






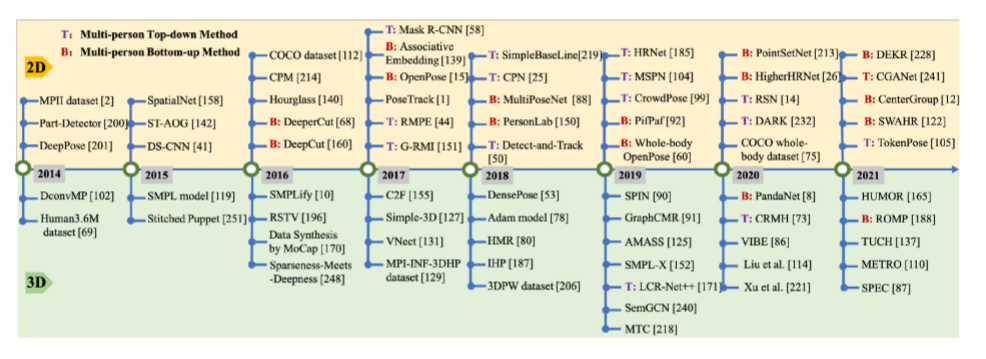
文献阅读:Recent Advances of Monocular 2D and 3D Human Pose
Estimation: A Deep Learning Perspective
摘要:在本文中,作者提供了一个全面的 2d到3d视角来解决单目人体姿态估计的问题。首先,全面总结了人体的二维和三维表征。然后总结了自 2014年以来在统一框架下这些人体展示的主流和里程碑式的方法。
2D 3D的贡献、想法、或者数据集的发展图
用于mpe的深度学习框架
大多数单人姿态估计网络可以被认为是由一个位姿encoder和位姿decoder组成,前者的目标是通过高低分辨率的过程提取高级特征。后者以基于检测的方式或基于回归的方式估计目标输出、2D/3D关键点位置或3D网格。
多人来说,就分为自上而下和自下而上的方法,自上而下就是先把每个人从图中分出来,然后再分别进行姿态的估计,自下而上就是先把所有关键点给找出来,然后把它们分类给具体的每一个人(2d的应用:openpose)。
数据集:应用最广泛的还是Human3.6M,但他也只是包含7个人的15项室内活动。在室外的训练数据太少了。
人体表征
从不同方面描述复杂的人体姿态,分为两类:
1.基于关键点的表示
2.基于模型的表示
基于关键点的表示:
2D/3D关键点坐标、2D/3D热图、方位地图(如openpose的部分亲和力场)、分层骨载体(如CHP)
基于模型的表示:
基于零件的体积模型(如EllipBody 模型,以椭球体作为人体部件基本单位)、详细统计3D人体模型(蒙皮多人线性模型SMPL)

单目2d姿态估计
单人:从输入的数据来进行分类为图像、视频。
Deeppose:基于深度卷积神经网络(DCNNs)的人体姿态估计方法,利用基于dcnn的位姿预测器级联,DeepPose 将关键点估计作为一个回归问题来表述。
IEF迭代误差反馈网络:利用自校正回归模型。这是一种自上而下的反馈,逐步改变最初的关键点预测。
结构车身模型:结合基于dcnn的整体特征表示,探索图形模型来描述具有空间关系的结构部分和局部部分。
多级管道:多级管道和多级特征融合对于捕捉人体细节非常有用。其中的代表作之一是堆叠式沙漏网络。每个沙漏网络由自下而上处理(从高分辨率到低分辨率)和自上而下处理(从低分辨率到高分辨率)之间的对称分布组成。它利用跳跃层来保存每个分辨率的空间信息。结合中间监控,整个网络连续堆叠多个沙漏模块。这是其设计优化变体的坚实基础。
CPM:多级网络卷积式状态机,使用中间输入和监督来学习隐式的空间模型,而没有显式的图形模型。它的序列多阶段卷积体系结构日益细化关键点位置的预测。
姿态细化:对网络输出进行细化可以提高最终姿态估计的性能。比如建多源深度模型,从不同信息源中提取非线性表示,包括视觉外观评分、外观混合类型和变形。
多任务学习:多任务学习可以利用相关任务中的互补信息,为姿态估计提供额外的线索。Luvizon等人提出了一种联合从视频序列中进行 2D/3D姿态估计和人体动作识别的多任务框架。还有文献利用对抗数据增强来解决随机数据增强在网络训练中的局限性。设计了一种奖罚策略,用于增强网络与目标(姿态估计)网络的联合训练。
提高模型运行速度:提高模型效率的框架,包括使用轻量级算子、网络二值化、模型精馏等。
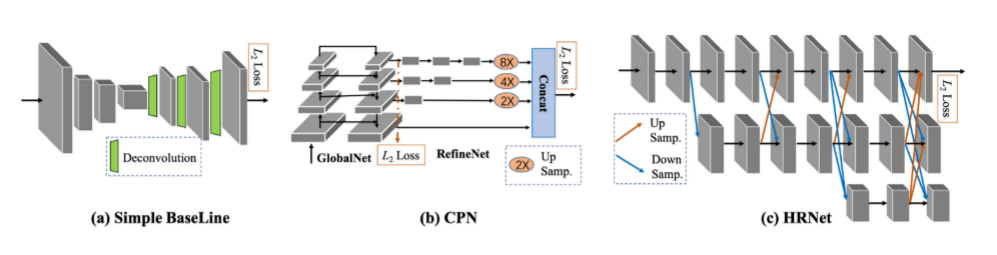
三个具有代表性的自顶向下二维多人姿态估计网络
simple baseline:随着精度性能的提升,模型的复杂度也越来越高,这使得找出究竟是哪种结构最为有效变得困难,作者尝试提供一个简单的比较基线,同时发现虽然简单但是同样获得了很好的关键点定位的效果。提出的模型结构是一个特征提取网络加反卷积层。没有使用任何跳层连接,直接在最后一层特征图上使用反卷积。
CPN:
Cascaded Pyramid Network(CPN)级联金字塔网络,该网络可以有效缓解“hard” keypoints的检测问题,CPN网络分为两个阶段:GlobalNet和RefineNet。GlobalNet网络是一个特征金字塔网络,该网络用于定位简单的关键点,如眼睛和手等,但是对于遮挡点和不可见的点可能缺乏精确的定位;RefinNet网络该网络通过集合来自GolbalNet网络的多级别特征来明确解决“难点”的检测问题。
HRNet:该网络主要是针对单一个体的姿态评估(即输入网络的图像中应该只有一个人体目标)。人体姿态估计在现今的应用场景也比较多,比如说人体行为动作识别,人机交互(比如人作出某种动作可以触发系统执行某些任务),动画制作(比如根据人体的关键点信息生成对应卡通人物的动作)等等。
多人姿态估计
自顶向下、自底向上。
自顶向下
两级管道:
Papandreou 等人提出了一种基于深度学习的两阶段自上而下的管道,名为 G-RMI。他们使用 Faster RCNN检测器来检测每个人,然后利用全卷积ResNet[59]来联合预测关键点的密集热图和偏移。他们还引入了基于关键点的 NMS而不是盒级NMS,以提高关键点的可信度。
多任务学习:通过在姿态估计相关任务之间共享特征,多任务学习可以为姿态估计提供更好的特征表示。
Mask- RCNN:]首先检测人的包围框,然后裁剪相应提议的特征图来预测人的关键点。多任务网络,联合预测关键点并对语义部分进行分割。
ZoomNet:人体姿态估计器、手/脸检测器和手/脸姿态估计器统一为一个网络。该网络首先定位身体关键点,然后放大手/脸区域,以更高的分辨率预测这些关键点。它可以处理人体不同部位的尺度差异。针对全文数据不足的问题,通过对COCO数据集进行全身标注扩展,提出了COCO- wholbody数据集。
多阶段或多分支融合:
级联金字塔网络(Cascade Pyramid Network, CPN),MSPN是在多级管道中扩展了CPN。它以CPN的全局网络为每个单级模块,通过跨级特征聚合融合不同阶段的特征,并通过由粗到细的损耗函数对整个网络进行监控。
HRnet指出高分辨率表示对于硬键点检测非常重要。HRNet 在整个网络中保持高分辨率表示,并逐渐增加高分辨率到低分辨率的子网,形成多分辨率特征。
graph - pcnn:利用带有残差步骤网络(RSN)模块的多级管道来聚合内部层面的特征。在RSN的精细局部表示的基础上,
提出了姿态精炼机(Pose Refine Machine, PRM)模块,进一步平衡局部/全局表示,细化输出关键点。
处理复杂场景:
RMPE设计了对称空间变压器网络来检测每个人,参数化姿态NMS来过滤冗余姿态,姿态引导的人建议发生器来提高网络的多人能力,以提高对不准确的人的检测能力。
为了解决拥挤场景中的问题,Li 等首先在每个裁剪的包围框中获取联合候选,然后在图模型中解决联合关联问题。他们还收集了一个名为 CrowdPose 的拥挤人体姿态估计数据集,并定义了人群指数
(Crowd Index)来衡量图像的拥挤程度。OASNet利用Siamese 网络的注意机制,去除感知遮挡的模糊,重构无遮挡特征。
Bin et al为了扩大挑战性案例的训练集,提出通过结合分割的身体部位来模拟挑战性案例来增强图像。利用生成网络动态调整增广参数,生成最混乱的训练样本。MIPNet[84]重新考虑了自顶向下人体姿态估计器的关键假设,即输入包围框中只有一个人。
提高效率:小型快速网络受到人们的关注。
FCPose提出了一种动态的实例感知框架,该框架消除了 roi 和关键点分组后处理,无论图像中有多少人,推理时间都是快速而恒定的。
CGANet提出了ROIGuider 在全局上下文信息的引导下聚合多尺度盒体特征,所提出的骨干 TNet 能够高效地实现多尺度特征融合。为了更好地平衡准确性和效率,一些著作利用神经结构搜索(NAS)方法来设计姿态特定网络。PoseNAS它直接搜索具有堆叠可搜索单元的面向数据的姿态网络,可以为特定姿态任务提供最优的特征提取器和特征融合模块。
ViPNAS[222]通过精心设计五个维度的搜索空间来搜索空间,包括网络深度、宽度、内核大小、组号和注意事项。通过搜索视频中的时间特征融合和自动分配计算,进一步将其应用到视频姿态估计中。
TokenPose**明确关键点之间的约束关系**提出了基于Token表示的Transformer体系结构。每个关键点被显式嵌入作为标记,以同时学习图像中的约束关系和外观线索。TokenPose 表明,基于变压器的模型与基于cnn的最先进的模型相当,同时更轻量级。
### 自底向上:
关键点分组:除了为了更精确的关键点检测而进行的网络设计外,如何对关键点之间的连接信息进行编码是将关键点
分组给不同人群的核心。
部分亲和字段:目前最流行的自底向上姿态估计方法
OpenPose提出通过局部亲和域(paf)联合学习关键点
位置及其关联。PAF通过一组二维向量场对分支的位置和方向进行编码。PAF的方向是从肢体的一部分指向另一
部分。然后,多人关联进行二部匹配,对候选关键点进行关联。
PIF局部强度场来定位人体部位,PifPaf网中合生成 PIF和PAF来处理低分辨率和遮挡场景。
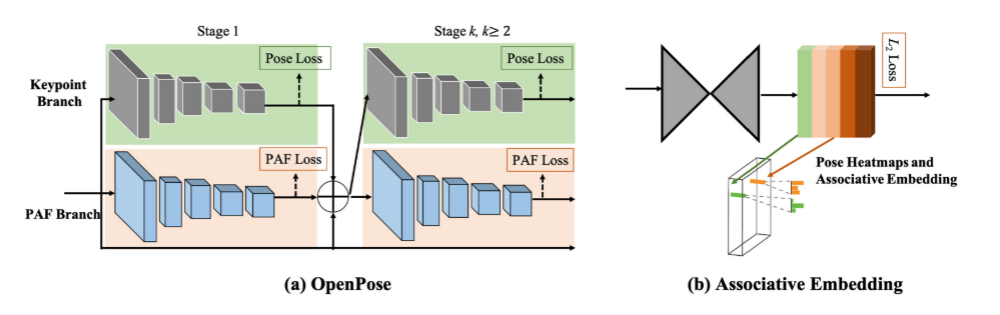
Hidalgo 等人提出了第一个用于全身多人姿态估计的
单网络方法,该方法可以同时定位图像中身体、面部、手和脚的关键点。
还有文献设计了身体部分感知的PAF对关键点之间的连接进行编码,并利用注意机制对堆叠的沙漏网络进行了改进。

两种代表性的自底向上的2d多人姿态估计方法:openpose和关联嵌入
关联嵌入:这种关联嵌入是一种检测分组的方法,它通过检测关键点并将关键点分组成具有嵌入特征或标记
的人。
Newell等人提出了生成关键点热图及其嵌入标签网络对身体的每个关节生成检测热图,同时预测关联嵌入标签。他们为每个关节选取最热门的检测,并将其与其他共享相同嵌入标签的检测相匹配,从而产生一组最终的个体姿态预测。
HigherHRNet:它从高分辨率的特征金字塔中学习尺度感知表示。利用了HRNet 中聚合的特征[185],以及通过转置卷积上采样的高分辨率特征,很好地处理了尺度变化,实现了自底向上姿态估计的最新技术。
scale and weight adaptive heatmap regression (SWAHR),自适应调整 heatmap中每个关键点的标准差,平衡前背景样本。
多任务学习:
MultiPoseNet:该模型可以联合处理人的检测、关
键点的检测和人的分割。设计了位姿残差网络,通过测量关键点和被检测人包围盒位置的相似性来确定关键点和被检测人包围盒的位置。
PersonLab:是一个多任务网络,可以联合预测关键点热图和人分割图。用近程和中程的两两偏移对关键点进行分组。同时,利用长程偏移和人体姿态检测来区分人脸分割。
**密集关键点回归**:另一种自下而上的范式是直接回归同一个人的关键点位置。
位姿划分网络(PPN):它对所有关键点候选点使用质心嵌入。
结构化姿态表示(Structured Pose Representation,
SPR:它利用根关节来表示人,并将关键点的位置编码为相应根的位移。
逐像素关键点回归方法:CenterNet、ConerNet、PointSetNet。对同一个人的关键点位置进行了密集预测。
DEKR:专注于学习精确关键点区域的表示,并使用多分支结构进行独立回归:每个分支通过专用的自适应卷积学习表示,并回归一个关键点。
CenterGroup:是一个基于注意的框架,它使用转换器获取所有关键点和中心的上下文感知嵌入。
SIMPLE:模拟了来自高性能自上而下管道的知识,并
将人体检测和姿态估计作为一个统一的点学习框架,以相互补充。
PINet:直接从人体可见部位推断出一个人的完整姿势,而不是预测单个关键点。它是一种姿态级回归策略,没有边界盒检测和关键点分组。
### 视频中的2d姿态估计:视频中的二维姿态估计也被 dcnn所提升,视频姿态估计必须考虑帧间的时间关系,以消除运动模糊和几何不一致性。利用好时空信息对视频中的人体姿态估计方法进行分类。
单人:是通过跨帧传播时间线索来细化单帧
姿态结果。
Pfister 是视频中最早基于深度学习的姿态估计的研究人员之一,他们通过在数据颜色通道中插入多帧图像来利用时间信息来替代基于图像的网络中输入的三通道 RGB图像。
•动作识别的姿态估计:
时空与或图(ST-AOG)模型,视频姿态估计与动作识别相结合。通过增加基于光流和外观特征的活动识别分支,使两者相互受益。
•基于光流的特征传播:
SpatialNet,该网络通过光流将邻帧热图时间上扭曲到当前帧。他们还利用参数池化层将对齐的热图组合成池化的置信度热图。
ConvNet 姿态估计器,通过空间图像匹配和光流传播,在整个视频中传播高质量的姿态标注。
Thin-Slicing:一个基于流的弯曲层,将先前的热图与当前帧对齐,然后是一个时空推理层。**时空传播利用了具有时空关系边的位姿配置图的迭代消息传递。**
•基于序列模型的特征传播:
链式模型:Gkioxari1等采用序列-序列循环模型来解决视频中的结构化姿态预测。
循环模型:每个主体关键点的预测依赖于所有之前预测的关键点。LSTM Pose Machine:通过增强内存的 LSTM框架来捕捉视频中的时间依赖性。给定一帧,encoder -RNN- decoder 管道首先通过编码器学习高级图像表示,然后通过 RNN单元传播时间信息并产生隐藏状态。**他们最终通过一个以隐藏状态作为输入的解码器来预测当前帧的关键点。 类似在**UniPose-LSTM也用了相同的概念。Pose Net 结合了运动补偿ConvLSTM来传播空间对齐的特征。**它利用压缩流来有效地从视频中解码姿态序列。**
### 视频中多人姿态估计和追踪:
PoseTrack数据集是大规模和在野外的多人数据集。
自上而下:自顶向下的方法遵循检测跟踪范式。它们**首先检测每个帧中的人物和关键点,然后在帧间传
播边界框或关键点。一些方法建立在基于剪辑的技术之上。**
3D Mask R- CNN:采用全3D卷积网络来检测视频片段中每个人的关键点。然后,使用一个关键点跟踪器通过比较检测到的包围盒的距离来连接预测
还有文献(M.-C. Wang, J. Tighe, and D. Modolo. 2020. Combining detection and tracking for human pose estimation in videos.
In CVPR.)使用了基于剪辑的跟踪器,通过精心设计的3D卷积层扩展HRNet,学习关键点之间的时间对应关系。设计了一种时空融合算法,通过时空平滑来估计出最优的关键点输出。
DCPose:解决运动模糊、视频散焦或姿态遮挡问题,提出了一种多帧人体姿态估计框架,该框架利用三个模块分别对关键点时空上下文进行编码,在双方向上计算加权姿态残差,并对姿态估计进行细化。
基于单帧检测基础上:(B. Xiao, H.-P. Wu, and Y.-C. Wei. 2018. Simple baselines for human pose estimation and tracking. In ECCV.)基于光流的时间位姿相似度来关联跨不同帧的关键点。
PGPT:解决了单帧缺失检测的问题,将基于图像的检测器与在线人员位置预测器相结合来补偿缺失的包围盒。还引入了一个分层的姿势引导的图卷积网络,该网络利用人类的结构关系来增强人的表示和数据关联。
Y.-D. Yang, Z. Ren, H.-X. Li, C.-L. Zhou, X.-C. Wang, and G. Hua. 2021. Learning dynamics via graph neural networks for human pose estimation and tracking. In CVPR.:设计了一个图形神经网络,明确地解释了时空和视觉信息。它输入历史位姿,直接预测下一帧对应的位姿,然后将预测的位姿与检测到的位姿进行聚合。
POINet:研究了一个姿态引导的 ovonic 洞察网络,以学习统一的端到端网络中的特征提取、相似性度量和身份分配。
R. Umer, A. Doering, B. Leibe, and J. Gall. 2020. Self-supervised keypoint correspondences for multi-person pose estimation and tracking in videos. In ECCV.提出了一种自监督关键点通信,它不仅可以恢复缺失的位姿检测,还可以跨帧将检测到的位姿和恢复到的位姿关联起来。
KeyTrack:提出了一种基于变压器的跟踪器,它只依赖于 15个关键点。基于变压器的网络利用二进制分类来预测一个姿势是否在时间上跟随另一个。
自下而上: **先使用单帧姿态估计预测每帧中的所有关键点,然后以时空优化的方式跨帧分配关键点。**
有基于图划分的方法扩展了图像级自底向上的多人姿态估计;PoseFlow:利用在不同帧中测量姿势距离的姿势流来跟踪同一个人。还有文献受到OpenPose的空间部分亲和力场的启发,利用时间流场来指示关键点跨帧的传播方向。还有使用了关联嵌入,对其进行扩展,构建了**时空嵌入**。
总结:综上所述,基于cnn的网络设计,借助身体部位结构关系、多级管道、多级特征融合、姿态细化、多任务学习和效率感知设计,极大地推动了二维位姿估计的发展。在多人情况下,**优秀的自顶向下方法依赖于精确的检测网络和可靠的单人姿态估计网络**。对于自底向上的方法,最**重要的部分是如何将检测到的关键点在不同的人之间进行关联。**在视频级姿态估计与跟踪中,有代表性的研究集中在如何有效传播时空信息以保证预测的一致性和平滑性。
## **单目三维姿态估计**:缺乏室外3D数据、深度模糊。数据集标注困难又贵。大多数数据集偏向于特定的环境。因此使用2d位姿数据集来提高泛化能力。(M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele. 2014. 2D human pose estimation: New benchmark and state of the art analysis. In CVPR.)(S. Johnson and M. Everingham. 2010. Clustered pose and nonlinear appearance models for human pose estimation.In BMVC.)(T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C.-L. Zitnick. 2014. Microsoft COCO:Common objects in context. In ECCV.)
**单目输入在描述深度信息时是不明确的。由于多个三维姿态可以映射到相同的二维观测,因此很难确定精确的三维姿态。特别是对于多阶段方法,这种模糊性更加严重。许多方法试图利用各种先验信息来解决这一问题**,如几何先验知识,统计模型和时间平滑。
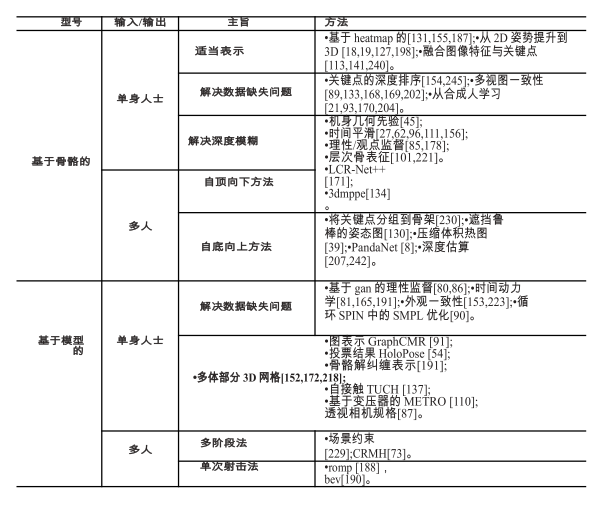
### 基于骨骼:直接估计人体关节的三维坐标。
### 基于模型:采用统计的三维模型:SMPL


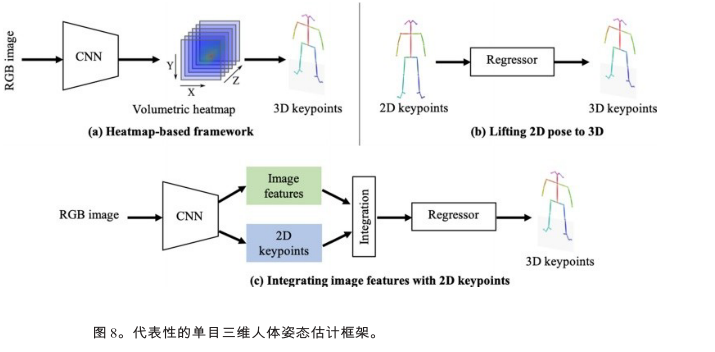
代表性的单目三维人体姿态框架
单人3d姿态估计方法:
(**1)体积热图**
基于热图的方法将每个三维关键点表示为热图中的三维高斯分布。在后处理过程中,通过获取局部最大值,从估计的体积热图中得到三维关键点坐标。如heatmap方法,通过端到端框架直接从单目图像中估算出体积热图。
C2F(由粗至细)网络,将沙漏网络进行叠加,并逐步向细粒度结果的预测热图的体积方向进行扩展。
VNect:是一种实时单目三维姿态估计方法。它使相干运动骨架在后处理中拟合,从而产生基于相干运动骨架的时间稳定位姿结果。
Integral Human Pose(IHP)提出了一种积分运算,在推理热图直接以可微的方式转换为关键点坐标。**它在基于热图的方法和基于回归的方法之间架起了一座桥梁。**
**(2)由2d姿态估计提升到3d姿态估计**
step1:从单目图像中估计 2D位姿
step2:将估计的2D位姿提升到3D
simple - 3d:这是一种著名的简单基线方法,从 2D位姿估计每个关键点的深度。它只包含两个完全连接的块,同时在相关的基准测试中获得良好的性能。
**位姿匹配**解决了 2d - 3d关键点提升问题。为了丰富匹配库,他们利用随机相机将 3D姿态投影到2D图像平面上,生成大量的2D-3D姿态对。然后,他们得到一个大型的2D-3D姿势对库。给定一张2D图像,他们只
需要预测2D姿势,并从库中搜索最相似的 2D- 3d姿势对。选择成对的三维姿态作为三维姿态估计结果。(C.-H. Chen and D. Ramanan. 2017. 3D human pose estimation = 2D pose estimation+ matching. In CVPR.)
一个多级卷积网络来递归地优化估计的 3D姿态:他们使用估计的 3D姿态的反投影来
细化中间的 2D姿态,这逐步提高了 2D和3D姿态估计的准确性。(Lifting from the deep: Convolutional 3D pose estimation from a single image. In CVPR.)
C.-H. Chen, A. Tyagi, A. Agrawal, D. Drover, S. Stojanov, and J.-M. Rehg. 2019. Unsupervised 3D pose estimation
with geometric self-supervision. In CVPR.:二维位姿输入与估计的三维位姿的二维投影之间的双循环一致性,以无监督的方式学习二维到三维的提升函数。它们在一个循环中随机变换提升的3D姿态,以避免在一个恒定的深度下收敛到局部最小值。
**(3)图像特征与2d姿态融合**
B.-X. Nie, P. Wei, and S.-C. Zhu. 2017. Monocular 3D human pose estimation by predicting depth on joints. In ICCV.:关键点的局部**图像纹理特征整合到全局二维骨架**中。然后,建立了LSTM网络的两级层次结构,逐步对全局和局部特征进行建模。
SemGCN:提取联合级图像特征,并将其与关键点坐标进行整合,形成多个图节点。利用图像特征,利用 GCN或LSTM来探讨关键点节
点之间的关系。
**解决数据不足的问题:大多数方法尝试以无监督或弱监督。**
Pavlakos认为优势在于监管重点之间的弱顺序深度关系。实验表明,**与基于地面真实三维姿态标注的直接监控相比,顺序监控
也能取得比较好的效果。**
Hemlets通过 heatmap **三态损失**将相邻关键点的显式深度排序编码为ground truth。
#### 使用多视图一致性进行监督(**但是还是采用的单目图像作为输入**)
如果只考虑多视图一致性,则会得到退化解决方案,模型可能会陷入局部最小值,并在不同输入下产生相似的零姿态。(H. Rhodin, J. Spörri, I. Katircioglu, Victor V. Constantin, F. Meyer, E. Müller, M. Salzmann, and P. Fua. 2018. Learning monocular 3D human pose estimation from multi-view images. In CVPR.)
Rhodin提出使用少量的标记数据来避免局部最小值,并修正预测。提出使用连续图像为身体表征学习提供先验时间一致性。
EpipolarPose:利用多视图 2D姿势,通过极向几何图形生成 3D姿势标注。通过这种方式,可以以自我监督的方式训练整个框架。
Umar:通过一种新的基于对准的目标函数来解决退化陷阱,而不需要外部摄像机校准。他们使用无标签的多视图图像和 2D姿势数据集训练模型。
Mitra:提出以半监督的方式学习视点不变的姿态嵌入。通过使左盆骨平行于XZ平面,训练模型来估计视图不变的 3D姿态。
**从合成的数据中学习**:
1)二维图像拼接管道
Rogez试图从3D动作捕捉(MoCap)数据集中生成 3D姿势的2D图像。
Chen 等人的和Varol 等人遵循 3D模态渲染流水线。他们使用 SCAPE或SMPL 3D人体模型,将有纹理的统计人体模型投影到 2D野外背景图像上进行数据生成。
**二维图像拼接管道有潜力生成更逼真的人物图像,而三维模型投影管道可以获得更全面的三维标注**
2)三维模型渲染管道
**PGP-human**:利用3d - 2d投影构建了一个自监督的训练管道。PGP-human利用了从野外视频中采样的图像对,其中包含同一个人在不同的背景下执行不同的动作。该模型通过训练,将图像对中提取的外观和姿态信息进行混合,进行图像再合成。
**解决内在的深度模糊**:采用各种先验约束来确定特定的位姿。许多方法使用时间一致性和动力学来解决单个2D位姿的模糊性。
RSTV:将视频序列中裁剪出来的单人图像块作为输入,在中心帧中估计出三维姿态。
Fang等人通过层次结构明确地将身体先验(包括运动学、对称性和驱动关节协调)纳入模型的双向RNN。
Lin 等人、Hossain等人、Lee 等人开发了由LSTM单元组成的序列-序列网络,从二维位姿序列估计出三维位姿序列。
VideoPose3D和OANet对二维位姿序列采用时间卷积来保证时间一致性。完整的卷积结构使高效的并行计算成为可能。OANet 使用圆柱体人体模型生成遮挡标签,帮助模型学习人体各部位之间的碰撞。
Sharma 等人以生成对抗的方式解决了歧义。他们训练了一个有条件的 VAE网络,以证明在2D位姿条件下生成的 3d位姿样本的合理性。
ActiveMoCap:试图估计不同预测的不确定性,这些预测用于选择模糊度较低的最佳输出。它帮助模型学习三维姿态估计的最佳视点。
分层骨表示的模型(Cascaded deep monocular 3D human pose estimation with evolutionary training data. In CVPR.)J.-W. Xu, Z.-B. Yu, B.-B. Ni, J.-C. Yang, X.-K. Yang, and W.-J. Zhang. 2020. Deep kinematics analysis for monocular
3D human pose estimation. In CVPR.
该模型明确地模拟了相邻关节的几何依赖关系,主要关注于监测骨骼长度和关节方向。得益于分层的骨骼表示,三维人体骨骼是可分离的,可以很容易地混合合成新的骨骼。
### 多人三维姿态估计:还是自上而下和自下而上。
自上而下:
LCR-Net++建立在通用的基于锚点的两级检测框架之上。他们首先从主播提议中收集姿势候选人,然后根据得分排名确定最终输出。
Camera distance-aware top-down approach for 3D multi-person pose estimation from a single RGB image. In ICCV.是建立在基于锚点的检测框架上。他们从检测到的人体区域及其包围盒位置的特征中提取独立的分支来估计三维绝对根定位和相对根姿态估计
自底向上:
Zanfir提出了一种自底向上的多阶段框架,用于单目多人 3D姿态估计。它首先从单个图像中估计体积热图,以确定 3D关键点位置。然后,对检测到的关键点之间所有可能连接的置信度得分进行预测,形成肢体。最后,他们进行骨骼分组,将四肢分配给不同的人。
Mehta提出了开发了一种遮挡-鲁棒姿态图(occlusion - robust Pose- Maps, ORPM),将冗余遮挡信息包含在部分亲和性图中。此外,他们提出了第一个多人三维姿势数据集 MuCo3DHP,极大地促进了该领域的发展。
Fabbri提出了编码器-解码器的方式估计体积热图,并从中回归多人的三维姿态。
PandaNet是一个基于锚点的多人 3D姿
态估计单镜头模型。它直接预测每个锚点位置的2D/3D姿势。
SMAP估计了多个map,表示体根深度和零件在每个位置的相对深度。
hor它通过实例级、部分级和联合级对多人顺序关系进行分层估计。
[HMOR: Hierarchical multi-person ordinal relations for
monocular multi-person 3D pose estimation. In ECCV](HMOR: Hierarchical multi-person ordinal relations for
monocular multi-person 3D pose estimation. In ECCV)

### 基于模型的三维姿态估计
**通过这种方式,他们将3D位姿估计表示为估计SMPL的位姿和形状参数,一般框架是直接从单人2D RGB图像中估计相机和 SMPL参数。**
单人方法分为1解决3d数据短缺的问题,2促进基于模型的3d姿态估计更恰当的表示。
多人方法:1多阶段方法 2单次方法
解决数据缺失:人体网格恢复(HMR)[80]利用了从 2D
姿势和 3D动作捕捉(MoCap)数据集的未配对数据中学习的方法。为了引导模型从已有的数据中明确地学习、一些方法对二维图像的固有特性进行了监督。
A. Kanazawa, J. Zhang, P. Felsen, and J. Malik. 2019. Learning 3D human dynamics from video. In CVPR.从时间动态中学习,**训练一个3D人体动力学模型**来估计当前、过去和未来帧的 3D姿态。
Kocabas开发了一个名为**VIBE**的时间网络。在HMR之后,他们使用了一个运动鉴别器,以生成对抗的方式监督预测运动序列的合理性。通过门控循环单元(Gated Recurrent Units, GRUs),描述运动序列的 SMPL参数在每个时间步长被映射到一个潜在的表示。
**HuMoR**使用条件变分自动编码器建立时间先验,以优化输入运动的动力学和鲁棒性。
TexturePose除了利用时间信息外,还利用同一个人在多视点或相邻视频帧之间的外观一致性进行监控。身体纹理从2D图像映射到UV映射,这在语义上对齐多视图或顺序纹理。
Holo- Pose提出了一个多任务网络,它可以估计
DensePose、2D和3D关键点,以及基于零件的3D重建。提出了一种迭代优化的方法来改进基于模型的二维三维关键点的三维估计与 DensePose 的对齐。此外,**人体网格变形(Human Mesh Deformation, HMD)**利用额外的信息,包括身体关键点、轮廓和每像素阴影,来细化估计的 3D网格。通过层次网格投影和变形细化,人体网格与输入的 2D图像中的人很好地对齐。
简化smpl,通过将3D人体网格拟合到预测的 2D关键点上,并将再投影误差最小化,迭代地细化 3D人体网格。
**SPIN**:结合了基于回归和基于优化的方法的优点。他们利用 simplify来优化训练循环中的估计结果,以提供额外的3D监督。
模型表示:探索基于模型的三维姿态估计更合适的表示方法。
比如GraphCMR:利用基于图形的表示来回归 SMPL体网格。他们将SMPL模板网格的每个顶点作为图卷积网络的一个节点。每个节点附加一个图像特征向量,估计对应顶点的三维坐标。然后,可以从这些顶点估计 SMPL参数。
**I2L-MeshNet**提出了一种 image-to-lixel(线+像素)预测网络,该网络预测一维热图上的逐像素可能性,以回归每个网格顶点坐标。使用差分渲染器将估计的体网格渲染回 IUV图,并与输入进行比较以进行监督。
Sun利用双线性变换开发了一种骨架解纠缠表示,以解决二维位姿和其他细节的特征耦合问题。
METRO采用基于变压器的网络,从图像特征估计三维体网格。通过将 CNN特征附加到模板网格的节点和顶
点上,利用基于变压器的模型对三维坐标进行回归输出。
一些作品探索了全身 3D网格恢复的表现,包括脸和手。
SMPL+H:将三维手模型集成到 SMPL身体模
型中,共同恢复身体和手的三维网格。
Xiang提出了MTC方法,利用分离的CNN网络估计身体、手和脸,然后将Adam模型联合拟合到所有身体部位的输出上。
**SMPL- x:**将FLAME head 模型与SMPL+H相结
合,通过将模型拟合到三维扫描数据中来学习与姿态相关的混合形状。
SMPLify-X:通过将SMPL-X迭代拟合人脸、手和身体的二维关键点,恢复人体全身三维网格。
Sun:提出了一种解纠缠框架及其基于综合的学习管道,可以一次性同时估计多个身体部位的网格。
此外,其他作品开始探索显式的高级表示,以模拟图像中一些复杂的角色,如身体自接触、相机姿态
和地面约束。
**TUCH**明确地模仿和学习身体的自我接触。他们观察到,自接触的顶点在欧几里得距离上是接近的,而在测地线距离上彼此是遥远的。基于这一观察结果,设计了一种基于优化的方法,以避免相互渗透,同时鼓励联系。
**SPEC**估计部分透视相机参数,使三维网格恢复更加准确。了解相机的姿态有助于克服透视投影带来的失真。
**Rempe**提出通过检测脚地接触来细化三维人体运动序列,减少了脚滑和脚地渗透。
## 多人3D网格恢复
虽然单目三维场景中人体姿态和形状的估计已经取得了很大的进展,但处理存在**截断、环境遮挡**和**人-人遮挡**的多人场景仍然至关重要。**现有的多阶段方法为单人管道配备了一个 2D人探测器,以处理多人场景。**与 2D/3D关键点估算仅估算几十个人体关节不同,近期的作品也试图探索 3D网格恢复的特殊性。
Zanfir 等人提出在多人场景中使用自然场景约束。为了得到初始的三维体网格,他们将SMPL模型与从图像中估计出的三维姿态及其语义分割进行了拟合。
Jiang 等提出使用**多人相干重建**(coherent reconstruction of multiple human, CRMH)实现多人三维网格恢复。他们基于 **fast - rcnn**构建了他们的方法,其中 roi 对齐的特征被用来预测SMPL参数。具体来说,他们开发了一种可微分插值损失,以避免体网格之间的碰撞。
Sun 等人提出了一种实时的单阶段方法,**ROMP**,用于多人网格恢复。在ROMP中,人体的二维中心位置和三维网格分别表示为二维热图和网格参数图。这种基于中心的显式表示保证了像素级特征编码。
Sun等人在ROMP简洁的单阶段架构的基础上,进一步发展了 **BEV**,从单目图像回归人之间的相对位置,特别是在深度上。
他们开发了一个鸟瞰视图表示来明确地推断深度。他们还会逐渐丧失对年龄的意识,从而利用从婴儿到成人的 3D
体型空间。他们还创建了一个名为“相对人类”(Relative Human)的数据集,以有效地了解野外图像中的相对深度和年龄。
## 评价指标
二维姿态估计:
PCP (Percentage of Correct Parts)来衡量身体部位预测的准确性。
PCK (Percentage of Correct Keypoints)被广泛用于测量二维关键点预测。
AP (Average Precision)被广泛用于测量二维关键点预测。多人姿态估计,平均精度(AP)是通过测量对象关键点相似度(OKS)来计算的。
三维姿态估计:
关节平均位置误差(Mean Per Joint Position Error, MPJPE)
Procrustes Aligned MPJPE (PA-MPJPE)是对MPJPE 的一种改进,该方法通过将预测的位姿与以毫米为单位的地面真
实度刚性对齐得到。
3D PCK是PCK度量的 3D 版本。
平均联合角误差(MPJAE)测量的角度之间的预测关键点方向和地面真实方向的程度。
Procrustes Aligned MPJAE (PA-MPJAE)测量所有预测方向上由旋转矩阵归一化的 MPJAE。
## 数据集
### 2d
MPII 数据集是一个大规模的图像级数据集,包含丰富的活动和捕获环境。
Microsoft Common Objects in COntext (MSCOCO)数据集包含了用于对象检测、全景分割和关键点检测的注释。
PoseTrack 数据集是第一个大规模视频级多人姿态估计和跟踪数据集。
### 3d
Human3.6M是应用最广泛的单人 3D人体姿态基准。
HumanEva是一个单人 3D 姿势数据集,包含两个子集HumanEva- i 和HumanEva- ii。
mpi - info - 3dhp是在一个拥有 14 台摄像机的工作室中拍摄的,使用的是一种商业无标记的运动捕捉设备,用于获取地面真实的 3D姿势。
MoVi是一个大规模的单人视频数据集,具有同步的 3D身体姿势和网格标注。
3dw是一个单视图、多人、野外的 3D人体姿势数据集,包含 60 个视频序列(24 列、24 测试和 12 个验证),包含爬山、高尔夫和在海滩上放松等丰富的活动。
数据集在不同方法的姿态空间分析
不同活动在位姿空间和不同聚类中的分布如所示。位
姿空间的样本密度非常不均匀。大多数样本都是聚集在一起的。从四个基准的聚类结果中可以得出类似的结论。我们观察到大多数样本的 3D姿势接近行走或站立的姿势。在 Human3.6M中,除了行走和站立,坐着的样本也聚集在一起。**根据腿部运动所形成的聚类结果,证明下肢运动相对于较为复杂的上肢运动而言,相对简单而相似。**视频中
的演员往往会更多地移动他们的上半身而不是他们的腿。**用这些数据集训练的模型在估计上肢的 3D姿势方面比腿的效果更好。极端的姿势(即异常值)在样本中很少见。**位姿空间的分布是有偏差的,这限制了这些数据集的多样性。
未来方向
复杂姿态和拥挤场景的姿态估计。如体操、跳水和跳高等体育比赛中,运动员可能会在很短的时间内表现出极端的姿势。
3D Mesh Recovery 的基准、协议和工具箱。
逼真的身体与表情的脸,手,头发和衣服。
与3D世界和其他代理的事物互动
带有情感、语言和交流的虚拟数字人类一代。虚拟数字人是指具有数字外貌特征的虚拟人。
数据集附录
•2D姿态数据集:Leeds Sports Pose (LSP) Dataset来自Flickr,使用8项体育活动(田径、羽毛球、棒球、体操、
跑跑、足球、网球和排球)的标签。它包含 2,000 张图像,其中 1,000 张用于训练,1,000 张用于测试。每个人全
身有14个关键点。与这些新发布的数据集相比,LSP的规模相对较小。它是对单个人姿态估计的初始性能评估。
电影帧标记(FLIC)数据集包含了从好莱坞电影中收集的 5003张图像。他们在30部电影中每 10帧运行一个人探
测器。最初,2万名候选人会被众包市场亚马逊土耳其机器人(Amazon Mechanical Turk)选中,在上半身贴上 10个
关键点的标签。人被遮挡或严重非正面的图像会被过滤掉。最后,选取1,016幅图像作为测试集。
AI-Challenger 数据集,也称为人体骨骼系统关键点检测数据集(HKD),包含 300K高分辨率的关键点检测和中文字幕图像,81658 幅图像用于零拍识别。大型数据集有多人和各种姿势。每个人都有一个边界框和 14个关键点。整个数据集分为训练集、验证集、测试A集和测试B集,分别使用210K、30K、30K和30K的图像。由于其规模大、
分辨率高、场景丰富,AI-Challenger 数据集作为2D/3D姿态估计网络训练和姿态相关任务的辅助数据集已被广泛应用。
CrowdPose Dataset旨在更好地评估拥挤场景中的人体姿态估计方法。这些图像是通过测量人群指数从MSCOCO(个人子集)、MPII 和AI 挑战者中收集的。定义人群指数来评价图像的拥挤程度。通过 Crowd Index 对30K幅图像进行分析,最终选出 20K幅高质量图像。接下来,为大约 80K人注释 14个关键点和全身边界框。
J-HMDB Dataset,简称联合标注的HMDB,是HMDB51 数据库的一个子集,包含 51 个人类动作的超过 5100 个片段。J-HMDB数据集包含 928个剪辑,21个动作类别。每个动作类包含 36-55 个片段。每个剪辑包含 15-40 帧。亚马逊土耳其机器人上标注了 31838 张图片。多达 15个可见的身体关键点被标记,连同规模,视点,分割,木偶蒙版和木偶流。训练图像与测试图像的数量之比约为 7:3。J-HMDB数据集在视频姿态估计和动作识别中得到了广泛的应用。
Penn Action Dataset是另一个不受约束的视频数据集,包含包含 15 个动作的 2326 个视频剪辑。训练集和测试集都有 1163 个视频剪辑。该数据集包含各种类内角色外观、动作执行率、视点、时空分辨率和复杂的自然背景。注释通过部署在亚马逊土耳其机器人上的半自动化视频注释工具进行。每个人都带有带有 2D坐标、可见性和摄
像机视点的13个关键点。
3D姿态数据集:
SURREAL是一个通过在背景图像上渲染纹理SMPL模型的单人合成视频数据集。SMPL模型是由大量的3D运动捕捉数据驱动的。这样,SURREAL包含 6M RGB帧,包含深度、身体部位、光流、2D/3D
姿势和表面法线标注。由于身体纹理的低分辨率限制,渲染的 2D图像的真实感还有待提高。然而,通过综合生成数据,我们可以获得大量现实中难以获得的注释。如何合成更逼真的图像是一个很有价值的研究方向。
AMASS是一个大规模的动作捕捉(MoCap)数据集。它通过MoSh++将 15 个MoCap数据集转换为 SMPL/DMPL
参数,从而统一了 15 个MoCap 数据集[125]。它包含超过 40 小时的运动数据,涵盖超过 300 个对象,超过 110K
个运动。除了 3D身体姿势,它还包含真实的软组织运动。AMASS被广泛用于通过监督估计的姿态或运动的合理
性来建立一个先验的人体运动空间。
CMU Panoptic是一个大规模的多视图、多人三维姿态数据集。目前,它包含 65 个序列和 150 万个3D骨骼。他们建造了一个令人印象深刻的 360 度运动捕捉穹顶,其中包含 480个VGA摄像头(25 FPS), 31 个高清摄像头(30FPS), 10个Kinect2传感器(30 FPS)和 5个DLP投影机。特别是,它包含多人社交场景。多人三维姿态估计方法
通常提取部分数据进行评估。
Zanfir 等和 Jiang 等选择四种社交活动(Haggling, Mafia, Ultimatum,Pizza)的两个子序列(9600帧,分别来自HD camera 16和30)进行评价。它包含丰富的注释,如 2D/3D身体/手姿势。
然而并不是每个视频序列都被完全注释。
JTA (Joint Track Auto)是一个用于多人三维姿态评估的综合数据集。JTA是使用视频游戏侠盗猎车手 v生成的。它包含了 512个高清视频,行人在城市场景中行走。每个视频长度为 30秒,拍摄速度为 30 FPS,分辨率为 1920× 1080。它包含了视频中所有人的2D/3D身体姿势和身份标注。
本周总结
下周打算找个一篇具有代表性且相对简单、开源的文献作为baseline进行跑一跑。在知乎上看别个讲到的,深度学习代码学习,先从模块化的角度来看待,它作用是什么?有哪些重要的类和函数,这些类和函数在哪里调用,作用是什么;数据的输入输出的格式,看看别人是怎么处理的。然后就逐行进行看、分析,做笔记,就记不住就抄下来。要记到脑子里,避免因为信息检索技术、大模型技术带来的便利导致脑袋空心化。
这篇综述,讲了2d、3d姿态估计的技术、主要是从单目的角度讲,还有数据集的介绍,后续的工作就是去看2d、3d主流的一些方法的文献,搞明白别人的网络模型,创新点,贡献。现阶段看很多方法都是很蒙蔽的状态。我觉得需要多和师兄师姐们交流,帮他们打下手,快速了解到一次完整的科研是什么经历。对于自己的方向,我觉得是从轻量化、单方向的3维人体姿态估计入手。**3维的数据集就是个问题,缺少室外的数据集,很多方法都是采用弱监督、无监督来进行处理的,因为标注数据集就很贵也很麻烦,深度模糊也是三维面临的困境。**其余的我还没有太多思路,因为到现在,我都没有完整地复现过一篇这个领域的文章。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









