







ASCII码
ASCII码就是机器能识别的单字节编码系统,它是单字节的。
Unicode编码
Unicode编码是一种统一码、万国码、单一码,它能编码任何国家的语言,Unicode编码不管英文还是中文最少都是占两个字节。
UTF-8编码
UTF-8编码是从Unicode编码上衍生出来的一种编码,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存。
GBK编码
GBK编码也是从Unicode编码上衍生出来的一种编码,是咱们大中华民族的专属字符编码集。
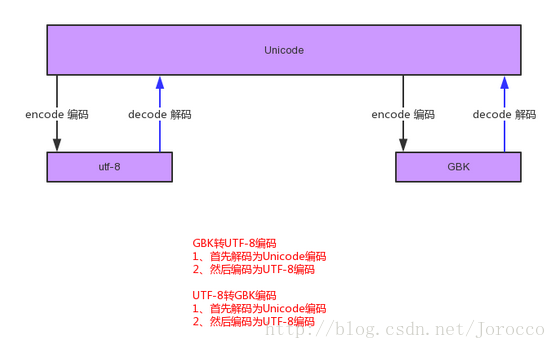
从图中我们可以看出,我们从一种编码转换成另一种编码,例如:GBK转UTF-8,首先得解码(decode)成它们的始祖Unicode,然后再编码(encode)成新的编码。
举例说明
python3的例子
这个例子是在python3环境中写的,python3环境默认的字符串编码是unicode,所以我们的写字符串都是unicode编码的,--coding:utf-8 --这个的意思是该.py文件是utf-8 编码的。
# -*-coding:utf-8 -*-
# Author:Morocco
s = "你好"
unicode_to_utf=s.encode("utf-8")#unicode编码成utf-8
print(s.encode("utf-8").decode("utf-8"))注意:
1、python3环境下如果不进行解码成Unicode,它打印出来的是一个bytes类型的编码方式,终端一般都是Unicode编码方式,所以最后一定得加上.decode("utf-8") 转成Unicode编码。
2、默认编码方式和--coding:utf-8 - 设置的文件编码方式不是同一个含义,默认的编码方式只是指该python3环境中的字符串编码,这是我们不能设置的,而我们所能设置的编码方式是文件编码方式,因为我们的文件不仅有所谓的字符串还有其他的代码。
python2.X例子
这里直接引用的是Python2.X中的编码转换
python3笔者认为是主流,把python3弄清楚就好。python2.X中的编码方式有点不苟同,它默认的字符串编码是ASCII编码,当我们指定文件编码为utf-8编码时,字符串编码就变成了utf-8。但在python3中却不是这样的!!!因为你即使改变了它的文件编码方式,它的字符串编码还是Unicode编码。















 536
536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









