







之前讲到了初步试验的结果,但那种算法对应的数据数据集不适合载入回收数据。
实际实验时用的是如下的算法:
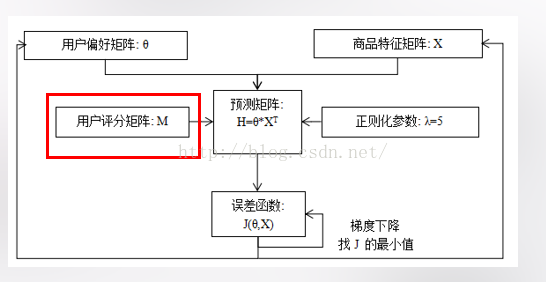
这是个很常见的机器学习线性推荐算法,在coursera的machine learning 里Andrew Ng老师做了很详细的解析,这里就不做过多陈述了。
接下来就要处理回收数据了,把它和购买数据整合在一起。
我们就遇到了个问题:回收的物品在电子商场里不存在。
确实啊这问题很现实,一个创业公司的电子商城怎么可能涵盖全部在世界流通的商品,商城里只有大概800种商品,是要被推荐的,可回收数据里有大概10,0000种独立商
品,因此我们需要找出商城内物品和回收物品的相似之处。

一种很合理的方法就是对商城商品、回收物品归类,研究组使用KNN对于商品的中文字段进行分类,使用爬虫爬下天猫的全部分类结果作为训练集,得到了每一个商品的
分类。
然后就是要载入回收数据了。
先上图

每一条回收记录,含有一个用户和一个类。
1.Set 为该用户有评价的同类商品集合。
2.V为标准化后的该用户同类商品加权特征向量。
3.计算出对原评分矩阵的调整值,并加回M矩阵中该用户有评价的同类商品的评分。
4.相同方法重新计算预测矩阵H,用户偏好矩阵θ,商品特征矩阵X。
经过上述方法载入回收数据,调整评分矩阵之后,嗯观察各个指标的结果。
很不幸除了Recall,别的所有指标都表现为系统性能变差了。。。。。就不列出数据结果了,太占篇幅,看官们估计也没耐心看。。。
这也许是数据源的锅,善于丢锅的组员们于是这么想到。。。。。
啊那就清洗数据吧。
我们删除了:
1,没有任何行为记录的用户。
2,回收记录数目比购买记录数大于10的用户。(因为如果一个用户在这个平台上只卖东西不买东西,我们无从基于商城的有限物品评判他的购买行为)
这么做确实是有用的。
清洗数据之后再执行前述算法,发现除了Precision指标,别的指标的表现都是系统性能提升了!(果然数据源有锅要背。。)
并且,Precision指标下降的幅度,要远比清洗数据之前下降的要少,而且在推荐数据达到50个以上的时候,载入回收数据后的Precision指标反超了载入之前。
。。。。。要转移地点了,先写到这里吧。















 1967
1967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









