







 本文详细介绍了机器学习的工作流程,包括数据清洗、特征工程、模型选择、交叉验证和超参数优化。强调了模型优化的重要性,讨论了模型状态、权重分析、bad-case分析和模型融合等技巧。通过案例分析,展示了如何在实际项目中应用这些方法。
本文详细介绍了机器学习的工作流程,包括数据清洗、特征工程、模型选择、交叉验证和超参数优化。强调了模型优化的重要性,讨论了模型状态、权重分析、bad-case分析和模型融合等技巧。通过案例分析,展示了如何在实际项目中应用这些方法。
七月在线4月机器学习算法班课程笔记——No.7
前言
我们知道,机器学习的过程是非常繁琐的。上一篇介绍了机器学习中特征处理重要而耗时,然而特征处理仅属于机器学习前序的工作内容。特征工程之后,需要选择机器学习模型、交叉验证、寻找最佳超参数等建模步骤。搭建模型之后呢,还需要进行模型的优化,模型调优是实际生产中一个必要的环节,也是不断去改进的一个事情。
这一篇会以小的数据集为例,讲一下机器学习在实际项目中的工作流程,介绍如何分析模型状态、分析权重、分析bad-case以及如何做模型融合。哈,开启宏观的认知!
1. 前序工作流程
1.1 数据部分
- 数据清洗:丢掉不可信的样本; 不用缺省值极多的字段。
- 数据采样:采用下/上采样保证样本均衡。
1.2 特征工程
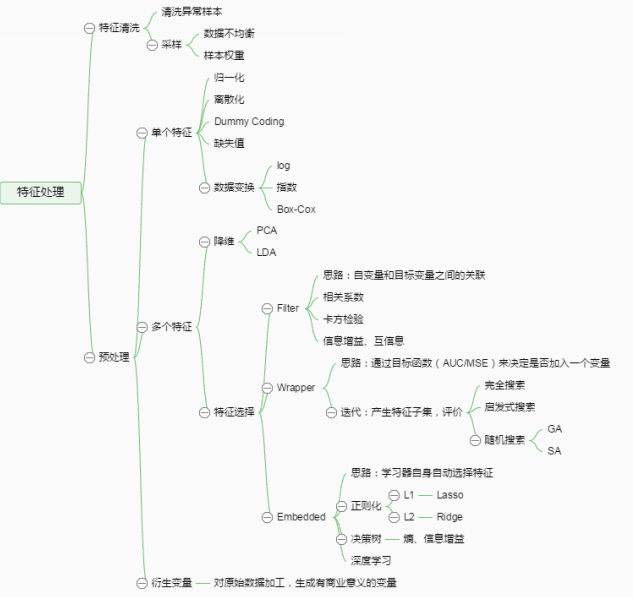
上一篇笔记重点讲了特征工程中的特征处理和特征选择。特征处理包括数值型、类别型、时间型、文本型、统计型和组合特征;特征选择包括过滤型、包裹型和嵌入型,在这里不再赘述。下图总结了特征处理中的流程和方法。
1.3 模型选择
准备好了训练数据,就可以根据特征选择机器学习的模型了。模型选择有两种理解方式。第一种含义是选择哪一种模型;第二种含义是确定了模型,如何指定参数。
1)第一种理解:
第一种含义是选择哪一种模型?
经常会有这样的问题:“我准备好了数据,计划做分类或连续值预测,用什么模型比较好呢?”但是实际上,没有一个模型是万能的,都有各自的适用场景。这里介绍一下scikit-learn,scikit-learn是一个用Python语言编写机器学习库的开源站点。通常解决机器学习问题最难的部分就是找到合适的估计器,下面的流程图清晰地给出了解决问题的路径,进入scikit-learn官网,可以单击任何一个估计器,看到它的说明文档。
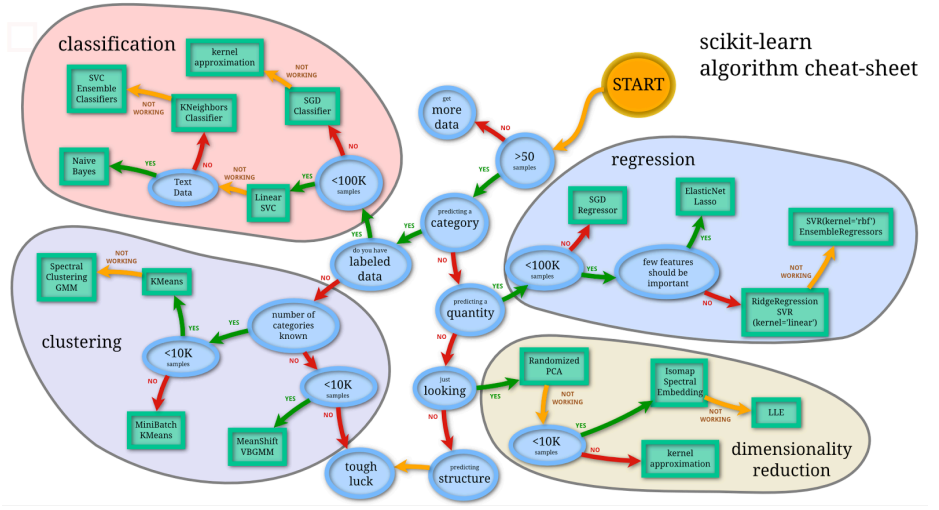
分析这张图,把模型选择分为几个步骤进行:
1. 准备好数据,然后看数据的样本量有多大。
样本量很小 → 就需要采集更多的数据,不然难以得到泛化的关系,容易造成过拟合。或者使用人工规则解决问题。
样本量足够 → 步骤2.
2. 判断问题类型是 连续值预测or离散值预测。
离散值预测
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









