







我是利用Python的
webdriver+selenium工具抓取的动态链接
测试
1.测试连通
from bs4 import BeautifulSoup
import lxml
import time
from selenium.webdriver import ActionChains
from selenium import webdriver
driver_path = r'D:\\scrapy\\chromedriver.exe'
url = 'https://m.weibo.cn/p/index?containerid=23065700428008611000000000000&luicode=10000011&lfid=100103type%3D1%26q%3D%E5%8C%97%E4%BA%AC'
chrome_options=webdriver.ChromeOptions()#定义对象
#无界面显示
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options,executable_path=driver_path)
browser.get(url)
html = browser.page_source
print(html)
soup = BeautifulSoup(html,'html.parser')
datelist=[]

获取网页源码成功
2.提取测试
提取过程中遇到空列表[]
分离变量观察是什么原因,所以爬取一下百度的网站看看问题所在
3.爬取百度测试
from bs4 import BeautifulSoup
import requests
from lxml import etree
import time
from selenium.webdriver import ActionChains
from selenium import webdriver
driver_path = r'D:\\scrapy\\chromedriver.exe'
url = 'https://www.baidu.com/'
#'https://m.weibo.cn/p/index?containerid=23065700428008611000000000000&luicode=10000011&lfid=100103type%3D1%26q%3D%E5%8C%97%E4%BA%AC'
chrome_options=webdriver.ChromeOptions()#定义对象
#无界面显示
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options,executable_path=driver_path)
browser.get(url)
ht = browser.page_source
#print(html)
ua = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'}
soup = BeautifulSoup(ht,'html.parser')
response = requests.get(url=url,headers=ua)
response.encoding = 'utf-8'
html = etree.HTML(response.text)
a = html.xpath('//*[@id="s-top-left"]/a[1]/text()')
#a = html.xpath('//*[@id="app"]/div[1]/div[2]/div/div/div/div/div/div/article/div/div[1]/a/span[2]/text()')
print(a)
#addr = response.xpath('//*[@id="app"]/div[1]/div[2]/div/div/div/div/div/div/article/div/div[1]/a/span[2]').extract_first()
#name = response.xpath('//*[@id="app"]/div[1]/div[2]/div/div/div/div/div/div/header/div/div/a/h3').extract()
#content = response.xpath('//*[@id="app"]/div[1]/div[2]/div/div/div/div/div/div/article/div/div[1]').extract()
'''h3 = soup.find_all(name='div', class_='card-list')
for n in h3:
name = n.find('h3','m-text-cut').text
addr = n.find('span','surl-text').text
content= n.find('div','weibo-text').text
'''
'''datalist=[]
datalist.append([name,addr,content])
print(datalist)'''
#card m-panel card9 weibo-member
# card-list
#m-text-cut

3. 构建要输出的csv文件形式
datalist=[]
datalist.append([name,addr,content])
print(datalist)
lie = ['name','content','addr']
test = pd.DataFrame(datalist,columns=lie)
test.to_csv('./test1.csv',index=False)
由于没爬取到信息,所以是空的
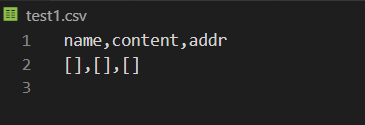
输出结果正常,所以可能是代理设置的问题
接下来购买IP代理,我是从某宝上购买的
接下来用代理的手段尝试
4.添加IP代理
初步使用代理之后是这样滴
from bs4 import BeautifulSoup
import requests
from lxml import etree
import time
from selenium.webdriver import ActionChains
from selenium import webdriver
import pandas as pd
driver_path = r'D:\\scrapy\\chromedriver.exe'
url = 'https://m.weibo.cn/p/index?containerid=23065700428008611000000000000&luicode=10000011&lfid=100103type%3D1%26q%3D%E5%8C%97%E4%BA%AC'
#'https://m.weibo.cn/p/index?containerid=23065700428008611000000000000&luicode=10000011&lfid=100103type%3D1%26q%3D%E5%8C%97%E4%BA%AC'
proxies= {
"http":"http://111.127.119.230:13456",
"http":"http://221.230.216.211:13456",
"http":"http://111.75.125.219:13456",
"http":"http://.38.241.103:13456",
"http":"http://223.214.217.45:13456",
"http":"http://183.4.22.247:13456",
"http":"http://125.87.93.115:13456",
"http":"http://114.233.51.125:13456",
"http":"http://182.38.172.166:13456",
"http":"http://222.189.191.29:13456",
"http":"http://121.233.207.136:13456",
"http":"http://60.184.199.19:13456",
"http":"http://115.226.128.29:13456",
"http":"http://121.233.206.155:13456",
"http":"http://117.91.248.87:13456",
"http":"http://115.152.230.162:13456",
"http":"http://115.152.231.172:13456",
"http":"http://115.196.198.11:13456",
"http":"http://61.130.131.105:13456",
}
#proxies = "http://"+proxy
chrome_options=webdriver.ChromeOptions()#定义对象
#无界面显示
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options,executable_path=driver_path)
browser.get(url)
ht = browser.page_source
#print(html)
ua = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36'}
soup = BeautifulSoup(ht,'html.parser')
response = requests.get(url=url,proxies=proxies)
response.encoding = 'utf-8'
html = etree.HTML(response.text)
a = html.xpath('//*[@id="app"]/div[1]/div[2]/div/div/div/div/div/div/article/div/div[1]/a/span[2]/text()')
time.sleep(3)
#a = html.xpath('//*[@id="app"]/div[1]/div[2]/div/div/div/div/div/div/article/div/div[1]/a/span[2]/text()')
print(a)
addr = html.xpath('//*[@id="app"]/div[1]/div[2]/div/div/div/div/div/div/article/div/div[1]/a/span[2]/text()')
name = html.xpath('//*[@id="app"]/div[1]/div[2]/div/div/div/div/div/div/header/div/div/a/h3/text()')
content = html.xpath('//*[@id="app"]/div[1]/div[2]/div/div/div/div/div/div/article/div/div[1]/text()')
'''h3 = soup.find_all(name='div', class_='card-list')
for n in h3:
name = n.find('h3','m-text-cut').text
addr = n.find('span','surl-text').text
content= n.find('div','weibo-text').text
'''
datalist=[]
datalist.append([name,addr,content])
print(datalist)
lie = ['name','content','addr']
test = pd.DataFrame(datalist,columns=lie)
test.to_csv('./test1.csv',index=False)
#card m-panel card9 weibo-member
# card-list
#m-text-cut
但是结果获得的仍然是空列表,再来!又有何惧!
5.改进
花了点软妹币,买了一天权限的IP代理
客服告诉我
这个rp时效只有五分钟。
可以一秒钟访问一下这个网址,然后每次采集的时候都是用最后一次踢出来的代理地址。
接下来需要用redis
接下来的操作见第二部分,接下来会继续分享















 1589
1589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









