






一.决策树介绍
决策树是一个预测模型,它代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表某个可能的属性值,而每个叶节点则对应从根节点到该叶节点所经历的路径所表示的对象的值。
决策节点:通常用矩形框来表示
机会节点:通常用圆圈来表示
终结节点:通常用三角形来表示
决策树是一树状结构,它的每一个叶节点对应着一个分类,非叶节点对应着在某个属性上的划分,根据样本在该属性上的不同取值将其划分成若干个子集。对于非纯的叶节点,多数类的标号给出到达这个节点的样本所属的类。构造决策树的核心问题是在每一步如何选择适当的属性对样本做拆分。对一个分类问题,从已知类标记的训练样本中学习并构造出决策树是一个自上而下,分而治之的过程。
二.决策树理论
2.1 信息增益
信息增益(Information Gain)用于度量属性选择前后数据集不确定性的减少程度。我们首先定义数据集D的信息熵H(D),它表示数据集D中样本类别的不确定性。信息熵的计算公式为:
H(D) = - Σ P(xi) * log2P(xi),其中P(xi)表示数据集D中第i个类别所占的比例。
然后,我们计算使用属性A对数据集D进行划分后的信息熵H(D|A),即根据属性A的不同取值将D划分为若干个子集,然后计算每个子集的加权信息熵。
信息增益IG(D, A) = H(D) - H(D|A)。信息增益越大,说明使用属性A进行划分所获得的“纯度提升”越大。
2.2 增益率
增益率(Gain Ratio)是信息增益的改进版,用于解决信息增益对取值较多的属性的偏好问题。增益率的计算公式为:
Gain_Ratio(D, A) = IG(D, A) / IV(A),其中IV(A)是属性A的固有值(Intrinsic Value),用于衡量属性A的取值数量对信息增益的影响。IV(A)的计算公式为:
IV(A) = - Σ (|Dv| / |D|) * log2(|Dv| / |D|),其中|Dv|是属性A取值为v的样本数,|D|是样本总数。
增益率越大,说明使用属性A进行划分的效果越好。
2.3 基尼指数
基尼指数(Gini Index)用于度量数据集的不纯度。基尼指数越小,说明数据集的纯度越高。对于属性A,其基尼指数的计算公式为:
Gini_index(D, A) = Σ (|Dv| / |D|) * Gini(Dv),其中Gini(Dv)是子集Dv的基尼不纯度,计算公式为:
Gini(Dv) = 1 - Σ P(xi)^2,其中P(xi)是子集Dv中第i个类别所占的比例。
在选择最优属性时,我们计算每个属性的基尼指数,并选择基尼指数最小的属性作为最优划分属性。
三、决策树的优缺点及应用场景
3.1 优点
直观易懂:决策树模型的结构清晰,易于理解和解释。人们可以很容易地通过查看树的结构来理解模型是如何根据特征值进行决策的。
分类速度快:一旦决策树被训练好,对新样本进行分类的速度非常快。只需要按照树的决策路径向下遍历,即可得到分类结果。
能够处理非线性关系:决策树可以自动发现特征之间的非线性关系,并基于这些关系进行分类。
无需数据预处理:决策树不需要对数据进行复杂的预处理,如特征缩放或去除缺失值等。
能够处理多分类问题:决策树不仅可以处理二分类问题,还可以处理多分类问题。
3.2 缺点
容易过拟合:如果决策树过于复杂,它可能会过于关注训练数据中的噪声和细节,导致在测试数据或新数据上的性能下降。这通常表现为决策树的深度过大或叶子节点过多。
对连续特征处理不佳:决策树对于连续特征的处理需要进行离散化,这可能会导致信息的损失,影响分类的准确性。
对缺失值敏感:决策树在处理包含缺失值的特征时可能会遇到困难,因为每个节点都需要基于完整的特征集进行决策。
不太稳定:不同的数据集或者不同的模型训练参数可能导致生成的决策树结构差异很大,这可能会影响模型的稳定性和可重复性。
为了克服这些缺点,实际应用中通常会采用一些策略,如剪枝(pruning)来简化决策树,防止过拟合;或者使用集成学习方法(如随机森林)来结合多个决策树的预测结果,提高模型的稳定性和准确性。
3.3 应用场景
电商推荐系统:电商平台可以利用决策树算法,根据用户的历史购买记录、浏览行为、个人偏好等信息,构建决策树模型,实现个性化的商品推荐,从而提高用户购买转化率。
医学诊断:医生可以使用决策树算法来辅助诊断疾病。根据患者的症状、生理指标、病史等特征,构建决策树模型,帮助医生判断患者是否患有某种疾病,从而指导治疗方案。
电影评分预测:在线视频平台可以利用决策树算法,根据用户的观看历史、评分记录、影片类型等信息,构建决策树模型,预测用户对未观看的电影的评分,从而为用户推荐感兴趣的电影。
股票市场预测:投资者可以使用决策树算法来预测股票市场的涨跌。根据股票的历史交易数据、市场指标、财务数据等特征,构建决策树模型,预测股票的涨跌趋势,指导投资决策。
人脸识别:人脸识别系统可以利用决策树算法,根据人脸图像的特征,构建决策树模型,识别出不同的人脸。
风险评估:在金融领域,决策树也被用于风险评估,如信用评分、欺诈检测等。通过构建决策树模型,金融机构可以更准确地评估客户的信用风险,预防潜在的欺诈行为。
游戏AI:在游戏开发中,决策树可以用来模拟游戏角色的行为和决策过程,增加游戏的智能性和互动性。
四、实战部分
4.1 导入所需的Python库和鸢尾花数据集
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
iris = load_iris()
# 选用鸢尾花数据集的特征
# 尾花数据集的 4 个特征分别为:sepal length:、sepal width、petal length:、petal width
# 下面选用 petal length、petal width 作为实验用的特征
X= iris.data[:,2:]
# 取出标签
y = iris.target
# 设置决策树的最大深度为 2(也可以限制其他属性)
tree_clf = DecisionTreeClassifier(max_depth = 2)
# 训练分类器
tree_clf.fit(X, y)
4.2 决策树进行可视化展示
# 导入对决策树进行可视化展示的相关包
from sklearn.tree import export_graphviz
export_graphviz(
# 传入构建好的决策树模型
tree_clf,
# 设置输出文件(需要设置为 .dot 文件,之后再转换为 jpg 或 png 文件)
out_file="iris_tree.dot",
# 设置特征的名称
feature_names=iris.feature_names[2:],
# 设置不同分类的名称(标签)
class_names=iris.target_names,
rounded = True,
filled = True
)
# 该代码执行完毕后,此 .ipython 文件存放路径下将生成一个 .dot 文件(名字由 out_file 设置,此处我设置的文件名为 iris_tree.dot)
结果
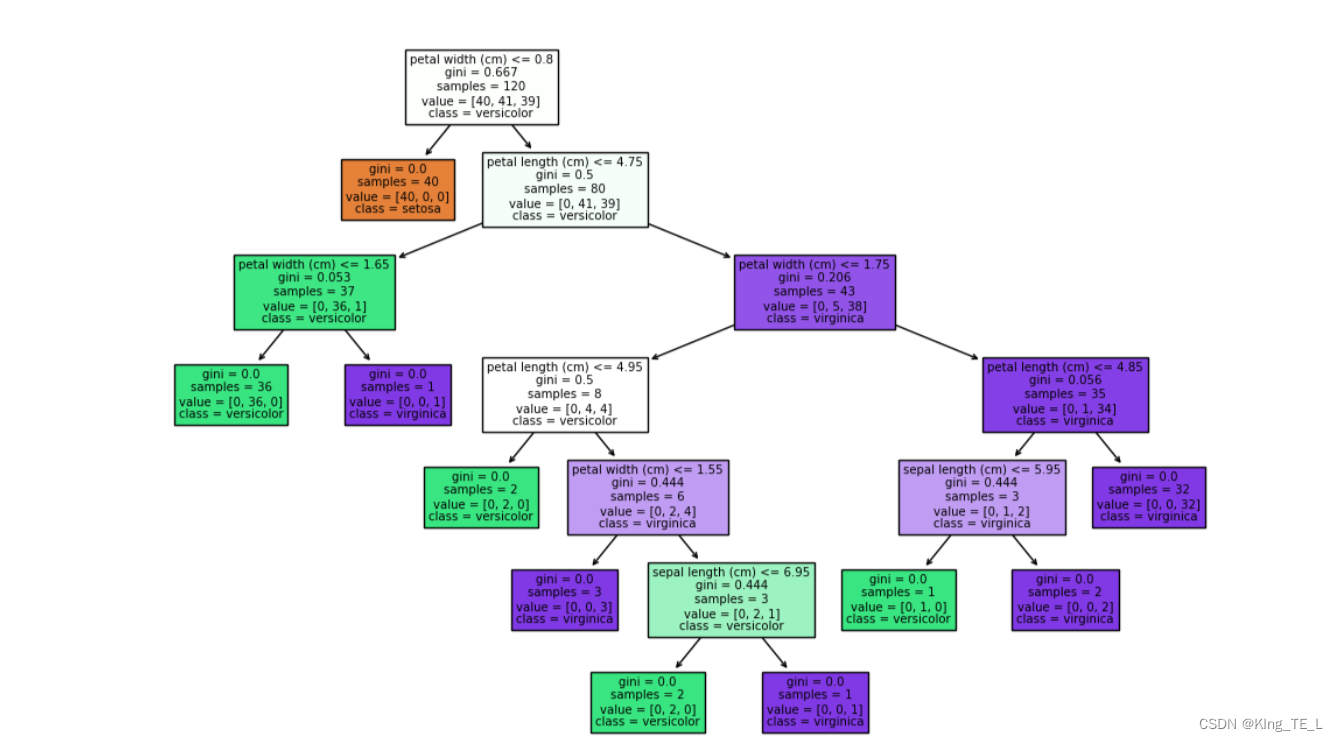
4.3 概率估计
定义绘制决策边界的函数:
from matplotlib.colors import ListedColormap
# 定义绘制决策边界的函数
def plot_decision_boundary(clf,X, y, axes=[0,7,0,3], iris=True,legend=False,plot_training=True):
# 构建坐标棋盘
# 等距选 100 个居于 axes[0],axes[1] 之间的点
x1s = np.linspace(axes[0],axes[1],100)
# x1s.shape = (100,)
# 等距选 100 个居于 axes[2],axes[3] 之间的点
x2s = np.linspace (axes[2],axes[3],100)
# x2s.shape = (100,)
# 构建棋盘数据
x1,x2 = np.meshgrid(x1s,x2s)
# x1.shape = x2.shape = (100,100)
# 将构建好的两个棋盘数据分别作为一个坐标轴上的数据(从而构成新的测试数据)
# x1.ravel() 将拉平数据(得到的是个列向量(矩阵)),此时 x1.shape = (10000,)
# 将 x1 和 x2 拉平后分别作为两条坐标轴
# 这里用到 numpy.c_() 函数,以将两个矩阵合并为一个矩阵
X_new = np.c_[x1.ravel(),x2.ravel()]
# 此时 X_new.shape = (10000,2)
# 对构建好的新测试数据进行预测
y_pred = clf.predict(X_new).reshape(x1.shape)
# 选用背景颜色
custom_cmap = ListedColormap(['#fafab0', '#9898ff', '#a0faa0'])
# 执行填充
plt.contourf(x1,x2,y_pred,alpha=0.3,cmap=custom_cmap)
if not iris:
custom_cmap2 = ListedColormap(['#7d7d58','#4c4c7f','#507d50'])
plt.contour(x1,x2, y_pred,cmap=custom_cmap2,alpha=0.8)
if plot_training:
plt.plot(X[:,0][y==0],X[:,1][y==0],"yo", label="Iris-Setosa")
plt.plot(X[:,0][y==1],X[:,1][y==1],"bs", label="Iris-Versicolor")
plt.plot(X[:,0][y==2],X[:,1][y==2],"g^", label="Iris-Virginica")
plt.axis(axes)
if iris:
plt.xlabel("Petal length", fontsize=14)
plt.ylabel("Petal width", fontsize=14)
else:
plt.xlabel(r"$x_1$", fontsize=18)
plt.ylabel (r"$x_2$", fontsize=18,rotation = 0)
if legend:
plt.legend(loc="lower right", fontsize=14)
绘制决策边界:
# 绘制决策边界
plt.figure(figsize=(8,4))
plot_decision_boundary(tree_clf, X, y)
# 为了便于理解,这里还绘制了决策边界的切割线(基于前面得到的图片)
plt.plot([2.45, 2.45], [0, 3], "k-", linewidth=2)
plt.plot([2.45, 7.5], [1.75,1.75], "k--", linewidth=2)
plt.plot([4.95, 4.95], [0, 1.75], "k:", linewidth=2)
plt.plot([4.85, 4.85], [1.75, 3], "k:", linewidth=2)
# 绘制决策边界划分出的类别所处深度
plt.text(1, 1.0, "Depth=1", fontsize=15)
plt.text(3.2, 2, "Depth=2", fontsize=13)
plt.text(3.2,0.5, "Depth=2", fontsize=13)
plt.title('Decision Tree decision boundaries')
plt.show()
结果:
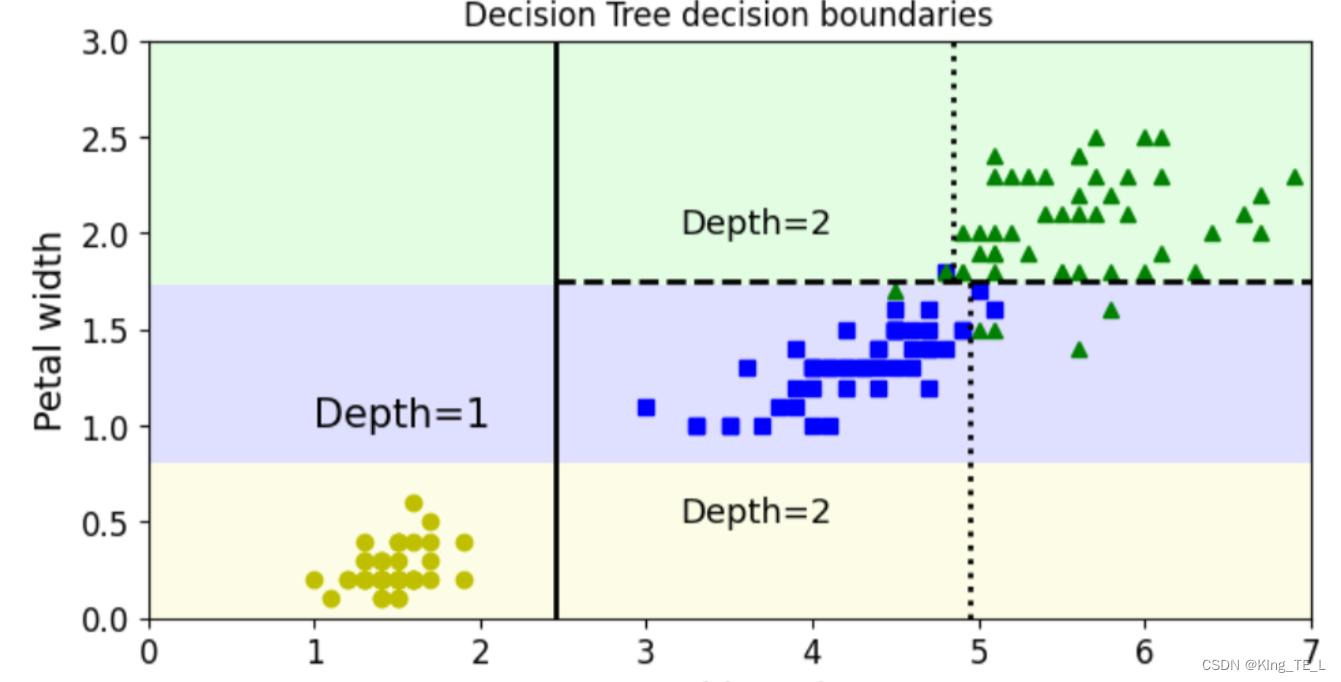
六、总结
本文详细介绍了决策树的理论基础,包括最优属性选择的三种方法,并通过Python代码展示了如何使用scikit-learn库创建决策树、评估模型性能并进行可视化。在实际应用中,我们可以根据数据的特点和需求选择合适的最优属性选择方法。这次实验也让我对决策树有了更深的理解和看法,重点就是掌握决策树的决策理论以及最优属性的选择方法,实验过程中我也遇到了很多困难,比如对Python不熟悉对scikit-learn库中的函数不熟悉。最后,希望在之后的机器学习之旅我能更上一层楼,期待下一次机器学习算法实验。
















 1221
1221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









