







作者 | 陈胜 美团 搜索排序负责人
整理 | DataFunTalk
美团的业务品类非常多,不同业务之间的履约方式差异很大。例如当用户进行搜索时,返回的是一个异构混排后的结果,可能会推荐一些具体的到店POI,也会推荐外卖POI,也可能是美团优选或者美团买菜的商品等。所以美团的排序架构需要同时承接很多业务。本次分享的主题是美团搜索在多业务排序领域上的实践。
今天的介绍会围绕下面三点展开:
美团搜索介绍
排序优化实践
排序优化总结
01
美团搜索介绍
首先和大家介绍一下美团搜索。
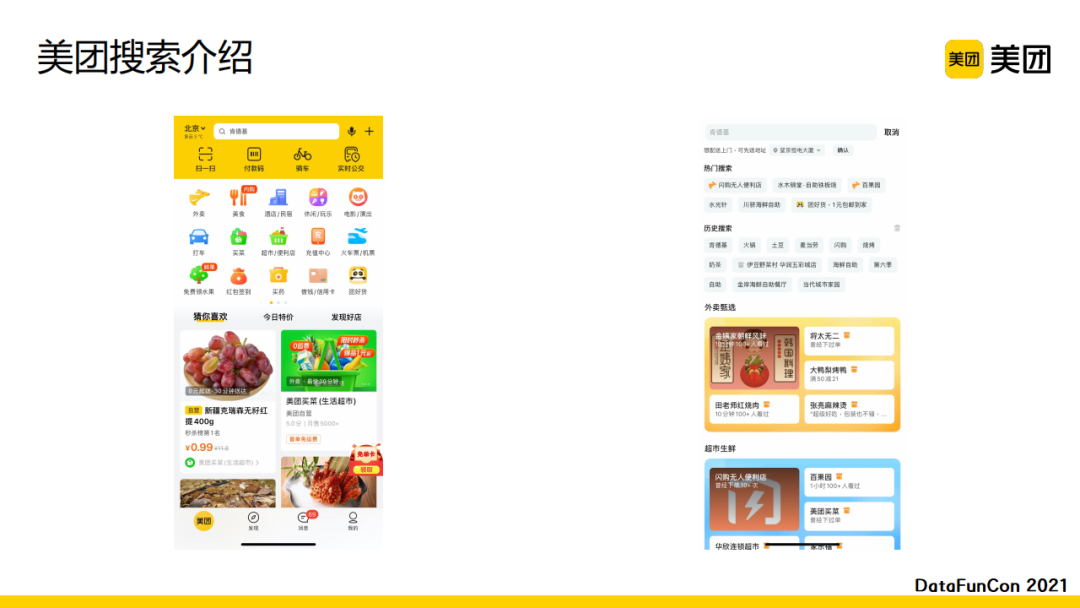
美团搜索的主要入口是美团App的首页搜索框。美团App首页主要有三部分:搜索框、金刚位和推荐流。从金刚位的布局可以看出美团的业务很多,包括外卖、美食、酒店、民宿、休闲娱乐、电影、演出、买菜、超市、买药等。
当进入搜索框之后,会有一个起始页,包含热词推荐和卡片推荐。用户开始输入后,会进入SUG推荐,比如用户输入“ken”的时候,我们会关联到“肯德基”这一文本,并推荐一些具体的POI,包括外卖的POI以及到店的POI,是一个异构混排的场景。发起搜索后,会进入搜索结果页。因为美团包含众多业务,例如搜索“肯德基”,用户可能是想点外卖,也可能是想去店里,还有可能是想获取精选优惠等。
02
排序优化实践
1. 排序架构
接下来,介绍一下美团搜索的排序架构。
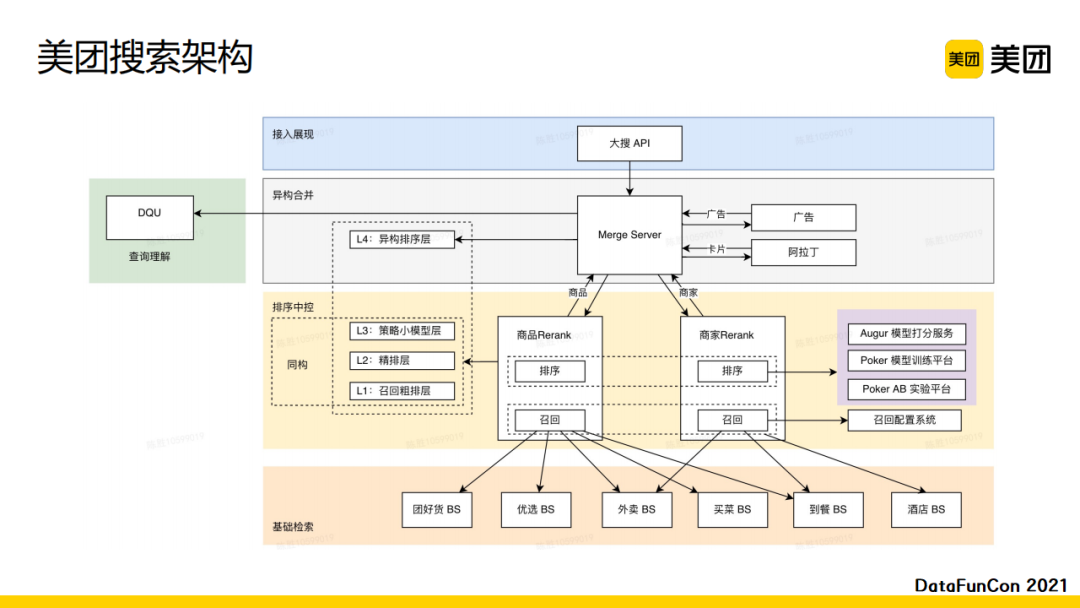
美团搜索的排序架构从上而下可以被分成四层。
最上层是用户发出query请求后有一个接入展现层。
下面一层是异构合并层。返回的结果包含四种类型:商品、商家、广告和卡片。商品和商家都包含多个业务,例如商家可以有酒店、旅游景点、餐饮店等;商品可以有送药上门的商品、美团优选的商品、美团买菜的商品等。不同的业务履约的形式也不一样。
再下面一层是商品和商家的排序层,我们进一步将其细化为不同层级。首先是召回粗排层L1,接下来是精排层L2,再往后是策略小模型层L3。商品和商家会在两路分别进行同构排序。在排序中控层完成同构排序后,我们会将结果送入上层的merge server进行异构排序。这时候排序就会涉及异构的元素,比如商品、商家、各种卡片以及广告,卡片常见的例子有排行榜和运营活动等。异构排序完成后会把最终结果返回给用户。架构还包含一个查询分析模块,会对query输入进行理解。
最下层是基础检索层,我们会针对不同的业务进行索引和基本召回服务的构建。
总结来说,由于美团在线上有很多业务,整个搜索排序架构会对业务进行分类,主要分为商家和商品。基于这两类我们构建了不同的排序服务。我们还对排序进行了进一步分层,分为同构排序和异构排序,并将它们分别部署在排序中控服务和merge server中进行实现。同构排序内部又分成三层,支持在不同场景下的排序优化。在排序层最上层L4,我们会进行异构排序。
为了更好地支持排序服务,我们开发了一些平台。例如我们的模型训练平台、AB实验平台、在线模型预估平台、召回配置系统等。这些平台可以提升算法的迭代效率,让算法和工程能更好地进行协作。
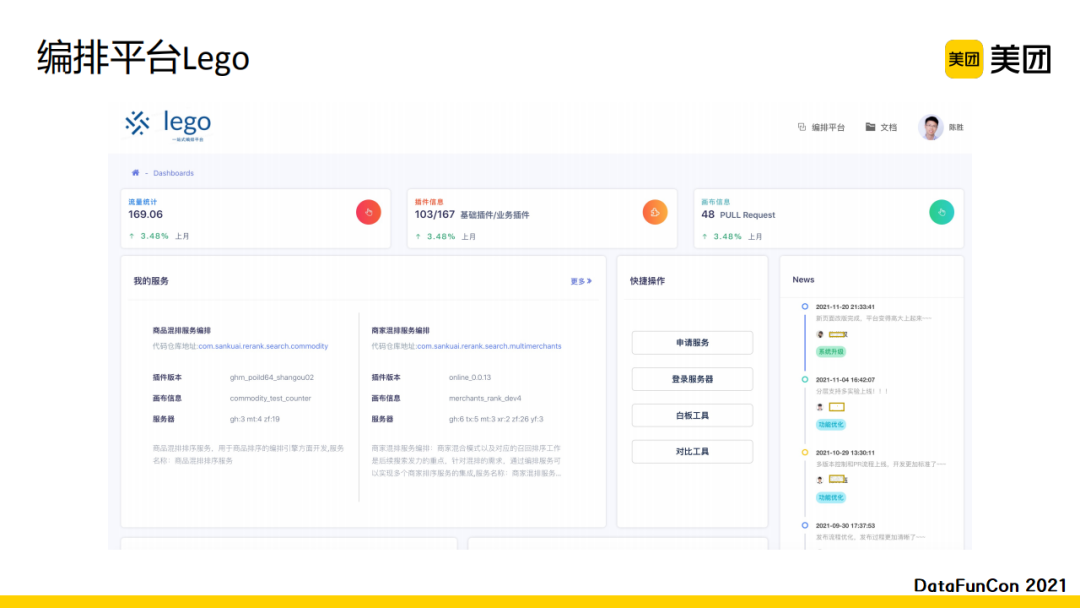
首先为大家介绍的是编排平台Lego,它是用来构建商品和商家的排序中控服务。这个服务中需要调用召回模块,进行多路合并,并进行精排和重排。
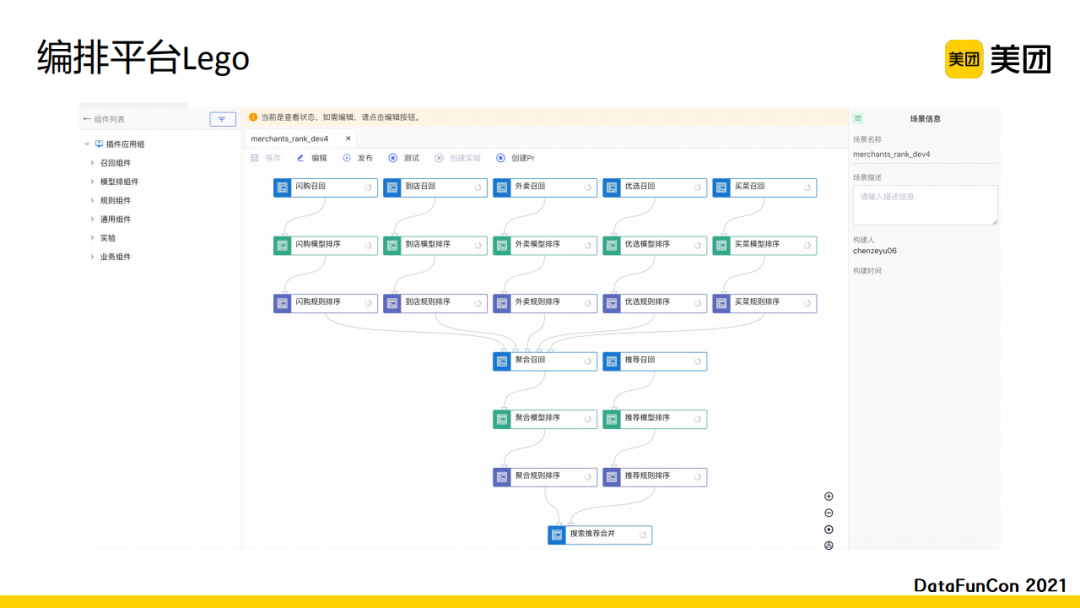
编排系统分为三个部分。中间是画布,它会组织当前服务的构建形式。左侧是通用的召回组件、排序模型组件、规则组件等,方便大家快速地在画布上进行迭代。右侧是画布与组件的配置,使得我们可以通过快速配置提升算法迭代效率。比如我们需要对“买菜”这个索引进行召回时,我们就可以使用召回组件快速地构建这一路召回。模型预估组件的作用是当我们进行某一个模型的在线预估时,可以通过配置模型预估组件来快速搭建模型预估服务。规则组件是在我们做策略优化的时候可以不写业务代码,利用已有的规则组件,如过滤、重排等直接进行配置,提升效率。
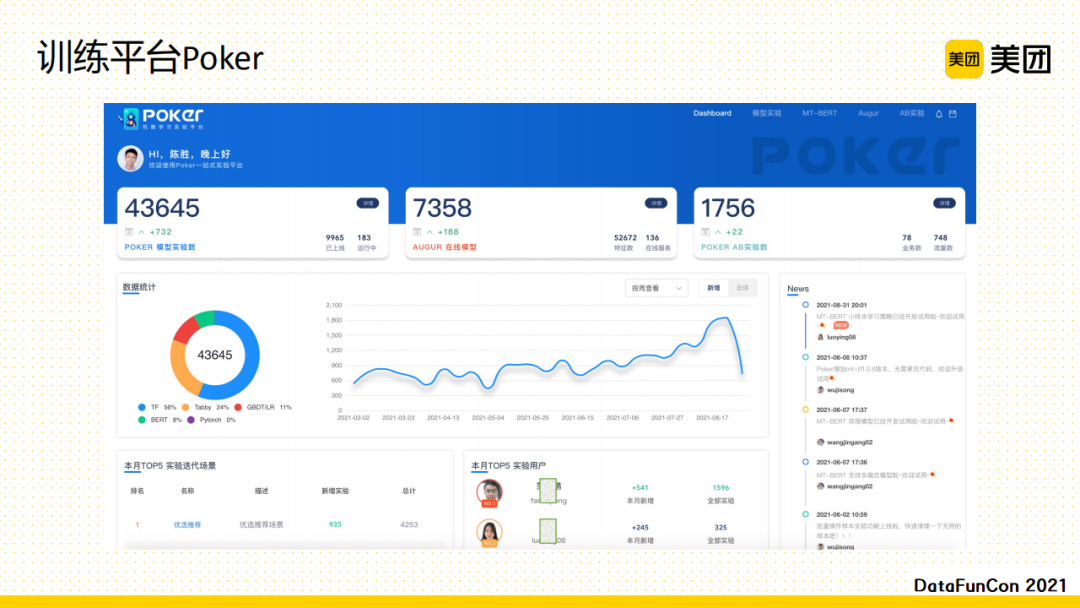
为大家介绍的第二个平台是训练平台Poker。它是一个一站式的训练实验平台。对于算法工程师来说,他需要进行数据获取、样本生成、模型训练、模型评估、再到AB实验,最后生成一个数据报表。整个执行流程都可以在Poker平台上完成,极大提升了算法迭代的效率。上图展示了平台的具体页面,里面包含模型的列表、特征的管理、实验平台、预估平台等。这样,通过一站式模型训练预估平台,极大地提升了策略迭代效率。
2. 多业务建模
(1) 多业务场景及挑战

多业务场景是美团搜索中比较独特的。美团的业务数量众多,业务供给的品类属性和履约方式差异很大。例如外卖与美食业务,对于同样一个“肯德基”query,有的用户是想点一个外卖送到家,而也有用户希望查看附近的肯德基门店。又比如针对买菜这一需求,美团买菜是提供30分钟到家的即时配送服务,而美团优选是隔日自提。

上图展示了一个典型的美团搜索多业务场景。比如当用户搜索“望京”的时候,可能是需要预定望京附近的酒店,或者是搜索望京周围的美食,也可能是查看望京周围的KTV或者电影院。这就是一个典型的美团多业务场景。
多业务场景下对应的就是多目标带来的挑战。首先,我们应该如何平衡不同的任务;其次,我们应该如何共享不同业务或者不同目标上的特征来提升模型的表现。
(2) 排序分层架构
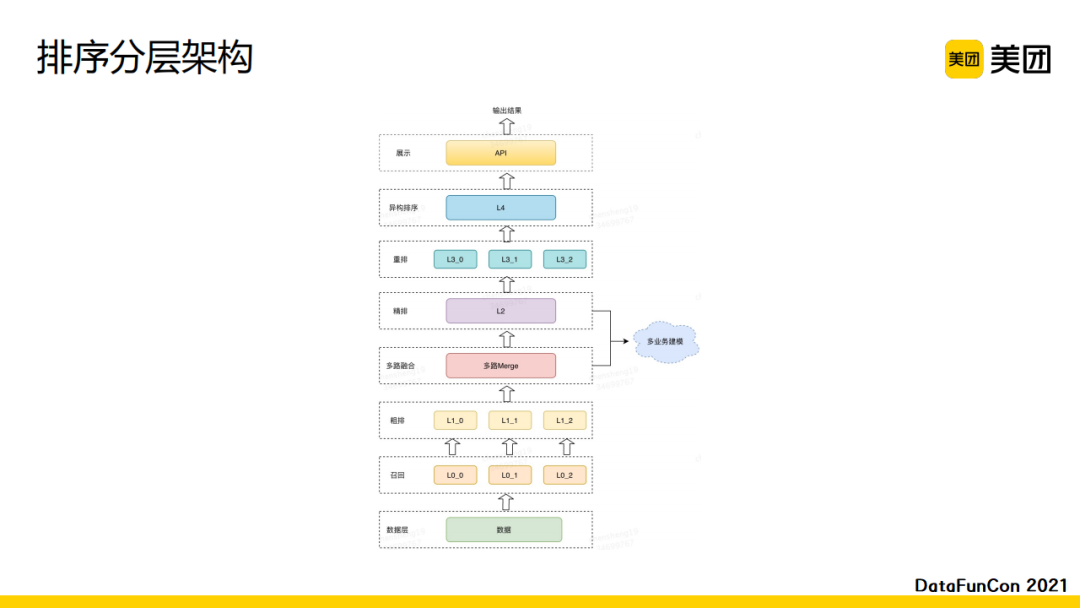
现在给大家展示一下从排序算法的角度如何做全链路的分层。最下面是数据层,接下来会进行多路的召回和多路的粗排,然后会进行多路融合,随后进行统一的大模型精排,再往上一层是各个场景的重排序以及异构排序。其中异构排序会引入卡片和广告。最后我们会有一个API进行结果展示。
接下来我重点介绍美团在多路融合层和L2排序层是如何对多业务进行建模的。
(3) 多业务配额模型
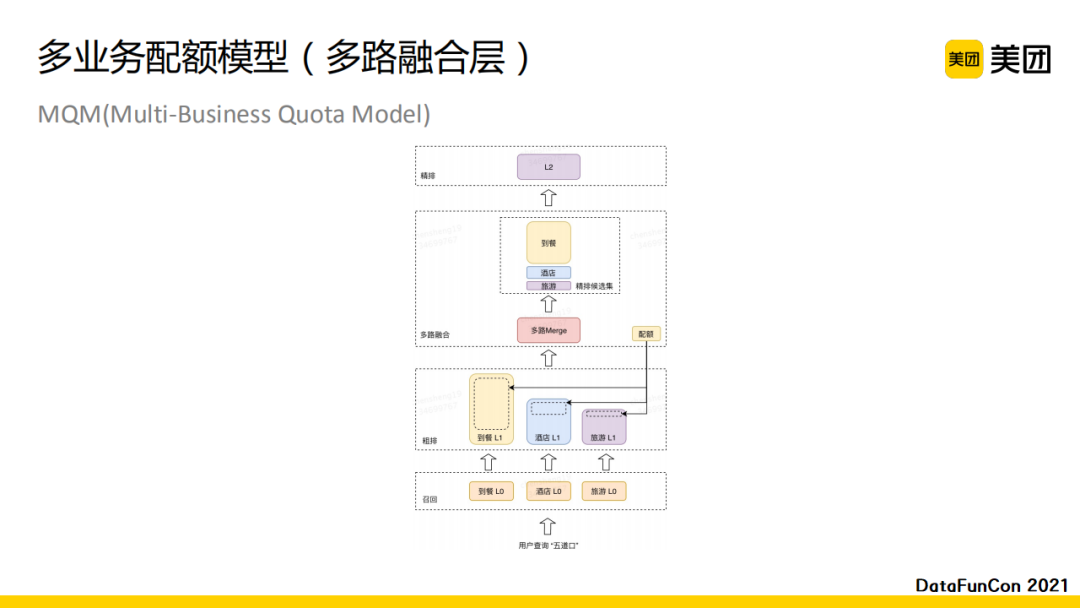
首先展示美团的多业务配额模型。它主要作用在多路融合层,即粗排后的结果融合。融合需要有一个配额,即每一路的top多少能够进入下一个精排层。
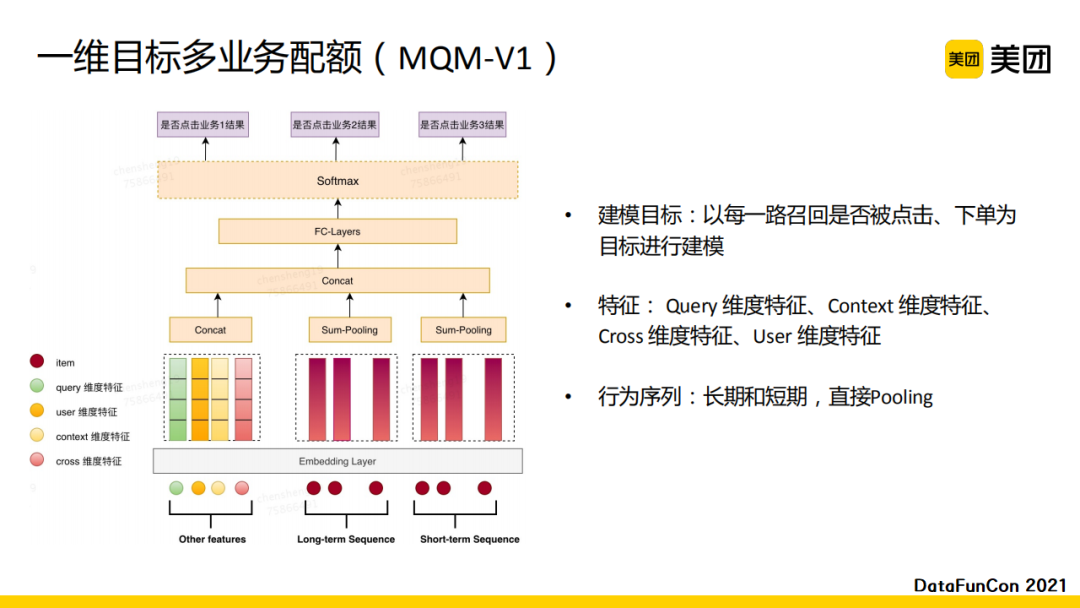
我们一共实现了两版方案。第一版方案比较直观。首先,我们每一个业务都有一个独立的目标,即以每一路召回是否被点击、下单为目标进行建模。特征包含query维度、context维度、cross维度以及user维度,并分别对它们做embedding。在训练时我们也引入了长期和短期的行为序列。针对每一个业务我们会做一个softmax,最后将输出作用至每一路进行融合。
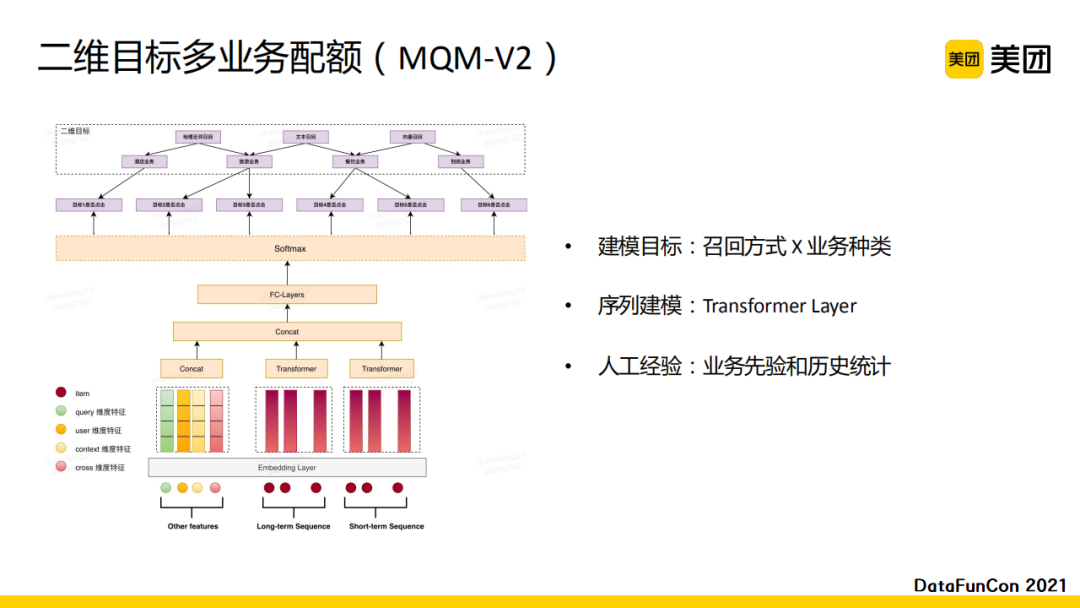
第一版模型有很多优化迭代空间,我们推出了第二版模型。在目标层面,从召回的角度来讲,业务的品类以及召回方式具有很大的差异。在美团的场景中,主要的召回方式分为:基于地理位置的召回、基于文本的召回以及向量召回。不同的召回方式带来的召回结果差异很大。比如向量化召回的相关性差异就比较大,而地理位置召回的品类也会有较明显的差异。所以我们使用叉乘将建模的目标转换为二维目标,即通过召回方式和业务种类进行叉乘,更细粒度刻画建模目标。在建模这一层面,我们使用Transformer更好的进行序列表征抽取,并加入人工经验(业务先验和历史统计),提升多路召回融合的鲁棒性。
(4) 多业务精排建模
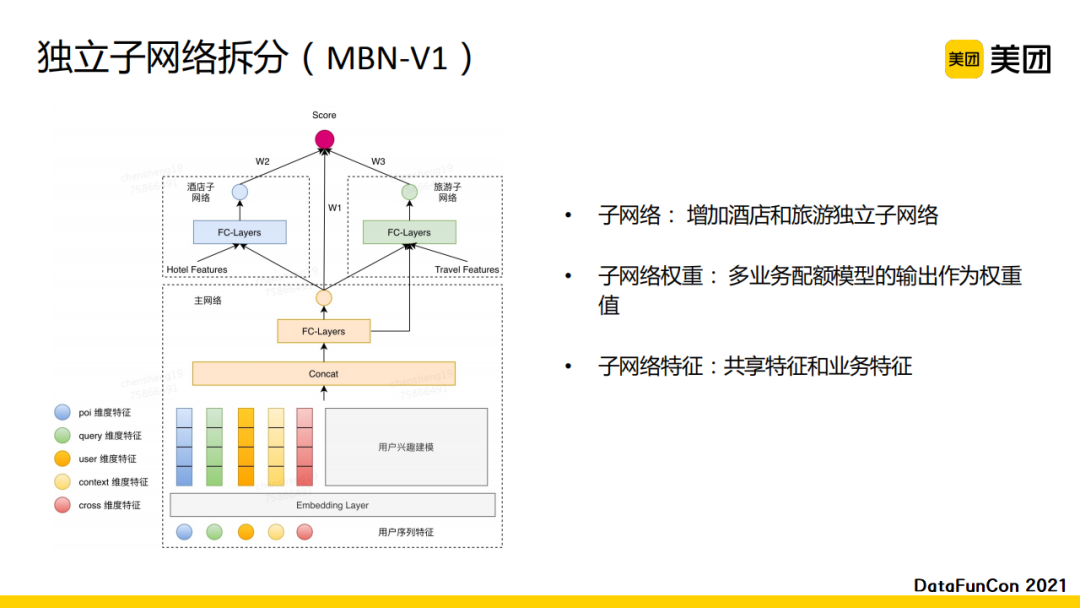
下面介绍一下多业务精排的实践经验。上图展示的是多业务精排的第一版模型。模型基于一个主网络,会首先得到一个预估值。上层会加入根据业务额外拆分的两个独立子网络,其中一个代表酒店,另一个代表旅游。酒店和旅游相对于其他业务较为低频,可以共享主网络的高阶表征输出。多业务配额模型的权重会作为主网络与子网络的输出融合权重。子网络的输入特征包括业务相关的独立特征和主网络的通用共享特征。
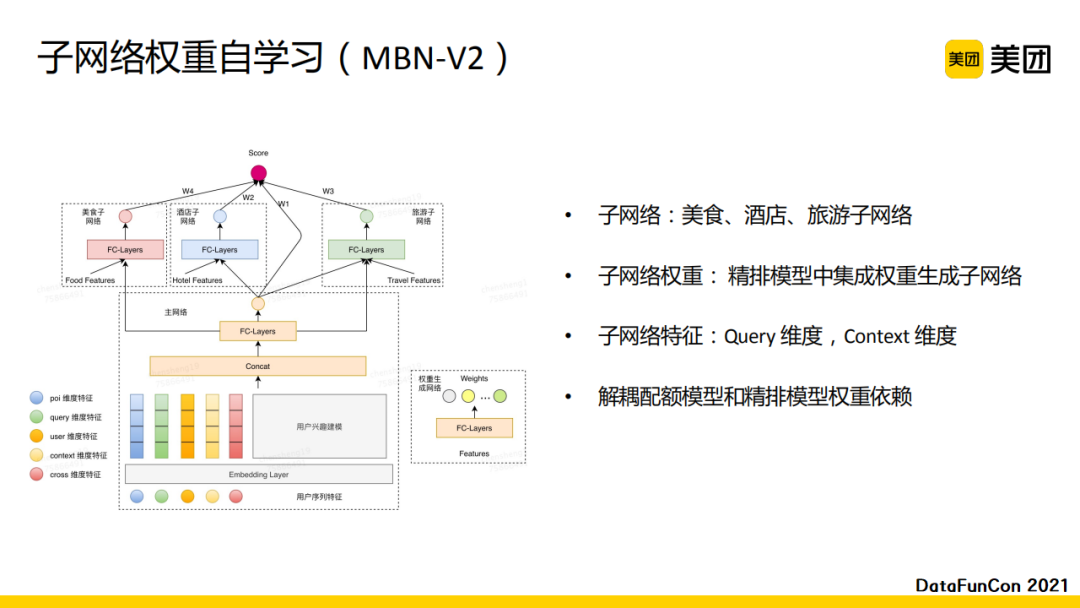
之后我们进行了一版迭代。首先,在子网络层面,我们将其进行了更精细化的拆分,将美食、酒店、旅游都独立拆分子网络。同时,针对子网络的权重,我们会有一个权重生成子网络与精排模型进行联合训练。因为在第一版时网络融合的权重是配额模型softmax得到的值,但是这会导致精排与多路融合网络有了强耦合。所以针对这个问题,我们在这一版模型中进行了解耦。
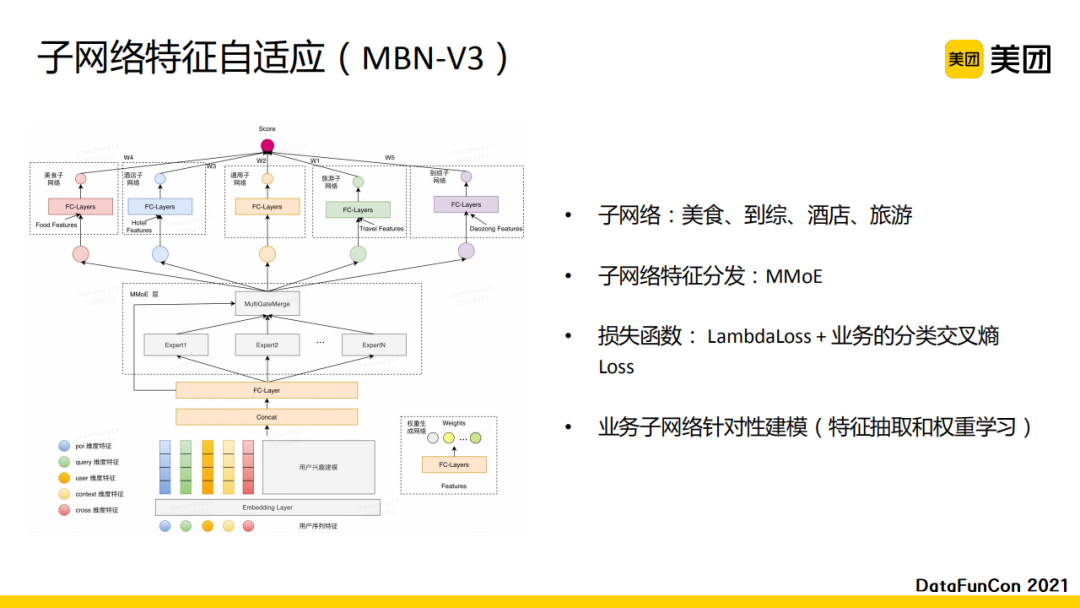
我们随后又做了一次迭代,对子网络进行进一步拆分,这一版本的模型总共有五个子网络。子网络的特征分发我们使用了MMoE,通过五个专家和不同的门控,使得每个业务子网络的输入特征是与业务最为相关的高层语义表征。损失函数的设计中我们使用了LambdaLoss与业务的分类交叉熵。加入交叉熵的原因是模型在做预估时,每个输出都会有一个品类,我们希望品类对应的子网络获得的权值更高,这样可以真正使每个子网络建模对应的业务场景。
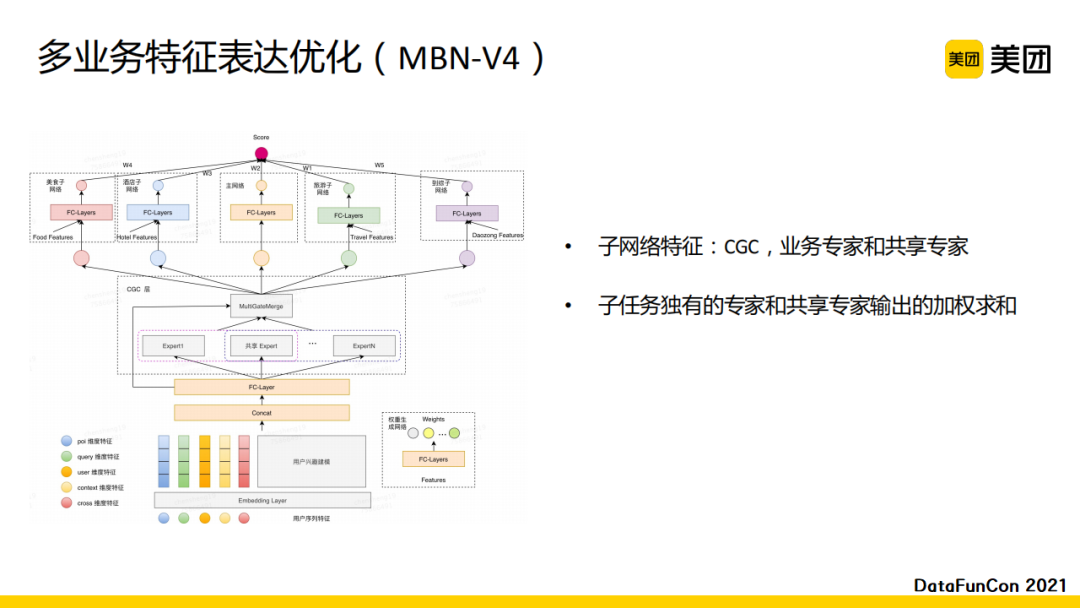
在做第四个版本的时候,我们进行了进一步升级。首先,我们借鉴了腾讯的CGC的工作替换了MMoE,发现CGC的效果有所提升。这是因为CGC显示的分开了共享专家和独享专家,可以更好地刻画复杂场景下的业务表征。业务子网络的输入是业务独有的专家和共享专家输出的加权求和。模型的输出与之前相同,是多个子网络的线性融合。
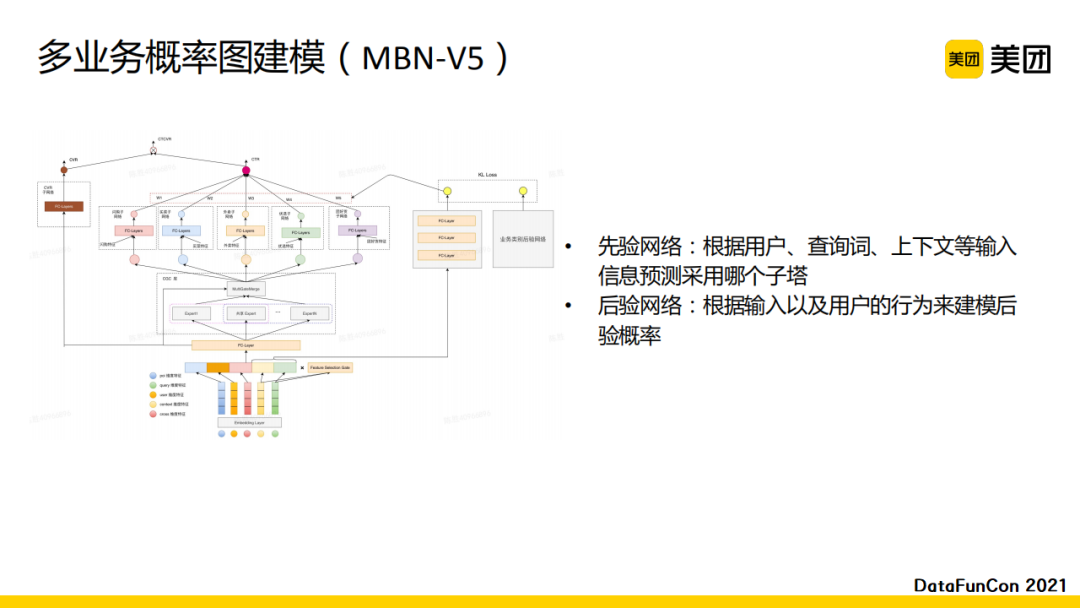
我们最后还在第四版模型的基础上做了进一步迭代。这一版中我们直接抽取了单独的网络结构作为先验网络和后验网络,建立了基于概率图的多业务模型。先验网络根据用户、查询词、上下文等输入信息预测query需要使用哪一个子塔,即输出对应的子塔的权值会更高。同时,我们还建立了一个后验网络,根据用户的行为和输入来建模后验概率,代表在模型得到业务分布后预测query需要使用哪一个子塔,即根据用户行为反馈来预测对应的业务。这个后验网络只会在训练中使用,而在预测的时候仅使用先验网络来预估结果,将输出使用在子目标的融合中。
3. 聚合建模

现在和大家分享一下美团搜索在聚合建模中的一些工作。我们有一部分场景的产品样式会包含不同的聚块,如上图所示。每个聚块有不同的大小,比如用户在搜索“鸡蛋”的时候,返回的结果可能会有生鲜到家,那么这个聚块中包含的就是生鲜到家的结果。类似的,美团优选、电商包邮等结果也会分别形成一个聚块。每一个聚块内部有相同的业务,不同的聚块业务不同,且不同聚块之间大小具有差异。这种场景就是典型的多目标建模场景,首先它需要预测哪一个聚块需要被排在前面,即聚块的排序问题,其次它需要预测每一个聚块的大小。
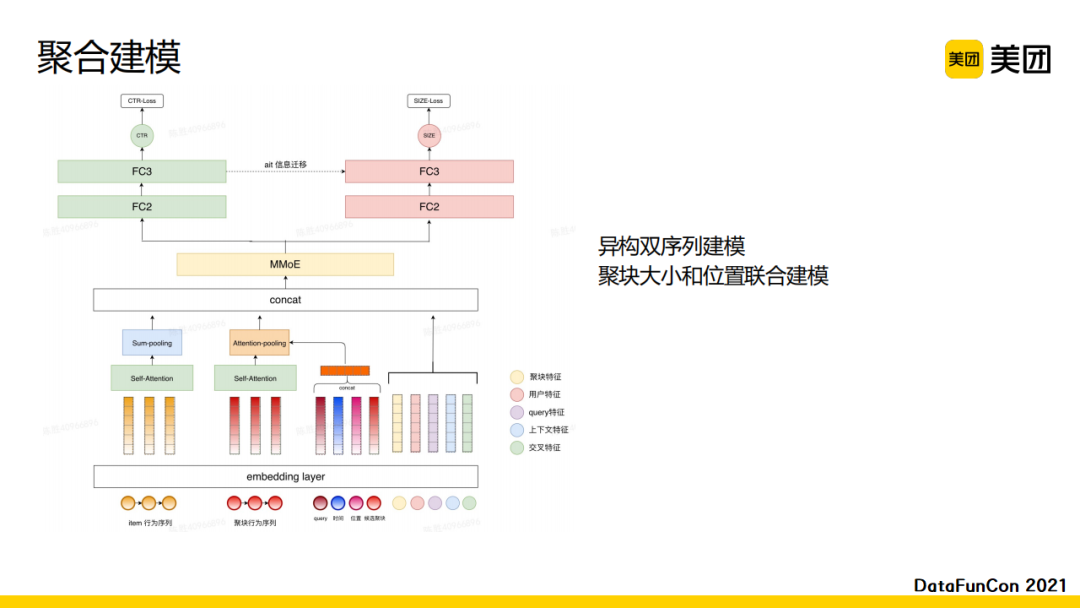
我们最初是将问题分为两步进行建模的。首先我们会设计一个独立的子网络来预测每一个聚块的位置,之后基于聚块的位置对聚块的大小进行预估。后来我们将这两部分做了统一建模,如上图所示。模型有两个目标:CTR和聚块大小。
此外,聚块排序接受的序列输入有两种:item行为序列和聚块行为序列。Item行为序列是用户直接点击某一些商品或者某一些商家构成的,而用户点击聚块的行为组成另一维度的行为序列。由于聚块行为序列表达了用户强烈且明确的需求,且两种序列异构,所以我们需要对这两类行为序列分别建模。我们使用了不同的attention机制对两类序列进行特征抽取,同时将查询词、时间和位置等上下文信息和候选聚块一同作为 Attention 中的 Target 来更好的刻画不同时空场景下用户的兴趣。
总结一下多业务建模相关的工作:
多业务配额模型(MQM):建模目标是召回方式与业务种类的叉乘,后面引入了Transformer做序列建模,最后还引入了人工经验和历史统计信息进行优化,保证多业务融合的效果;
多业务精排建模(MBN):经历了五个版本的迭代,从独立子网络的拆分,到子网络权重自学习,再到引入MMoE进行子网络特征自适应,演进至使用CGC进行多业务特征表达的优化,最后再将模型升级为多业务概率图建模,设计了先验网络和后验网络,引入了概率图模型更好地优化多目标效果。
聚合建模:我们通过多目标联合建模来同时预估聚块大小和聚块位置,其次item维度的行为序列和聚块维度的行为序列差异很大,我们使用异构双序列建模的方法来解决这个问题。
03
排序优化总结
下面总结一下美团搜索在排序中的探索工作:
业务:不同的公司或者不同的场景面临的问题不一样,所以对业务的理解非常重要。有了业务理解才会根据数据、特征、模型这一条线路进行持续探索与迭代。
数据:数据能力是核心的技术能力,是整个上层应用优化的基石。这包括了在线实验能力、数据分析能力、数据平台能力等。
架构:优秀的架构可以极大地提升算法迭代的效率。分层和分类是问题抽象的关键。粗排、精排、重排和异构混排的分层架构,让问题在各层上得到抽象和聚焦解决。有时我们面对的业务很复杂,但再复杂的业务也可以通过一些标准进行分类。比如美团的业务虽然有几百种,但通过分类可以归为商品和商家这两类。此外,工程与算法的协同也同样重要。我前面也介绍了美团搭建了一些平台来有效地支持算法进行快速迭代。另外,我们针对全链路优化做了很多工作,比如粗排、精排的联合优化,站在全链路的视角更好地对性能和效果进行权衡。
系统:搜索是一个系统工程,查询理解、召回排序、知识图谱、多模态理解等需要彼此协同共进。
下面列出了本次分享中涉及到的内容更加详细的材料,大家如果想了解更多细节,可以细读查阅。同时欢迎大家关注美团技术博客的微信公众号“美团技术团队”,互相学习交流。
美团搜索排序团队致力于打造一流的搜索排序平台,欢迎有搜广推经验的工程或者算法方向的同学加入我们,帮大家吃得更好,生活更好。
简历可投至:chensheng19@meituan.com

04
精彩问答
Q:DQU中意图理解和query消歧使用了哪些模型?
A:在查询理解(DQU)中我们包含了多个模块,包括意图识别、查询改写、NER、实体链接等。DQU中最大的迭代是在18年引入了BERT模型,因为BERT在NLP中使用大规模预训练的范式能够很好地适应下游的任务,所以我们使用BERT对DQU的模块进行了一次大升级。如果想要深入了解DQU的细节,可以关注美团技术博客中有关DQU的分享。
Q:如何设定每个子网络的特有任务特征?模型中先验知识是如何引入的?
A:例如使用MMoE时,我们会定义五个子网络,那下面也对应了五个专家网络。模型的损失函数除了采用用户线上反馈计算的主 LambdaLoss 外,额外添加了业务的分类交叉熵 Loss,达到预测某业务 Item 得分时,其对应的业务子塔权重最大的目的。比如当一个样本的品类是美食品类时,美食子网络的权重在最后的输出时最大,对应业务子网络训练得更充分。通过这种目标为导向,我们可以使每一个子网络尽量学习到独有的特征。不同于MMoE单纯使用多路门控自适应地组合多路特征,在使用CGC时我们考虑到有一些特征其实是和某一路子网络强相关的,那么这类特征就被输入到自己业务独有的专家网络中去。通过这一做法,我们引入了人工先验,对特征做了有效的隔离,使得子网络接收到的信息更加纯粹,能更好地表征子业务的高阶语义信息。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

- END -





















 1322
1322

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









