







前言
- 📚 笔记专栏:斯坦福CS231N:面向视觉识别的卷积神经网络(23)
- 🔗 课程链接:https://www.bilibili.com/video/BV1xV411R7i5
- 💻 CS231n: 深度学习计算机视觉(2017)中文笔记:https://zhuxiaoxia.blog.csdn.net/article/details/80155166
- 🔥 2023最新课程PPT:https://download.csdn.net/download/Julialove102123/88734395
⚠️ 本节重点内容:
- 可视化模型所学:过滤器可视化、最终层特征可视化、激活可视化
- 了解输入像素:识别重要像素、通过反向推理识别显著性、引导逆推生成图像、梯度上升可视化特征
- 对抗性扰动
- 风格迁移:特征反转、深度梦境、纹理合成、神经风格转移
一、模型可视化
我们在之前的课程里看到CNN的各种应用,在计算机视觉各项任务中发挥很大的作用,但我们一直把它当做黑盒应用,本节内容我们先来看看特征可视化,主要针对一些核心问题:
- CNN工作原理是什么样的
- CNN的中间层次都在寻找匹配哪些内容
- 我们对模型理解和可视化有哪些方法
1.1 第一个卷积层
1) 可视化卷积核
第一个卷积层相对比较简单,可以把第一层的所有卷积核可视化来描述卷积层在原始图像匹配和关注什么。
可视化卷积核的背后原理是,卷积就是卷积核与图像区域做内积的结果,当图像上的区域和卷积核很相似时,卷积结果就会最大化。我们对卷积核可视化来观察卷积层在图像上匹配寻找什么。
常见的CNN架构第一层卷积核如下:

从图中可以看到,不同网络的第一层似乎都在匹配有向边和颜色,这和动物视觉系统开始部分组织的功能很接近。
1.2 中间层
第一个卷积层使用16个3x7x7的卷积核,第二层使用 20个16x7x7的卷积核。由于第二层的数据深度变成16维,不能直接可视化。一种处理方法是对每个卷积核画出16个7x7的灰度图,一共画20组。
然而第二层卷积不和图片直接相连,卷积核可视化后并不能直接观察到有清晰物理含义的信息。

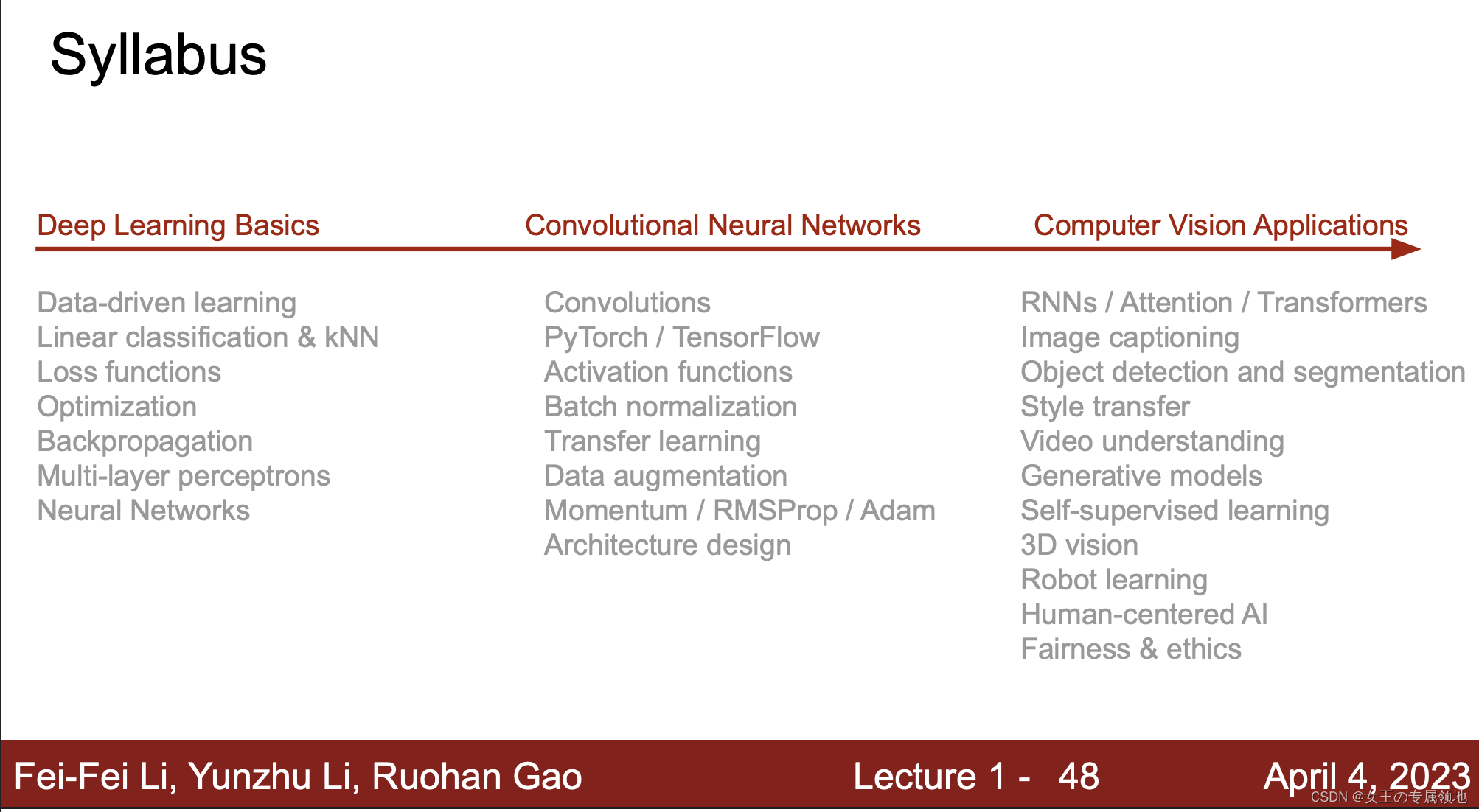
1) 可视化激活图
与可视化卷积核相比,将激活图可视化更有观察意义。比如可视化 AlexNet 的第五个卷积层的128个13x13的特征图,输入一张人脸照片,画出 Conv5 的128个特征灰度图,发现其中有激活图似乎在寻找人脸(不过大部分都是噪声)。
案例:

1.3 倒数第二个全连接层
1) 最邻近
另一个有价值的观察对象是输入到最后一层用于分类的全连接层的图片向量,比如 AlexNet 每张图片会得到一个 4096维的向量。

使用一些图片来收集这些特征向量,然后在特征向量空间上使用最邻近的方法找出和测试图片最相似的图片。作为对比,是找出在原像素上最接近的图片。可以看到,在特征向量空间中,即使原像素差距很大,但却能匹配到实际很相似的图片。比如大象站在左侧和站在右侧在特征空间是很相似的。
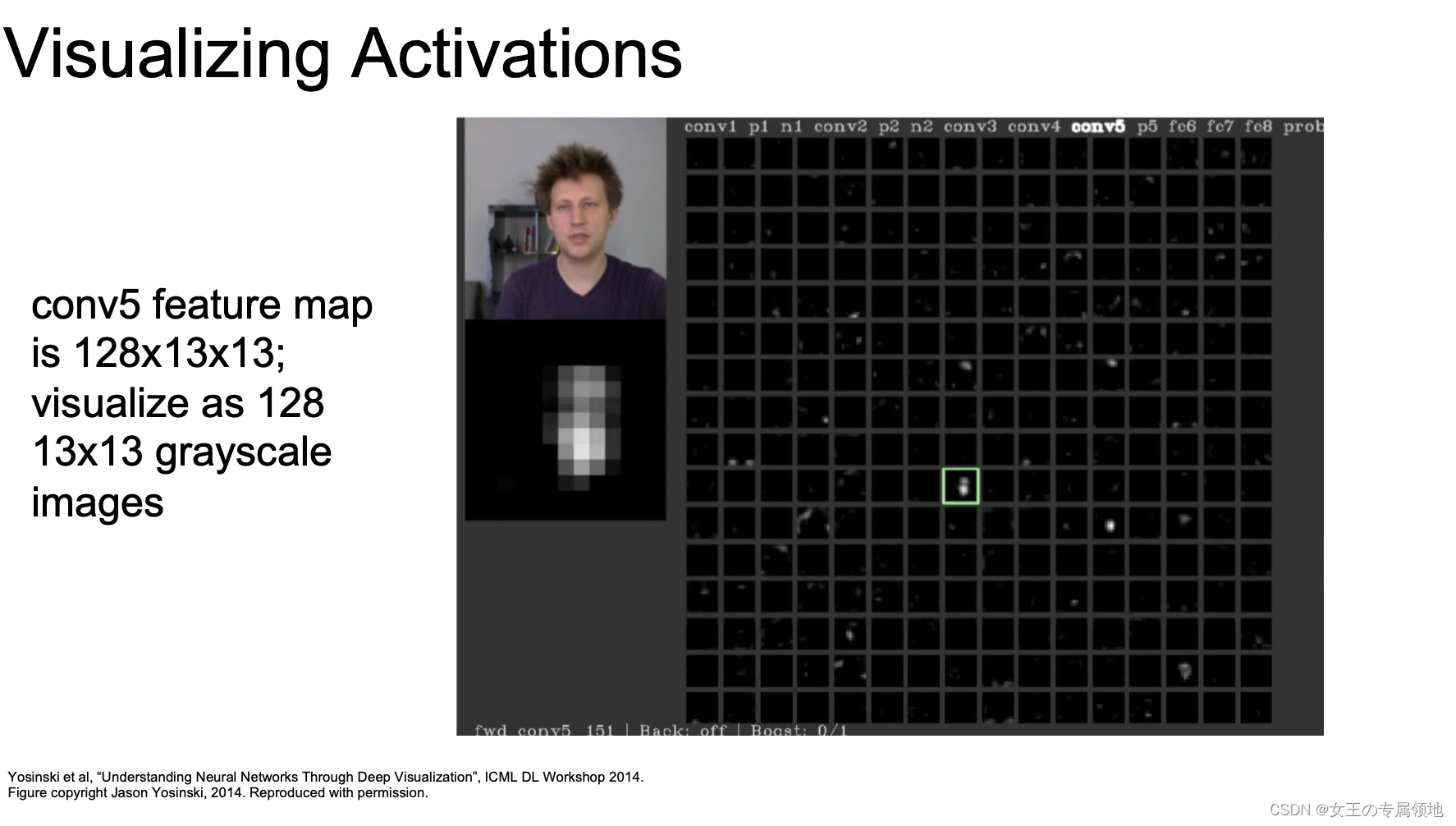
2) 降维
另一个观察的角度是将4096维的向量压缩到二维平面的点,方法有PCA,还有更复杂的非线性降维算法比如 t-SNE(t-distributed stochastic neighbors embeddings,t-分布邻域嵌入)。我们把手写数字 0-9 的图片经过CNN提取特征降到2维画出后,发现都是按数字簇分布的,分成10簇。如下图所示:
同样可以把这个方法用到 AlexNet 的 4096 维特征向量降维中。输入一些图片,得到它们的 4096 维特征向量,然后使用 t-SNE 降到二维,画出这些二维点的网格坐标,然后把这些坐标对应的原始图片放在这个网格里。

可以观察到相似内容的图片聚集在了一起,比如左下角都是一些花草,右上角聚集了蓝色的天空。
二、了解输入像素
2.1. 最大激活区块
可视化输入图片中什么类型的小块可以最大程度的激活不同的神经元。
-
比如选择 AlexNet 的 Conv5 里的第17个激活图(共 128 个),然后输入很多的图片通过网络,并且记录它们在 Conv5 第 17个激活图的值。
-
这个特征图上部分值会被输入图片集最大激活,由于每个神经元的感受野有限,我们可以画出这些被最大激活的神经元对应在原始输入图片的小块,通过这些小块观察不同的神经元在寻找哪些信息。

如图所示,每一行都是某个神经元被最大激活对应的图片块: -
有的神经元在寻找类似眼睛的东西
-
有的在寻找弯曲的曲线等
如果不使用 Conv5 的激活图,而是更后面的卷积层,由于**卷积核视野的扩大,寻找的特征也会更加复杂,比如人脸、相机等,**对应图中的下面部分。
2.2 哪些像素对分类起作用?
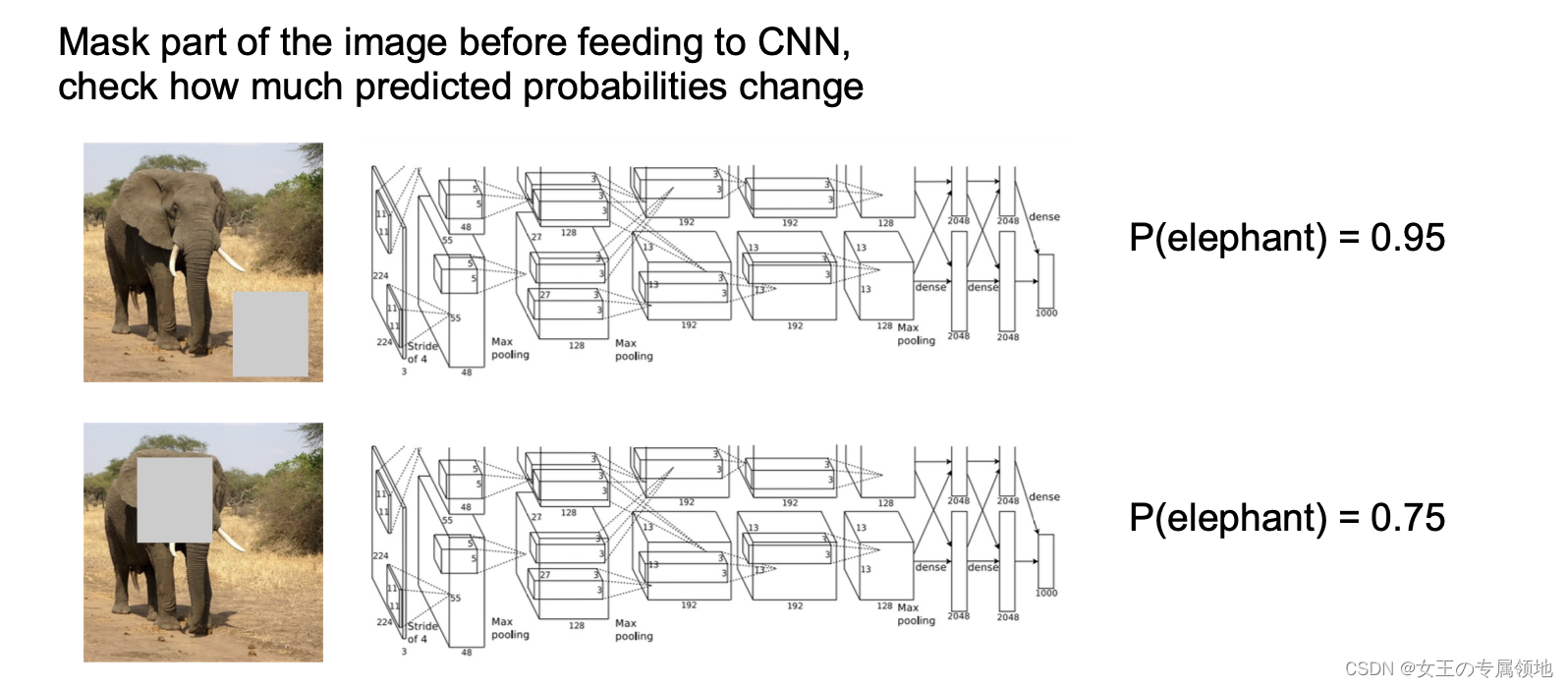
1) 遮挡实验(Occlusion)
在图片输入网络前,遮挡图片的部分区域,然后观察对预测概率的影响,可以想象得到,如果遮盖住核心部分内容,将会导致预测概率明显降低。如下图所示,是遮挡大象的不同位置,对「大象」类别预测结果的影响。
2) 显著图(Saliency Map)
除了前面介绍到的遮挡法,还有显著图(Saliency Map)法,它从另一个角度来解决这个问题。显著图(Saliency Map)方法是计算分类得分相对于图像像素的梯度,这将告诉我们在一阶近似意义上对于输入图片的每个像素如果我们进行小小的扰动,那么相应分类的分值会有多大的变化。可以在下图看到,基本上找出了小狗的轮廓。
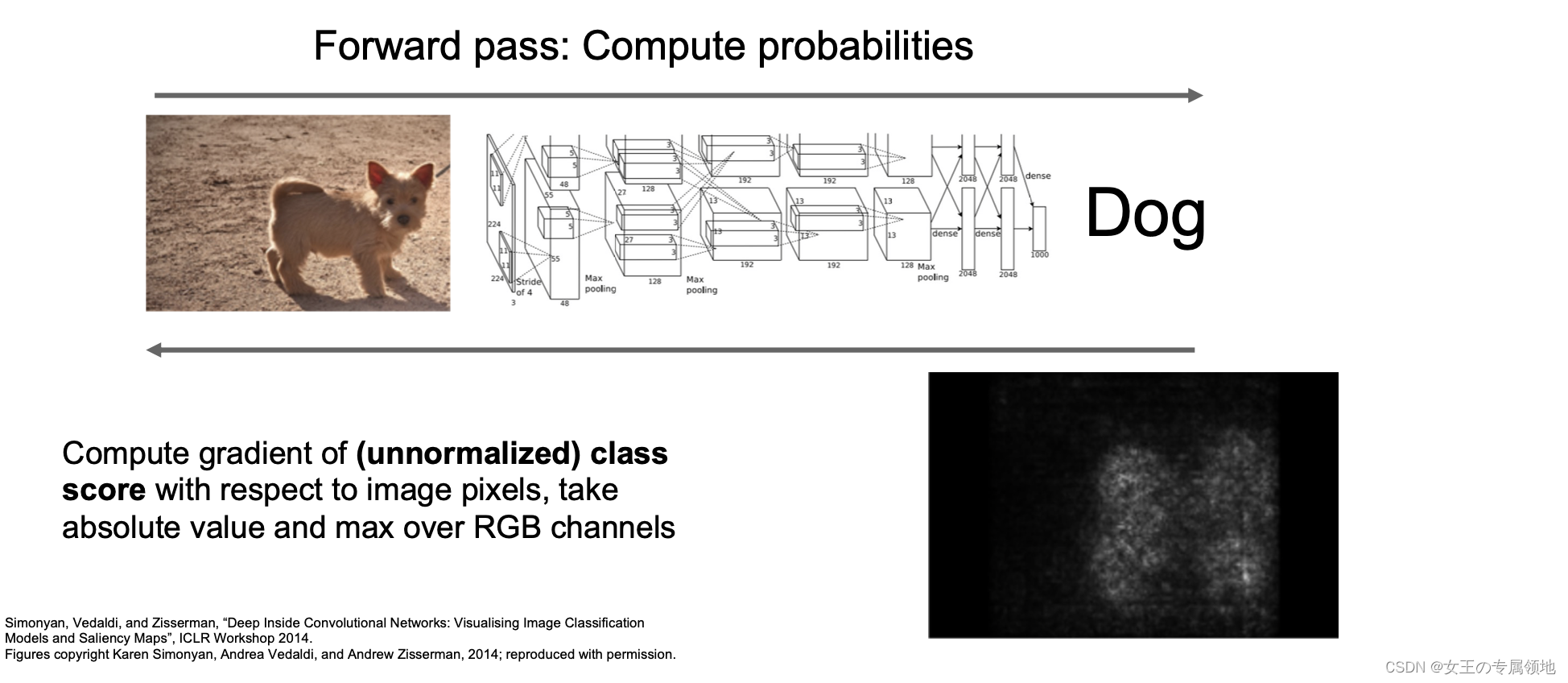
进行语义分割的时候也可以运用显著图的方法,可以在没有任何标签的情况下可以运用显著图进行语义分割。
3) 引导式反向传播
使用卷积网络某一层的一个特定神经元的值对像素求导,这样就可以观察图像上的像素对特定神经元的影响。但这里的反向传播是引导式的,即 ReLU 函数的反向传播时,只回传大于 0 的梯度,具体如下图所示。
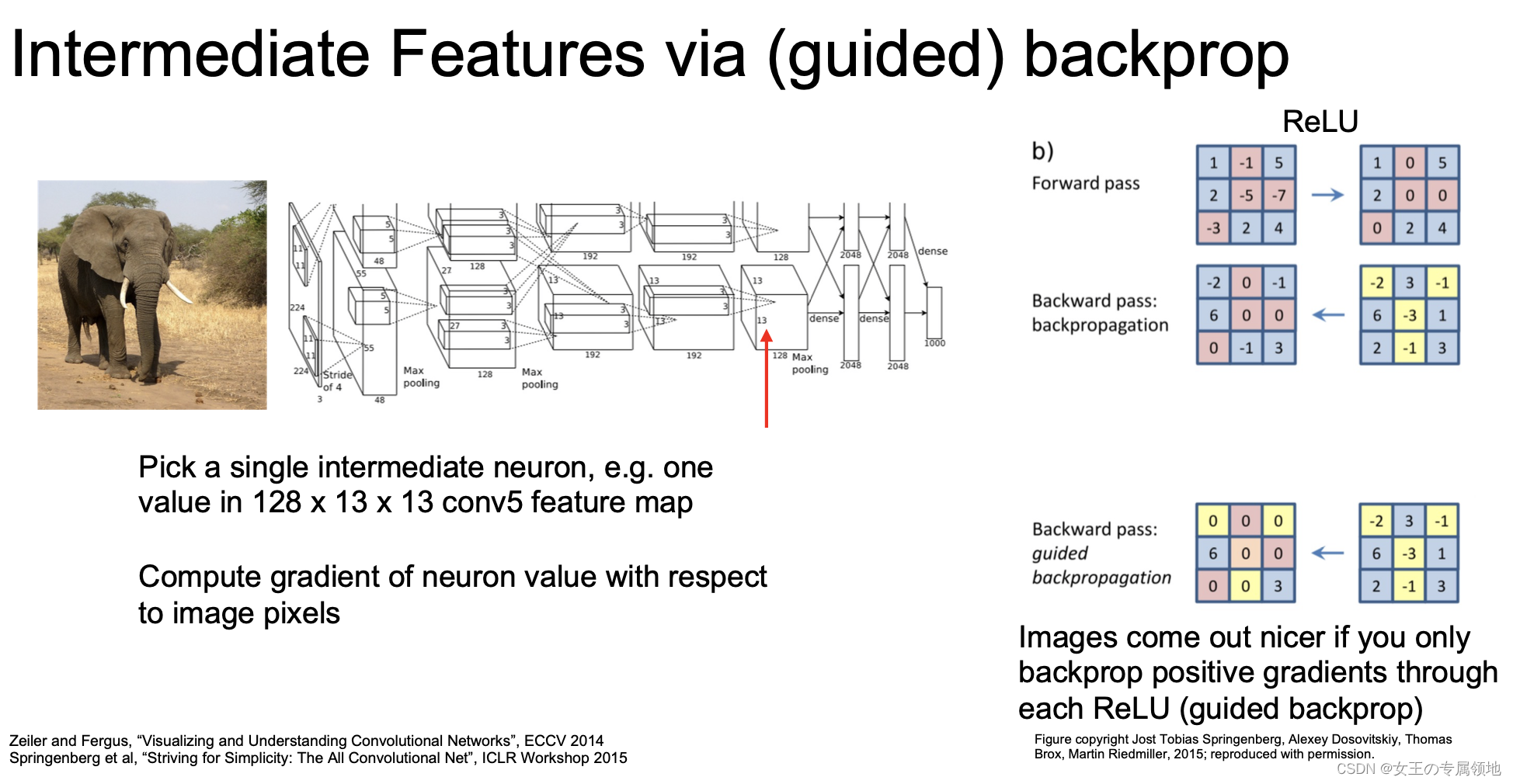
我们把引导式反向传播计算的梯度可视化和最大激活块进行对比,发现这两者的表现很相似。

- 左边是最大激活块,每一行代表一个神经元,右侧是该神经元计算得到的对原始像素的引导式反向传播梯度。
- 第一行可以看到,最大激活该神经元的图像块都是一些轮子的区域,这表明该神经元可能在寻找轮子形状物体,下图右侧可以看到圆形区域的像素会影响的神经元的值。
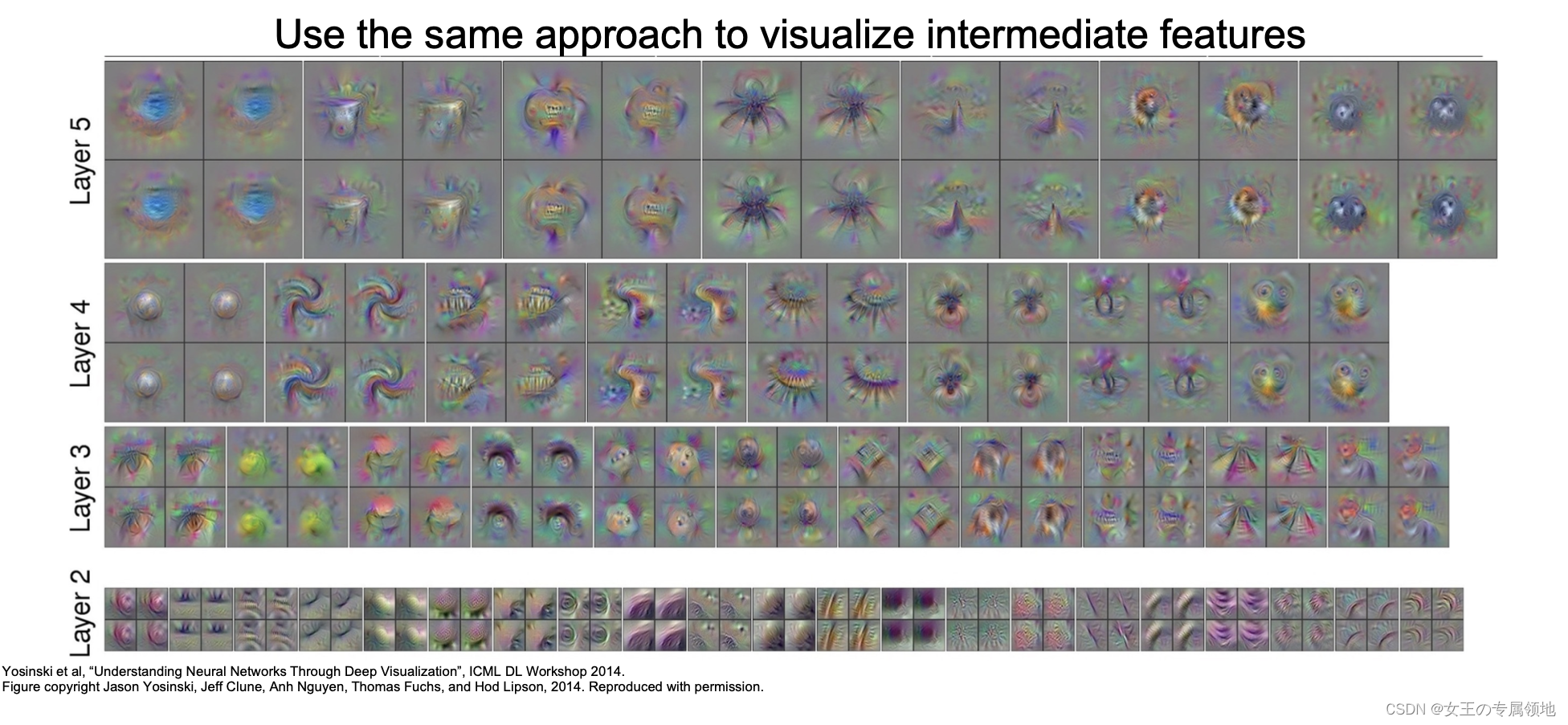
4) 梯度上升(Gradient Ascent)
引导式反向传播会寻找与神经元联系在一起的图像区域,另一种方法是梯度上升,合成一张使神经元最大激活或分类值最大的图片。
在训练神经网络时用梯度下降来使损失最小,现在我们要修正训练的卷积神经网络的权值,并且在图像的像素上执行梯度上升来合成图像,即最大化某些中间神将元和类的分值来改变像素值。
梯度上升的具体过程为:输入一张所有像素为0或者高斯分布的初始图片,训练过程中,神经网络的权重保持不变,计算神经元的值或这个类的分值相对于像素的梯度,使用梯度上升改变一些图像的像素使这个分值最大化。
同时,还会用正则项来阻止我们生成的图像过拟合。
总之,生成图像具备两个属性:
- 最大程度地激活分类得分或神经元的值;
- 希望这个生成的图像看起来是自然的;
正则项强制生成的图像看起来是自然的图像,比如使用 L2 正则来约束像素,针对分类得分生成的图片如下所示:

也可以使用其他方法来优化正则,比如:
- 对生成的图像进行高斯模糊处理
- 去除像素值特别小或梯度值特别小的值
上述方法会使生成的图像更清晰。也可以针对某个神经元进行梯度上升,层数越高,生成的结构越复杂。
添加多模态(multi-faceted)可视化可以提供更好的结果(加上更仔细的正则化,中心偏差)。通过优化 FC6 的特征而不是原始像素,会得到更加自然的图像。

三、Adversarial perturbations
一个有趣的实验是「愚弄网络」:
- Start from an arbitrary image
- Pick an arbitrary class
- Modify the image to maximize the class
- Repeat until network is fooled
输入一张任意图像,比如大象,给它选择任意的分类,比如考拉,现在就通过梯度上升改变原始图像使考拉的得分变得最大,这样网络认为这是考拉以后观察修改后的图像,我们肉眼去看和原来的大象没什么区别,并没有被改变成考拉,但网络已经识别为考拉.

四、风格迁移
3.1 特征反演(Feature Inversion)
3.2 Deep dream
3.3 纹理生成(Texture Synthesis)
3.4 神经风格迁移(Neural style transfer)
五、拓展阅读
- 斯坦福CS231n最全笔记:https://zhuanlan.zhihu.com/p/527899421
- CNN可视化/可解释性:https://blog.csdn.net/xys430381_1/article/details/90413169
- 万字长文概览深度学习的可解释性研究:https://zhuanlan.zhihu.com/p/110078466


















 5028
5028

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











