






Python
# 加载模块
import pandas
import requests
from bs4 import BeautifulSoup
# 伪装报头
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'
}
# 定义get_info,获取排名情况、歌手、歌名、歌曲链接、歌曲时长
def get_info(url):
destination = requests.get(url, headers = headers)
soup = BeautifulSoup(destination.text, 'lxml')
ranks = soup.select('span.pc_temp_num')
titles = soup.select('div.pc_temp_songlist ul li > a')
times = soup.select('span.pc_temp_time')
total = []
for rank, title, time in zip(ranks, titles, times):
data = { 'rank' : rank.get_text().strip(),
'singer' : title.get_text().split('-')[0],
'song' : title.get_text().split('-')[1],
'link' : title.get('href'),
'time' : time.get_text().strip()
}
total.append(data)
return total
# 程序入口
result = []
for i in range(1, 24):
url = 'http://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'.format(i)
result.append(get_info(url))
print(result)
# 导出数据
deal1 = list(map(pandas.DataFrame, result)) # 有序排列
deal2 = pandas.concat(deal1) # 合并每一页的内容,只保留一个总表头
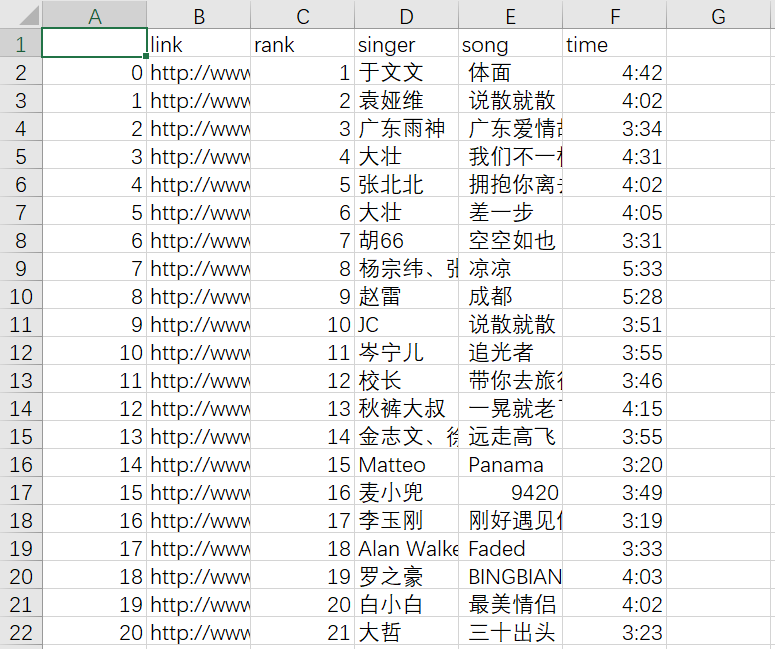
deal2.to_csv('kugouTop500.csv')
参考资料:
爬取酷狗top500
从零开始学Python网络爬虫
R
# 加载包
library(rvest)
library(stringr)
# 定义GetinfoFunc,获取排名情况、歌手、歌名、歌曲链接、歌曲时长
GetinfoFunc <- function(url) {
result <- data.frame()
for (i in seq_along(url)) {
destination <- read_html(url[i], encoding = 'UTF-8')
rank <- destination %>% html_nodes('span.pc_temp_num') %>% html_text() %>% str_trim()
title <- destination %>% html_nodes('div.pc_temp_songlist ul li > a') %>% html_text()
singer <- title %>% strsplit(., '-') %>% lapply(., function(x){x[1]}) %>% unlist()
song <- title %>% strsplit(., '-') %>% lapply(., function(x){x[2]}) %>% unlist()
link <- destination %>% html_nodes('div.pc_temp_songlist ul li > a') %>% html_attr('href')
time <- destination %>% html_nodes('span.pc_temp_time') %>% html_text() %>% str_trim()
data <- data.frame(rank, singer, song, link, time)
result <- rbind(result, data)
cat(sprintf('第【%d】页歌曲抓取成功', i), sep = '\n')
}
return(result)
}
# 执行函数
base1 <- 'http://www.kugou.com/yy/rank/home/'
base2 <- '-8888.html'
url <- paste0(base1, 1:23, base2)
kugou <- GetinfoFunc(url)
# 导出csv文件
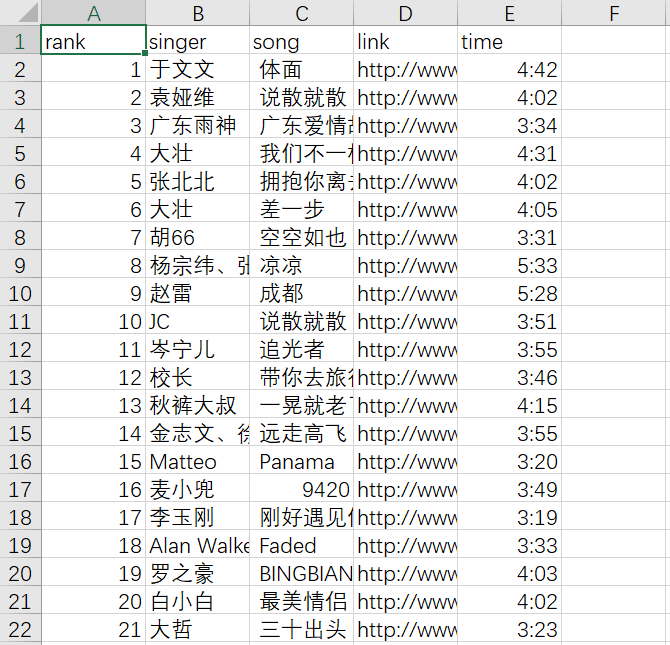
write.table(kugou, row.names = FALSE, sep = ',', 'kugouTop500.csv')















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









