







回忆一下单机的执行流程,用户执行ncclSend之后通过ncclEnqueueCheck将sendbuff,sendbytes,peer等信息保存到了comm->p2plist中;然后执行ncclGroupEnd,如果发现channel没有建立到peer的链接则先建链,然后根据p2plist执行scheduleSendRecv(ncclSaveKernel)将信息保存到channel->collectives,然后再启动kernel,kernel会遍历channel->collectives执行send和recv。然后我们看下多机的流程是怎样的。
ncclProxyArgs
首先看下scheduleSendRecv过程的ncclSaveKernel,这里流程和单机不一样的为ncclProxySaveP2p。
ncclResult_t ncclSaveKernel(struct ncclInfo* info) {
...
for (int bid=0; bid<nChannels*nSubChannels; bid++) {
int channelId = (info->coll == ncclCollSendRecv) ? info->channelId :
info->comm->myParams->gridDim.x % info->comm->nChannels;
struct ncclChannel* channel = info->comm->channels+channelId;
...
// Proxy
proxyArgs.channel = channel;
...
if (info->coll == ncclCollSendRecv) {
info->comm->myParams->gridDim.x = std::max<unsigned>(info->comm->myParams->gridDim.x, channelId+1);
NCCLCHECK(ncclProxySaveP2p(info, channel));
} else {
NCCLCHECK(ncclProxySaveColl(&proxyArgs, info->pattern, info->root, info->comm->nRanks));
}
...
}
...
}多机间网络通信的过程是由独立的proxy线程执行的,ncclProxyArgs保存了通信需要的参数,proxy线程会根据这些args执行相应的通信流程。然后执行SaveProxy
ncclResult_t ncclProxySaveP2p(struct ncclInfo* info, struct ncclChannel* channel) {
struct ncclProxyArgs args;
memset(&args, 0, sizeof(struct ncclProxyArgs));
args.channel = channel;
args.sliceSteps = 1;
args.chunkSteps = 1;
args.protocol = NCCL_PROTO_SIMPLE;
args.opCount = info->comm->opCount;
args.dtype = info->datatype;
if (info->delta > 0 && info->sendbytes >= 0) {
int peersend = (info->comm->rank+info->delta)%info->comm->nRanks;
args.nsteps = DIVUP(info->sendbytes, info->comm->buffSizes[NCCL_PROTO_SIMPLE]/NCCL_STEPS/SENDRECV_SLICEFACTOR);
if (args.nsteps == 0) args.nsteps = 1;
NCCLCHECK(SaveProxy<proxySend>(peersend, &args));
}
if (info->delta > 0 && info->recvbytes >= 0) {
int peerrecv = (info->comm->nRanks+info->comm->rank-info->delta)%info->comm->nRanks;
args.nsteps = DIVUP(info->recvbytes, info->comm->buffSizes[NCCL_PROTO_SIMPLE]/NCCL_STEPS/SENDRECV_SLICEFACTOR);
if (args.nsteps == 0) args.nsteps = 1;
NCCLCHECK(SaveProxy<proxyRecv>(peerrecv, &args));
}
return ncclSuccess;
}首先获取当前channel连接到peer的ncclPeer,根据type是send还是recv获取这个peer的对应connector,单机场景下connector的 transportComm为p2pTransport,proxy为空,因此这里直接返回,而多机场景下为netTransport,proxy不为空,然后申请ncclProxyArgs,设置progress为transportComm->proxy。
template <int type>
static ncclResult_t SaveProxy(int peer, struct ncclProxyArgs* args) {
if (peer < 0) return ncclSuccess;
struct ncclPeer* peerComm = args->channel->peers+peer;
struct ncclConnector* connector = type == proxyRecv ? &peerComm->recv : &peerComm->send;
if (connector->transportComm == NULL) {
WARN("[%d] Error no transport for %s peer %d on channel %d\n", connector->comm->rank,
type == proxyRecv ? "recv" : "send", peer, args->channel->id);
return ncclInternalError;
}
if (connector->transportComm->proxy == NULL) return ncclSuccess;
struct ncclProxyArgs* op;
NCCLCHECK(allocateArgs(connector->comm, &op));
memcpy(op, args, sizeof(struct ncclProxyArgs));
op->connector = connector;
op->progress = connector->transportComm->proxy;
op->state = ncclProxyOpReady;
ProxyAppend(connector, op);
return ncclSuccess;
}然后执行ProxyAppend。
static void ProxyAppend(struct ncclConnector* connector, struct ncclProxyArgs* args) {
struct ncclComm* comm = connector->comm;
struct ncclProxyState* state = &comm->proxyState;
pthread_mutex_lock(&state->mutex);
if (connector->proxyAppend == NULL) {
// Nothing running for that peer. Add to the circular list
if (state->ops == NULL) {
// Create the list
args->next = args;
state->ops = args;
} else {
// Insert element in the list
args->next = state->ops->next;
state->ops->next = args;
}
connector->proxyAppend = args;
} else {
// There is an active operation already for that peer.
// Add it to the per-peer list
connector->proxyAppend->nextPeer = args;
connector->proxyAppend = args;
}
pthread_mutex_unlock(&state->mutex);
}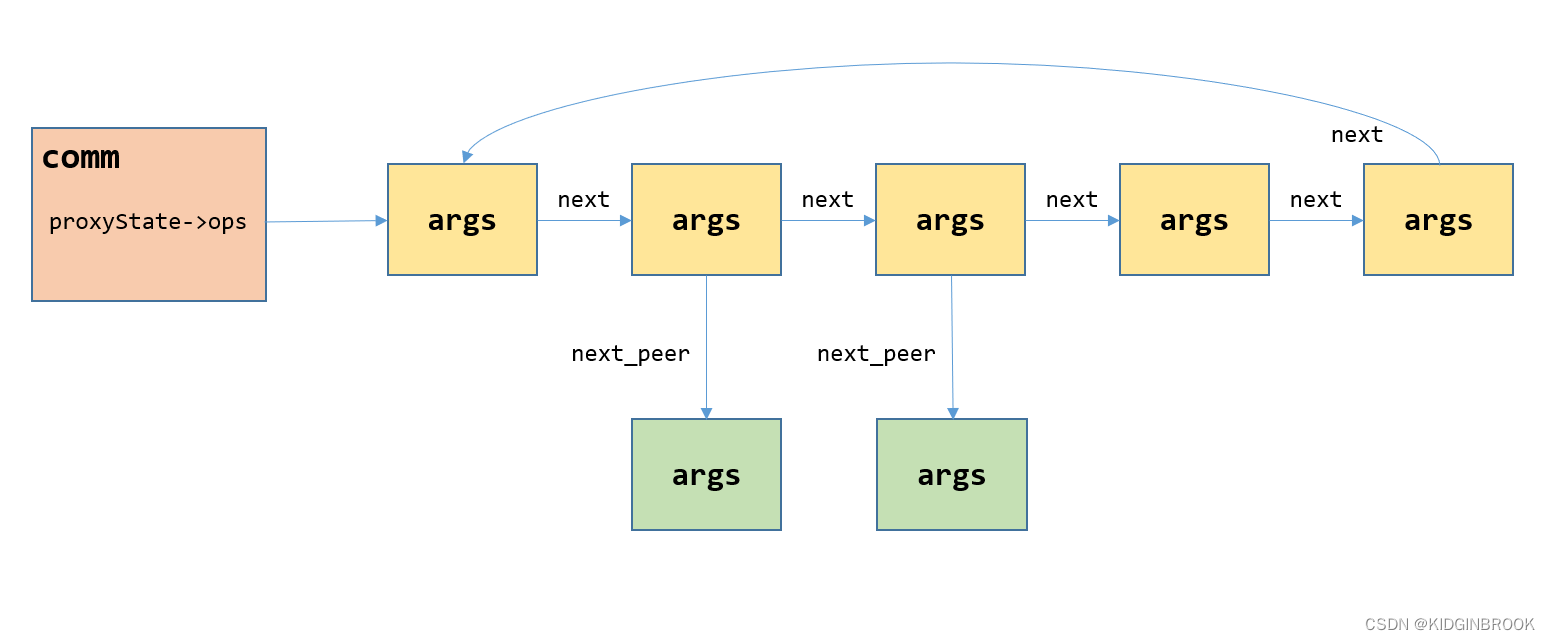
ncclProxyArgs被组织成图一分层的链式结构,comm中的proxyState->ops为第一层的第一个args,图中纵向的一列表示在同一个connector上边的所有args,第一层(黄色框)为该connector的第一个args,第二层(绿色框)为该connector的第二个args,层间通过next_peer指针索引;一行就是所有connector的对应位置的args,层内通过next指针索引。
proxy线程
然后看下刚提到的proxy线程,在initTransportsRank的时候通过ncclProxyCreate创建了proxy线程执行persistentThread,创建的时候由于还没有执行过ProxyAppend,所以comm中的proxyState->op为null,所以线程就阻塞在state->cond。
void* persistentThread(void *comm_) {
struct ncclComm* comm = (struct ncclComm*)comm_;
struct ncclProxyState* state = &comm->proxyState;
struct ncclProxyArgs* op = NULL;
ncclResult_t ret = ncclSuccess;
int idle = 1;
int idleSpin = 0;
while (1) {
do {
if (*comm->abortFlag) return NULL;
if (op == NULL) {
pthread_mutex_lock(&state->mutex);
op = state->ops;
if (op == NULL) {
if (state->stop) {
// No more commands to process and proxy has been requested to stop
pthread_mutex_unlock(&state->mutex);
return NULL;
}
pthread_cond_wait(&state->cond, &state->mutex);
}
pthread_mutex_unlock(&state->mutex);
}
} while (op == NULL);
...
}
}当有ProxyArgs被添加进来并唤醒proxy线程之后,proxy线程就开始执行图一的第一层args,拿到第一个args op,然后执行op的progress函数,对于send场景,progress就是netTransport的netSendProxy,receive就是netRecvProxy。执行op的progress之后遍历到下一个args next,如果next的状态不是ncclProxyOpNone,表示next还没有执行结束,那么将op设置为next,下一次将会执行next;如果状态为ncclProxyOpNone,表示next已经执行完成,那么需要将next从args链中去除,这个时候尝试将next的next_peer替换next,如果next没有next_peer,那么直接将next从第一层链中删除,否则将next_peer提到第一层链来替换next。
void* persistentThread(void *comm_) {
...
while (1) {
...
op->idle = 0;
// opCount >= lastOpCount are part of an ongoing GroupStart/GroupEnd that hasn't started
// yet and might be cancelled before they even start. Hold on on those.
if (op->state != ncclProxyOpNone && op->opCount < comm->lastOpCount) ret = op->progress(op);
if (ret != ncclSuccess) {
comm->fatalError = ret;
INFO(NCCL_ALL,"%s:%d -> %d [Proxy Thread]", __FILE__, __LINE__, ret);
return NULL;
}
idle &= op->idle;
pthread_mutex_lock(&state->mutex);
if (!idle) idleSpin = 0;
struct ncclProxyArgs *next = op->next;
if (next->state == ncclProxyOpNone) {
struct ncclProxyArgs *freeOp = next;
if (next->nextPeer) {
// Replace next by its next per-peer element.
next = next->nextPeer;
if (op != freeOp) {
next->next = freeOp->next;
op->next = next;
} else {
next->next = next;
}
} else {
// Remove next from circular list
next->connector->proxyAppend = NULL;
if (op != freeOp) {
next = next->next;
op->next = next;
} else {
next = NULL;
}
}
if (freeOp == state->ops) state->ops = next;
freeOp->next = state->pool;
state->pool = freeOp;
}
op = next;
if (op == state->ops) {
if (idle == 1) {
if (++idleSpin == 10) {
sched_yield();
idleSpin = 0;
}
}
idle = 1;
}
pthread_mutex_unlock(&state->mutex);
}
}然后看下是如何唤醒proxy线程的,在执行scheduleSendRecv之后,通过ncclBarrierEnqueue启动了kernel。
ncclResult_t ncclGroupEnd() {
...
for (int i=0; i<ncclGroupIndex; i++) {
struct ncclAsyncArgs* args = ncclGroupArgs+i;
if (args->funcType == ASYNC_FUNC_COLL) {
if (args->coll.comm->userStream == NULL)
CUDACHECKGOTO(cudaSetDevice(args->coll.comm->cudaDev), ret, end);
NCCLCHECKGOTO(ncclBarrierEnqueue(args->coll.comm), ret, end);
}
}
for (int i=0; i<ncclGroupIndex; i++) {
struct ncclAsyncArgs* args = ncclGroupArgs+i;
if (args->funcType == ASYNC_FUNC_COLL) {
CUDACHECKGOTO(cudaSetDevice(args->coll.comm->cudaDev), ret, end);
NCCLCHECKGOTO(ncclBarrierEnqueueWait(args->coll.comm), ret, end);
}
}
for (int i=0; i<ncclGroupIndex; i++) {
struct ncclAsyncArgs* args = ncclGroupArgs+i;
if (args->funcType == ASYNC_FUNC_COLL) {
if (args->coll.comm->userStream == NULL)
CUDACHECKGOTO(cudaSetDevice(args->coll.comm->cudaDev), ret, end);
NCCLCHECKGOTO(ncclEnqueueEvents(args->coll.comm), ret, end);
}
}
...
}然后在ncclBarrierEnqueueWait中会执行ncclProxyStart,这里会通过pthread_cond_signal唤醒阻塞在proxyState.cond里边的proxy线程。
ncclResult_t ncclProxyStart(struct ncclComm* comm) {
pthread_mutex_lock(&comm->proxyState.mutex);
if (comm->proxyState.ops != NULL)
pthread_cond_signal(&comm->proxyState.cond);
pthread_mutex_unlock(&comm->proxyState.mutex);
return ncclSuccess;
}队列的创建
首先看下send端的proxy线程和kernel是如何协作的,类似单机内部send和recv之间的队列,proxy和kernel间也是通过这种生产者消费者队列来协调的,整体结构如下图所示
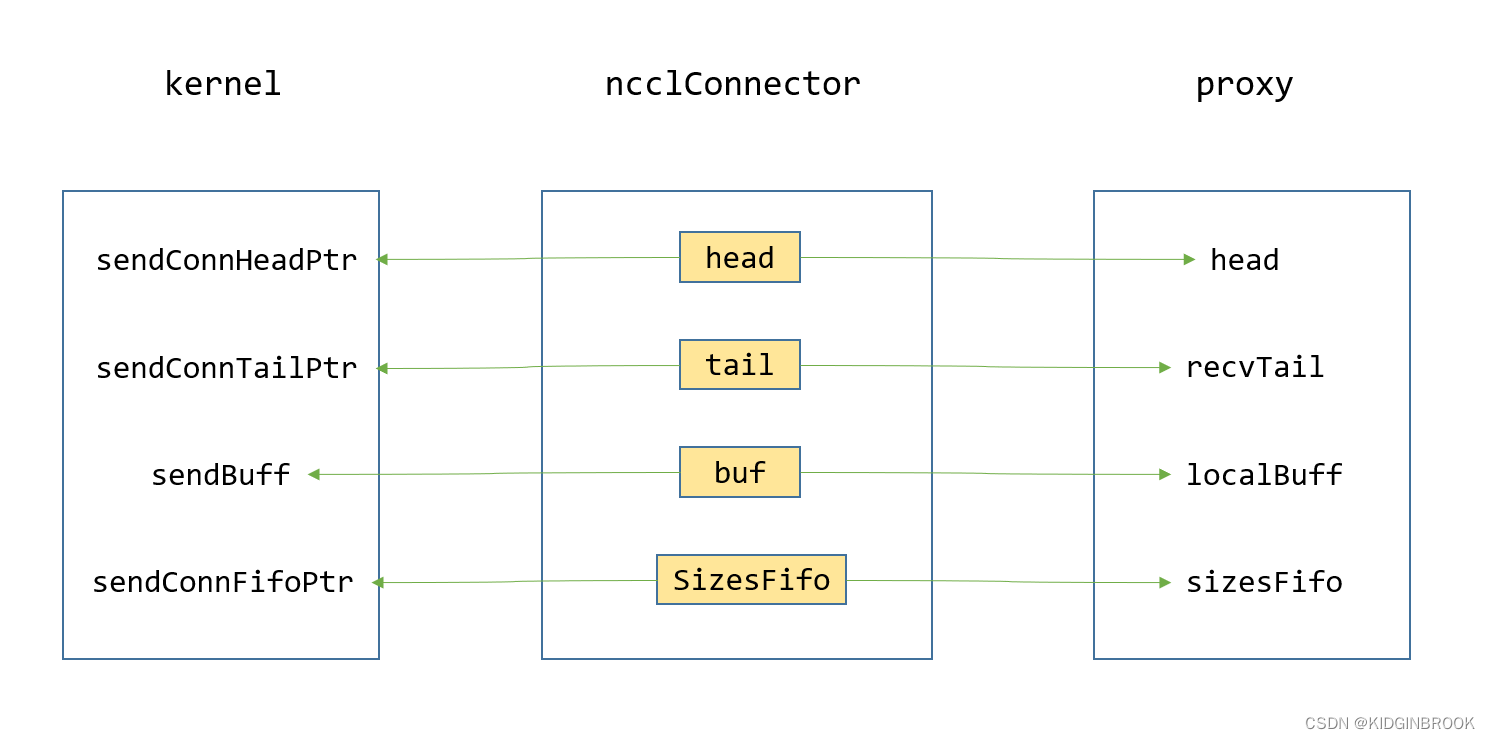
回顾下通信连接建立的过程中,send端会执行netSendSetup分配通信过程中需要的变量,如图二的ncclConnector。
ncclResult_t netSendSetup(struct ncclTopoSystem* topo, struct ncclTopoGraph* graph, struct ncclPeerInfo* myInfo, struct ncclPeerInfo* peerInfo, struct ncclConnect* connectInfo, struct ncclConnector* send, int channelId) {
...
NCCLCHECK(ncclCudaHostCalloc(&resources->sendMem, 1));
NCCLCHECK(ncclCudaHostCalloc(&resources->recvMem, 1));
send->conn.direct |= resources->useGdr ? NCCL_DIRECT_NIC : 0;
send->conn.tail = &resources->recvMem->tail;
send->conn.fifo = resources->recvMem->sizesFifo;
send->conn.head = &resources->sendMem->head;
for (int i=0; i<NCCL_STEPS; i++) send->conn.fifo[i] = -1;
...
if (resources->buffSizes[LOC_DEVMEM]) {
NCCLCHECK(ncclCudaCalloc(resources->buffers+LOC_DEVMEM, resources->buffSizes[LOC_DEVMEM]));
}
...
int offsets[LOC_COUNT];
offsets[LOC_HOSTMEM] = offsets[LOC_DEVMEM] = 0;
for (int p=0; p<NCCL_NUM_PROTOCOLS; p++) {
resources->mhandlesProto[p] = resources->mhandles+protoLoc[p];
send->conn.buffs[p] = resources->buffers[protoLoc[p]] + offsets[protoLoc[p]];
offsets[protoLoc[p]] += buffSizes[p];
}
...
return ncclSuccess;
}核心就是队列的head,tail和SizesFifo,通信过程中的buf,这些都会保存到connector的conn中。对于kernel端,当执行了loadSendConn和loadSendSync之后kernel就持有了ncclConnector的变量,如图二左侧框。
__device__ __forceinline__ void loadSendConn(struct ncclConnInfo* conn, int i) {
sendBuff[i] = (T*)conn->buffs[NCCL_PROTO_SIMPLE];
sendStep[i] = conn->step;
...
}
__device__ __forceinline__ void loadSendSync() {
if (tid < nsend) {
sendConnHeadPtr = sendConn->head;
sendConnHeadCache = *sendConnHeadPtr;
sendConnFifoPtr = sendConn->fifo;
}
if (tid >= nthreads && wid<nsend) {
sendConnTailPtr = sendConn->tail;
}
}对于proxy线程,ncclConnector被保存到了ncclProxyArgs中,所以proxy也可以拿到这些变量,如图二的右侧框。
队列的运行
然后分别从kernel视角和proxy视角看下这个队列如何运行的。
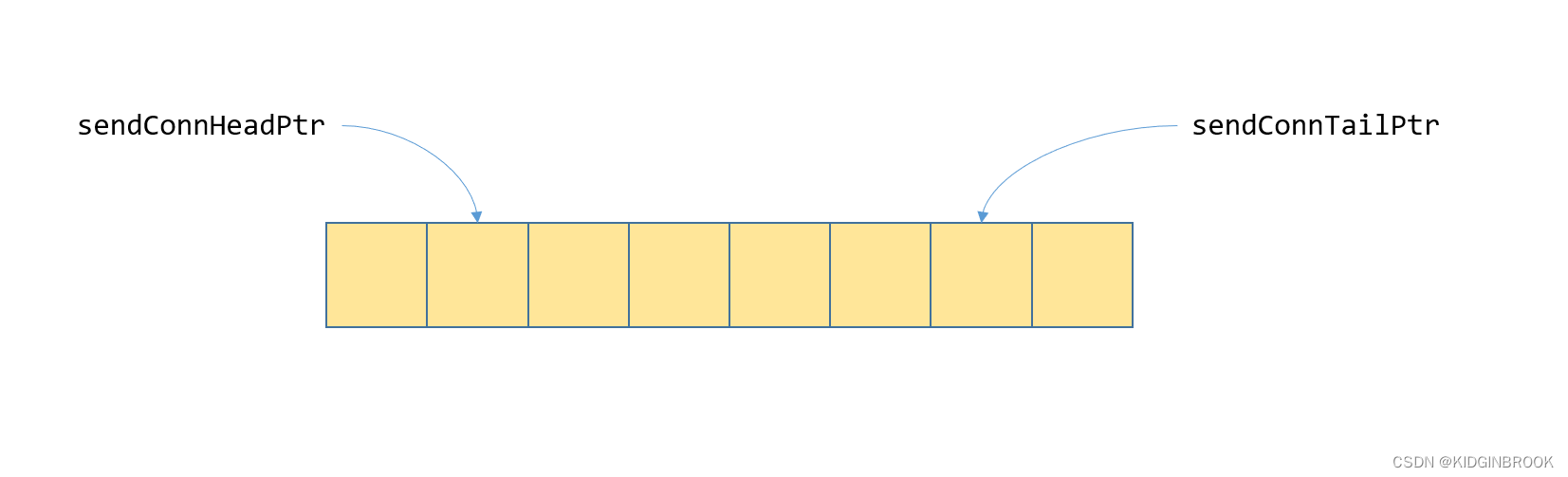
对于kernel端,如图三,过程和单机一致,在搬运数据之前,通过判断sendConnHeadPtr和sendConnTailPtr之间的距离来判断队列是否已满,注意这里sendConnHead其实是sendConnTailPtr。然后将数据长度写入到sendConnFifoPtr中,即sizesFifo,这样proxy就能知道这次写的数据的长度。
inline __device__ void waitSend(int nbytes) {
spins = 0;
if (sendConnHeadPtr) {
while (sendConnHeadCache + NCCL_STEPS < sendConnHead + SLICESTEPS) {
sendConnHeadCache = *sendConnHeadPtr;
if (checkAbort(wid, 1)) break;
}
if (sendConnFifoPtr) {
sendConnFifoPtr[sendConnHead%NCCL_STEPS] = nbytes;
}
sendConnHead += SLICESTEPS;
}
}每当新搬运了一块数据,就将sendConnTailPtr加一。
inline __device__ void postSend() {
if (sendConnTailPtr) *sendConnTailPtr = sendConnTail += SLICESTEPS;
}同样的队列在proxy端的视角如图四
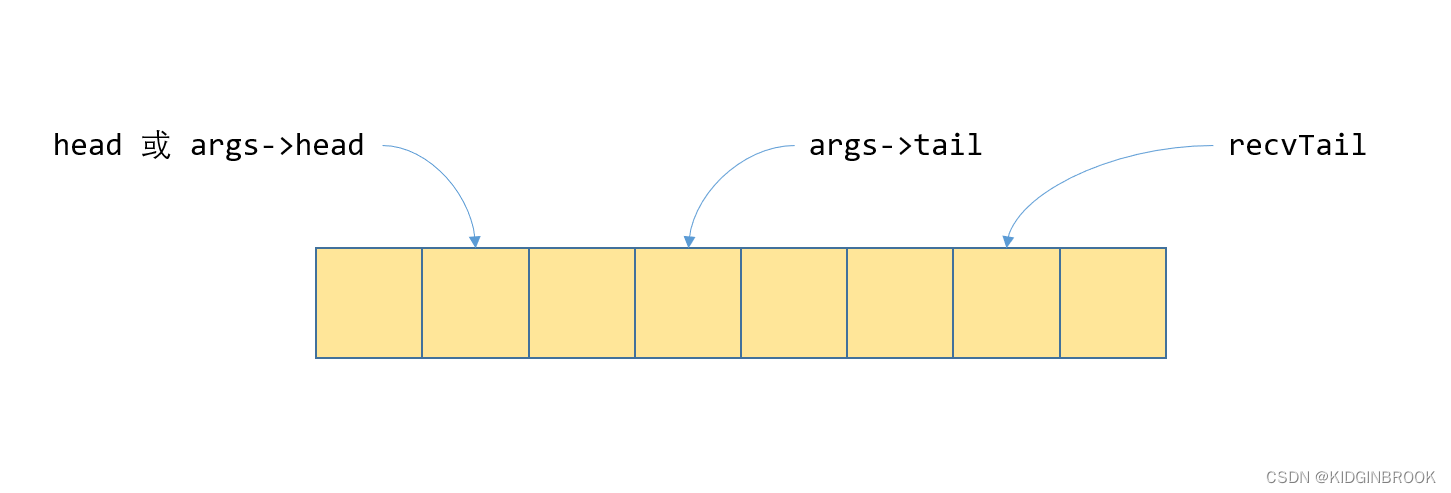
recvTail由kernel更新,表示kernel端产生了这么多的数据,head由proxy更新,表示proxy完成了这些数据的发送;由于proxy使用异步发送,所以引入了tail变量,head和tail之间的数据为proxy执行了异步发送,但还没确定发送完成,tail和recvTail之间为proxy还没有执行发送的数据。
具体看下,proxy拿到一个新的ncclProxyArgs args(state为ncclProxyOpReady)之后,首先计算head,tail和end,其中head和tail表示队列的首尾,end表示完成当前这个args的数据发送一共需要多少步,然后状态转变为ncclProxyOpProgress
ncclResult_t netSendProxy(struct ncclProxyArgs* args) {
struct netSendResources* resources = (struct netSendResources*) (args->connector->transportResources);
if (args->state == ncclProxyOpReady) {
// Round to next multiple of sliceSteps
resources->step = ROUNDUP(resources->step, args->chunkSteps);
args->head = resources->step;
args->tail = resources->step;
args->end = args->head + args->nsteps;
args->state = ncclProxyOpProgress;
}
...
return ncclSuccess;
}单机过程中的队列其实是逻辑的,并没有实际分配一个队列,多机这里可以将sizesFifo理解为实际分配的队列,fifo中每一项代表了这块数据的长度,可以看到proxy在拿到fifo对应项之后直接通过ncclNetIsend执行数据的发送过程。
ncclResult_t netSendProxy(struct ncclProxyArgs* args) {
struct netSendResources* resources = (struct netSendResources*) (args->connector->transportResources);
...
if (args->state == ncclProxyOpProgress) {
int p = args->protocol;
int stepSize = args->connector->comm->buffSizes[p] / NCCL_STEPS;
char* localBuff = args->connector->conn.buffs[p];
void* mhandle = *(resources->mhandlesProto[p]);
args->idle = 1;
if (args->head < args->end) {
int buffSlot = args->tail%NCCL_STEPS;
if (args->tail < args->end && args->tail < args->head + NCCL_STEPS) {
volatile int* sizesFifo = resources->recvMem->sizesFifo;
volatile uint64_t* recvTail = &resources->recvMem->tail;
if (args->protocol == NCCL_PROTO_LL128) {
...
} else if (args->protocol == NCCL_PROTO_LL) {
...
} else if (args->tail < *recvTail) {
// Send through network
if (sizesFifo[buffSlot] != -1) {
NCCLCHECK(ncclNetIsend(resources->netSendComm, localBuff+buffSlot*stepSize, sizesFifo[buffSlot], mhandle, args->requests+buffSlot));
if (args->requests[buffSlot] != NULL) {
sizesFifo[buffSlot] = -1;
// Make sure size is reset to zero before we update the head.
__sync_synchronize();
args->tail += args->sliceSteps;
args->idle = 0;
}
}
}
}
...
}
...
}
return ncclSuccess;
}如果head小于tail,说明有执行了异步发送的请求,通过ncclNetTest判断是否发送完成,如果发送完成了,那么更新head。最后如果head等于end,说明这个args执行完成了,将state转为ncclProxyOpNone。
ncclResult_t netSendProxy(struct ncclProxyArgs* args) {
struct netSendResources* resources = (struct netSendResources*) (args->connector->transportResources);
...
if (args->state == ncclProxyOpProgress) {
...
if (args->head < args->end) {
int buffSlot = args->tail%NCCL_STEPS;
...
if (args->head < args->tail) {
int done;
int buffSlot = args->head%NCCL_STEPS;
NCCLCHECK(ncclNetTest(args->requests[buffSlot], &done, NULL));
if (done) {
args->head += args->sliceSteps;
resources->sendMem->head = args->head;
args->idle = 0;
}
}
}
if (args->head == args->end) {
resources->step = args->end;
args->idle = 0;
args->state = ncclProxyOpNone;
}
}
return ncclSuccess;
}网络通信过程
然后以rdma为例看下send端和recv端是如何配合的。以rdma send/recv为例,当send端执行rdma send的时候,要求recv端已经post过一个wr到rq里,否则将会报错,为了解决这个问题,在send和recv的两个proxy之间,也引入了一个fifo,如图五所示
struct ncclIbSendFifo {
uint64_t addr;
int size;
uint32_t seq;
uint32_t rkey;
uint32_t ready;
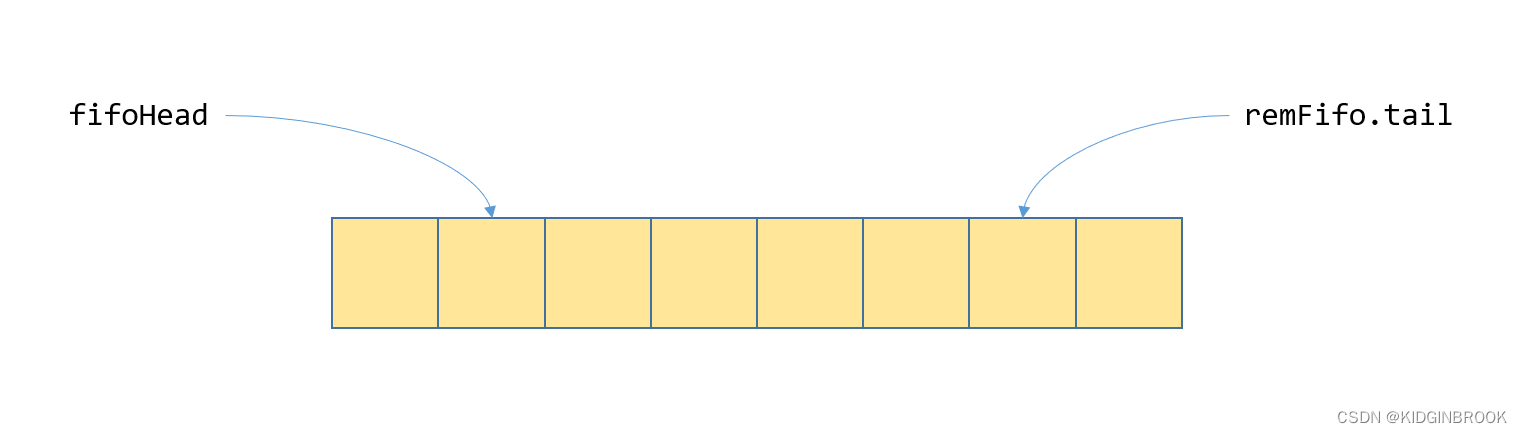
};fifo中每个元素为ncclIbSendFifo,fifoHead由send端持有,remFifo.tail由recv端持有。对于rdma send/recv来说最重要的是ready字段,其他为rdma write场景用的。fifo是由send端创建的,在rdma建链过程中的ncclIbConnect里会将fifo对应内存注册,然后通过socket将fifo地址和rkey发送给recv端,recv端在每次往rq中下发一个wr之后会通过rdma write写send端fifo的tail对应的ncclIbSendFifo,send端只有在fifoHead位置的ready为1才能执行send。
这里多说一个疑问,在rdma write的场景中还需要ncclIbSendFifo的addr和rkey等字段,假设fifo中fifoHead位置叫slot,当使用rdma write的时候,发现slot->ready为1后,如何保证slot->addr等字段是可用的(网卡已经写完成),在咨询Tuvie大佬之后,因为slot的大小较小,会在同一个PCIe tlp中,又因为ready为最后的位置,所以可保证ready可用的时候,其他字段均可用。
然后看下ncclIbSend的逻辑,首先通过fifoHead获取到fifo中对应的slot,判断ready,如果为1则可以发送,然后通过ncclIbGetRequest获取一个req,req表示当前这个请求,之后会通过req判断这个通信是否完成。然后设置wr,这里将wr_id设置为req的地址以方便之后判断请求是否完成,然后post到sq中就返回,并将req存到fifo的对应位置。
ncclResult_t ncclIbIsend(void* sendComm, void* data, int size, void* mhandle, void** request) {
struct ncclIbSendComm* comm = (struct ncclIbSendComm*)sendComm;
if (comm->ready == 0) NCCLCHECK(ncclSendCheck(comm));
if (comm->ready == 0) { *request = NULL; return ncclSuccess; }
struct ibv_mr* mr = (struct ibv_mr*)mhandle;
// Wait for the receiver to have posted the corresponding receive
volatile struct ncclIbSendFifo* slot = comm->fifo + (comm->fifoHead%MAX_REQUESTS);
volatile uint32_t * readyPtr = &slot->ready;
if (*readyPtr == 0) { *request = NULL; return ncclSuccess; }
struct ncclIbRequest* req;
NCCLCHECK(ncclIbGetRequest(comm->reqs, &req));
req->verbs = &comm->verbs;
req->size = size;
struct ibv_send_wr wr;
memset(&wr, 0, sizeof(wr));
wr.wr_id = (uint64_t)req;
struct ibv_sge sge;
if (size == 0) {
wr.sg_list = NULL;
wr.num_sge = 0;
} else {
sge.addr=(uintptr_t)data; sge.length=(unsigned int)size; sge.lkey=mr->lkey;
wr.sg_list = &sge;
wr.num_sge = 1;
}
wr.opcode = IBV_WR_SEND;
wr.send_flags = IBV_SEND_SIGNALED;
int useAr = 0;
if (size > ncclParamIbArThreshold()) {
useAr = 1;
}
// We must clear slot->ready, but reset other fields to aid
// debugging and sanity checks
slot->ready = 0;
slot->addr = 0ULL;
slot->rkey = slot->size = slot->seq = 0;
comm->fifoHead++;
struct ibv_send_wr* bad_wr;
NCCLCHECK(wrap_ibv_post_send(comm->qp, &wr, &bad_wr));
*request = req;
return ncclSuccess;
}然后看下ncclIbTest,判断指定的req是否发送完成,根据req获取对应的cq,然后执行ibv_poll_cq获取到wc,通过wc拿到wr_id,wr_id为对应的req,然后设置这个req的done为1;然后循环直到指定的req->done为1。
ncclResult_t ncclIbTest(void* request, int* done, int* size) {
struct ncclIbRequest *r = (struct ncclIbRequest*)request;
*done = 0;
while (1) {
if (r->done == 1) {
*done = 1;
if (size) *size = r->size;
r->used = 0;
return ncclSuccess;
}
int wrDone = 0;
struct ibv_wc wcs[4];
NCCLCHECK(wrap_ibv_poll_cq(r->verbs->cq, 4, wcs, &wrDone));
if (wrDone == 0) return ncclSuccess;
for (int w=0; w<wrDone; w++) {
struct ibv_wc *wc = wcs+w;
if (wc->status != IBV_WC_SUCCESS) {
WARN("NET/IB : Got completion with error %d, opcode %d, len %d, vendor err %d", wc->status, wc->opcode, wc->byte_len, wc->vendor_err);
return ncclSystemError;
}
struct ncclIbRequest* doneReq = (struct ncclIbRequest*)wc->wr_id;
if (doneReq) {
if (wc->opcode == IBV_WC_RECV) {
doneReq->size = wc->byte_len;
}
doneReq->done = 1;
if (doneReq->free == 1) {
// This is an internal (FIFO post) req. Free it immediately.
doneReq->used = 0;
}
}
}
}
}recv端proxy整体流程基本和send一致,不过在执行ncclIbTest之后需要执行一下ncclIbFlush。
ncclResult_t netRecvProxy(struct ncclProxyArgs* args) {
...
if (args->tail > args->head) {
int buffSlot = args->head%NCCL_STEPS;
int done, size;
NCCLCHECK(ncclNetTest(args->requests[buffSlot], &done, &size));
if (done) {
args->head += args->sliceSteps;
if (args->protocol == NCCL_PROTO_SIMPLE) {
if (resources->useGdr) NCCLCHECK(ncclNetFlush(resources->netRecvComm, localBuff+buffSlot*stepSize, size, mhandle));
resources->recvMem->tail = args->head;
}
args->idle = 0;
}
}
...
return ncclSuccess;
}
下边是之前第八节中关于flush的介绍
gpuFlush也对应一个qp,不过这个qp是local的,即他的对端qp就是自己,当开启gdr之后,每次接收数据后都需要执行一下flush,其实是一个rdma read操作,使用网卡读一下接收到的数据的第一个int到hostMem。官方issue里解释说当通过gdr接收数据完成,产生wc到cpu的时候,接收的数据并不一定在gpu端可以读到,这个时候需要在cpu端执行一下读取。
更新:这里保序涉及两块
- PCIe链路的保序
- GPU卡上从PCIe接口到hbm落盘的保序
这里的flush解决的是第二个保序问题,后续Hopper架构这里取消了flush,由GPU硬件保证不乱序。
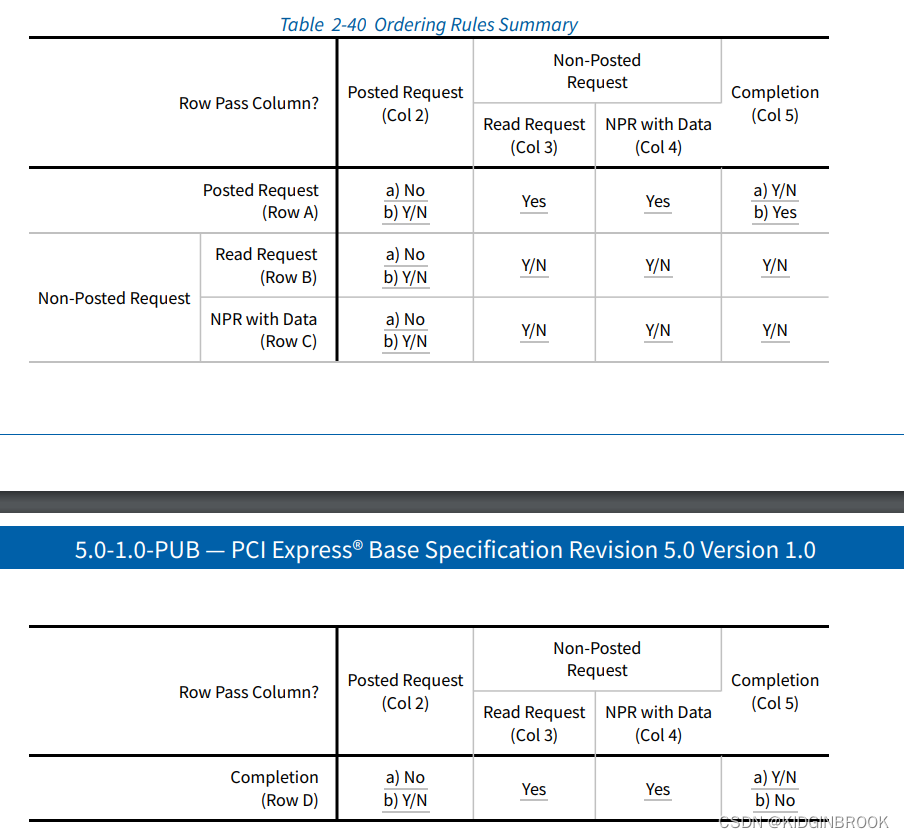
关于执行读取为什么能够保序后来咨询kkndyu大佬了解到,PCIe设备中有Transaction Ordering的概念,在同一个PCIe控制器中默认Read Request不会超过Posted Request,如下图col2
最后总结下多机通信的整体流程
- 通信由kernel和proxy线程协调完成,send端kernel负责将数据从input搬运到buf,proxy线程负责将buf中数据通过网络发送给recv端
- kernel和proxy间通过队列实现生产者消费者模式
- send端通过rdma send发送数据,和recv端通过队列实现生产者消费者模式,队列位于send端,recv端每次下发一个wr到rq之后会执行rdma write通知send端

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









