







HDFS常用命令及基础编程
JunLeon——go big or go home

目录
前言:
HDFS是Hadoop的分布式文件系统,旨在运行在商品硬件上。它与现有的分布式文件系统有很多相似之处。但是与其他分布式文件系统的区别是显着的。HDFS 具有高度容错性,旨在部署在低成本硬件上。HDFS 提供对应用程序数据的高吞吐量访问,适用具有大型数据集的应用程序。HDFS 放宽了一些 POSIX 要求,以启用对文件系统数据的流式访问。HDFS 最初是作为 Apache Nutch 网络搜索引擎项目的基础设施而构建的。HDFS 是 Apache Hadoop Core 项目的一部分。
一、HDFS概述
1、什么是HDFS?
HDFS(Hadoop Distributed File System)分布式文件系统。是Hadoop平台的数据存储系统,大多用于存储大型的离线数据。
HDFS 具有主/从架构。HDFS 集群由单个 NameNode 组成,NameNode 是一个主服务器,用于管理文件系统命名空间并管理客户端对文件的访问。此外,还有许多 DataNode,通常集群中的每个节点一个,用于管理连接到它们运行的节点的存储。HDFS 公开了一个文件系统命名空间,并允许将用户数据存储在文件中。在内部,文件被分成一个或多个块,这些块存储在一组 DataNode 中。NameNode 执行文件系统命名空间操作,如打开、关闭和重命名文件和目录。它还确定块到 DataNode 的映射。DataNode 负责处理来自文件系统客户端的读写请求。DataNode 还执行块的创建、删除等操作。
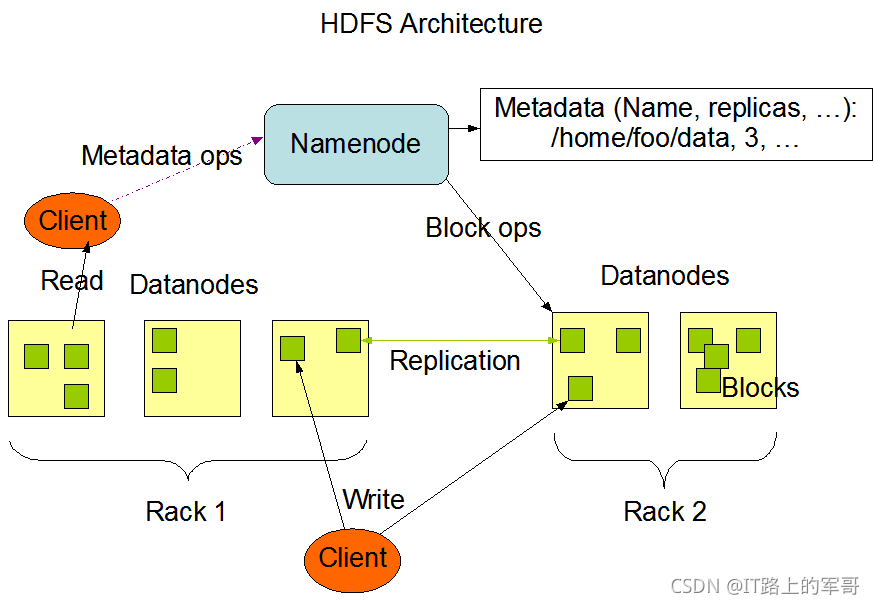
HDFS的Master/Slave架构主要由HDFS Client、NameNode、DataNode和Secondary NameNode四个部分组成,各组件介绍如下:
HDFS Clent:HDFS的客户端,与NameNode交互的程序,职责或功能如下:
(1)文件切分:在上传文件至HDFS的时候,Client会将文件分切成一个个的Block上传;
(2)与NameNode交互,可以获取文件的位置信息(存在哪个节点上);
(3)Client可以通过一些命令来访问HDFS,比如增删改查操作;
(4)Client通过一些命令来管理HDFS,比如将NameNode格式化。
NameNode:就是master,负责管理DataNode和管理HDFS的相关信息:
(1)管理HDFS的名称空间;
(2)管理副本的策略;
(3)管理数据块(Block)的映射信息;
(4)处理客户端的读写请求。
Secondary NameNode:并非是NameNode的热备。当NameNode挂掉的时候,它并不会立即替换NameNode并提供服务。
(1)辅助NameNode,分担其工作量,比如定期合并FsImage和Edits,并将合并后的FsImage.checkPoint推送给NameNode;
(2)在紧急情况下可以辅助恢复NameNode。
DataNode:就是slave,NameNode下达指令,DataNode执行实际的操作:
(1)存储实际的数据块;
(2)执行数据块的读/写操作。
2、HDFS数据存储模式——数据块(block)
HDFS主要以数据块(block)的模式对数据进行存储。
在Hadoop2.0以前,默认数据块大小为64Mb;Hadoop2.0以后版本默认数据块大小为128Mb。 block大小可以通过配置参数(dfs.blocksize)来设置。
采用数据块的模式存储数据的优点:
支持大规模文件存储:一个很大的文件可以被拆分为若干文件块,不同的文件块可以被分发到不同的节点上。因此一个文件的大小不会受单个节点的存储容量的限制。
简化系统设置:首先,简化存储管理,因为文件大小是固定的,这样就很容易算出一个节点可以存放多少文件块。其次,简化元数据的管理,元数据不需要和文件块一起存储。
适合数据备份:每个文件块都可以冗余地存储到多个节点上
3、HDFS的副本存放策略及机架感知
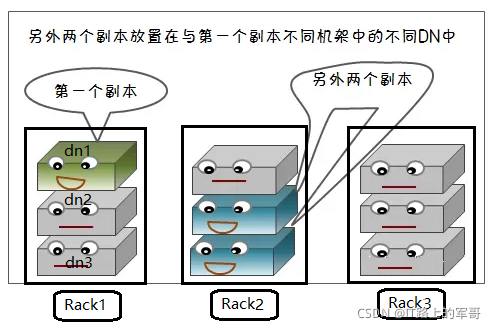
HDFS文件系统中,默认的副本存放数量为3,在写入数据是会自动的进行备份,副本数量可在hdfs-site.xml中(dfs.replication)来设置。
(1)副本存放策略:
1、第一个副本存储在本机(本地节点),这里所说的本地节点是相对于客户端来说的,也就是说某一个用户正在用一个客户端来向HDFS中写数据,如果该客户端上有数据节点,那么就应该最优先考虑把正在写入的数据的一个副本保存在这个客户端的数据节点上,它即被看做是本地节点。
2、第二个副本块存跟本机不同机架内的任意服务器节点。
3、第三个副本块存与第二个副本所在节点同一机架最近的另一个节点上。
作用:保证对该block所属文件的访问能够优先在本rack下找到,如果整个rack发生了异常,也可以在另外的rack上找到该block的副本。这样足够的高效,并且同时做到了数据的容错。这种策略设置可以将副本均匀分布在集群中,有利于当组件失效的情况下的均匀负载。
(2)机架感知:
通常,大型Hadoop集群会分布在很多机架上。在这种情况下,
1.希望不同节点之间的通信能够尽量发生在同一个机架之内,而不是跨机架。
2.为了提高容错能力,名称节点会尽可能把数据块的副本放到多个机架上。
综合考虑这两点的基础上Hadoop设计了机架感知功能
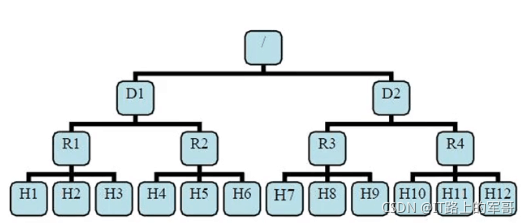
有了机架感知。NameNode就能够画出上图所看到的的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。
则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的parent是D1。这些rackid信息能够通过topology.script.file.name配置。有了这些rackid信息就能够计算出随意两台datanode之间的距离。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R1/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode4、HDFS的读写过程
(1)读流程:
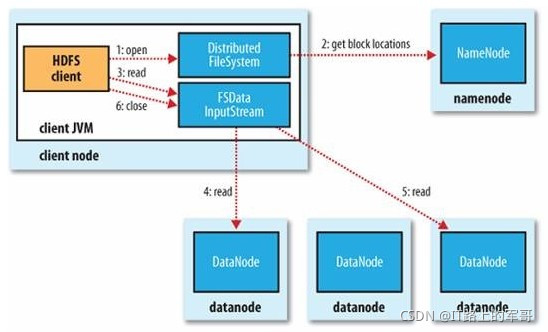
读详细步骤:
1、client访问NameNode,查询元数据信息,获得这个文件的数据块位置列表,返回输入流对象。
2、就近挑选一台datanode服务器,请求建立输入流 。
3、DataNode向输入流中中写数据,以packet为单位来校验。
4、关闭输入流
(2)写流程:
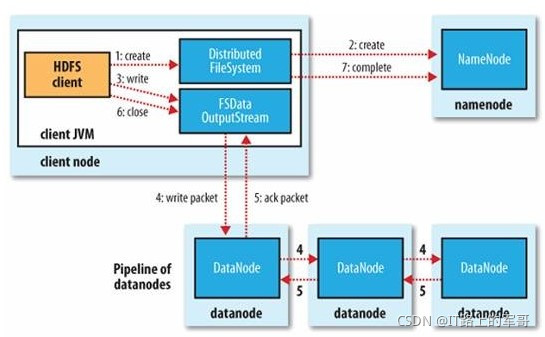
写详细步骤:
1、客户端向NameNode发出写文件请求。
2、检查是否已存在文件、检查权限。若通过检查,直接先将操作写入EditLog,并返回输出流对象。
(注:WAL,write ahead log,先写Log,再写内存,因为EditLog记录的是最新的HDFS客户端执行所有的写操作。如果后续真实写操作失败了,由于在真实写操作之前,操作就被写入EditLog中了,故EditLog中仍会有记录)
3、client端按128MB的块切分文件。
4、client将NameNode返回的DataNode列表和Data数据一同发送给最近的第一个DataNode节点,此后client端和多个DataNode构成pipeline管道。
client向第一个DataNode写入一个packet,这个packet便会在pipeline里传给第二个、第三个…DataNode。
在pipeline反方向上,逐个发送ack(命令正确应答),最终由pipeline中第一个DataNode节点将ack发送给client。
5、写完数据,关闭输输出流.
6、发送完成信号给NameNode。
二、HDFS常用命令
1、Hadoop命令
| 命令名称 | 命令格式 | 作用 |
|---|---|---|
| -help | hadoop -help | 查看hadoop命令的使用信息 |
| version | hadoop version | 查看hadoop的版本信息 |
| jar | hadoop jar project.jar Class.main | 运行jar文件 |
| fs | hadoop fs commond | 操作HDFS文件系统 |
| namenode -format | hadoop namnode -format | 格式化NameNode |
示例:
hadoop -help # 帮助命令,查看hadoop命令详情
hadoop version # 查看hadoop版本信息
hadoop jar jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar #运行自带的测试包
hadoop namenode -format # 格式化NameNode,这个命令在启动HDFS前已经执行过2、HDFS常用命令
HDFS操作命令也可用: hdfs dfs [-command]
| 命令名称 | 命令格式 | 作用 |
|---|---|---|
| -cat | hadoop fs -cat <hdfs:pathFile> | 查看HDFS文件系统里的文件内容 |
| -ls | hadoop fs -ls <hdfs:path> | 查看HDFS文件系系统的目录 |
| -mkdir | hadoop fs -mkdir <hdfs:pathDir> | 创建HFDS的目录 |
| -rm | hadoop fs -rm <hdfs:pathFile> | 删除HDFS中的文件或目录 |
| -cp | hadoop fs -cp <hdfs:pathFile> | 复制HDFS中的文件或目录 |
| -mv | hadoop fs -mv <hdfs:pathFile> | 移动HDFS中的文件或目录 |
| -put | hadoop fs -put <loacl:pathfile > <hdfs:pathFile> | 将本地文件或目录进行上传到HDFS |
| -copyFormLocal | hadoop fs -copyFormLocal <loacl:pathfile > <hdfs:pathFile> | 同上,类似于put命令 |
| -get | hadoop fs -get <hdfs:pathFile> <loacl:pathfile > | 将HDFS的文件下载到本地 |
| -copyToLocal | hadoop fs -copyToLocal <hdfs:pathFile> <loacl:pathfile > | 同上,类似于get命令 |
| -du | hadoop fs -du <hdfs:pathFile> | 显示HDFS中的文件或目录的大小 |
| -dus | hadoop fs -dus <hdfs:pathFile> | 显示HDFS中的指定目录的大小 |
| -touchz | hadoop fs -touchz <hdfs:pathFile> | 创建一个0字节的空文件 |
| -text | hadoop fs -text <hdfs:pathFile> | 将源文件输出为文本格式。允许的格式是zip和TextRecordInputStream。 |
部分命令示例:
hadoop fs -ls / # 查看HDFS的根目录
hadoop fs -ls -R / #递归查看HDFS的根目录/
hadoop fs -mkdir /data # 在HDFS中创建一个data目录
hadoop fs -touchz /data/a.txt # 在HDFS的/data目录下创建一个0字节的空文件a.txt
hadoop fs -cp /data/a.txt /data/b.txt #将/data目录下的a.txt复制一份在当前目录重命名为b.txt
hadoop fs -mv /data/a.txt / # 将HDFS的/data目录下的a.txt移动到HDFS的根目录
hadoop fs -cat /a.txt # 查看HDFS根目录下的a.txt,由于刚刚创建的是空文件,显示没有内容,可查看其他文件
hadoop fs -get /a.txt /~ # 将HDFS根目录下的a.txt下载到本地/home目录(本地指的是虚拟机)
hadoop fs -put /~/a.txt /data/ # 将家目录下的a.txt上传到HDFS中的data目录下3、安全模式
NameNode在启动时会自动进入安全模式,安全模式是NameNode的一种状态,在这个阶段,文件系统不允许有任何修改。
系统显示Name node in safe mode,说明系统正处于安全模式,这时只需要等待几十秒即可,也可通过下面的命令退出安全模式:
hadoop dfsadmin -safemode leave也可以进入安装模式:
hadoop dfsadmin -safemode enter三、HDFS API 基础编程
1、Eclipse的环境搭建(hadoop插件)
(1)环境准备
java下载并安装:(安装过程略)
java版本: jdk-8u91-windows-x64
百度云下载:链接:https://pan.baidu.com/s/1rCd7LHGyc3oMk0SFc95DEg 提取码:8888
Eclipse下载并安装:(安装过程略)
Hadoop下载并解压:
基于Eclipse的Hadoop插件下载:
百度云 链接:https://pan.baidu.com/s/1nCCNgzKvy70X3LUKEex_IA 提取码:8888
(2)环境配置
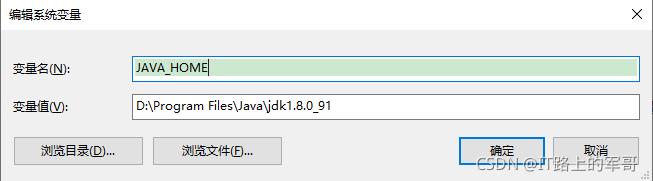
配置java环境变量:
1、右键单击桌面 我的电脑/此电脑-->属性-->找到高级系统设置-->环境变量-->下面的系统变量-->新建变量
JAVA_HOME=D:\Program Files\Java\jdk1.8.0_91 (自己安装的路径)
新建变量,如图:
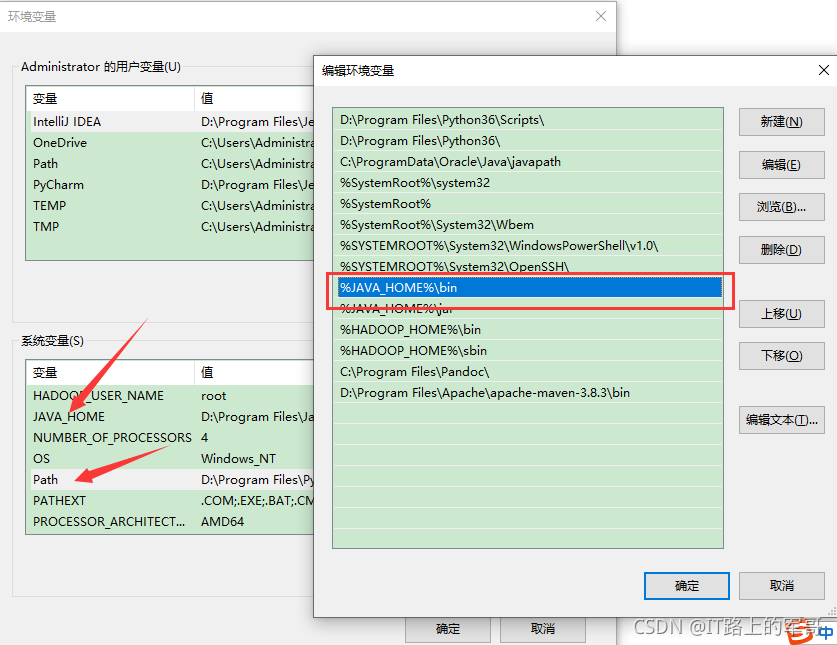
2、找到Path,添加 %JAVA_HOME%\bin
配置hadoop环境变量:
1、右键单击桌面 我的电脑/此电脑-->属性-->找到高级系统设置-->环境变量-->系统变量-->新建变量
HADOOP_HOME=D:\SoftWare\hadoop-2.7.3 (自己安装的路径)

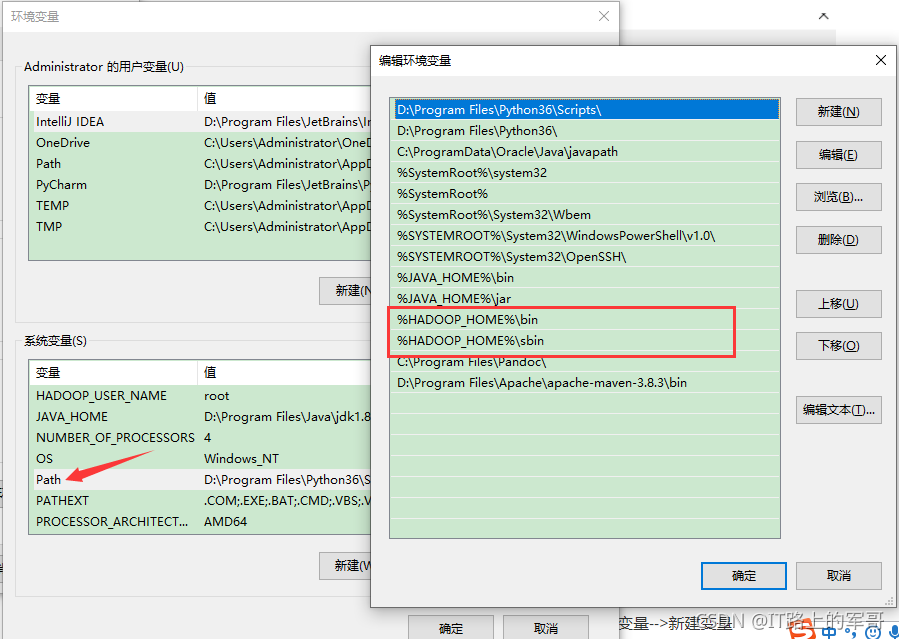
2、找到Path,添加 %HADOOP_HOME%\bin、%HADOOP_HOME%\sbin
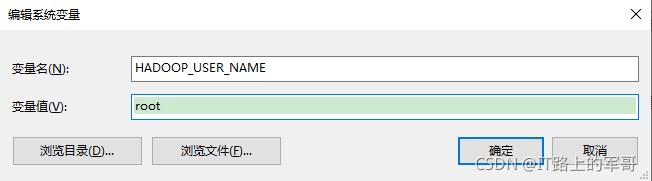
配置Hadoop用户名:HADOOP_USER_NAME
右键单击桌面 我的电脑/此电脑-->属性-->找到高级系统设置-->环境变量-->系统变量-->新建变量
添加变量:HADOOP_USER_NAME=root
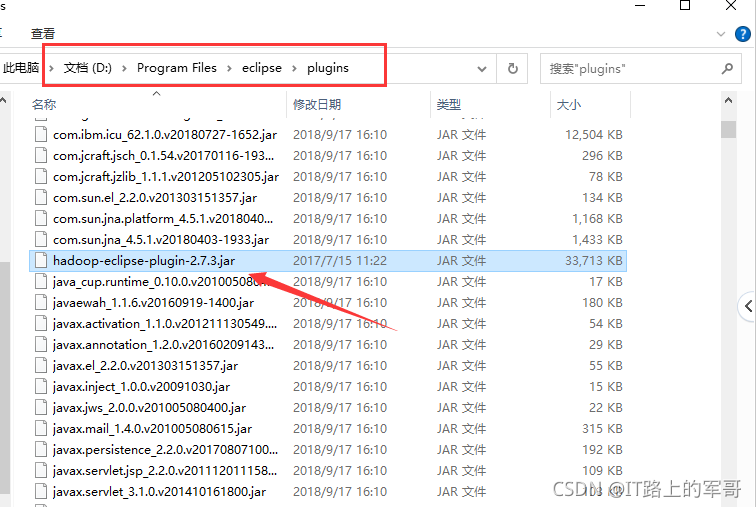
配置hadoop-eclipse插件:
1、将下载好的hadoop-eclipse-plugin-2.7.3.jar复制到eclipse的plugins目录下
2、将下载好的hadoop.dll和winutils.exe复制到hadoop的bin目录下

(3)环境测试
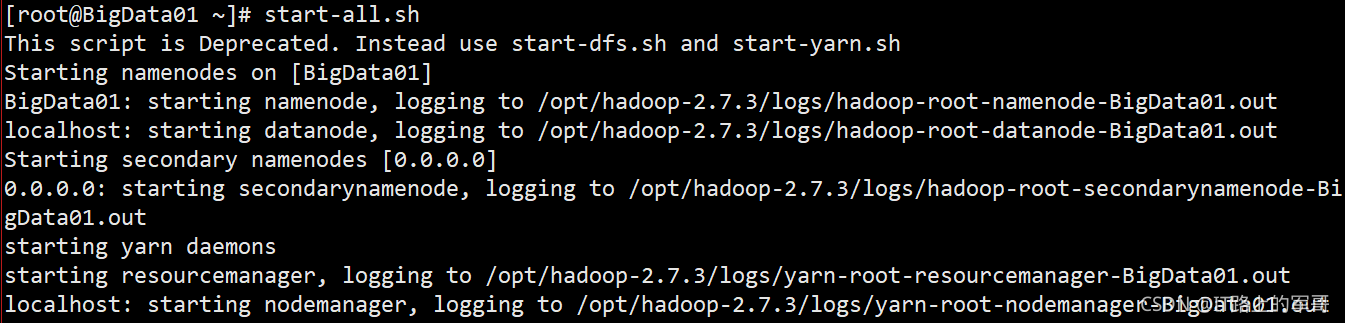
1、在Hadoop伪分布式或者分布式上先开启HDFS节点(可以先在Web端进行访问)
开启节点:(伪分布式)
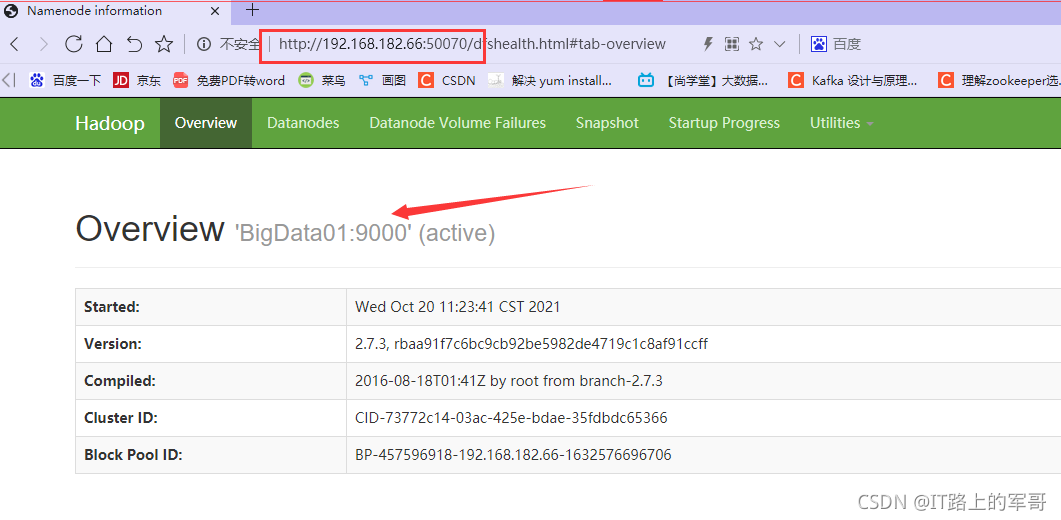
Web端访问:
在浏览器里输入ip:50070即可访问到DHFS主页
2、在Eclipse中连接到HDFS
启动 Eclipse 后就可以在左侧的Project Explorer中看到DFS Locations
注:如果没有DFS Locations显示项则直接创建MapReduce项目打开新的视图后会出现

选择 Window 菜单下的 Preference
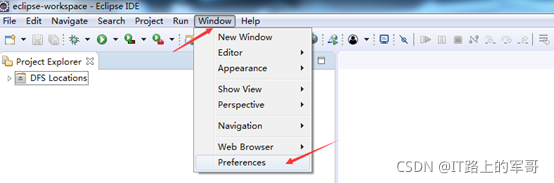
此时会弹出一个窗体,点击选择 Hadoop Map/Reduce 选项,选择 Hadoop 的安装目录(例如:D:\SoftWare\hadoop-2.7.3)
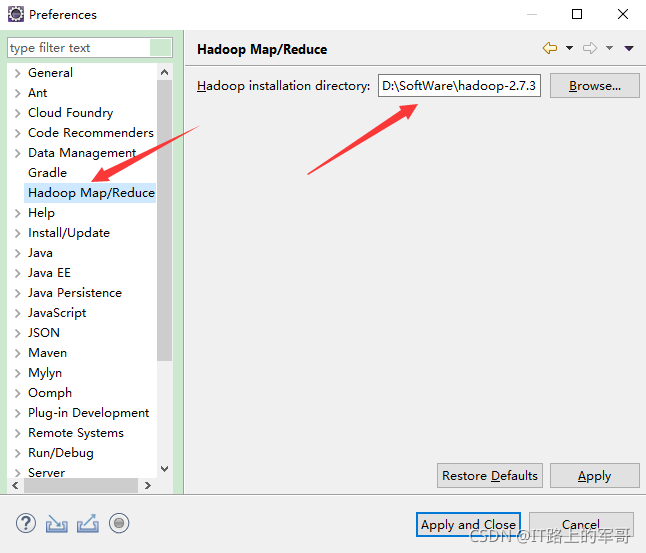
切换 Map/Reduce 开发视图
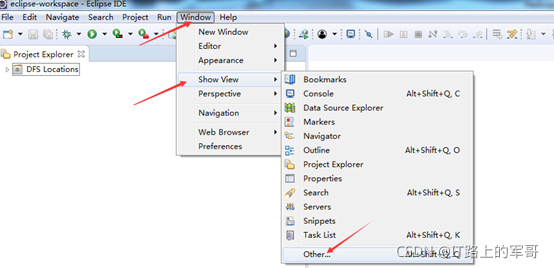
选择Other中,找到MapReduce Tools-->MapReduce Location
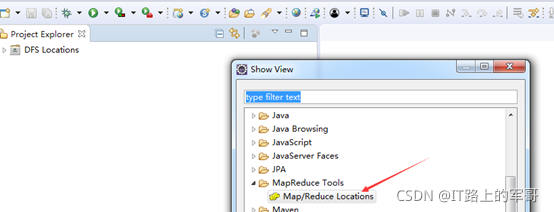
在下面既可以看到 MapReduce Location ,开始连接HDFS:

在弹出来的General选项面板中,General 的设置要与 Hadoop主机的配置一致。
Location Name:随意填写
DFS Master:
伪分布式:
Host:设置你的主机名,也可以为 IP地址(建议用IP,用主机名需要在Windows中配网络映射)
Port 改为 9000。(此端口和hadoop里core-site.xml中设置的端口号一致,有人配置为8020,则改为8020)
Map/Reduce(V2) Master: Host和Port 用默认的即可
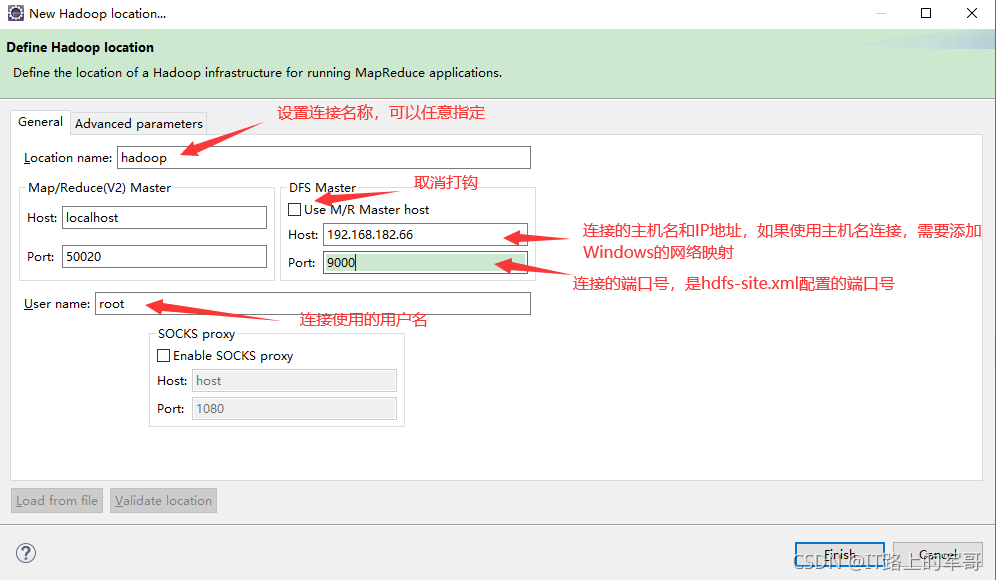
如果出现以下错误:是因为Windows下没有给主机名hadoop配置网络映射
Windows中网络配置文件c:/windows/system32/drivers/etc/hosts
在hosts文件末尾添加:192.168.182.66 hadoop
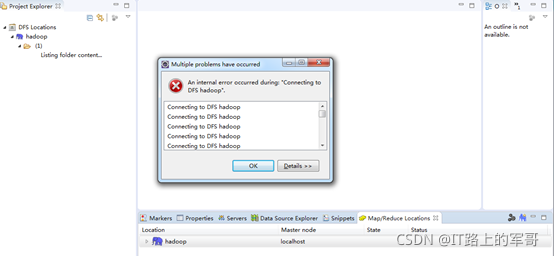
连接成功后:
2、HDFS API
创建项目:
1.在eclipse中,File --> New --> Project 
找到Map/Reduce --> MapReduce Project

下一步:输入项目名,完成
在项目中src下创建类并创建包:
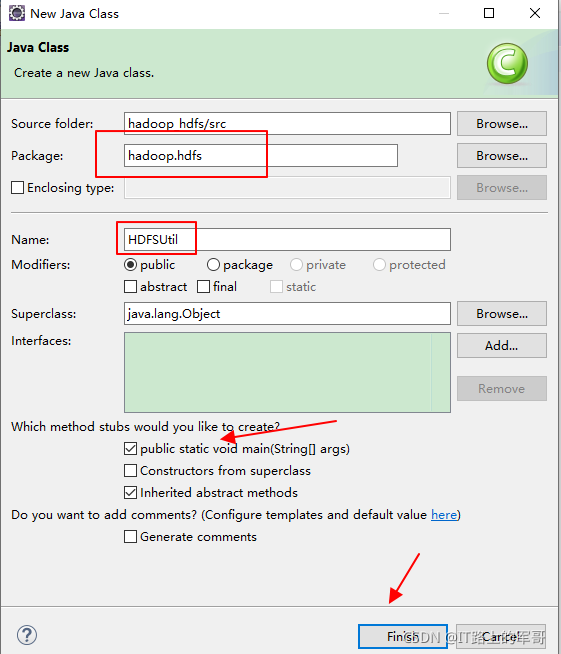
HFDS API:
main函数中的调用:
public static void main(String[] args) throws IOException {
//在集群上创建新文件,并写入字符内容,如下:
//如果工程里没有加入core-site.xml、hdfs-site.xml,则下面参数中的文件名前必须指定 HDFS通信地址 (如:hdfs://IP:端口号/ )
//创建一个新文件hello.txt
createFile("hdfs://192.168.182.66:9000/hello.txt", "Hello world! Welcome to learn Hadoop! HDFS, Mapreduce!\n");
//读取hello.txt文件内容
readFile("hdfs://192.168.182.66:9000/hello.txt");
//上传文件
//uploadFile("D:\\a.txt","hdfs://192.168.182.66:9000/a.txt");
//显示文件属性详情
showFile("hdfs://192.168.182.66:9000/hello.txt",true);
//查看数据块信息
showLocation("hdfs://192.168.182.66:9000/hello.txt/hello.txt");
//获取集群上的节点信息
showDataNodeName();
//删除指定文件hello.txt
//deleteFile("hdfs://192.168.182.66:9000/hello.txt/hello.txt");
}注:单个调用方法时,请把其他方法注释掉
(1)创建新文件
public static void createFile(String dstPath, byte[] contents) throws IOException {
Configuration conf = new Configuration(); //获取配置文件
FileSystem fs = FileSystem.get(conf); //创建一个文件系统对象
Path dst = new Path(dstPath); //将传入的dstPath转换为path对象
FSDataOutputStream outputStream = fs.create(dst); //创建指定文件
outputStream.write(contents); //将字节数组的内容写入文件
outputStream.close(); //关闭输出流
fs.close(); //关闭文件系统
System.out.println("文件创建成功!");
}
public static void createFile(String dstPath,String contents) throws IOException {
byte[] buffer = contents.getBytes(); //文件内容-->字节数组
createFile(dstPath,buffer);
}
以上代码还可以优化成一个方法:(上下两种代码选择一种即可)
public static void createFile(String dstPath, String contents) throws IOException {
Configuration conf = new Configuration(); //获取配置文件
FileSystem fs = FileSystem.get(conf); //创建一个文件系统对象
Path dst = new Path(dstPath); //将传入的dstPath转换为创建path对象
FSDataOutputStream outputStream = fs.create(dst); //创建指定文件
byte[] buffer = content.getBytes(); //文件内容--字节数组
outputStream.write(buffer,0,buffer.length); //将字节写入
outputStream.close(); //关闭输出流
fs.close(); //关闭文件系统
System.out.println("文件创建成功!");
}(2)删除文件
//HDFS中删除指定的文件
public static void deleteFile(String filePath) throws IOException {
Configuration conf = new Configuration(); //获取配置文件
FileSystem fs = FileSystem.get(conf); //创建文件系统
Path path = new Path(filePath); //将传入的filePath转换为Path对象
boolean isOk = fs.deleteOnExit(path); //调用deleteOnExit方法删除文件,并将返回的状态赋值给boolean变量
if(isOk) { //判断文件是否删除
System.out.println("文件已被删除!");
}else {
System.out.println("删除文件失败!");
}
}(3)上传文件到HDFS指定目录中
//从本地上传文件到HDFS
public static void uploadFile(String src,String dst) throws IOException {
Configuration conf = new Configuration(); //获取配置文件
FileSystem fs = FileSystem.get(conf); //创建文件系统
Path srcPath = new Path(src); //实例化本地文件路径
Path dstPath = new Path(dst); //实例化上传后的HDFS路径
fs.copyFromLocalFile(srcPath, dstPath); //调用copyFromLocalFile方法将本地文件上传
FileStatus[] fileStatus = fs.listStatus(dstPath); //创建一个FileStatus类型数组接收指定文件的属性
for (FileStatus file : fileStatus) { //遍历数组
System.out.println("HDFS中目标文件路径" + file.getPath()); //打印输出该文件的路径属性
System.out.println("上传文件成功!");
}
}(4)读取文件内容
//读取HDFS中指定文件的内容
public static void readFile(String filePath) throws IOException {
Configuration conf = new Configuration(); //获取配置文件
FileSystem fs = FileSystem.get(conf); //创建文件系统
Path path = new Path(filePath); //实例化文件路径
FSDataInputStream inputStream = null;
try{
inputStream = fs.open(path);
IOUtils.copyBytes(inputStream, System.out, 4096, false);
} finally {
IOUtils.closeStream(inputStream);
}
}(5)显示文件属性
public static void showFile(String filePath,boolean isDetail) throws IOException {
Configuration conf = new Configuration(); //获取配置文件
FileSystem fs = FileSystem.get(conf); //创建文件系统
Path path = new Path(filePath); //创建一个路径地址
FileStatus dstStatus = fs.getFileStatus(path); //创建文件属性对象
if(dstStatus.isDirectory()) { //判断是否是一个目录
System.out.println("这是一个目录,目录下的文件及子目录有:");
for (FileStatus file : fs.listStatus(path)) { //遍历属性列表
if(isDetail) { //判断是否打印输出文件的详细信息
System.out.println((file.isDirectory() ? "d" : "-") +
file.getPermission().toShort() + " " + //获取指定文件的权限
file.getOwner() + "\t" + //获取指定文件的所有者
file.getGroup() + "\t" + //获取指定文件的所属组
file.getLen() + "\t" + //获取指定文件的长度
new TimeStamp(file.getModificationTime()).toString() + "\t" + //获取指定文件修改时间
file.getPath().toString() //获取文件的路径
);
} else {
System.out.println(file.getPath().toString()); //只输出文件路径属性
}
}
}
}(6)显示数据块信息
private static void showLocation(String path) throws IOException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf); //获取配置文件
Path dst = new Path(path);
FileStatus filestatus = fs.getFileStatus(dst);
BlockLocation[] locations = fs.getFileBlockLocations(filestatus, 0, filestatus.getLen());
//可能存在多个节点
for(int i=0; i<locations.length; i++){
String[] host = locations[i].getHosts();
for(int j=0; j<host.length; j++){
System.out.println("block_"+i+": "+host[j]);
}
}
}(7)查看DataNode节点信息
private static void showDataNodeName() throws IOException {
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf); //获取配置文件
DistributedFileSystem hdfs = (DistributedFileSystem) fs; //创建分布式文件系统对象
//获取各数据节点信息
DatanodeInfo[] dataNodeStatus = hdfs.getDataNodeStats();
for(int i=0; i<dataNodeStatus.length; i++){
System.out.println("DataNode_Name: "+dataNodeStatus[i].getHostName());
System.out.println("DataNode_IP: "+dataNodeStatus[i].getIpAddr());
System.out.println("DataNode_IpcPort: "+dataNodeStatus[i].getIpcPort());
}
}下一篇:MapReduce初级编程实践(超详细)
如果你喜欢、对你有帮助,点赞+收藏,跟着军哥学知识……
















 1232
1232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











