







后门攻击的防御手段横向对比
防御方法概述
下表是将防御方法用到的10种思想进行了简要对比,包括基于过滤投毒数据的防御、基于增强模型稳定性的防御、基于差分隐私的防御、基于特征提取与特征选择(基于降维)的防御、基于修改协议过程的防御、基于综合运用多种技术的防御、基于相似性的防御、基于统计的防御、基于联邦遗忘的防御和基于全局模型性能的防御。
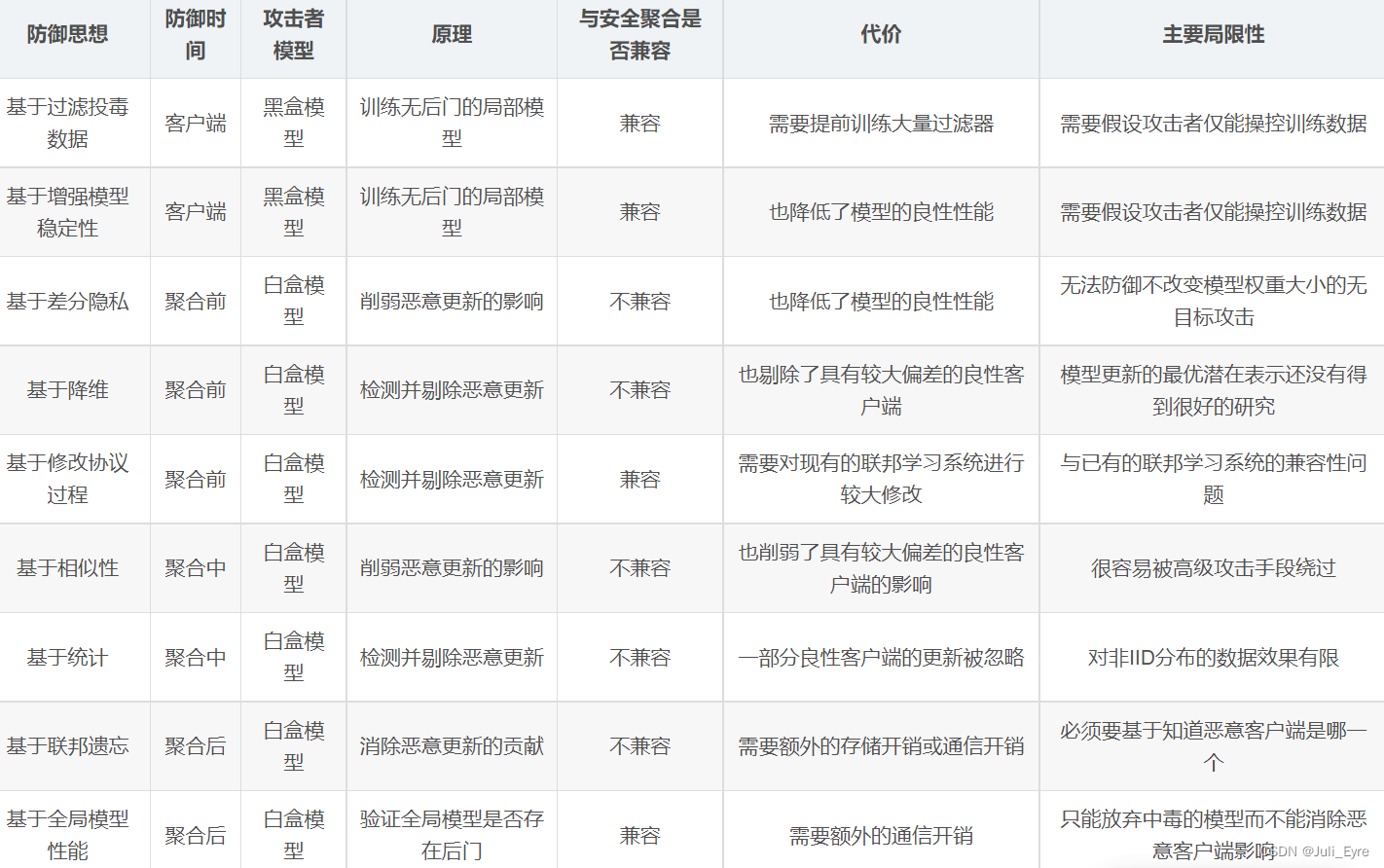
本大节的剩余部分将对每一类思想进行介绍,以及依据近年的文献介绍更加具体的实现方法。
基于差分隐私的防御方法
防御后门攻击的一种数学方法是训练具有差分隐私的模型,具体的可以通过裁减更新、添加高斯噪声来实现。
由于针对模型投毒的后门攻击可能会产生具有较大范数的更新,因此可以让服务器忽略范数超过某个阈值 M M M的更新或将其剪裁到阈值 M M M的范围之内。这样可确保每个模型更新的范数较小,从而缓解恶意更新对服务器的影响。
添加高斯噪声可以在不太影响模型整体性能的情况下,减轻恶意更新的影响。
不足&局限性
- 基于添加噪声的防御虽然无需对攻击者行为和数据分布进行具体假设,但是会恶化聚合模型的良性性能。且由于通常假设服务器不能访问训练数据,尤其是有毒的数据集,因此服务器通常只能根据经验使用的足够数量的噪声。
- 而为了清除恶意更新的影响,通常也会用较小的剪裁因子,这也会影响良性的模型更新。而如果使用较大的剪裁因子,攻击者可以按比例增大恶意模型的参数,直至达到剪裁因子,从而达到最大程度影响全局模型。
- 这种方法可以在一定程度上减轻恶意攻击的影响,但不能完全消除它们。
这种防御方法无法防御不改变模型权重大小的非目标攻击,例如符号翻转攻击。
基于剪裁和添加噪声的防御方法
由于针对局部模型进行投毒的后门攻击的更新往往范数较大,因此可以让服务器将范数超过阈值 M M M的更新剪裁到阈值 M M M的范围之内。这样可确保每个模型更新的范数较小,减轻恶意更新对服务器的影响。
步骤:
- 服务器获取 n n n个用户的模型。
- 剪裁每个模型更新至阈值 M M M之内,并进行求和得到全局模型更新 Δ w t + 1 = ∑ k Δ w t + 1 k max ( 1 , ∥ Δ w t + 1 k ∥ 2 / M ) \Delta w_{t+1}=\sum_{k} \frac{\Delta w_{t+1}^{k}}{\max \left(1,\left\|\Delta w_{t+1}^{k}\right\|_{2} / M\right)} Δwt+1=∑kmax(1,∥Δwt+1k∥2/M)Δwt+1k 。 然后更新全局模型。
- 对剪裁后得到的全局模型添加高斯噪声。
优点&效果
- 可以防御朴素的基于标签翻转的后门攻击。
- 可以防御基于放大模型参数的模型替换攻击。
不足&局限性
- 当攻击者已知服务器的剪裁阈值时,可以直接构建最大限度满足范数约束的模型更新,使得剪裁的防御措施没有效果,尤其是当攻击者可以进行多轮攻击时。
- 这种防御方法无法防御不改变模型权重大小的非目标攻击,例如符号翻转攻击。
- 这种方法没有规定和说明剪裁阈值和噪声量如何确定。
- 可能无法防御基于植入触发器的后门攻击。
来源
【2019 NeurIPS】Can You Really Backdoor Federated Learning
基于特征提取与特征选择(基于降维)的防御方法
在低维的潜在特征空间,来自恶意客户端的异常模型更新可以很容易被区分。因此通过提取高维模型的特征,在低维特征空间中进行判别,可以防御后门攻击。
不足&局限性
- 这类方法也剔除了具有较大偏差的良性客户端的更新,导致聚合后的全局模型对此类客户端的性能较差。
- 这类方法要求恶意客户端数量至少小于50%。
- 模型更新的最优潜在表示还没有得到很好的研究。
基于变分自编码器的特征提取
利用模型更新在低维潜在空间中的表示来检测异常模型更新。因为低维嵌入空间在保留了数据本质特征同时,去除了噪声和不相关的特征,使得恶意模型更新的特征与正常模型更新的特征差异更大。
基于这种思想,考虑用一个变分自编码器来模拟模型更新的低维嵌入。同时收集在集中训练中获得的无偏模型更新,对这些更新的坐标进行随机采样,用于训练变分自编码器。由于良性客户端的更新和无偏模型的更新的差异比恶意客户端的更新和无偏模型的更新的差异要小得多,所以可以通过这种自编码器检测出恶意模型更新。
步骤
- 训练一个编码器-解码器模型来近似低维嵌入。将公共数据集集中训练过程中得到的无偏更新作为编码器的输入并输出低维嵌入,然后将低维嵌入作为解码器的输入并输出原始更新的重构,同时得到重构误差。
- 训练至收敛。通过将重构误差最小化,来优化编码器-解码器模型的参数,直到其收敛。
- 获得局部模型。服务器获取 n n n个用户的更新。
- 检测并剔除恶意更新。在每一轮通信中,将检测阈值设置为所有局部更新重构误差的均值,从而得到一个动态的阈值设置策略。重构误差高于阈值的更新将被视为恶意更新,并被排除在聚合步骤之外。然后进行聚合并开始下一轮更新。
优点&效果
检测阈值是在接收到客户端的模型更新后动态更新的
这种方法是有目标的防御,即可以检测出恶意客户端
不足&局限性
需要额外的公共数据集和集中的训练过程来提供无偏见的模型更新,从而训练变分自编码器,而这在现实世界的联邦学习中是比较难实现的。
牺牲了一定的隐私,与安全聚合不兼容。在安全聚合协议中,服务器无法知道用户局部更新的明文,服务器不能检测参与者对全局模型的异常贡献,这种方法无法使用。
来源
【2020 arXiv】Learning to Detect Malicious Clients for Robust Federated Learning
基于PCA的特征提取
在参数空间的一个子集中,恶意客户端提交的参数更新与良性客户端的参数更新相比,具有更加独特的特征。对上传的模型进行PCA降维分解,然后进行聚类,将最大的类对应的更新视为正常更新,其他类对应的更新视为恶意更新。
步骤
- 服务器获取 n n n个用户的模型 { θ i } {\{\theta_i\}} {θi}
- 对局部模型进行聚合得到全局模型 θ \theta θ
- 计算 n n n个用户的局部模型相对于全局模型的增量 θ Δ , i = θ i − θ \theta_{\Delta, i}=\theta_{i}-\theta θΔ,i=θi−θ(相当于对更新进行了零中心化预处理)。
- 定义类别
c
s
r
c
c_{src}
csrc是怀疑被攻击者在标签翻转攻击中进行投毒的源标签,又由于某一类的概率仅由DNN结构最后一层的特定节点算得到,
到,故仅提取 θ Δ , i \theta_{\Delta, i} θΔ,i 中与 n c s r c n_{c_{s r c}} ncsrc 节点有关的子集 θ Δ , i s r c \theta_{\Delta, i}^{s r c} θΔ,isrc ,并将其放入列表 U U U 中。
- 在经过对列表 U U U 的多轮构建之后,对其进行标准化,然后对标准化之后的列表进行PCA降维,并得到可视化结果。
- 然后对结果进行聚类,将最大的类视为良性更新,而恶意参与者的更新属于其他明显不同的聚类。
- 识别出恶意参与者后,聚合器可以将其列入黑名单,或在末来几轮中忽略其更新。
- 在早期回合中消除恶意客户端后,最终可以得到具有可用性的聚合模型。
优点&效果
可以防御基于标签翻转的后门攻击。
不足&局限性
牺牲了一定的隐私,与安全聚合不兼容。在安全聚合协议中,服务器无法知道用户局部模型参数的明文,服务器不能检测参与者对全局模型的异常贡献,这种方法无法使用。
可能无法防御基于植入触发器的后门攻击。
来源
【2020 ESORICS】Data Poisoning Attacks Against Federated Learning Systems
基于修改协议过程的防御方法
基于分组聚合的防御方法
由于联邦学习中数据分布是非IID的,所以不同客户端提交的模型更新会出现较大差异,这增加了服务器检测恶意更新的难度,同时安全聚合也不允许服务器检查模型更新。而一组良性客户端模型更新的平均值则相对分布得比较集中,于是考虑先对客户端分组进行聚合,对分组聚合的结果进行检测后,再进行最终的聚合。
步骤
- 在每一轮训练中,服务器随机选择 π \pi π 个队列,每个队列包含 c c c 个客户端。
- 服务器向每个队列中的客户端发送全局模型 G t G_{t} Gt ,每个客户机在其本地训练数据上对模型 G t G_{t} Gt 进行独立训练,以获得新的本地模型 L t + 1 L_{t+1} Lt+1 ,并将计算其模型更新 Δ i \Delta_{i} Δi 。
- 然后,服务器同时对 π \pi π 个队列建立 π \pi π 个安全聚合协议,分别对每个队列的客户端提交的更新进行聚合,从而得到 π \pi π 个“队列更新”(注 意,这样得到的“队列更新”是用明文表示的)。
- 服务器可以用基于统计的防御方法对每个队列的聚合结果进行检测,在统计上不同于其他良性聚合的对抗聚合会被服务器检测到并 丟弃。
- 最后,服务器对良性的“队列更新”进行聚合得到全局更新,并用其更新全局模型。
优点&效果
- 这种方法与安全聚合兼容,因为参与者提交的都是加密之后的更新。虽然每个队列进行聚合后得到的“队列更新”仍可能泄露队列成员集体的数据信息,但推理出来的信息无法与任何单个客户端相关联。
- 由于客户端的数据集是非IID分布,所以提交的模型更新可能会显示出很大的差异,这使得服务器很难确定哪些更新是恶意的。而对队列中的更新进行聚合之后,良性“队列更新”的数据分布会更加集中,有助于服务器检测异常。
可以防御基于标签翻转的后门攻击。
可以防御基于植入触发器的后门攻击。
可以防御基于模型替换的后门攻击。
不足&局限性
这类方法要求恶意客户端数量较少,至少在每一轮中,不能有超过50%的队列中有恶意客户端出现。
来源
【2021 arXiv】Meta Federated Learning
基于限制模型更新上传比例的聚合规则(PartFedAvg)
由于现有的后门攻击方法都是基于全参数的投毒,如果只上传更新参数的一部分,将大大降低恶意模型的毒性。因此设计参数 d d d来控制每个客户端模型更新的上传比例,这使得恶意客户端很难进行后门攻击。
另外设计了一套安全的聚合协议,用于防止推理攻击,从而保护客户端隐私,同时这种协议也可以让服务器验证用户提交的更新向量中非零分量的个数。
步骤
客户端:
- 得到局部模型更新。将当前的全局模型 G t G^{t} Gt 作为当前的局部模型 L t L^{t} Lt ,使用局部数据集 D i D^{i} Di 训练 L t L^{t} Lt 得到新的局部模型 L t + 1 L^{t+1} Lt+1 ,二者相减得 到参数更新 Δ i t \Delta_{i}^{t} Δit 。
- 选择上传更新。随机将 Δ i t \Delta_{i}^{t} Δit 中比例为 ( 1 − d ) (1-d) (1−d) 的部分填充为 0 ,其余值保持不变,将修改后的参数更新上传给服务器。
服务器:
- 服务器获取 n n n 个用户的局部更新的更新向量。
- 对于每一个维度 j j j ,服务器对所有的 n n n 个更新向量计算其第 j j j 个参数为非零值的个数之和,非零值的个数表明有多少个客户端贡献了 该参数的更新。
- 对于每一个维度 j j j ,对局部模型的更新进行求和,并除以非零值的个数,从而计算出更新的平均值 Δ a g g i \Delta_{a g g_{i}} Δaggi 。
- 计算出所有维的更新的平均值之后,更新全局模型 G t + 1 = G t + Δ a g g t G^{t+1}=G^{t}+\Delta_{a g g}^{t} Gt+1=Gt+Δaggt 。
优点&效果
- 可以防御后门攻击。恶意客户端无法在短时间内上传完整的恶意参数,且每一轮聚合操作都会使全局模型倾向于良性客户端,抵消恶意参数的影响。
- 使用的是安全聚合的协议,每个客户端只上传一小部分参数信息,且传输过程和聚合过程都进行了同态加密,可以防御推理攻击。
不足&局限性
这种防御方法无法防御无目标攻击,比如符号翻转攻击。
这种方法需要对客户端算法进行修改。
这种方法可以在一定程度上减轻恶意攻击的影响,但不能完全消除它们。
来源
【2022 IEEE】Secure Partial Aggregation: Making Federated Learning More Robust for Industry 4.0 Applications
综合运用多种技术的防御方法
正因为每一类防御方法都有其缺点,所以可以考虑同时使用多种防御手段,综合每一类方法的优点,使防御更加可靠,也可以防止过分依赖某一种方法而带来的不可接受的负面影响(比如添加过多噪声对主任务精度造成的影响)。
基于HDBSCAN聚类、剪裁和加噪的自适应防御方法
这种方法综合运用了基于聚类的防御方法、基于剪裁的防御方法和基于添加噪声的防御方法,且剪裁的阈值和添加的噪声量是动态自适应变化的。将对异常模型更新的检测和权值的裁剪相结合,首先剔除具有高后门影响的局部更新,然后通过剪裁和加噪来消除残余的后门。实现了去除后门所需的剪裁因子和噪声量的最小化,以保持全局模型的良性性能。
步骤
- 服务器获取 n n n 个用户的模型。
- 计算 n n n 个模型两两之间的余弦相似度。
- 使用动态聚类算法HDBSCAN对两两之间的余弦相似度进行聚类,超过 50 % 50 \% 50% 的类为良性更新。其他类均视为离群值,将其剔除,得 到剩余的 L L L 个良性模型。
- 对 n n n 个模型中的每个模型计算和当前全局模型的欧式距离 ( e 1 , … , e n ) \left(e_{1}, \ldots, e_{n}\right) (e1,…,en) ,并令其中值为 S t S_{t} St
- 对于每一轮的 L L L 个用聚类算法笑选出来的模型,令其动态自适应剪裁阈值为 γ = S T / e l \gamma=S_{T} / e_{l} γ=ST/el 。
- 计算剪裁后的局部模型 W l = G t − 1 + ( W l − G t − 1 ) ∗ M I N ( 1 , γ ) W_{l}=G_{t-1}+\left(W_{l}-G_{t-1}\right) * M I N(1, \gamma) Wl=Gt−1+(Wl−Gt−1)∗MIN(1,γ)
- 对剪裁后的局部模型赋予相同的权重进行聚合得到全局模型 G t G_{t} Gt
- 基于局部模型之间的差异 (距离) 得到动态自适应噪声量 σ = λ ∗ S t \sigma=\lambda * S_{t} σ=λ∗St ,其中超参数 λ \lambda λ 是根据经验设置的噪声水平因子。
- 得到加噪后的全局模型 G t = G t + N ( 0 , σ 2 ) G_{t}=G_{t}+N\left(0, \sigma^{2}\right) Gt=Gt+N(0,σ2)
优点&效果
- 这种方法也开发了一种基于安全多方计算的方法对上述算法进行升级,从而可以对客户端的隐私进行保护,可以同时防御后门攻击和推理攻击。(但由于本文重点总结后门攻击,故没有详细介绍这种升级版方法对推理攻击的处理。)
- 由于这种方法中用到的HDBSCAN聚类算法是动态自适应的,剪裁因子和噪声量也是动态自适应的,因此这种方法适用于一般的攻击者模型,不依赖于对攻击者攻击策略和数据分布的强假设。比如,相较于固定分成 n n n类的聚类防御方法,这种自适应的聚类方法可以防御任意数量的后门同时注入的攻击,也不会在没有后门攻击时对良性模型误报。
- 通过优化剪裁和噪声的阈值,使得这种方法对聚合模型的良性性能的影响可以忽略不计,同时确保有效地消除恶意后门。
可以完全防御基于放大模型参数的模型替换后门攻击。
可以完全防御基于植入触发器的分布式协同后门攻击。
可以完全防御基于边界情况的后门攻击。
不足&局限性
这种方法还有一个升级版本,升级版的方法保证了隐私,与安全聚合兼容,但对联邦学习的流程进行了大量的、代价高昂的更改。如果不用升级版则牺牲了一定的隐私,与安全聚合不兼容。
这种方法需要恶意客户端数量至少小于50%。
来源
【2021 arXiv】FLGUARD: Secure and Private Federated Learning
【2021 arXiv】FLAME: Taming Backdoors in Federated Learning
基于相似性的防御方法
利用欧式距离、余弦相似度等计算模型的相似性。根据相似性调整局部模型的权重或学习速率。或利用基于聚类的方法找到离群值,并从中去除离群值。
不足&局限性
- 在安全聚合协议中,服务器无法得到客户端的局部模型参数或更新的明文,因此在这种情况下,基于相似性的防御方法无法使用。(但是随着技术的进步,未来版本的联邦学习协议可能有在不泄露客户端训练数据隐私的情况下计算客户端参数的偏离程度和距离的方法,从而进行异常检测,所以基于相似性的防御方法仍有研究价值。)
- 这些防御对基础的攻击者有效,但可以很容易地被高级攻击者所绕过。更复杂的恶意客户端可能通过采取隐蔽措施或相互串通来隐藏他们的意图。
- 比如,攻击者可以通过将恶意的更新向量投影到真实更新向量的邻域,从而绕过这些基于相似性的防御。
- 比如,攻击者可以让有毒模型更新 W 0 W_{0} W0 与良性模型更新 W W W 之间的距离小于所采用的防御方法的判别阈值 ϵ \epsilon ϵ ,即 ∥ W 0 − W ∥ ≤ ϵ \left\|W_{0}-W\right\| \leq \epsilon ∥W0−W∥≤ϵ ,从 而避开基于检测距离相似性的防御方法。
- 比如,攻击者可以通过缩小后门参数的放大比例从而避免被检测。
- 比如,攻击者可以让多个恶意客户端同时注入多个不同的后门,从而避免所有后门被检测出来。比如对于将客户端的更新固定分成 n n n类的聚类防御方法,攻击者可以精心构造 m ≥ n m ≥ n m≥n 数量的后门进行攻击,从而实现部分后门的成功注入。同时对于将客户端的更新固定分成 n n n类的聚类防御方法,即便在没有后门攻击发生时仍然会剔除一部分良性更新,导致产生误报。
- 这类方法需要恶意客户端数量至少小于50 % 。
-有些防御方法需要关于阈值的先验知识,而这在实际应用中很难得到。
基于历史更新余弦相似性的防御方法
当每个客户端的训练数据都是非IID时,由于诚实客户端的梯度更新存在多样性,而恶意客户端的行为更加相似,所以恶意客户端将上传比诚实客户之间更相似的更新。为了更好地估计客户端的相似性,可以计算所有历史更新的相似性,而非某一轮迭代中的更新的相似性。并基于特定特征的相似性来调整每个客户端的学习速率,从而减少恶意更新的影响。
步骤
- 对于每一个客户端 i i i ,服务器保存其历史更新向量为 H i = ∑ t Δ i , t H_{i}=\sum_{t} \Delta_{i, t} Hi=∑tΔi,t
- 寻找指示性特征。(指示性特征是指与模型的正确性相关或后门攻击相关的特征。)
- 计算客户端历史更新中指示性特征两两之间的余弦相似性 c s i j c s_{i j} csij ,并令 v i v_{i} vi 为客户端 i i i 与其他所有客户端余弦相似性中的最大值。
- 两两之间的余弦相似性计算完毕之后,对于每一个客户端 i i i ,如果存在另一个客户端 j j j 满足 v j > v i v_{j}>v_{i} vj>vi ,则将客户端 i i i 的 c s i j c s_{i j} csij 修正为 c s i j ∗ v i / v j c s_{i j} * v_{i} / v_{j} csij∗vi/vj 。通过重新衡量余弦相似度,可以使得诚实客户端与恶意客户端的相似性进一步减小,而恶意客户端与恶意客户端的相 似性基本不变,从而减少误报。
- 计算每一个客户端 i i i 的学习速率为 α i = 1 − max j ( c s i ) \alpha_{i}=1-\max _{j}\left(c s_{i}\right) αi=1−maxj(csi) ,并通过除以 α i \alpha_{i} αi 中的最大值,将其标准化缩放到0到1之间。
- 对每一个客户端的学习速率 α i \alpha_{i} αi ,使用以0.5为中心logit函数,使得接近0和1的学习速率变得更加发散。
- 将最终的学习速率与对应的模型更新相乘,得到聚合后的模型更新,并用其更新全局模型。
优点&效果
- 这种方法对恶意客户端最大数量没有限制,攻击者可以掌控任意数量的恶意客户端。(其他大部分防御方法至少都有恶意客户端最大数量小于50%的限制。)
- 可以防御基于植入触发器的后门攻击。
不足&局限性
- 这种方法对攻击者的行为有过强的假设。它需要假设攻击者的行为一直是恶意的,即在所有训练回合中攻击者都要提供恶意模型更新,从而累计历史更新。然而,这样的假设是不现实的,攻击者可以随意改变攻击策略,在每个训练回合中,攻击者可以不注入后门(即作为良性行为),也可以注入一个后门,还可以注入多个后门。
- 这种方法不能防御同时注入多个后门的攻击。
来源
【2020 RAID】The Limitations of Federated Learning in Sybil Settings
基于余弦相似性的攻击自适应防御方法
用余弦关系判断相似性,然后利用一个阈值,将相似性过低的数据直接剔除,仅让相似度较高的更新参与最终的模型聚合,从而避免恶意更新的影响。
并且这种方法中相似性的计算是用当前轮的局部更新向量与上一轮的全局更新结果进行比较,即是用当前的输入以及之前得到的结果去判断当前的输入是否是诚实的更新向量,相当于是基于前面的经验去判断后面的数据。
步骤:
- 首先训练查询编码器 Q Q Q 和更新向量编码器 K K K 。对于每种不同攻击,在服务器的测试集上模拟运行联邦学习场景来收集更新向量及对 应的标签(恶意的或真实的)。并对更新向量运行同后面步骤 3 至步骤 6 类似的算法,得到对标签真实性的预测(恶意的或真实 的),然后用一个损失函数鼓励预测标签与真正标签的差距最小化,来优化编码器的参数,直到其收敛。之后便可以在服务器上开 始使用了。
- 服务器获取 n n n 个用户的局部更新的更新向量 { x i } \left\{x_{i}\right\} {xi}
- 利用中位数等聚合规则,得到第一轮更新的鲁棒性估计 q 0 = med ( { x i } ) q_{0}=\operatorname{med}\left(\left\{x_{i}\right\}\right) q0=med({xi}) 。(这一步仅需要在首轮进行)
- 在第 t + 1 t+1 t+1 轮,对于第 i i i 个更新向量,计算其与上一轮全局模型的余弦相似度为 s i = Q ( q t ) ∗ K ( x i ) ∥ Q ( q t ) ∥ ∥ K ( x i ) ∥ s_{i}=\frac{Q(q t) * K\left(x_{i}\right)}{\|Q(q t)\|\left\|K\left(x_{i}\right)\right\|} si=∥Q(qt)∥∥K(xi)∥Q(qt)∗K(xi)
- 将相似度约束到0到1的范围,得到更新向量的权重 w i = exp ( c s i ) / ∑ j exp ( c s i ) w_{i}=\exp \left(c s_{i}\right) / \sum_{j} \exp \left(c s_{i}\right) wi=exp(csi)/∑jexp(csi) ,其中 c c c 是一个超参数, c c c 越大则恶意更新的权重 越低。
- 对恶意更新进行剔除,计算最终的更新向量的权重 w i = w i ⋅ 1 ( w i ≥ ϵ / n ) w_{i}=w_{i} \cdot 1_{\left(w_{i} \geq \epsilon / n\right)} wi=wi⋅1(wi≥ϵ/n)
- 根据权重对局部更新进行聚合,得到全局更新
q
t
+
1
q_{t+1}
qt+1 ,并作为下一轮通信的鲁棒性估计。
优点&效果
- 这是一种自监督的方法,可以根据训练数据和攻击手段的变化来改进编码器Q和K,从而抵御新的攻击。
- 在防御后门攻击方面,这种方法优于以前的方法,如基于中位数的聚合规则、基于残差的重新加权聚合规则。
不足&局限性
- 对每一种攻击都需要相应的测试集提前在服务器上训练编码器。
- 牺牲了一定的隐私,与安全聚合不兼容。在安全聚合协议中,服务器无法知道用户局部更新的明文,服务器不能检测参与者更新的相似性,这种方法无法使用。
来源
【2021 arXiv】Robust Federated Learning with Attack-Adaptive Aggregation
基于马氏距离相似性的防御方法
由于后门攻击会在局部模型的权重上有所暴露,故首先对CNN某一层中过滤器的梯度进行零中心化预处理,然后采用无监督的异常检测手段来评估预处理过的过滤器,为每个客户端计算异常得分。最后根据客户端的异常得分来确定其是否为恶意客户端,大多数良性客户端的得分会分布在一个很小的范围内,而恶意的客户端应该有显著的更高或更低的分数。
步骤
- 服务器获取 n n n 个用户的局部模型的权重 { w i } \left\{w_{i}\right\} {wi}
- 对模型权重进行预处理,得到零中心化后的梯度 δ i t + 1 = w i t + 1 − 1 n ∑ i w i t + 1 \delta_{i}^{t+1}=w_{i}^{t+1}-\frac{1}{n} \sum_{i} w_{i}^{t+1} δit+1=wit+1−n1∑iwit+1
- 取一个CNN层提取其所有的过滤器,将所有客户端该层的所有过滤器视为一个整体进行考虑,计算出过滤器梯度的平均值 f ˉ \bar{f} fˉ ,然后 计算每个过滤器的梯度到过滤器梯度的平均值的马氏距离。
- 将距离最大的 γ \gamma γ 个过滤器视为异常过滤器,若客户端有一个异常过滤器,则其异常得分加1。
- 如果某个客户端的异常得分显著的更高或更低,则客户端可能是恶意的。
- 识别出可疑客户端后,服务器像往常一样对其余的模型权值进行聚合,得到新的全局模型。
优点&效果
这种方法有三个强假设,假设攻击者知道服务器端可能执行的所有防御,假设攻击者在任何时候任意选择所有恶意客户端进行攻击,假设恶意客户端可以合谋分担攻击工作量。
能够在不降低模型性能的情况下,有效且鲁棒地抵御多种最新的攻击。
可以防御基于标签翻转的后门攻击。
可以防御基于像素模式的后门攻击。
可以防御基于语义的后门攻击。
不足&局限性
牺牲了一定的隐私,与安全聚合不兼容。在安全聚合协议中,服务器无法知道用户局部模型参数的明文,服务器不能检测参与者对全局模型的异常贡献,这种方法无法使用。
来源
【2022 arXiv】ARIBA: Towards Accurate and Robust Identification of Backdoor Attacks in Federated Learning
基于统计的防御方法
根据中位数、平均值等统计特性,选择一个或多个有代表性的客户端更新,并使用其来估计真实更新的中心,从而避免恶意模型的参数的影响。
不足&局限性
- 部分方法虽然在统计上对后门攻击具有鲁棒性,但可能导致一个有偏差的全局模型、因为所选择的更新只占局部更新的一小部分,导致聚合模型对具有较大偏差的良性客户端客户端的性能较差。
- 在安全聚合协议中,服务器无法得到客户端的局部模型参数或更新的明文,因此在这种情况下,基于统计的防御方法无法使用。(但是随着技术的进步,未来版本的联邦学习协议可能有在不泄露客户端训练数据隐私的情况下计算客户端参数的偏离程度的方法,从而进行异常检测,所以基于统计的防御方法仍有研究价值。)
- 这类方法需要恶意客户端数量至少小于50 % 。
基于中位数的聚合规则(Coordinate-Wise Median)
利用局部模型更新每一维的中值作为聚合后的全局模型更新。
步骤
- 服务器获取n个用户的局部更新。
- 对于每一个维度j,服务器求出所有局部模型第j个参数的中位数。
- 服务器使用每个参数的中位数作为全局模型的更新更新全局模型。
优点&效果
计算过程简单。
对攻击者模型没有过多的限制。
不足&局限性
- 对非IID数据准确性较低。这种方法是在2018年提出来的,当时的应用场景是分布式学习,但是由于联邦学习场景中数据的分布是非IID的。而当数据分布为非IID时,仅只取一个中位数会忽略其他数据,所以这种方法的防御效果在联邦学习中有所下降,尤其是对具有较大偏差的良性客户端客户端的性能较差。
- 牺牲了一定的隐私,与安全聚合不兼容。在安全聚合协议中,服务器无法知道用户局部更新的明文,服务器不能检测参与者对全局模型的异常贡献,这种方法无法使用。
【2018 ICML】Byzantine-Robust Distributed Learning: Towards Optimal Statistical Rates.
基于修剪的平均值的聚合规则(Trimmed Mean)
选择局部模型更新对应维度的修剪后的平均值作为聚合后的全局模型更新。
步骤
- 服务器获取n个用户的局部更新。
- 对于每一个维度j,服务器对n个更新的第j个参数进行排序,并丢弃排序后最大的一部分值和最小的一部分值。
- 取剩余值的平均作为全局模型更新的第j个参数更新全局模型。
优点&效果
计算过程简单。
对攻击者模型没有过多的限制。
不足&局限性
对非IID数据准确性较低。 这种方法是在2018年提出来的,当时的应用场景是分布式学习,但是由于联邦学习场景中数据的分布是非IID的,所以这种方法的防御效果在联邦学习中有所下降。
牺牲了一定的隐私,与安全聚合不兼容。在安全聚合协议中,服务器无法知道用户局部更新的明文,服务器不能检测参与者对全局模型的异常贡献,这种方法无法使用。
【2018 ICML】Byzantine-Robust Distributed Learning: Towards Optimal Statistical Rates.
基于残差的重新加权聚合规则
将一种经典鲁棒性回归算法(重复中值线性回归)扩展到了联邦学习环境。对局部模型每一维,用回归算法得到线性回归,根据每个模型在该维上的参数的标准差求相应的置信度,并乘以该参数的标准差得到在该维上的权重。然后将每个模型的所有维的权重求和,作为聚合时该局部模型的权重,聚合后得到全局模型。
步骤
- 获得局部模型。服务器获取 n n n 个用户的更新,得到 n n n 个用户的局部模型。
- 得到参数和索引值的二维点集。对于每一个维度 j j j ,服务器对 n n n 个模型的第 j j j 个参数 y j y_{j} yj 进行排序,并为第 k k k 个模型的第 j j j 个参数添加索 引 x k j x_{k}^{j} xkj ,得到二维点集 ( x k , y k ) \left(\boldsymbol{x}_{k}, \boldsymbol{y}_{k}\right) (xk,yk)
- repeated median线性回归。对于每一个维度 j j j ,用重复中值线性回归法得到点集 ( x k , y k ) \left(\boldsymbol{x}_{k}, \boldsymbol{y}_{k}\right) (xk,yk) 的线性回归。
- 计算残差。计算每个模型第 j j j 个参数的残差。
- 计算标准差。对残差标准化得到标准差。
- 计算参数置信度。根据标准差计算每个模型第 j j j 个参数的置信度。
- 超大值修正。为了削弱过大参数对全局模型可能造成的恶意影响,对于置信度小于阈值 δ \delta δ 的参数,用重复中值回归得到的线性估计的 值代替原本的参数。
- 计算各局部模型权重。第 k k k 个局部模型第 j j j 个参数的权重为该模型第 j j j 个参数的置信度 × \times × 第 j j j 个参数的标准差。第 k k k 个局部模型的整体权 重为所有参数权重之和。
- 聚合得到全局模型。根据每个局部模型的权重,加权聚合得到全局模型。
优点&效果
这种聚合方法可以防御基于标签翻转的后门攻击。
这种聚合方法可以防御基于放大模型参数的模型替换攻击。
不足&局限性
牺牲了一定的隐私,与安全聚合不兼容。在安全聚合协议中,服务器无法知道用户局部更新的明文,服务器不能检测参与者对全局模型的异常贡献,这种方法无法使用。
【2019 arXiv】Attack-Resistant Federated Learning with Residual-based Reweighting
基于调整每个参数学习速率的聚合规则
对每个回合的每一维,根据客户端更新的符号信息,调整聚合时的学习速率。**如果更新方向相同的模型数量超过某个阈值,则朝着最小化该维度上的损失的方向正常更新;反之,说明可能是攻击方在将参数向后门引导,则朝着最大化该维度上的损失的方向更新,**具体操作为将该维的学习率变为原来的相反数。
步骤
- 服务器获取 n n n 个用户的局部更新。
- 对于每一个维度 j j j ,服务器对 n n n 个模型的第 j j j 个参数求符号函数,再对符号函数的运算结果求和,即求 ∑ k s g n ( Δ j k ) \sum_{k} s g n\left(\Delta_{j}^{k}\right) ∑ksgn(Δjk)
- 设置一个学习阈值的超参数 θ \theta θ ,若 ∣ ∑ k sgn ( Δ j k ) ∣ ≥ θ \left|\sum_{k} \operatorname{sgn}\left(\Delta_{j}^{k}\right)\right| \geq \theta ∣∣∑ksgn(Δjk)∣∣≥θ ,则 η j = η \eta_{j}=\eta ηj=η ,反之 η j = − η \eta_{j}=-\eta ηj=−η
- 选用一种聚合函数(如联邦平均) 对局部更新进行聚合,唯一的区别是,每个参数的学习速率不是固定的相同的 η \eta η ,而是前面求出 的 η j \eta_{j} ηj
优点&效果
这种方法只调整学习速率,而与聚合函数无关,因此可以同其他的防御方法(如剪裁更新和添加噪声)结合起来,以增强防御效果。
这种方法可以防御针对数据投毒的后门攻击。
同单纯的基于中位数的聚合、基于调整每个客户端学习速率的聚合、基于差分隐私的聚合相比,这种方法降低后门攻击成功率的效果更好。
不足&局限性
牺牲了一定的隐私,与安全聚合不兼容。在安全聚合协议中,服务器无法知道用户局部更新的明文,服务器不能检测参与者对全局模型的异常贡献,这种方法无法使用。
【2021 AAAI】Defending Against Backdoors in Federated Learning with Robust Learning Rate
基于联邦遗忘的防御方法
在联邦训练过程之后,从全局模型中彻底有效地删除指定客户端的贡献,从而完全消除恶意客户端的影响。
不足&局限性
需要已知恶意客户端是哪一个。
需要对客户端的算法进行修改。
基于再培训的联邦遗忘方法
将联邦学习过程中客户端的历史参数更新保存在服务器上,用于重建遗忘模型,并用一种校正方法对保存的更新值进行校正,快速构建遗忘模型。相当于用服务器的存储空间换取遗忘模型的构建时间。
步骤
- 在全局模型的训练过程中,服务器每隔 E c a l i E_{c a l i} Ecali 轮保存客户端的更新以及相应轮次的索引,被记录的一轮更新为 U t j = { U 1 t j , U 2 t j … U k t j , } U^{t_{j}}=\left\{U_{1}^{t_{j}}, U_{2}^{t_{j}} \ldots U_{k}^{t_{j}},\right\} Utj={U1tj,U2tj…Uktj,},
- 全局模型训练完成之后,需要继续进行 T T T 轮训练。定义除了恶意客户端之外的其他客户端为校准客户端。在第 j j j 轮培训中,服务器将 上一轮校准中获得的校准全局模型 M t j M^{t_{j}} Mtj 发送给校准客户端,令校准客户端对其运行 E c a l i E_{c a l i} Ecali 轮本地训练。(第1轮服务器则将初始的模 型发送给校准客户端。)
- 校准训练后,每个校准客户端 C k c C_{k_{c}} Ckc 计算当前更新 U ^ k c t j \hat{U}_{k_{c}}^{t_{j}} U^kctj ,并将其发送到服务器进行更新校准。
- 校准客户端 k c k_{c} kc 用当前更新 U ^ k c t j \hat{U}_{k_{c}}^{t_{j}} U^kctj 校准服务器保存的对应客户端的更新 U k c t j U_{k_{c}}^{t_{j}} Ukctj ,保存的更新 U k c t j U_{k_{c}}^{t_{j}} Ukctj 指示了要更改的大小,而当前更新 U ^ k c t j \hat{U}_{k_{c}}^{t_{j}} U^kctj 归一 化后代表了需要更改的方向。结合这二者的信息,于是对 U k c t j U_{k_{c}}^{t_{j}} Ukctj 的校准可以表示为 ∣ U k c t j ∣ U ^ k c ∥ U ^ k c t j ∥ \left|U_{k_{c}}^{t_{j}}\right| \frac{\hat{U}_{k_{c}}}{\left\|\hat{U}_{k_{c}} t^{j}\right\|} ∣∣∣Ukctj∣∣∣∥U^kctj∥U^kc 。
- 利用校准之后的更新进行加权平均聚合得到全局更新,其中每个局部模型更新的权重由其局部数据量决定,与标准的联邦学习聚合 规则一致。再加上上一轮的全局模型得到当前轮校准后的全局模型。
优点&效果
这种方法是联邦学习中的第一个遗忘算法,能够消除客户端数据对全局模型的影响。
这种方法比重新从头开始训练模型的速度提高了4倍。
服务器端只需要增加额外的保存功能,而不用对现有的联邦学习体系结构或联邦客户端上的培训过程进行大的修改,因此这种防御机制很容易作为一个组件部署到现有的联邦学习系统中。
由于原理是删除指定客户端的贡献所以几乎可以适用于防御所有的攻击。
不足&局限性
校准过程依赖于客户端的参与,并且要使用它们的历史数据集,而一个实际的问题是,客户端的边缘设备可能只有有限的存储空间,他们可能会在培训过程结束后随时删除数据。
需要客户端和服务器之间进行额外的通信, 但是通信会耗费大量时间和精力。
一般的联邦学习在训练过程中需要随机选择参加每轮培训的客户端,此外,在每个客户端的本地训练过程中也存在很多随机性,所以训练过程是随机的。因此,用在原始数据集上重新训练,用新的更新校准历史更新可能在实际中并不可行。
需要已知恶意客户端是哪一个。
牺牲了一定的隐私,与安全聚合不兼容。在安全聚合协议中,服务器无法知道用户局部更新的明文,服务器无法利用客户端的更新,这种方法无法使用。
【2021 IEEE】FedEraser: Enabling Efficient Client-Level Data
基于知识蒸馏的联邦遗忘方法
首先从全局模型中减去目标客户端累积的历史更新来消除其贡献,然后用旧的全局模型作为教师模型来训练遗忘模型,通过知识蒸馏的方法来恢复模型的性能。
步骤
- 假设恶意客户端的所有轮的更新为 0 ,即 Δ M t n = 0 \Delta M_{t}^{n}=0 ΔMtn=0 ,则全局模型更新的遗忘过程可以简化为 Δ M t ′ = Δ M t − 1 N Δ M t n \Delta M_{t}^{\prime}=\Delta M_{t}-\frac{1}{N} \Delta M_{t}^{n} ΔMt′=ΔMt−N1ΔMtn
- 考虑到任何一轮全局模型的更新都会导致对随后所有轮的模型更新的影响,因此需要用 ϵ t \epsilon_{t} ϵt 来表示第 t t t 轮对全局模型的必要修正。可以 得到最终的全局模型的遗忘模型为 M F ′ = M F − ∑ t 1 N Δ M t n + ∑ t ϵ t M_{F}^{\prime}=M_{F}-\sum_{t} \frac{1}{N} \Delta M_{t}^{n}+\sum_{t} \epsilon_{t} MF′=MF−∑tN1ΔMtn+∑tϵt
- 根据上述模型,从最终的全局模型 M F M_{F} MF 中减去目标客户端 N N N 的所有历史平均更新即可得到有偏差的遗忘模型 M F ∗ = M F − M_{F}^{*}=M_{F}- MF∗=MF− ∑ t 1 N Δ M t n \sum_{t} \frac{1}{N} \Delta M_{t}^{n} ∑tN1ΔMtn 。然后用知识蒸馏的方法弥补偏差 ∑ t ϵ t \sum_{t} \epsilon_{t} ∑tϵt
- 将原始的全局模型作为教师模型,将有偏差的遗忘模型作为学生模型。服务器可以使用任何末标记的数据在高温下通过知识蒸馏的 方法训练遗忘模型,从而纠正由上一个过程引起的偏差。
- 知识蒸馏训练结束之后,将温度调回至1,得到最终的遗忘模型。
优点&效果
- 可以使得后门攻击的成功率降为0。遗忘模型的测试准确率与从头再训练的模型的测试准确率基本一致。
- 知识蒸馏训练完全在服务器进行,无需标记数据集,因此不需要客户端的时间和计算开销,也不会进行网络通信。
- 后门特征不会从教师模型转移到遗忘模型,因为在知识蒸馏的训练过程中没有后门模式的出现,这些特征就不会被激活。
- 知识蒸馏可以避免模型与数据拟合得过于紧密,并且可以在训练点周围更好地泛化,从而能提高模型的鲁棒性,进一步提高训练后模型的性能。
- 由于原理是删除指定客户端的贡献所以几乎可以适用于防御所有的攻击。
不足&局限性
需要已知恶意客户端是哪一个。
牺牲了一定的隐私,与安全聚合不兼容。在安全聚合协议中,服务器无法知道用户局部更新的明文,服务器无法利用客户端的更新,这种方法无法使用。
【2022 arXiv】Federated Unlearning with Knowledge Distillation
基于全局模型性能的防御方法
利用客户端的本地数据集测试全局模型,从而验证全局模型是否具有后门。
传统的基于性能的测试一般是利用服务器上的辅助数据集测试每个本地模型,并依据准确率、损失函数等性能剔除恶意模型。而由于联邦学习任务通常涉及大量客户端,因此对其进行全面测试几乎是不可能的。同时由于恶意模型在主任务和后门任务上都可以达到很高的准确性,因此服务器上有限的测试数据很难发现恶意异常。而由于客户端的本地数据集具有多样性,并且可以多个客户端并行测试,故可以考虑将聚合后的全局模型发送给客户端进行测试。
不足&局限性
需要对客户端的算法进行修改
这种方法需要恶意客户端数量至少小于50 % 。
基于反馈性能检测的防御机制
由于客户端的私有数据集提供了丰富多样的已标记的数据集,所以不仅可以将客户端的数据用于训练,还可以用于检测模型中毒。在服务器训练出全局模型之后,随机选择一组客户端,根据其本地数据验证全局模型,并通过反馈回路投票决定接受或拒绝该模型,如果确定为中毒模型,则将其放弃。并且经过实验评估,这种方法的正确性并不依赖于诚实客户端拥有后门数据。
步骤
- 获得用户局部更新,聚合得到当前待检测的全局模型。服务器获取 n n n 个用户的更新,聚合后得到当前的全局模型 G r G^{r} Gr 。
- 确定每一轮的拒绝阈值。由于期望每一轮的全局模型的精度都比上一轮的全局模型有所提高,因此根据最近几轮的全局模型在服务 器的测试集上的预测结果确定这一轮的拒绝阈值,用于客户端判断全局模型是否可疑。
- 选择客户端。服务器随机选择 n n n 个客户端,将当前的全局模型以及拒绝阈值发送给客户端。
- 客户端使用本地数据集进行验证。客户端验证全局模型,并根据拒绝阈值向服务器报告当前全局模型是否可疑。
- 确定仲裁阈值 q q q 。使得是服务器拒绝当前全局模型需要的报告可疑的客户端的最少数量。既要保证不能因为恶意客户端的恶意误报 而导致拒绝真正的模型(即 n M < q ) n_{M}<q ) nM<q) ,也要保证能让诚实的客户端拒绝中毒模型(即 n M ≤ n − q ) n_{M} \leq n-q ) nM≤n−q) ,其中 n M n_{M} nM 为恶意客户端的最大 数量。当然考虑到诚实客户端也会有误判的情况,所以还要依据经验考虑到误判率 ρ 。 \rho_{\text {。 }} ρ。
- 服务器判断全局模型是否为中毒模型。如果有大于等于仲裁阈值 q q q 的验证客户端认为该模型可疑,则服务器拒绝接受这一轮的全局更 新,并令这一轮的全局模型为上一轮的全局模型 G r − 1 G^{r-1} Gr−1 ,继续进行下一轮的更新。
优点&效果
与安全聚合兼容, 因为客户端的判断完全基于全局模型,而不是对单个更新。
可以防御基于放大模型参数的模型替换攻击。
这种防御方法对现有的联邦学习系统部署的修改最小。
可以防御自适应攻击。这种方法利用客户端的私有数据的多样性防御不可预测的攻击,使攻击者难以调整其策略以避免检测。
不足&局限性
无法防御基于植入触发器的后门攻击。
只能检测恶意模型但不能纠正或消除。
【2020 arXiv】BaFFLe: Backdoor detection via Feedback-based Federated Learning
基于过滤投毒数据的防御方法
客户端通过从训练数据中除去带有后门的投毒数据,从而训练出无后门的局部模型。
基于后门区域过滤的防御方法
服务器使用可解释(XAI)模型和分类器训练后门过滤器,并使用不同的XAI模型和不同的分类器组合训练多个过滤器,以保证每个过滤器的可用性和随机性。
其中之所以要使用可解释模型,是为了提取样本的重要特征,因为如果直接将触发器的大小设置为一个固定的值将有损训练出来的过滤器的通用性,因此可以通过提取并检测输入样本的重要特征来识别触发区域。
然后服务器将每个过滤器被随机发送到客户端,用于识别后门输入。对于被确定为后门的输入,客户端用模糊和标签翻转策略来清理数据上的后门触发区域,恢复数据的可用性。其中随机发送过滤器是为了防止攻击者故意对特定的过滤器进行攻击。
步骤
服务器端训练后门过滤器:
- 服务器需要收集现有攻击信息建立一个攻击库,里面有现有的恶意模型和相应的带有后门的数据样本。
- 对于攻击库中每一个恶意模型及相应的后门样本,服务器随机使用分类器模型初始化后门分类器,使用XAI模型初始化样本解释器 (即触发检测器)。
- 样本解释器将恶意模型 G a G_{a} Ga 、原始数据样本 x a x_{a} xa 以及模型对数据样本的预测 y a y_{a} ya 作为输入,同时输出显示数据样本重要特征的热图 S t = S_{t}= St= I ( G a , x a , y a ) I\left(G_{a}, x_{a}, y_{a}\right) I(Ga,xa,ya) 。
- 服务器设置一个阈值 α \alpha α 来选择最重要的特征。遍历重要特征热图 S t S_{t} St ,若 S t [ l ] > α S_{t}[l]>\alpha St[l]>α ,则最重要特征大小 x t = x t + 1 x_{t}=x_{t}+1 xt=xt+1 。如果样本是后 门样本,标记 y t = 1 y_{t}=1 yt=1 ,否则为 0 。
- 将若干组 { x t , y t } \left\{x_{t}, y_{t}\right\} {xt,yt} 作为训练数据来训练分类器,将 x t x_{t} xt 作为分类器的输入,分类器输出预测该样本是否带有后门。定义一个损失函 数,鼓励分类器预测情况与真正情况的差距最小化,根据损失函数来动态调整阈值 α \alpha α 。(注:这种方法仅选取了触发器的大小作为 后门特性对后门进行鉴别,也可以加入触发器的位置、形状等其他特性。)
- 每一轮中,服务器向每个参与的客户端发送一个不同的后门过滤器,后门过滤器由一个样本解释器、一个分类器和阈值 α \alpha α 组成。
客户端触发检测、触发清理和标签翻转:
- 触发检测。当客户端接受输入数据 a a a 时,用客户端的本地模型 L L L 输出其分类结果 y y y 。然后得到显示数据样本重要特征的热图 S = S= S= I ( L , a , y ) I(L, a, y) I(L,a,y) ,并根据阈值 α \alpha α 得到最重要特征的大小 s s s 。后门分类器利用最重要特征大小 s s s 判断样本是否为后门样本。若数据 a a a 是后门, 则对数据 a a a 进行后门的两步操作。
- 触发清理。若数据 a a a 是后门,可以推断后门触发区域贡献了 a a a 最重要的特征,于是将原始图像中与最重要的特征相对应的部分提取出 来作为 S ′ S^{\prime} S′ 。对于 S ′ S^{\prime} S′ 区域的每一个像素,触发器清理器会通过对它周围的像素值取平均对其进行代替,从而模糊掉可疑触发区域。
- 标签翻转。将模糊后的数据再次输入到局部模型 L L L 中,将模型输出的最大概率类别作为输入数据的预测类别,而如果预测类别与原 始预测结果相同,则模型选择第二个最可能的类别作为预测结果。
优点&效果
能够准确地识别带有触发器的后门数据,并能通过模糊的策略清理触发区域,从而能重用去了触发区域的数据,提高了数据利用率。
能够防御基于植入触发器的分布式协同后门攻击。
与安全聚合协议兼容。
不足&局限性
对攻击者的能力有过多的假设,假设攻击者能力是黑盒攻击,仅能对训练数据进行投毒,而无法控制客户端的行为。
需要后门模型和后门数据样本等先验知识训练过滤器和得到经验阈值。
仅对基于像素模式的后门触发器有用。
【2021 IEEE】Mitigating the Backdoor Attack by Federated Filters for Industrial IoT Applications
基于增强模型稳定性的防御方法
根据信息论,通过增加训练阶段参数的不确定性,可以提高模型的稳定性和泛化程度。因此可以通过丢弃部分优化信息来提高模型的泛化程度。而模型的泛化能力越强,抵御对抗样本带来的后门攻击的能力就越强。
基于dropout的防御方法
dropout是指在随机梯度下降(SGD)优化过程中,随机将梯度在某个分量上的权重设置为0,从而提高了模型的泛化能力和稳定性。而模型泛化能力越强,抵御对抗样本带来的后门攻击的能力就越强。
步骤
- 分别研究dropout比例与模型准确率(clean ACC)和后门攻击准确率(backdoor ACC)的关系。
实验表明,clean ACC和backdoor ACC均随着dropout的增加而下降,且超过一个阈值后会急剧下降。但是,这两者的阈值是不同的。
换言之,clean ACC和backdoor ACC的关系即为,clean ACC增大的同时,backdoor ACC也增大,但是存在一个转换点,这是一个clean ACC很高,而backdoor ACC很低的点。从而可以基于此设计防御机制。
- 定义评价学习模型稳定性的泛化误差的上界 ϵ \epsilon ϵ。
首先在良性数据集的基础上,通过在一部分样本中添加特定的后门触发器来构造包含后门样本和原始良性样本的后门数据集。
然后复制一个完全相同的后门数据集,并去除其中带有触发器的样本来构建一个新的良性数据集。
接着在后门数据集和良性数据集上分别用完全相同的网络结构训练后门模型和良性模型。
最后对于后门数据集中的每一个数据,分别通过后门模型和良性模型计算其损失值。将这两个损失值之间的误差的绝对值定义为模型的泛化误差。将所有泛化误差中的最大值定义为泛化误差的上界
ϵ
\epsilon
ϵ。
- 研究dropout比例与泛化误差上界的关系。
随着dropout的增加,泛化误差上界逐渐减小,即抵御敌对样本带来的后门攻击的能力逐渐增强。(但同时根据上一个实验的结果,随着dropout的增加,clean ACC也会下降。)
且泛化误差的上界在变化时也会出现一个转换点,在这个转换点之后,泛化误差上界急剧下降,即学习模型的稳定性迅速增强。
此外,对于不同的攻击比例,泛化误差上界的变化也非常相似。
- 基于过渡点设置最优的dropout参数。可以通过泛化误差上界发生急剧下降变化的点,来找到clean ACC很高,而backdoor ACC很低的过渡点,这个过渡点对应的dropout参数即为最优的dropout参数。
优点&效果
对于不同的攻击比例,泛化误差上界的变化非常相似,即过渡点非常相似,因此这种防御机制可以防御包含不同攻击者比例的后门攻击。
后门攻击成功率几乎为0。
在训练数据被后门投毒的情况下,这种基于稳定性的防御机制也能提高主任务的性能。
不足&局限性
实验设置的参与者数量较少,且参与者的数据是IID的,在有大量用户且数据为非IID分布的联邦学习场景中效果有所下降。
【2021 IEEE】Stability-Based Analysis and Defense against Backdoor Attacks on Edge Computing Services
纵向联邦学习后门攻击的防御方法
基于向主动方添加可训练层的防御方法
在主动方引入额外的防御训练层,比如可以在输出层之前加上一个具有32个节点的密集层。
优点&效果
可以减少标签信息的泄露,提高模型性能。
来源
【2020 ICML】Backdoor Attacks and Defenses in Feature-partitioned Collaborative Learning
基于差分隐私的防御方法
先剪裁恶意放大的梯度,然后再加入噪声。
优点&效果
在交换的消息中添加噪声的方法比剪裁的方法更加有效。
来源
【2020 ICML】Backdoor Attacks and Defenses in Feature-partitioned Collaborative Learning
基于梯度稀疏化的防御方法
将每次迭代中的下降率作为阈值,将阈值以内的小幅度的梯度直接剪裁为0。
优点&效果
梯度稀疏化可以在不影响主任务性能的情况下进一步增强防御的有效性。
来源
【2020 ICML】Backdoor Attacks and Defenses in Feature-partitioned Collaborative Learning
————————————————
版权声明:本文为CSDN博主「3077491278」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/w18727139695/article/details/123727138














 6299
6299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









