







系列文章目录
yolov5 win10 CPU与GPU环境搭建,亲测有效!
yolov5训练自己的数据集,详细教程!
yolov5转tensorrt模型
Jetson调用triton inference server详细笔记
yolov5模型部署:Triton服务器+TensorRT模型加速(基于Jetson平台)
前言
在完成yolov5环境搭建,训练自己的模型,以及将yolov5模型转换成Tensorrt模型后,下面就要对得到的tensorrt模型进行部署,本文采用的Triton服务器的部署方式。
本文是在完成yolov5转tensorrt模型、Jetson安装完成triton inference server的前提下进行的,故所用的模型文件也是以上文章中产生的。对这些步骤不熟悉的同学可以参考系列文章。
一、建立triton模型库
yolov5转tensorrt模型生成了yolov5s.engin与libmyplugins.so文件。
1.1config文件编写
config.pbtxt按如下例子编写:
platform: "tensorrt_plan"
max_batch_size : 1
input [
{
name: "data"
data_type: TYPE_FP32
dims: [ 3, 640, 640 ]
}
]
output [
{
name: "prob"
data_type: TYPE_FP32
dims: [ 6001, 1, 1]
}
]
其中input与output名称与维度在生成engine文件过程中就已确定。
1.2文件配置
将之前生成的yolov5s.engin改名为model.plan。另外还有生成的libmyplugins.so文件,按照下面tree放置:
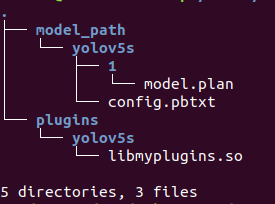
二、启动triton服务
cd 到tritonserver目录下,运行:
LD_PRELOAD=/media/nvidia/ubuntu_fs/plugins/yolov5s/libmyplugins.so ./tritonserver --model-repository=/media/nvidia/ubuntu_fs/model_path
这里需要把libmyplugins.so与model_path改为自己的路径

可以看到yolov5s模型已经启动成功了(这里我的model_path包含多个模型,如果同学们按照教程来只会出现一个yolov5s模型)
注意:这里必须要加载libmyplugins.so,否则模型无法正常启动。
三、启动客户端
这里需要自己编写前处理与后处理代码,下面给出样例代码:
https://github.com/JulyLi2019/tensorrt-yolov5(欢迎star!!!)
下面贴出client端关键部分代码:
inputs = []
outputs = []
inputs.append(grpcclient.InferInput('data', [1, 3, 640, 640], "FP32"))
outputs.append(grpcclient.InferRequestedOutput('prob'))
input_image_buffer = preprocess(frame, FLAGS.mask_y)
input_image_buffer = np.expand_dims(input_image_buffer, axis=0)
inputs[0].set_data_from_numpy(input_image_buffer)
results = triton_client.infer(model_name=FLAGS.model,
inputs=inputs,
outputs=outputs,
client_timeout=None)
result = results.as_numpy('prob')
detected_objects = postprocess(result, frame.shape[1], frame.shape[0], FLAGS.confidence, FLAGS.nms)
测试图片


测试视频

总结
Triton环境搭建与模型成功部署,整个过程相当痛苦,前前后后搞了有两周,特别是加载自己的模型时,遇到了很多问题,也询问一些CSDN的博主,这里特别感谢小屋*大神,不仅给了回答了我的很多问题,还给我提供了测试代码,虽然你不一定会看到这篇博客,但是还要谢谢你!!!
参考文档:
https://blog.csdn.net/weixin_48994268/article/details/118859830
http://doge.ac.cn/?p=2856
如果阅读本文对你有用,欢迎一键三连呀!!!
2021年8月24日15:55:18
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











