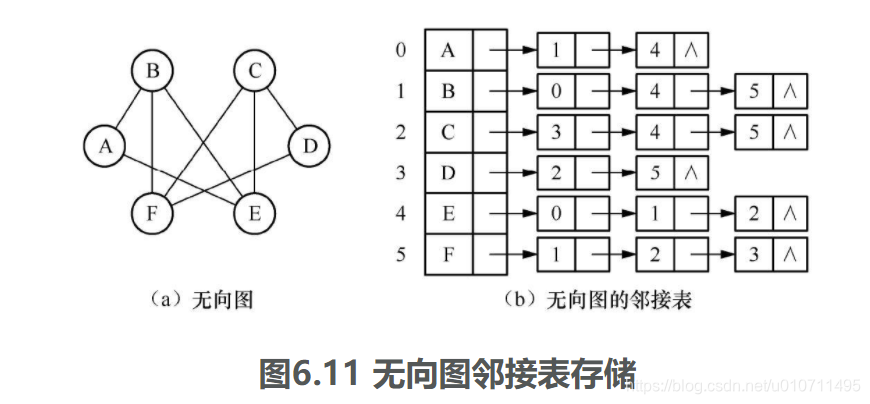
无向图的邻接表表示如图6.11所示。
为什么需要邻接表?
相比邻接矩阵,节省空间.
边结点的java实现?
class ArcNode {
int adjVex;//存放相邻结点的序号
ArcNode nextArc;//下一个边结点
int weight;//权重
public ArcNode() {
adjVex = 0;
weight = 0;
nextArc = null;
}
}
顶点的java实现
class VNode<T> {//顶点结点
T data;//存储顶点的名称或其他相关信息
ArcNode firstArc;//指向顶点Vi的第一个边结点
public VNode() {
data = null;
firstArc = null;
}
}
邻接表的java实现
class ArcNode {
int adjVex;//存放相邻结点的序号
ArcNode nextArc;//下一个边结点
int weight;//权重
public ArcNode() {
adjVex = 0;
weight = 0;
nextArc = null;
}
}
class VNode<T> {//顶点结点
T data;//存储顶点的名称或其他相关信息
ArcNode firstArc;//指向顶点Vi的第一个边结点
public VNode() {
data = null;
firstArc = null;
}
}
class AlGraph<T> {//图的邻接表数据类型
protected final int MAXSIZE = 10;
protected VNode[] adjList;//顶点
int n, e;//图的顶点数和边数
public AlGraph() {
adjList = new VNode[MAXSIZE];//顶点列表
}
public void CreateLink() {
}//创建无向图的邻接表
public int LocateVex(T x) {
int i;
for (i = 0; i < n; i++) {
if (adjList[i].data == x) return i;
return -1;
}
return i;
} //在图中查找顶点,返回其索引
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











