






文章目录
摘要
本周在深度学习方面,对神经网络中卷积层、池化层的概念、以及LeNet、AlexNet、VGG主流模型进行了学习,在OPENCV方面,继续学习了canny边缘检测算法、以及各类算子的作用。
This week, I studied the concepts of convolutional layers and pooling layers in neural networks, and studied mainstream models like LeNet, AlexNet, and VGG. In the aspect of OpenCV, I continued my learning on the Canny edge detection algorithm and explored the functions of various operators.
深度学习
读写文件
保存训练的模型, 以备将来在各种环境中使用,对于单个张量,我们可以直接调用load和save函数分别读写它们。
# 我们需要给共享层一个名称,以便可以引用它的参数
shared = nn.Linear(8, 8)
net = nn.Sequential(nn.Linear(4, 8), nn.ReLU(),
shared, nn.ReLU(),
shared, nn.ReLU(),
nn.Linear(8, 1))
net(X)
# 检查参数是否相同
print(net[2].weight.data[0] == net[4].weight.data[0])
net[2].weight.data[0, 0] = 100
# 确保它们实际上是同一个对象,而不只是有相同的值
print(net[2].weight.data[0] == net[4].weight.data[0])
在实例化中,net(x)其实是相当于调用call函数,是执行了forward函数的。
forward函数是在执行向前传播的时候调用的
torch.save()储存函数
torch.load()储存函数
在GPU上训练神经网络
在PyTorch中,每个数组都有一个设备(device), 我们通常将其称为环境(context)。 默认情况下,所有变量和相关的计算都分配给CPU。 有时环境可能是GPU。 当我们跨多个服务器部署作业时,事情会变得更加棘手。 通过智能地将数组分配给环境, 我们可以最大限度地减少在设备之间传输数据的时间。 例如,当在带有GPU的服务器上训练神经网络时, 我们通常希望模型的参数在GPU上。
存储在GPU上的张量:
X = torch.ones(2, 3, device=try_gpu())
gpu之间 gpu到cpu上挪动数据是非常慢的
net = nn.Sequential(nn.Linear(3, 1))
net = net.to(device=try_gpu())
将神经网络挪动到第0号gpu上
def try_gpu(i=0): #@save
"""如果存在,则返回gpu(i),否则返回cpu()"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def try_all_gpus(): #@save
"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]"""
devices = [torch.device(f'cuda:{i}')
for i in range(torch.cuda.device_count())]
return devices if devices else [torch.device('cpu')]
try_gpu(), try_gpu(10), try_all_gpus()
选择GPU 的三要素: 显存 每秒计算浮点数的能力 价格
卷积层

- 平移不变性(translation invariance):不管检测对象出现在图像中的哪个位置,神经网络的前面几层应该对相同的图像区域具有相似的反应,即为“平移不变性”。
- 局部性(locality):神经网络的前面几层应该只探索输入图像中的局部区域,而不过度在意图像中相隔较远区域的关系,这就是“局部性”原则。最终,可以聚合这些局部特征,以在整个图像级别进行预测。
在多层感知机上,因为是先输入的图像,因此输入的值是一个二维矩阵,而输出的值也是一个二维矩阵,因此首先是把权重w变成一个四阶矩阵。
全连接层形式化表示为:
[
H
]
i
,
j
=
[
U
]
i
,
j
+
∑
k
∑
l
[
W
]
i
,
j
,
k
,
l
[
X
]
k
,
l
\begin{aligned} \left[\mathbf{H}\right]_{i, j} &= [\mathbf{U}]_{i, j} + \sum_k \sum_l[\mathsf{W}]_{i, j, k, l} [\mathbf{X}]_{k, l}\\ &\end{aligned}
[H]i,j=[U]i,j+k∑l∑[W]i,j,k,l[X]k,l
将w矩阵用v来替代,这两个矩阵之间存在一一对应关系
,相应的x的下标也发生改变。
[
H
]
i
,
j
=
[
U
]
i
,
j
+
∑
a
∑
b
[
V
]
i
,
j
,
a
,
b
[
X
]
i
+
a
,
j
+
b
.
\begin{aligned} \left[\mathbf{H}\right]_{i, j} &= [\mathbf{U}]_{i, j} + \sum_a \sum_b [\mathsf{V}]_{i, j, a, b} [\mathbf{X}]_{i+a, j+b}.\end{aligned}
[H]i,j=[U]i,j+a∑b∑[V]i,j,a,b[X]i+a,j+b.
而引入了上述的第一个原则,平移不变性。再通过引入
[
V
]
i
,
j
,
a
,
b
=
[
V
]
a
,
b
[\mathsf{V}]_{i, j, a, b} = [\mathbf{V}]_{a, b}
[V]i,j,a,b=[V]a,b
从而全连接层定义为:
[
H
]
i
,
j
=
u
+
∑
a
∑
b
[
V
]
a
,
b
[
X
]
i
+
a
,
j
+
b
.
[\mathbf{H}]_{i, j} = u + \sum_a\sum_b [\mathbf{V}]_{a, b} [\mathbf{X}]_{i+a, j+b}.
[H]i,j=u+a∑b∑[V]a,b[X]i+a,j+b.
仅通过改变a、b的值,可以覆盖整个图像,但又不会改变V矩阵和U的值。
局部性的引入是:
为了收集用来训练参数
[
H
]
i
,
j
[\mathbf{H}]_{i, j}
[H]i,j的相关信息,我们不应偏离到距
(
i
,
j
)
(i, j)
(i,j)很远的地方。这意味着在
∣
a
∣
>
Δ
|a|> \Delta
∣a∣>Δ或
∣
b
∣
>
Δ
|b| > \Delta
∣b∣>Δ的范围之外,我们可以设置
[
V
]
a
,
b
=
0
[\mathbf{V}]_{a, b} = 0
[V]a,b=0。因此,我们可以将
[
H
]
i
,
j
[\mathbf{H}]_{i, j}
[H]i,j重写为
[ H ] i , j = u + ∑ a = − Δ Δ ∑ b = − Δ Δ [ V ] a , b [ X ] i + a , j + b . [\mathbf{H}]_{i, j} = u + \sum_{a = -\Delta}^{\Delta} \sum_{b = -\Delta}^{\Delta} [\mathbf{V}]_{a, b} [\mathbf{X}]_{i+a, j+b}. [H]i,j=u+a=−Δ∑Δb=−Δ∑Δ[V]a,b[X]i+a,j+b.
总的来说,卷积层就是特殊的全连接层。
卷积层将输入和核矩阵进行交叉相关、加上偏移后得到输出。核矩阵和偏移是可学习的参数。核矩阵的大小是超参数。
互相关运算
在二维互相关运算中,卷积窗口从输入张量的左上角开始,从左到右、从上到下滑动。
当卷积窗口滑动到新一个位置时,包含在该窗口中的部分张量与卷积核张量进行按元素相乘,得到的张量再求和得到一个单一的标量值,由此我们得出了这一位置的输出张量值。
例子:
def corr2d(X, K): #@save
"""计算二维互相关运算"""
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
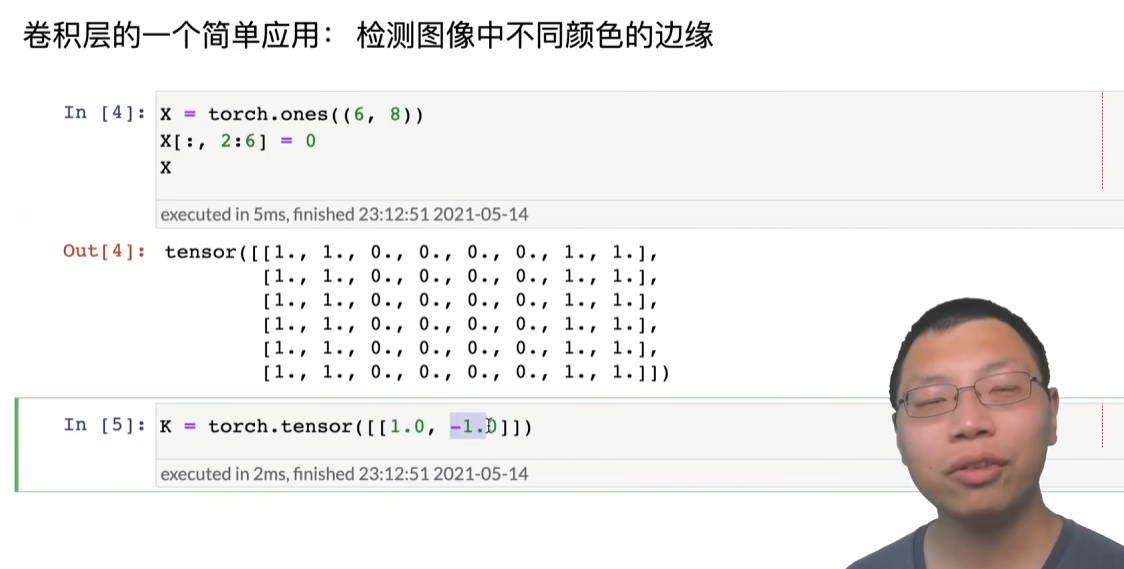
X = torch.ones((6, 8))
X[:, 2:6] = 0
K = torch.tensor([[1.0, -1.0]])
Y = corr2d(X, K)
通过构建卷积核为[[1.0,-1.0]]的张量,与原图像矩阵做互相关运算。但是K只可以检测垂直边缘。

通过梯度下降的来确定卷积核
先构造一个卷积层,并将其卷积核初始化为随机张量。接下来,在每次迭代中,我们比较Y与卷积层输出的平方误差,然后计算梯度来更新卷积核。为了简单起见,我们在此使用内置的二维卷积层,并忽略偏置。
# 构造一个二维卷积层,它具有1个输出通道和形状为(1,2)的卷积核
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False)
# 这个二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 其中批量大小和通道数都为1
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
lr = 3e-2 # 学习率
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
conv2d.zero_grad()
l.sum().backward()
# 迭代卷积核
conv2d.weight.data[:] -= lr * conv2d.weight.grad
if (i + 1) % 2 == 0:
print(f'epoch {i+1}, loss {l.sum():.3f}')
填充
在应用多层卷积时,我们常常丢失边缘像素。 由于我们通常使用小卷积核,因此对于任何单个卷积,我们可能只会丢失几个像素。 但随着我们应用许多连续卷积层,累积丢失的像素数就多了。解决这个问题的简单方法即为填充(padding):在输入图像的边界填充元素。

import torch
from torch import nn
# 为了方便起见,我们定义了一个计算卷积层的函数。
# 此函数初始化卷积层权重,并对输入和输出提高和缩减相应的维数
def comp_conv2d(conv2d, X):
# 这里的(1,1)表示批量大小和通道数都是1
X = X.reshape((1, 1) + X.shape)
Y = conv2d(X)
# 省略前两个维度:批量大小和通道
return Y.reshape(Y.shape[2:])
# 请注意,这里每边都填充了1行或1列,因此总共添加了2行或2列
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)
X = torch.rand(size=(8, 8))
comp_conv2d(conv2d, X).shape
步幅
步幅是指行列的滑动步长,在计算互相关时,卷积窗口从输入张量的左上角开始,向下、向右滑动。 在前面的例子中,我们默认每次滑动一个元素。 但是,有时候为了高效计算或是缩减采样次数,卷积窗口可以跳过中间位置,每次滑动多个元素。
通常,当垂直步幅为
s
h
s_h
sh、水平步幅为
s
w
s_w
sw时,输出形状为
⌊ ( n h − k h + p h + s h ) / s h ⌋ × ⌊ ( n w − k w + p w + s w ) / s w ⌋ . \lfloor(n_h-k_h+p_h+s_h)/s_h\rfloor \times \lfloor(n_w-k_w+p_w+s_w)/s_w\rfloor. ⌊(nh−kh+ph+sh)/sh⌋×⌊(nw−kw+pw+sw)/sw⌋.

conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
comp_conv2d(conv2d, X).shape
conv2d = nn.Conv2d(1, 1, kernel_size=(3, 5), padding=(0, 1), stride=(3, 4))
comp_conv2d(conv2d, X).shape
多输入通道
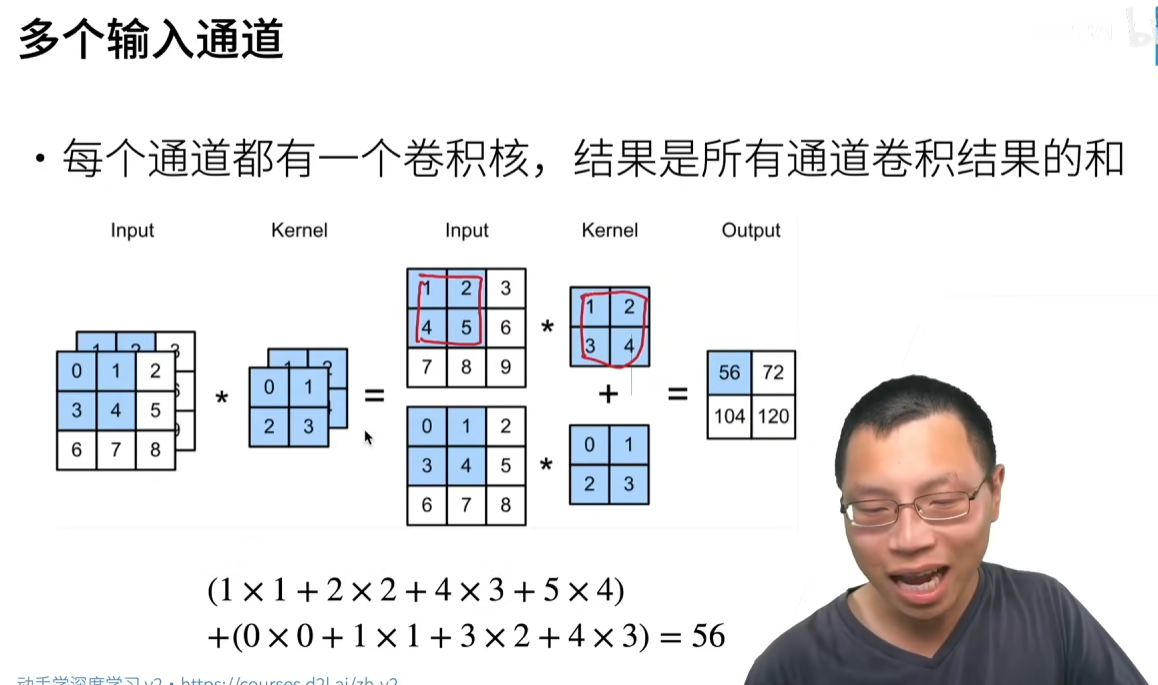
当输入包含多个通道时,需要构造一个与输入数据具有相同输入通道数的卷积核,以便与输入数据进行互相关运算。假设输入的通道数为
c
i
c_i
ci,那么卷积核的输入通道数也需要为
c
i
c_i
ci。如果卷积核的窗口形状是
k
h
×
k
w
k_h\times k_w
kh×kw,那么当
c
i
=
1
c_i=1
ci=1时,我们可以把卷积核看作形状为
k
h
×
k
w
k_h\times k_w
kh×kw的二维张量。
然而,当 c i > 1 c_i>1 ci>1时,我们卷积核的每个输入通道将包含形状为 k h × k w k_h\times k_w kh×kw的张量。将这些张量 c i c_i ci连结在一起可以得到形状为 c i × k h × k w c_i\times k_h\times k_w ci×kh×kw的卷积核。由于输入和卷积核都有 c i c_i ci个通道,我们可以对每个通道输入的二维张量和卷积核的二维张量进行互相关运算,再对通道求和(将 c i c_i ci的结果相加)得到二维张量。这是多通道输入和多输入通道卷积核之间进行二维互相关运算的结果。
import torch
from d2l import torch as d2l
def corr2d_multi_in(X, K):
# 先遍历“X”和“K”的第0个维度(通道维度),再把它们加在一起
return sum(d2l.corr2d(x, k) for x, k in zip(X, K))
X = torch.tensor([[[0.0, 1.0, 2.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]],
[[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0]]])
#两个通道的图
K = torch.tensor([[[0.0, 1.0], [2.0, 3.0]], [[1.0, 2.0], [3.0, 4.0]]])#两个通道的卷积核
#3*3 图片与 2*2核进行互相关运算
corr2d_multi_in(X, K)
多输出通道

用 c i c_i ci和 c o c_o co分别表示输入和输出通道的数目,并让 k h k_h kh和 k w k_w kw为卷积核的高度和宽度。为了获得多个通道的输出,我们可以为每个输出通道创建一个形状为 c i × k h × k w c_i\times k_h\times k_w ci×kh×kw的卷积核张量,这样卷积核的形状是 c o × c i × k h × k w c_o\times c_i\times k_h\times k_w co×ci×kh×kw。在互相关运算中,每个输出通道先获取所有输入通道,再以对应该输出通道的卷积核计算出结果。卷积核增加维度,即可实现输出通道数增加。
每个输出通道可以识别特定模式,输入通道核识别并组合输入中的模式。
def corr2d_multi_in_out(X, K):
# 迭代“K”的第0个维度,每次都对输入“X”执行互相关运算。
# 最后将所有结果都叠加在一起
return torch.stack([corr2d_multi_in(X, k) for k in K], 0)
#stack在0得维度上,合并起来
K = torch.stack((K, K + 1, K + 2), 0)
K.shape
输出结果:
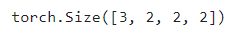
corr2d_multi_in_out(X, K)

1*1 卷积层
1*1卷积层不识别空间模式(它只看原图像那个像素点),只是用来融合通道。相当于输入形状为
N
h
N
w
∗
C
i
NhNw*Ci
NhNw∗Ci,权重为
C
o
∗
C
i
Co*Ci
Co∗Ci的全连接层。
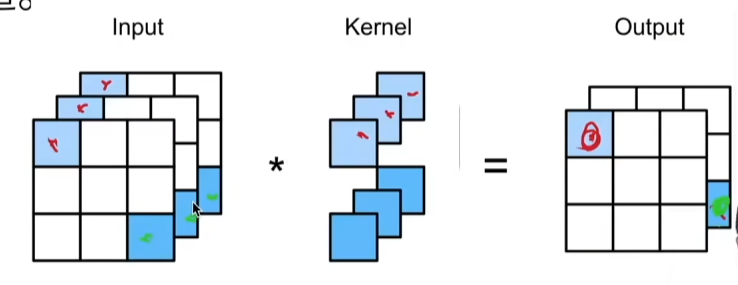
代码实现:
def corr2d_multi_in_out_1x1(X, K):
c_i, h, w = X.shape
c_o = K.shape[0]
X = X.reshape((c_i, h * w))
K = K.reshape((c_o, c_i))
# 全连接层中的矩阵乘法
Y = torch.matmul(K, X)
return Y.reshape((c_o, h, w))
X = torch.normal(0, 1, (3, 3, 3))
K = torch.normal(0, 1, (2, 3, 1, 1))
Y1 = corr2d_multi_in_out_1x1(X, K)
Y2 = corr2d_multi_in_out(X, K)
assert float(torch.abs(Y1 - Y2).sum()) < 1e-6
#说明Y1和Y2的差异小于1e-6,可以理解成一样了、

上图是一个二维卷积层输入、核矩阵、偏差矩阵、输出矩阵模型,说明了就算卷积层输入样本不大的情况下,经过6个矩阵相乘来计算,对应的浮点数计算数也是非常大的。
输出通道数是卷积层的超参数。
每一个输入通道都有独立的二维卷积核,所有通道结果相加得到一个输出通道结果。
每个输出通道都有独立的三维卷积核。
池化层
池化层能允许像素做一点偏移,池化层和卷积层类似,都有填充和步幅。但没有可学习的参数,在多输入通道都做一次池化层,得到输出通道,因此输出通道数等于输入通道数。
一般来讲,池化层都是用最大池化层进行操作,但也有平均池化层。

因此可以看到,最大池化层是把像素最强的模型信号提取出来,而平均池化层的信号强度较弱,但是比较整体比较柔和。
主要作用是缓解卷积层的位置敏感性。
实现池化层的正向传播。
import torch
from torch import nn
from d2l import torch as d2l
def pool2d(X, pool_size, mode='max'):
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))#和卷积层一样
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y
X = torch.arange(16, dtype=torch.float32).reshape((1, 1, 4, 4))
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)
pool2d = nn.MaxPool2d((2, 3), stride=(2, 3), padding=(0, 1))
pool2d(X)
输出结果

在处理多通道输入数据时,汇聚层在每个输入通道上单独运算。
X = torch.cat((X, X + 1), 1)
pool2d = nn.MaxPool2d(3, padding=1, stride=2)
pool2d(X)

LeNet
LeNet是早起成功的神经网络,由两个卷积层,两个池化层,和三个全连接层组成的。
它先用卷积层学习图像的空间信息,再用池化层降低位置敏感度,最后用全连接层转化到类别的空间。
卷积编码器:由两个卷积层组成;
全连接层密集块:由三个全连接层组成。
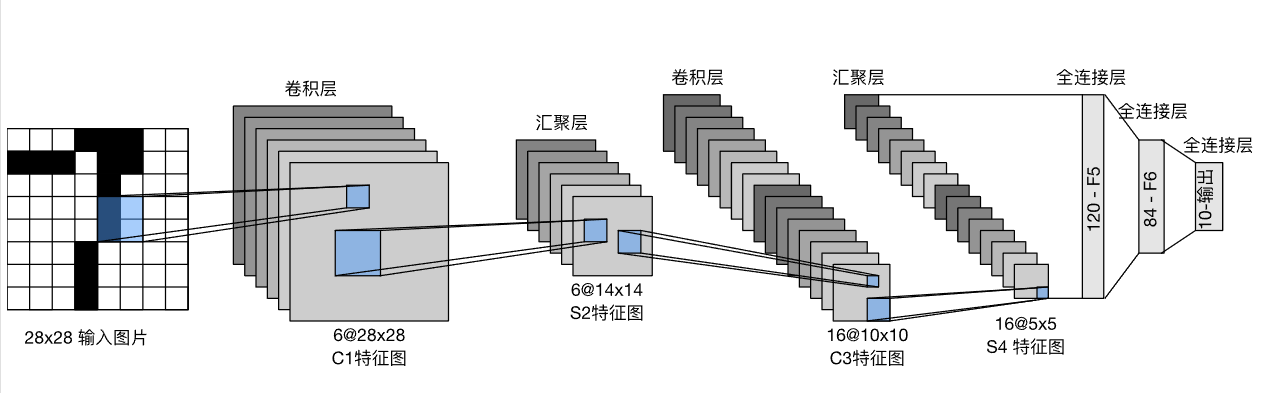
# LeNet(LeNet-5) 由两个部分组成:卷积编码器和全连接层密集块
import torch
from torch import nn
from d2l import torch as d2l
class Reshape(torch.nn.Module):
def forward(self,x):
return x.view(-1,1,28,28) # 批量数自适应得到,通道数为1,图片为28X28
net = torch.nn.Sequential(
Reshape(), nn.Conv2d(1,6,kernel_size=5,padding=2),nn.Sigmoid(),
nn.AvgPool2d(2,stride=2),
nn.Conv2d(6,16,kernel_size=5),nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2,stride=2),nn.Flatten(),
nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),
nn.Linear(120, 84), nn.Sigmoid(),
nn.Linear(84,10))
X = torch.rand(size=(1,1,28,28),dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t',X.shape) # 上一层的输出为这一层的输入
可以看到每一层输出的变化:

LeNet第二个卷积层的通道数增加到了16,通过通道数来增加像素匹配模型的多样性,但总体的信息量还是一个被消减的过程。
总结就是说,不断的把空间信息压缩压缩,通道数不断增加,也就是说把抽出来的压缩的信息放到不同的通道里去,最后MLP把这些所有的模式拿出来,然后做全连接输出。
用GPU来实现
LeNet在Fashion-MNIST数据集上的表现
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
# 对evaluate_accuracy函数进行轻微的修改
def evaluate_accuracy_gpu(net, data_iter, device=None):
"""使用GPU计算模型在数据集上的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # net.eval()开启验证模式,不用计算梯度和更新梯度
if not device:
device = next(iter(net.parameters())).device # 看net.parameters()中第一个元素的device为哪里
metric = d2l.Accumulator(2)
for X, y in data_iter:
if isinstance(X,list):
X = [x.to(device) for x in X] # 如果X是个List,则把每个元素都移到device上
else:
X = X.to(device) # 如果X是一个Tensor,则只用移动一次,直接把X移动到device上
y = y.to(device)
metric.add(d2l.accuracy(net(X),y),y.numel()) # y.numel() 为y元素个数,把分类正确的y元素存入metric(1)中,y所有元素个数存入metric(2)中;
return metric[0]/metric[1] #正确数/总数=正确率
# 为了使用GPU,还需要一点小改动
train_ch6是在GPU上计算的函数
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):
"""Train a model with a GPU"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight) # 根据输入、输出大小,使得随即初始化后,输入和输出的的方差是差不多的
net.apply(init_weights)
print('training on',device)
net.to(device) def try_gpu(i=0): #@save
"""如果存在,则返回gpu(i),否则返回cpu()"""
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def try_all_gpus(): #@save
"""返回所有可用的GPU,如果没有GPU,则返回[cpu(),]"""
devices = [torch.device(f'cuda:{i}')
for i in range(torch.cuda.device_count())]
return devices if devices else [torch.device('cpu')]
try_gpu(), try_gpu(10), try_all_gpus()
optimizer = torch.optim.SGD(net.parameters(),lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch',xlim=[1,num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
metric = d2l.Accumulator(3)
net.train()
for i, (X,y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)#挪到内存上
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat,y),X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if(i+1) % (num_batches//5) == 0 or i == num_batches - 1:
animator.add(epoch + (i+1) / num_batches,
(train_l, train_acc, None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f},train acc {train_acc:.3f},'
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec'
f'on{str(device)}')
李沐Accumulator类的理解:
class Accumulator:
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
#n是需要累加变量的个数
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
#*arg是传入的参数可以是个不定长的参数列表
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
train函数与以前的train函数主要的区别就是将X,Y挪到GPU上、还有NET的参数也要挪到GPU上。
AlexNet
SVM
在深度学习之前,2001年使用的是核方法,用核函数来计算相关性,线性模型就是做内积,在高维空间中,通过变换空间,把空间拉成我们想要的样子,通过核函数来把问题变成凸优化问题,因此能求出显示解。
几何学
在2000年的时候,计算机视觉主要关心的是几何学,把计算机视觉问题描述成几何学问题。
特征工程
另一种预测这个领域发展的方法————观察图像特征的提取方法。在2012年前,图像特征都是机械地计算出来的。事实上,设计一套新的特征函数、改进结果,并撰写论文是盛极一时的潮流。
SIFT :cite:Lowe.2004
SURF :cite:Bay.Tuytelaars.Van-Gool.2006
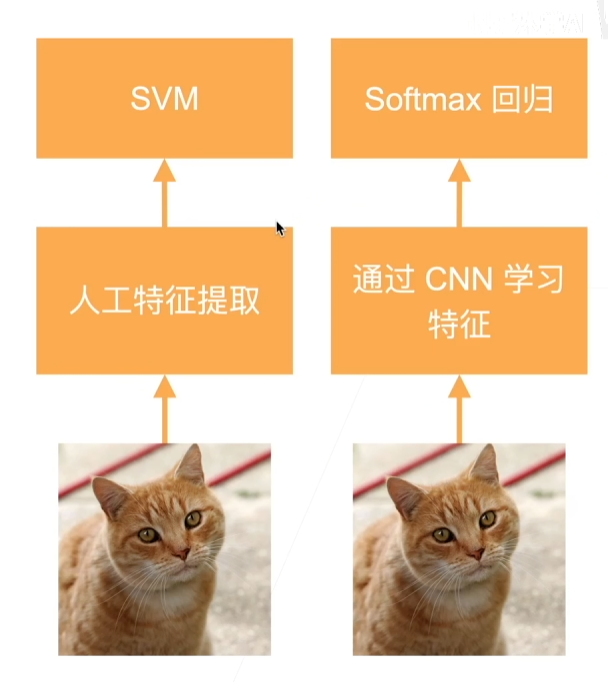
在深度学习之前,对于一张图片是进行人工特征提取,主要是怎么去做人工特征提取,然后再用支持向量机来实现。
在AlexNet中,最后一层是用softmax回归,之前所有层都是用CNN学习特征。也就是说通过CNN学习出来的特征,很有可能就是softmax想要的。
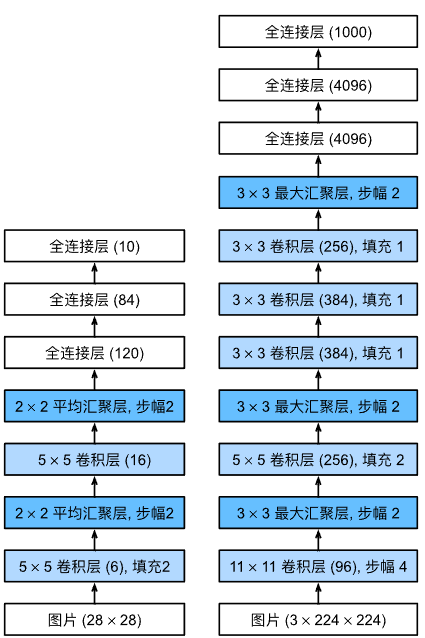
AlexNet与LeNet相比多了很多卷积层,并且极大地提升了通道数。使得图像匹配的模式会更多。激活函数由sigmoid变到了ReLu,能减缓梯度消失。并且在隐藏全连接层后加入了丢弃层。
AlexNet还进行了数据增强:假设采样了一只猫的图片,它不会直接将这个图片拿进去学习,而是将这个图片随机地截取图片、或者随机进行亮度、灰度、色温的变换,卷积对像素位置、光照是比较敏感的,通过以上的方式,降低其卷积的敏感度。
AlexNet与LeNet复杂度对比
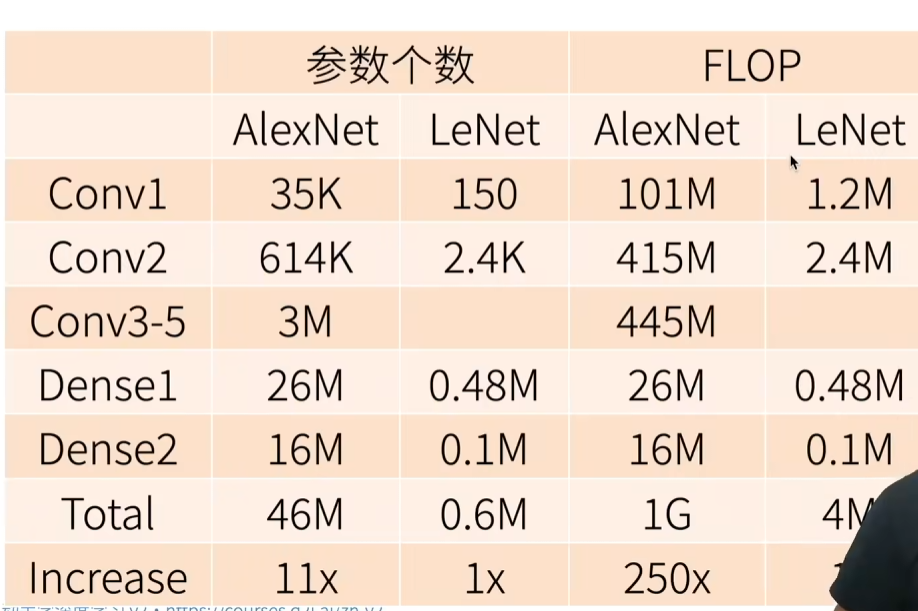
可以看出AlexNet与LeNet的主要差距不仅是在参数个数上,跟主要体现在浮点数计算量的差异上,虽然参数个数上面只相差了10倍样子,但是与AlexNet相比LeNet的浮点数计算量是其250分之一。
# 深度卷积神经网络 (AlexNet)
import torch
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Conv2d(1,96,kernel_size=11,stride=4,padding=1),nn.ReLU(), # 数据集为fashion_mnist图片,所以输入通道为1,如果是Imagnet图片,则通道数应为3
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(96,256,kernel_size=5,padding=2),nn.ReLU(), # 256为输出通道数
nn.MaxPool2d(kernel_size=3,stride=2),
nn.Conv2d(256,384,kernel_size=3,padding=1),nn.ReLU(),
nn.Conv2d(384,384,kernel_size=3,padding=1),nn.ReLU(),
nn.Conv2d(384,256,kernel_size=3,padding=1),nn.ReLU(),
nn.MaxPool2d(kernel_size=3,stride=2),nn.Flatten(),
nn.Linear(6400,4096),nn.ReLU(),nn.Dropout(p=0.5),
#丢弃一下神经单元,丢弃概率设置为0.5
nn.Linear(4096,4096),nn.ReLU(),nn.Dropout(p=0.5),
nn.Linear(4096,10))
X = torch.randn(1,1,224,224)
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'Output shape:\t', X.shape)
在通过对AlexNet论文的阅读后,发现了这样的一句话:“一个大型的深度卷积神经网络能够使用纯监督学习在一个极具挑战性的数据集上取得破纪录的结果。值得注意的是,如果移除单个卷积层,我们的网络性能会下降。
例如,删除任何中间层都会导致网络 to p -1 性能损失约 2%。所以深度对于实现我们的结果真的很重要。”
但是想问的是,AlexNet为什么新增加了3层384输出的卷积层,是有什么道理吗?为什么不增加更多或者更少的卷积层?这种网络设计是通过多少尝试试出来的?还有什么理论基础支撑选择设计呢?
深度卷积神经,在对研究成果宣传时,是需要采用比较新颖、夸张的词汇,能够吸引更多人的关注。
VGG
用窄而深的模型来跑,效果更好。使用VGG块来代替AlexNet模型,把vgg块串在一起。VGG本质就是一个更大更深的AlexNet的网络。
疑问是在与为什么深度学习需要那么多层,为什么层数越多效果越好?
每一个神经元相当于一个线性分类器,所以单层神经网络把decision region剖分成两个半平面;每个神经元后面带有一个非线性的激活函数,输入经过一层神经元的非线性映射相当于对原始的输入空间做了一种非线性扭曲,在扭曲后的空间上再用一层神经元做半平面的剖分,那么两层神经网络综合的作用相当于把decision region 做凸多边形那种划分。
增加深度比增加宽度要好,因为增加深度可以分层,模块化,不同层学习不同难度的信息抽取,提升模型的学习能力。
OpenCV
计算梯度时,使用不同算子来处理图像,得到的效果是不同的。
laplacian 算子
Laplacian算子是一种具有旋转不变性的各向同性的二阶微分算子,这个算子是四周减去中间,由于它对噪音很敏感所以很少单独用。
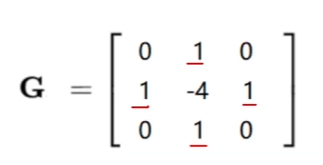
Roberts算子
Roberts算子即交叉微分算子,是基于交叉差分的梯度算子。此算法通过局部差分来计算检测图像的边缘线条,对噪声敏感。
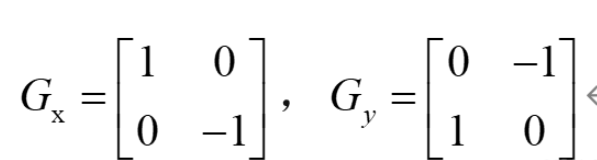
对于图像而言,如果im表示图像像素矩阵,则可以如下计算(i,j)点处的特征值:
im(i,j)=|im(i,j)-im(i+1,j+1)|+|im(i+1,j)-im(i,j+1)|
canny边缘检测算法
Canny边缘检测流程:
- 使用高斯滤波器,以平滑图像,滤除噪声。
- 计算图像中每个像素点的梯度强度和方向。
- 应用非极大值(Non-Maximum Suppression)抑制,以消除边缘检测带来的杂散响应。
- 应用双阈值(Double-Threshold)检测来确定真实的和潜在的边缘。
- 通过抑制孤立的弱边缘最终完成边缘检测。
非极大值抑制
有两种方法来实现,第一种是线性插值法,首先是找到该像素点周围的八个点,然后以该像素点的梯度方向作直线,交周围八点所形成的正方形的边框线,就会得到两个交点。
然后根据其交点的临近两个点的梯度值和它们距离交点的距离所构成的权重,来计算出交点的梯度值。
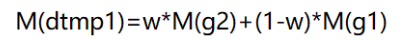
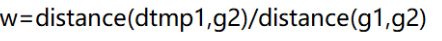
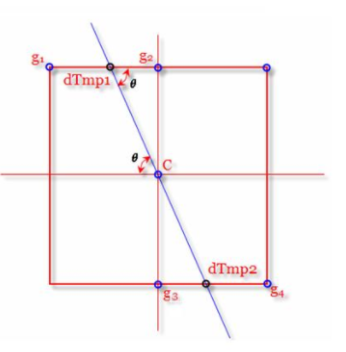
w是g2点距离交点dTmp1的距离/g1g2之间的总距离。
同上求出交点dTmp2的梯度值,然后与C点比较,看是否C的梯度值是最大的,从而判断C是否为边缘。
① C 点的梯度和方向可以通过前一步算出来。
② C 点的梯度是不是一个极大值点,应该是去跟它的临近点去比较。
③ 利用 C 点梯度的方向,可以得到上面有一个交点 Q,下面有一个交点 Z,如果 C 点的梯度比 Q 和 Z 都大,那么 C 就是极大值点,其中 Q 和 Z 的梯度值通过线性差值法来计算。
④ 如果 C 的梯度是极大值点,那么 C 就是边缘点。否则 C 不是极大值点,就会被抑制。
双阈值检测
设置两个阈值,最大值maxVal和最小值minVal,其作用为对比像素点的梯度,若其大于maxVal,则处理为边界,若小于maxVal,但是大于minVal,但是与边界是相连的,就保留为边界,否则舍弃。若梯度值小于minVal,直接舍弃。
代码实现:
import cv2
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
def cv_show(img,name):
cv2.imshow(name,img)
cv2.waitKey()
cv2.destroyAllWindows()
img=cv2.imread('01_Picture/07_Lena.jpg',cv2.IMREAD_GRAYSCALE)
v1 = cv2.Canny(img,80,150) # 第二个参数为minVal,第三个参数为maxVal
v2 = cv2.Canny(img,50,100)
res = np.hstack((v1,v2))
cv_show(res,'res')
img = cv2.imread('01_Picture/08_Car.png',cv2.IMREAD_GRAYSCALE)
v1 = cv2.Canny(img,120,250) # 第二个参数为minVal,第三个参数为maxVal
v2 = cv2.Canny(img,50,100)
res = np.hstack((v1,v2))
cv_show(res,'res')
总结
对深度学习的学习终于到了卷积神经网络这一步,自己最开始不太理解这些模型设计、层数的应用是如何想出来的,后面知道神经网络的模型更多地还是通过不断实验检验训练效果从而推导出的,没有严格的数学证明,往往缺少可解释性,目前许多神经网络模型还是可以被称为黑盒模型。















 203
203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









