







博主使用的是github上Stable Diffusion webui版;所有图片训练也是基于该项目。
该项目对新手比较友好,且有丰富的图形界面和参数设置简易明了。
github链接:GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
如果嫌打开慢的话可以直接下载附件:
链接:https://pan.baidu.com/s/1rFEmPvV_EacuWcQLu9UqnQ?pwd=1111
提取码:1111
一、环境准备
python 3.10.6
二、准备模型库
下载完毕后,点击项目文件中的 webui.bat 运行项目。
此时项目会自动下载 model(图片素材库)也是我们生成图片所需要的基础图库。
这些 XXXX.safetensors 文件通常比较大,下载时间很慢,而且还存在网络等问题。
嫌慢的可以直接下载博主准备好的素材库(v1-5-pruned版本素材库3.97G):
链接:https://pan.baidu.com/s/1zZkDZHH1WypPD8IsYQeb5g?pwd=1111
提取码:1111
三、启动项目
确保python环境和库都没问题后。就可以点击 webui.bat 运行项目。
运行结果如下:
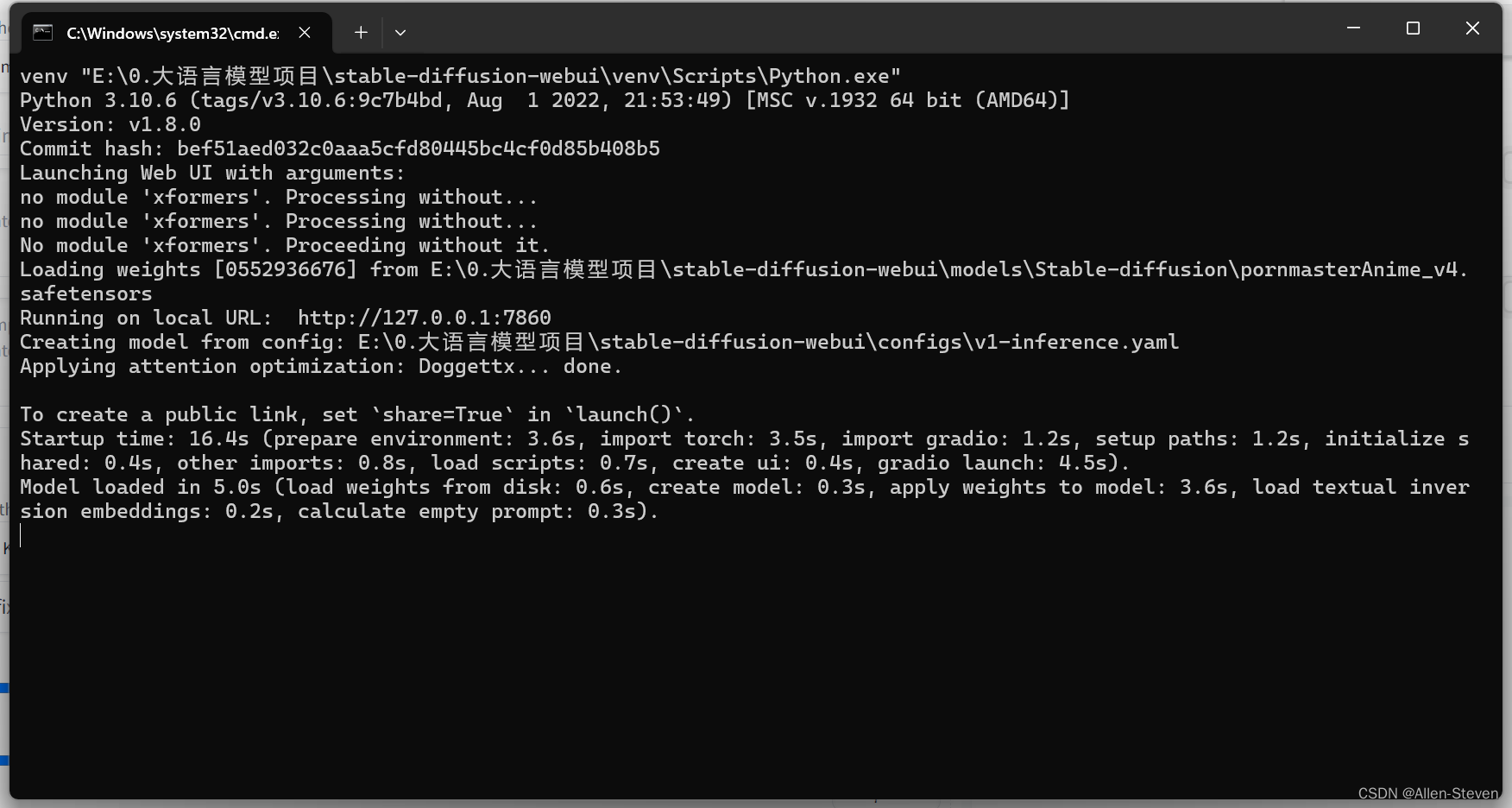
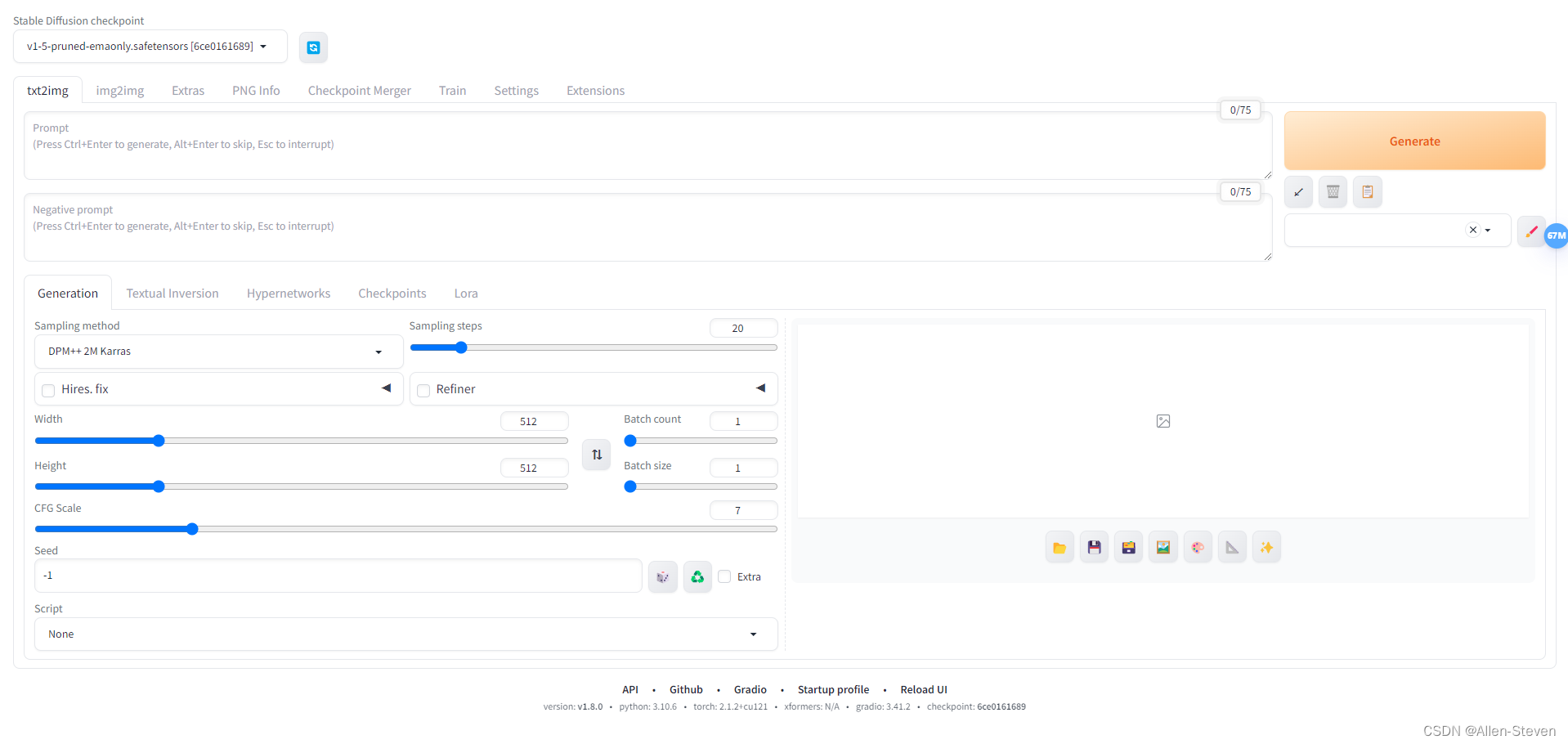
写入你的prompt,点击Generate就可以开始你的text2img魔法之旅了。
四、扩展
如果上面操作大家都没有问题的话,给大家推荐一个模型下载网站:
C站:后期可以加上模型定制与Lora等多元素相结合,生成更多可塑性强的定制图片,让梦幻成为现实。















 3266
3266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









