






今天为大家带来阿里巴巴2021年的一篇文章:《One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction》。该文章提出的方法可以只使用一种模型,便可以服务于多种CTR业务场景。这些业务场景中可能会共享一些user和item,也有自己独立的user和item。相比于传统方法中的一个模型对应一种业务,该方法既可以减少多个模型带来的维护成本与计算资源,也可以共享不同业务场景下的数据。我们接下来将详细介绍。
1. 方法动机
针对不同的业务场景,例如图1所示的首页推荐和猜你喜欢,传统方法会针对每个业务场景建立不同的模型。这种方法会带来以下几种问题:
一些业务场景的流量较少,相比于其他相似的业务场景,缺乏训练数据。
维护多个模型会带来大量的成本。
因此,我们提出了一种使用单个模型服务于多种业务场景的任务。我们将其称之为 multi-domain CTR prediction,「即我们的模型需要同时预测在业务场景下的点击率。模型以作为输入,其中为输入特征,为点击标签,为不同业务场景的标识」。其中由不同业务场景下的分布得到。为了充分利用不同业务场景下的数据,该文章提出了以下3种模块:
「Partitioned Normalization (PN)」: 可以针对不同业务场景下不同的数据分布做定制化归一化。
「Star topology fully-connected neural network」: 文章提出了Star Topology Adaptive Recommender(STAR) 来解决多领域的CTR预估问题。该网络可以充分利用多个业务中的数据来提升各自业务的指标。
文章提出了一种「辅助网络」(auxiliary network),直接以业务场景的标识(domain indicator)作为输入,来使得网络更好的感知不同场景下的数据分布。
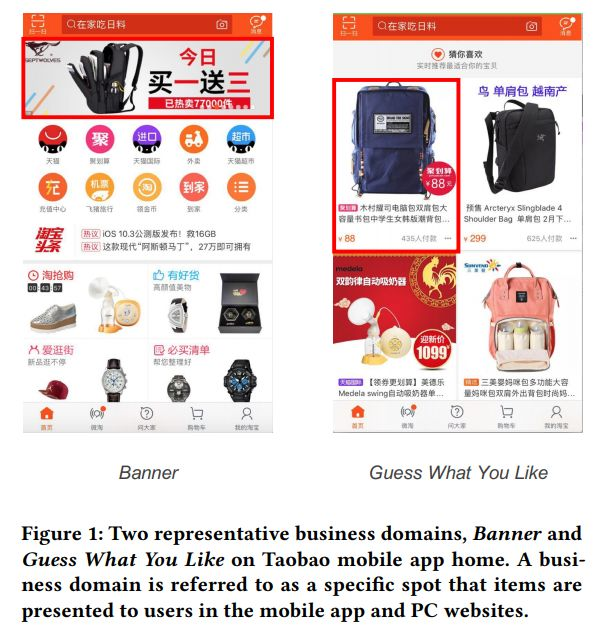 图1:首页推荐和猜你喜欢。
图1:首页推荐和猜你喜欢。
2. 方法介绍
方法总览
如图2(a)所示,之前单场景CTR预估的方法将输入经过embedding层后,通过pooling/concat操作得到一维的向量表示后,通过BN层,经过一系列FC层,输出最后的结果。这类方法一个模型对应一种业务,不能充分利用不同业务场景下相似的数据,也提升了多个模型带来的业务成本。本文提出的方法如图2(b)所示:相比于图2(a)所示的模型,该模型有以下几点不同:
将BN(Batch Normalization)层替换为PN(Partitioned Normalization)层。
将FCN替换为Star Topology FCN。
将domain indicator直接输入。
我们接下来将详细介绍这三个不同之处。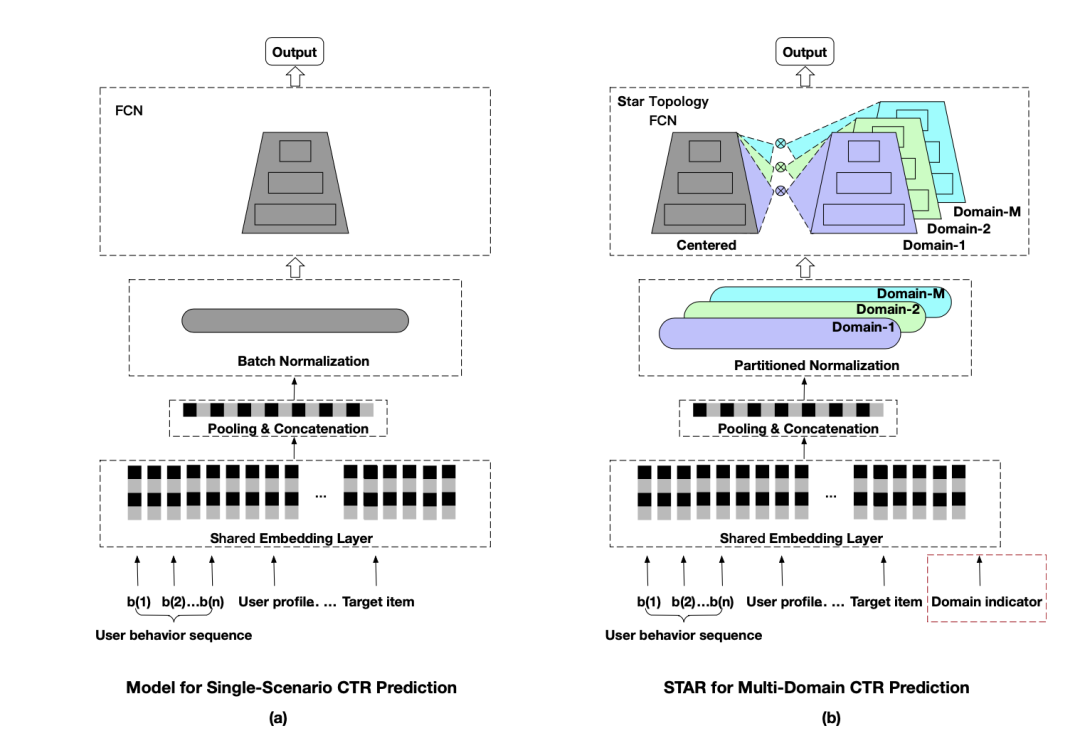
Partitioned Normalization
Batch Normalization (BN)是一个具有代表性的方法,该方法对于深度网络的训练有着关键的作用。具体来说,BN的公式如下:
其中为输出,和 为可学习的缩放系数与bias,和为mini-batch的均值和方差。在测试阶段,BN使用训练中滑动平均得到的均值和方差:
「BN假设所有的样本都是独立同分布(i.i.d),同时所有的训练样本都有着相同的统计规律。」
「然而在multi-domain CTR prediction任务下,样本只在一个domain里遵循i.i.d,不同领域之间并不独立同分布」。因此,文章提出了Partitioned Normalization(PN),具体公式如下:
其中为domain-specific scale 和 domain-specific bias,来捕捉不同domain之间的数据分布。在测试阶段,PN使用训练中每个领域滑动平均得到的均值和方差:
Star Topology FCN
如图2(b)所示,在经过PN层后,输出会作为Star Topology FCN的输入。Star Topology FCN包含一个所有领域共享的FCN和每个领域各自独立的FCN(如图3所示)。因此,所有的FCN数量为, 为domain的数量。对于共享的FCN,我们令为共享FCN的权重,为共享FCN的偏置。对于每个领域各自独立的FCN,我们令其权重为,偏置为。对于第个领域,其最后的权重和偏置表示为:
其中为逐点相乘。我们令为网络第个领域的输入,则输出可表示为:
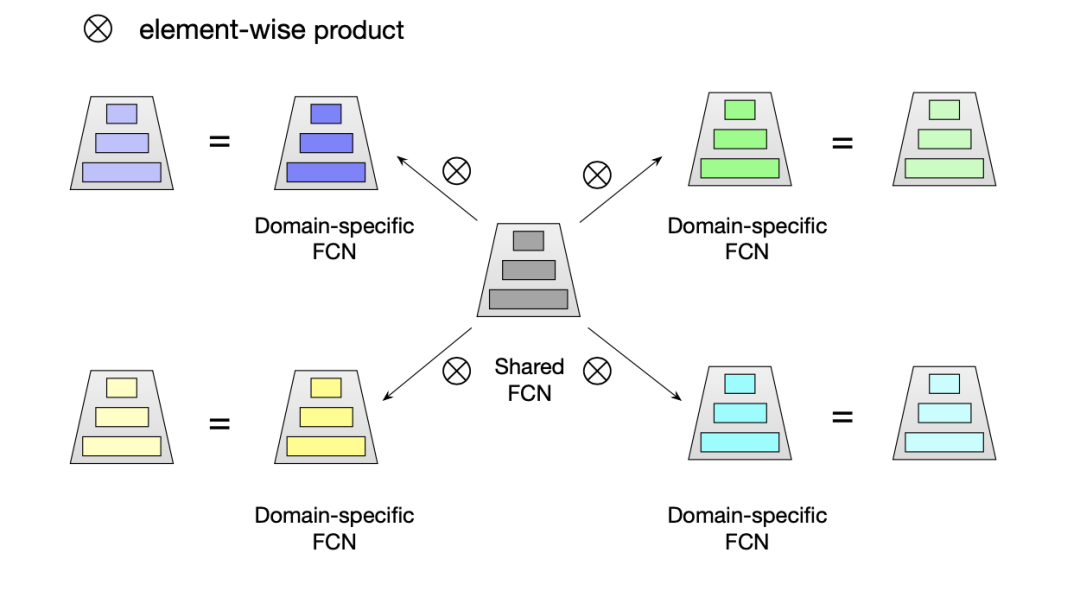 图3:Star Topology FCN结构
图3:Star Topology FCN结构
所以,通俗来说,Star Topology FCN中每个领域网络的权重由共享FCN和其domain-specific FCN的权重共同决定。共享FCN来决定每个领域中数据的共性,而domain-specific FCN习得不同领域数据之间分布的差异性。
为了方便大家理解,我们提供了Star Topology FCN的tensorflow 代码实现,核心步骤实现如代码中注释所示:由于公众号显示代码会有遮挡,欢迎大家点击阅读原文,更方便地查看详细代码。
import tensorflow as tf
from tensorflow.python.keras import backend as K
from tensorflow.python.keras.initializers import Zeros, glorot_normal
from tensorflow.python.keras.layers import Layer
from tensorflow.python.keras.regularizers import l2
def activation_layer(activation):
if isinstance(activation, str):
act_layer = tf.keras.layers.Activation(activation)
elif issubclass(activation, Layer):
act_layer = activation()
else:
raise ValueError(
"Invalid activation,found %s.You should use a str or a Activation Layer Class." % (activation))
return act_layer
class STAR(Layer):
def __init__(self, hidden_units, num_domains, activation='relu', l2_reg=0, dropout_rate=0, use_bn=False, output_activation=None,
seed=1024, **kwargs):
self.hidden_units = hidden_units
self.num_domains = num_domains
self.activation = activation
self.l2_reg = l2_reg
self.dropout_rate = dropout_rate
self.use_bn = use_bn
self.output_activation = output_activation
self.seed = seed
super(STAR, self).__init__(**kwargs)
def build(self, input_shape):
input_size = input_shape[-1]
hidden_units = [int(input_size)] + list(self.hidden_units)
## 共享FCN权重
self.shared_kernels = [self.add_weight(name='shared_kernel_' + str(i),
shape=(
hidden_units[i], hidden_units[i + 1]),
initializer=glorot_normal(
seed=self.seed),
regularizer=l2(self.l2_reg),
trainable=True) for i in range(len(self.hidden_units))]
self.shared_bias = [self.add_weight(name='shared_bias_' + str(i),
shape=(self.hidden_units[i],),
initializer=Zeros(),
trainable=True) for i in range(len(self.hidden_units))]
## domain-specific 权重
self.domain_kernels = [[self.add_weight(name='domain_kernel_' + str(index) + str(i),
shape=(
hidden_units[i], hidden_units[i + 1]),
initializer=glorot_normal(
seed=self.seed),
regularizer=l2(self.l2_reg),
trainable=True) for i in range(len(self.hidden_units))] for index in range(self.num_domains)]
self.domain_bias = [[self.add_weight(name='domain_bias_' + str(index) + str(i),
shape=(self.hidden_units[i],),
initializer=Zeros(),
trainable=True) for i in range(len(self.hidden_units))] for index in range(self.num_domains)]
self.activation_layers = [activation_layer(self.activation) for _ in range(len(self.hidden_units))]
if self.output_activation:
self.activation_layers[-1] = activation_layer(self.output_activation)
super(STAR, self).build(input_shape) # Be sure to call this somewhere!
def call(self, inputs, domain_indicator, training=None, **kwargs):
deep_input = inputs
output_list = [inputs] * self.num_domains
for i in range(len(self.hidden_units)):
for j in range(self.num_domains):
# 网络的权重由共享FCN和其domain-specific FCN的权重共同决定
output_list[j] = tf.nn.bias_add(tf.tensordot(
output_list[j], self.shared_kernels[i] * self.domain_kernels[j][i], axes=(-1, 0)), self.shared_bias[i] + self.domain_bias[j][i])
try:
output_list[j] = self.activation_layers[i](output_list[j], training=training)
except TypeError as e: # TypeError: call() got an unexpected keyword argument 'training'
print("make sure the activation function use training flag properly", e)
output_list[j] = self.activation_layers[i](output_list[j])
output = tf.reduce_sum(tf.stack(output_list, axis=1) * tf.expand_dims(domain_indicator,axis=-1), axis=1)
return output
def compute_output_shape(self, input_shape):
if len(self.hidden_units) > 0:
shape = input_shape[:-1] + (self.hidden_units[-1],)
else:
shape = input_shape
return tuple(shape)
def get_config(self, ):
config = {'activation': self.activation, 'hidden_units': self.hidden_units,
'l2_reg': self.l2_reg, 'use_bn': self.use_bn, 'dropout_rate': self.dropout_rate,
'output_activation': self.output_activation, 'seed': self.seed}
base_config = super(STAR, self).get_config()
return dict(list(base_config.items()) + list(config.items()))Auxiliary Network
文章还提出了一个辅助网络来学习不同领域之间数据分布的差别。该网络和主干网络相比,参数量很小,仅为几层layer。该辅助网络以domain indicator 的embedding作为输入,同时连接了其他的特征。输出为,我们令主干网络的输出为。最终的CTR预测结果如下所示:
由此可见,domain indicator会直接影响到输出分数的变化,增强了网络捕捉不同领域数据分布的能力。
总结
本文首先提出了不同业务场景下,数据互相共享互补提升的思路,提出了一种新的任务:multi-domain CTR prediction。并针对这类任务设计了PN,Star Topology FCN,辅助网络等结构。笔者认为,该文章具有很好的借鉴价值,大家可以在自己的任务上或者业务中进行尝试,欢迎大家交流。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定要备注信息才能通过)

参考文献:
Sheng XR, Zhao L, Zhou G, Ding X, Luo Q, Yang S, Lv J, Zhang C, Zhu X. One Model to Serve All: Star Topology Adaptive Recommender for Multi-Domain CTR Prediction. arXiv preprint arXiv:2101.11427. 2021 Jan 27.
- END -




升级换代!Facebook全新电商搜索系统Que2Search



















 2513
2513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









