







项目内容:
用Python写的糗事百科的网络爬虫。
使用方法:
新建一个Bug.py文件,然后将代码复制到里面后,双击运行。
程序功能:
在命令提示行中浏览糗事百科。
原理解释:
首先,先浏览一下糗事百科的主页:http://www.qiushibaike.com/hot/page/1
可以看出来,链接中page/后面的数字就是对应的页码,记住这一点为以后的编写做准备。
然后,右击查看页面源码:

观察发现,每一个段子都用div标记,其中class必为content,title是发帖时间,我们只需要用正则表达式将其“扣”出来就可以了。
明白了原理之后,剩下的就是正则表达式的内容了,可以参照这篇博文:
http://blog.csdn.net/wxg694175346/article/details/8929576
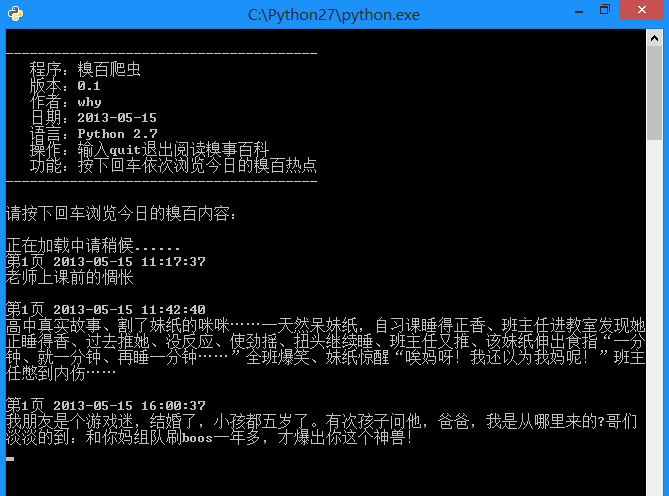
运行效果:
# -*- coding: utf-8 -*-
#---------------------------------------
# 程序:糗百爬虫
# 版本:0.2
# 作者:why
# 日期:2013-05-15
# 语言:Python 2.7
# 操作:输入quit退出阅读糗事百科
# 功能:按下回车依次浏览今日的糗百热点
# 更新:解决了命令提示行下乱码的问题
#---------------------------------------
import urllib2
import urllib
import re
import thread
import time
#----------- 处理页面上的各种标签 -----------
class HTML_Tool:
# 用非 贪婪模式 匹配 \t 或者 \n 或者 空格 或者 超链接 或者 图片
BgnCharToNoneRex = re.compile("(\t|\n| |<a.*?>|<img.*?>)")
# 用非 贪婪模式 匹配 任意<>标签
EndCharToNoneRex = re.compile("<.*?>")
# 用非 贪婪模式 匹配 任意<p>标签
BgnPartRex = re.compile("<p.*?>")
CharToNewLineRex = re.compile("(<br/>|</p>|<tr>|<div>|</div>)")
CharToNextTabRex = re.compile("<td>")
# 将一些html的符号实体转变为原始符号
replaceTab = [("<","<"),(">",">"),("&","&"),("&","\""),(" "," ")]
def Replace_Char(self,x):
x = self.BgnCharToNoneRex.sub("",x)
x = self.BgnPartRex.sub("\n ",x)
x = self.CharToNewLineRex.sub("\n",x)
x = self.CharToNextTabRex.sub("\t",x)
x = self.EndCharToNoneRex.sub("",x)
for t in self.replaceTab:
x = x.replace(t[0],t[1])
return x
#----------- 处理页面上的各种标签 -----------
#----------- 加载处理糗事百科 -----------
class HTML_Model:
def __init__(self):
self.page = 1
self.pages = []
self.myTool = HTML_Tool()
self.enable = False
# 将所有的段子都扣出来,添加到列表中并且返回列表
def GetPage(self,page):
myUrl = "http://m.qiushibaike.com/hot/page/" + page
myResponse = urllib2.urlopen(myUrl)
myPage = myResponse.read()
#encode的作用是将unicode编码转换成其他编码的字符串
#decode的作用是将其他编码的字符串转换成unicode编码
unicodePage = myPage.decode("utf-8")
# 找出所有class="content"的div标记
#re.S是任意匹配模式,也就是.可以匹配换行符
myItems = re.findall('<div.*?class="content".*?title="(.*?)">(.*?)</div>',unicodePage,re.S)
items = []
for item in myItems:
# item 中第一个是div的标题,也就是时间
# item 中第二个是div的内容,也就是内容
items.append([item[0].replace("\n",""),item[1].replace("\n","")])
return items
# 用于加载新的段子
def LoadPage(self):
# 如果用户未输入quit则一直运行
while self.enable:
# 如果pages数组中的内容小于2个
if len(self.pages) < 2:
try:
# 获取新的页面中的段子们
myPage = self.GetPage(str(self.page))
self.page += 1
self.pages.append(myPage)
except:
print '无法链接糗事百科!'
else:
time.sleep(1)
def ShowPage(self,q,page):
for items in q:
print u'第%d页' % page , items[0]
print self.myTool.Replace_Char(items[1])
myInput = raw_input()
if myInput == "quit":
self.enable = False
break
def Start(self):
self.enable = True
page = self.page
print u'正在加载中请稍候......'
# 新建一个线程在后台加载段子并存储
thread.start_new_thread(self.LoadPage,())
#----------- 加载处理糗事百科 -----------
while self.enable:
# 如果self的page数组中存有元素
if self.pages:
nowPage = self.pages[0]
del self.pages[0]
self.ShowPage(nowPage,page)
page += 1
#----------- 程序的入口处 -----------
print u"""
---------------------------------------
程序:糗百爬虫
版本:0.1
作者:why
日期:2013-05-15
语言:Python 2.7
操作:输入quit退出阅读糗事百科
功能:按下回车依次浏览今日的糗百热点
---------------------------------------
"""
print u'请按下回车浏览今日的糗百内容:'
raw_input(' ')
myModel = HTML_Model()
myModel.Start()














 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









