






我们在编写 nodejs 服务的时候,有时候需要使用 fs.readFileSync api 去读取文件,但是使用 fs.readFileSync 会将文件读取在内存中,如果遇到了文件很大时,fs.readFileSync 会占据服务器大量的内存,即使读取的文件比较小,但是如果遇到用户访问剧增的时候,大规模读取小文件也会使得服务器内存长时间处于高位。
当然如果我们要避免 fs.readFileSync 去读取文件有很多方法,今天我们介绍一种不是很常见的方式去读取。就是我们可以通过使用 fs.createReadStream 将文件读取成流chunk。
接下来我们通过一个案例来比较这两种方式在读取同一文件速度上的差异。
fs.readFileSync
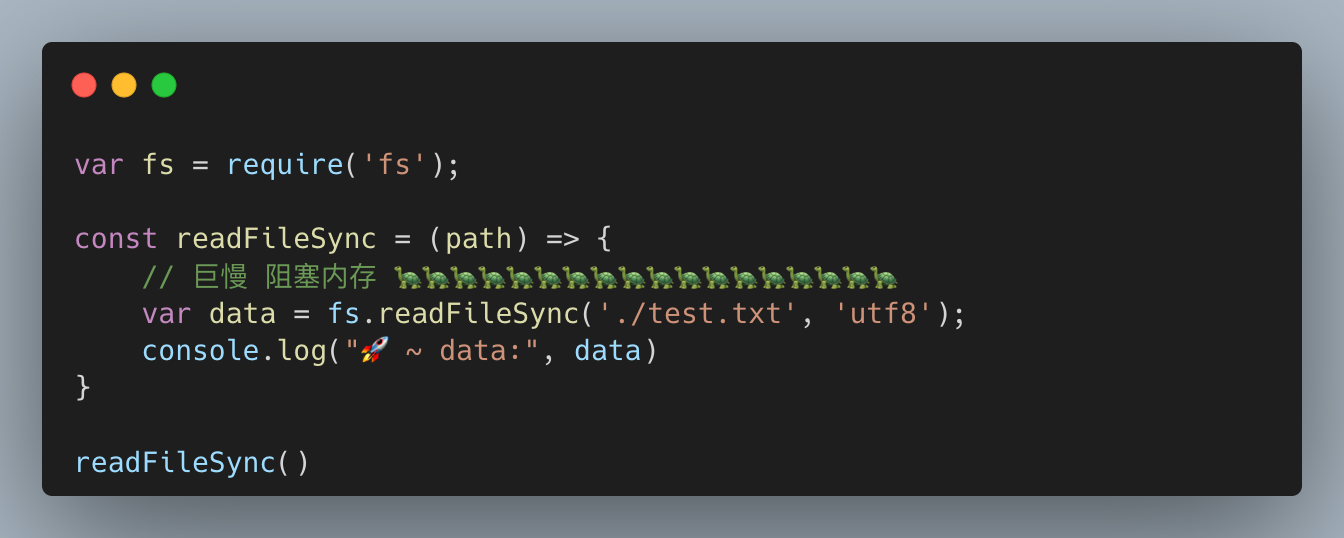
直接使用 readFileSync 同步读取一个 130M 文件大小的文件并将内容进行输出
fs.createReadStream
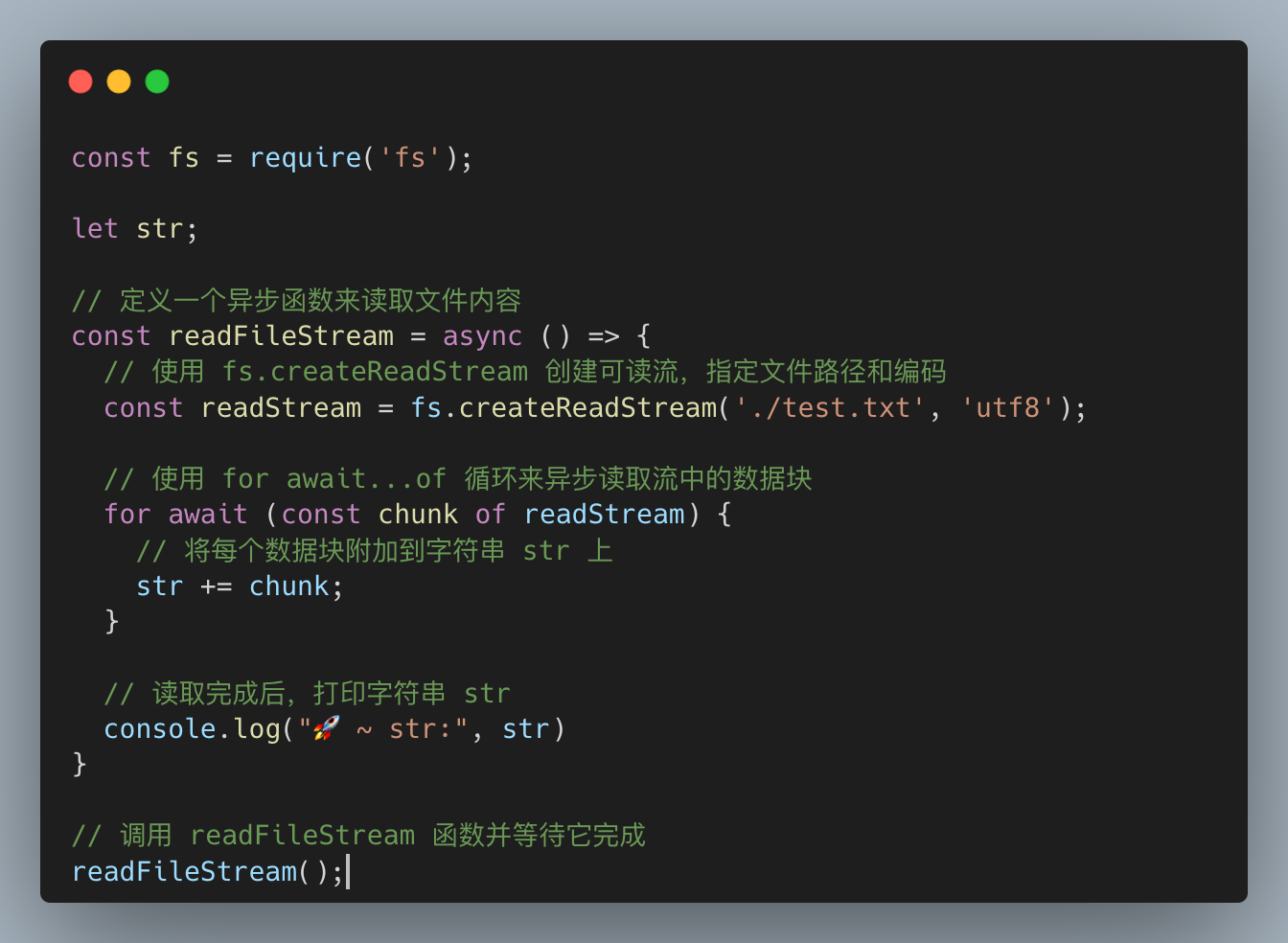
- 使用
fs.createReadStream创建可读流,指定文件路径和编码 - 使用
for await...of循环来异步读取流中的数据块
这里简单介绍一下fs.createReadStream这个 api
createReadStream 是 Node.js 文件系统 (fs) 模块中的一个方法,用于创建一个可读流对象。createReadStream 函数接受两个参数:
- 文件路径:要读取的文件的路径。
- 可选参数对象:用于配置流的行为,例如编码、起始位置和结束位置等。
const readStream = fs.createReadStream('path/to/file.txt', {
encoding: 'utf8',
autoClose: true,
emitClose: true,
start: 0,
end: Infinity,
highWaterMark: 16 * 1024 // 16KB 缓冲区大小
});
常见使用方法是采用回调的方式,也可以使用本案例中的 for await of 的方式。
const fs = require('fs');
// 创建可读流
const readStream = fs.createReadStream('path/to/file.txt', {
encoding: 'utf8',
highWaterMark: 16 * 1024 // 16KB 缓冲区大小
});
// 监听 data 事件
readStream.on('data', (chunk) => {
console.log('读取到数据块:', chunk);
});
// 监听 end 事件
readStream.on('end', () => {
console.log('文件读取完成');
});
// 监听 error 事件
readStream.on('error', (err) => {
console.error('读取文件时发生错误:', err);
});
// 监听 close 事件
readStream.on('close', () => {
console.log('流已关闭');
});
差异
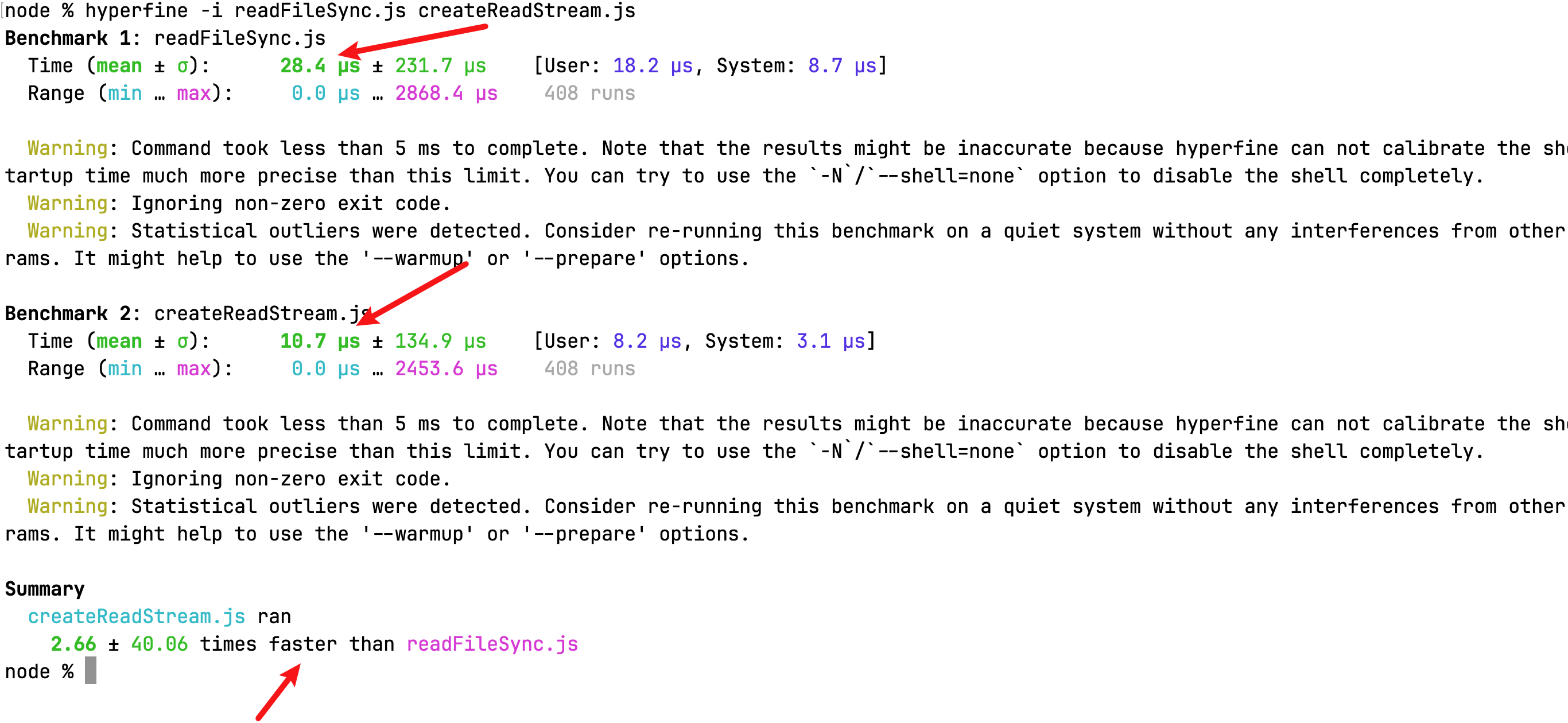
通过 hyperfine 工具我们可以对这两个脚本进行基准测试,我们可以通过基准测试数据可以看出,同样是同步获取 130M 文件内容,createReadStream 的速度就是快于 readFileSync
小结
通过上面的介绍,相信大家对 fs.readFileSync 和 fs.createReadStream 这两个 api 在同步获取文件内容时,执行速度上的差异了。这样以后等我们在进行性能优化的时候,就可以使用fs.createReadStream 去优化脚本的响应了。
如果这篇文章对你有帮助,欢迎点赞、关注➕、转发 ✔ !















 1119
1119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









