







相关阅读:
TL;DR
目前大多数的Graph Embedding 方法仅对每个顶点生成一个固定不变的向量表示,而这会带来两个问题:
静态向量无法处理
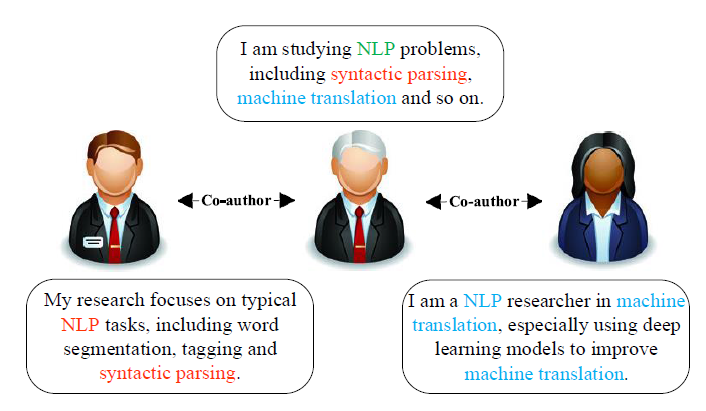
同一节点与不同邻居节点交互时呈现的不同含义aspect;如下图,一个学者可以和不同的合作者就不同的合作方向进行合作;这些方法产生的节点向量通常会使得
同一节点的不同邻居节点的向量也彼此相似,这显然在现实中是不合理的。如下图,左右两个学者的向量应该是相距较远的,因为他们共同关注的话题较少。
为解决上述问题,论文 CANE: Context-Aware Network Embedding for Relation Modeling[1] 提出了 Context-Aware Network Embedding (CANE) 框架,以学习节点的上下文相关向量表示。具体而言,CANE模型考虑了节点丰富的外部属性,如文本、标签等,利用 Attention 机制建模复杂网络关系,最终产出动态上下文相关向量。
模型
为了充分利用数据的结构信息和文本信息,同事更好地刻画网络,CANE 为每个节点设置了两个Embedding
结构向量 :获取网络的结构信息
文本向量 :获取网络的顶点文本信息
最终节点的向量表示为 ,其中 既可以是静态的,也可以是动态的, 是动态的,因此最后整体向量表示是上下文相关的。
文本向量
上下文无关文本向量
有很多神经网络模型可以从单词序列中获取文本 embedding,包括 CNN,RNN 等。论文中作者研究了多个模型,包括 CNN 、双向 RNN、GRU ,最终选择了效果最好的 CNN。
CNN就不需要多说了吧~
上下文相关文本向量
静态文本向量获取很简单,那怎么获取动态文本向量呢?
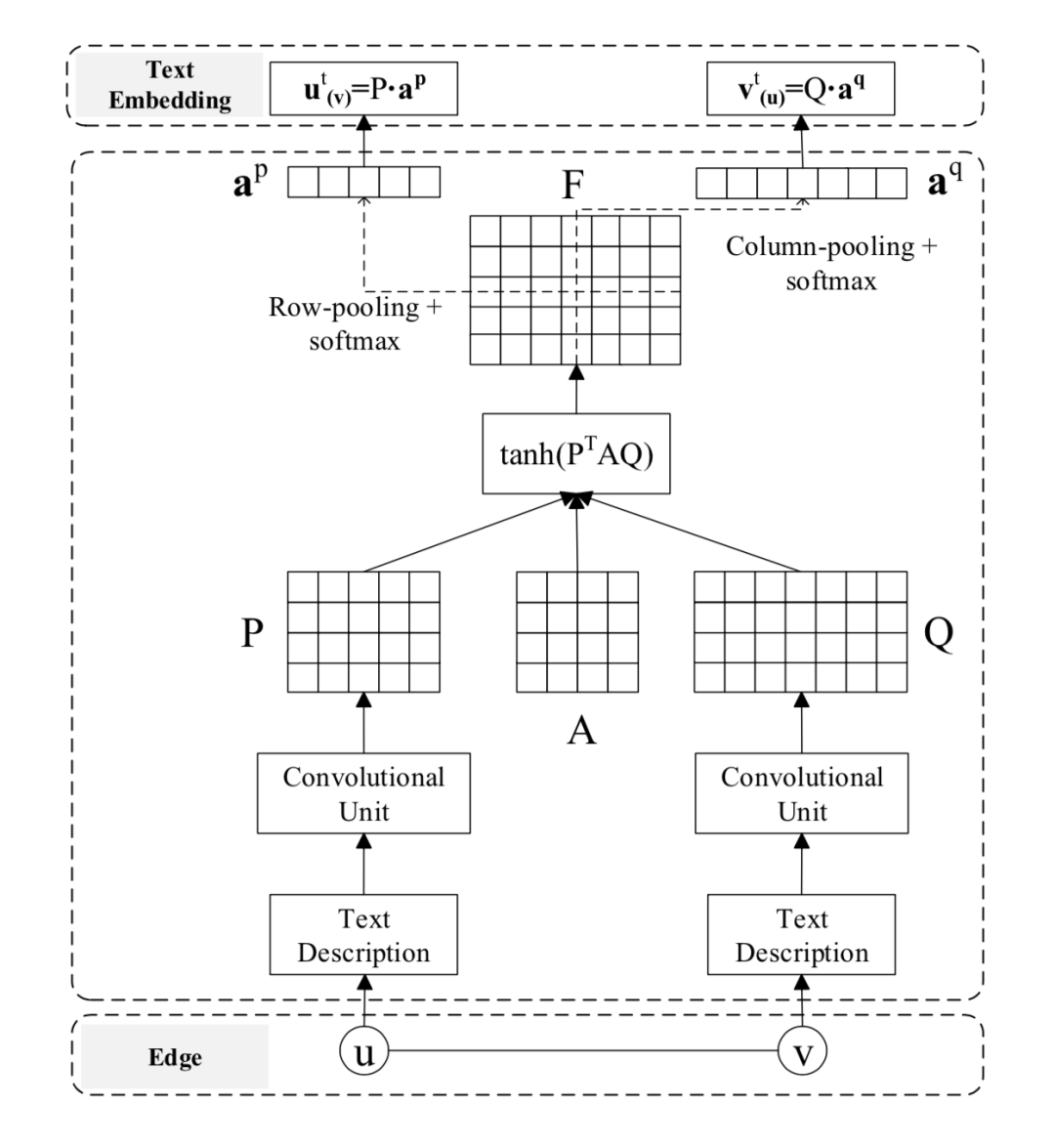
整体模型如下所示。给定一条边 以及顶点 的文本序列和顶点 的文本序列,对两个序列分别过CNN后获得句子表示 和 。然后利用注意力矩阵 对两个序列进行交互,得到相关性矩阵:
其中 表示节点u中第 个元素和节点v中第 个元素的相关性打分。
之后我们对
矩阵 row pooling + softmax 得到
的注意力向量,对
矩阵 column pooling + softmax 得到
的注意力向量,
最终 和 的上下文相关文本向量分别为:
目标函数
CANE 的目标函数为:
其中 由两部分组成:基于结构的目标函数以及基于文本的目标函数。
基于结构的目标函数:假设网络是有向的(无向边可以视为两个方向相反、权重相等的有向边),基于结构的目标函数旨在通过结构
embedding来最大化有向边的对数似然:和
LINE一样,我们定义已知顶点 的条件下存在边 的概率为:基于文本的目标函数:现实世界网络中的顶点通常会伴随关联的文本信息,因此我们可以利用这些文本信息来学习基于文本的顶点
embedding。基于文本的目标函数 有多种形式。为了和 保持一致,我们定义 为:
其中:
控制了对应部分的权重
条件概率 将两种类型的顶点
embedding映射到相同的表达空间中,其计算公式也采用类似 的softmax。
实验
链接预测
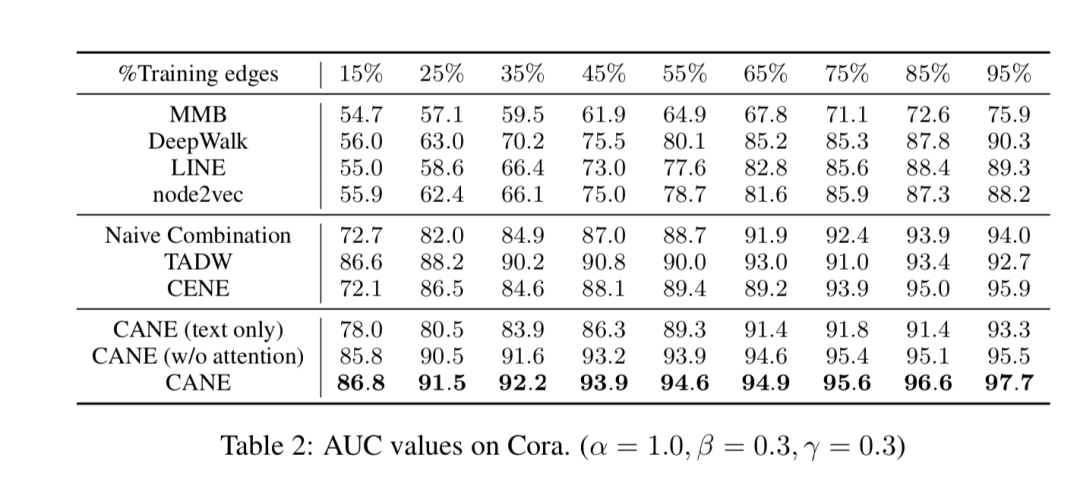
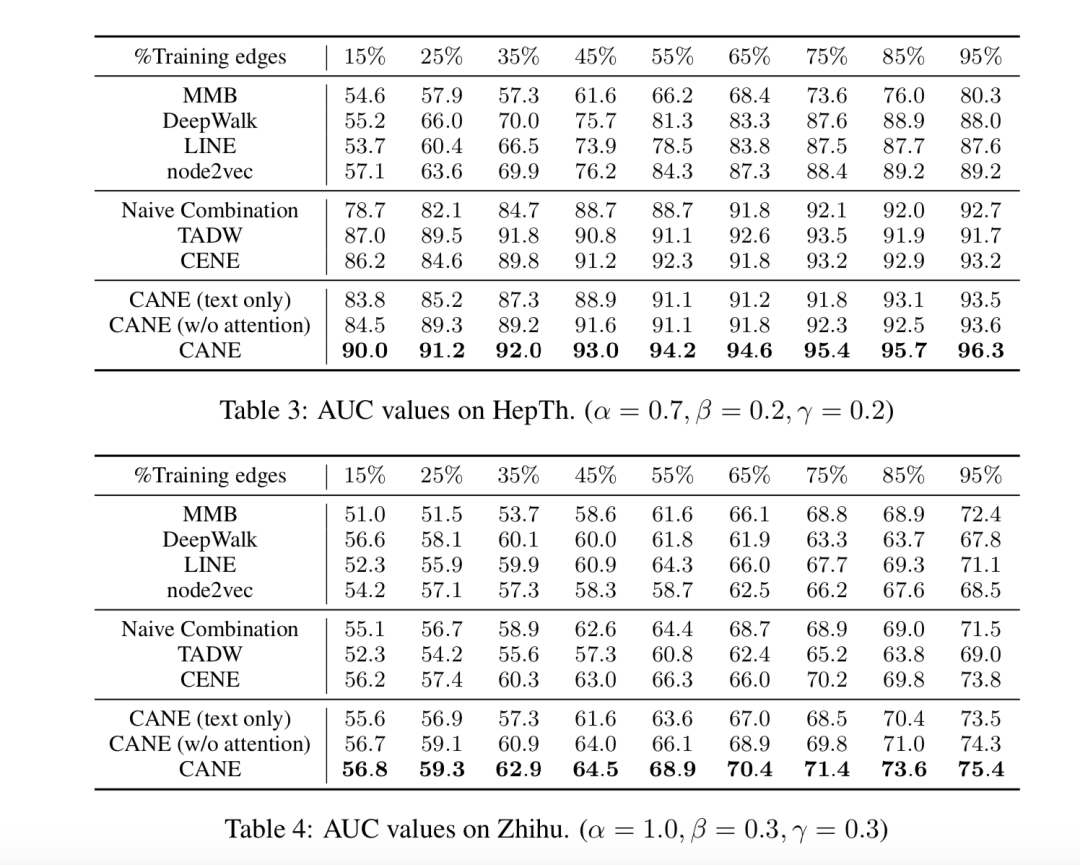
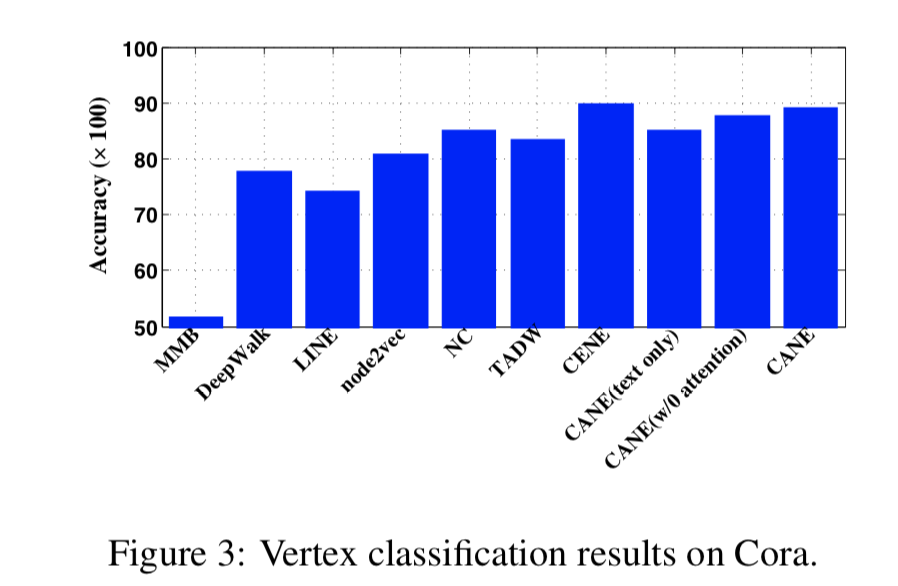
顶点分类
可视化

一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定要备注信息才能通过)

本文参考资料
[1]
CANE: Context-Aware Network Embedding for Relation Modeling: https://www.aclweb.org/anthology/P17-1158/
- END -


Keras正式从TensorFlow分离:结束API混乱与耗时编译

样本量极少如何机器学习?最新Few-Shot Learning综述




















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









