






标题:Recommender Systems with Generative Retrieval
地址:https://arxiv.org/pdf/2305.05065.pdf
会议:NeurIPS 2023
学校:威斯康星大学,谷歌
1.导读
现代推荐系统主要是通过在同一空间中构建查询emb和item的emb,然后通过大规模检索,在给定查询emb的情况下进行近似近邻搜索以选择最佳item。本文提出了一种新的生成检索方法Transformer Index for GEnerative Recommenders (TIGER) ,其中检索模型对目标item的标识符进行自回归解码。为此,作者构建了具有语义意义的码字(codeword)元组,作为每个item的语义ID。给定用户会话中item的语义ID,训练基于Transformer的seq-to-seq模型来预测用户将与之交互的下一个item的语义标识。
2.方法
本文提出的TIGER主要分为两步:
以内容特征生成语义ID:将item内容特征编码为emb向量,并将emb量化为语义码字的元组。由此产生的码字元组被称为item的语义ID
在语义ID上训练通用的推荐系统:构建transformer模型在语义id上训练用于序列推荐的模型
2.1 语义ID生成
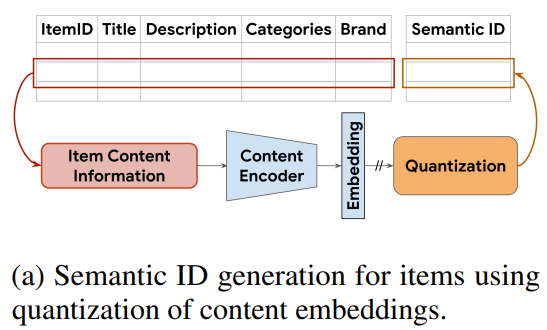 假设每个item都有相关的内容特征,这些特征捕捉有用的语义信息(例如标题或描述或图像)。采用预训练的内容编码器来生成语义emb,比如采用BERT,转换item的文本特征,以获得语义emb。然后对语义emb进行量化,以生成每个item的语义ID,如图a所示。
假设每个item都有相关的内容特征,这些特征捕捉有用的语义信息(例如标题或描述或图像)。采用预训练的内容编码器来生成语义emb,比如采用BERT,转换item的文本特征,以获得语义emb。然后对语义emb进行量化,以生成每个item的语义ID,如图a所示。
将语义ID为长度为m的码字元组。元组中的每个码字都来自不同的码本。语义ID可以唯一表示的item的数量,因此码本大小的乘积等于item集合的大小。虽然生成语义ID的不同技术导致ID具有不同的语义属性,但它们得有以下属性:相似的item(具有相似内容特征或语义emb紧密的item)应该具有重叠的语义ID。例如,与语义ID为(10,23,32)的item相比,具有语义ID(10,21,35)的item应该更类似于具有语义ID的项目(10,21,40)。即相似的item的语义ID重叠度应该较高。
2.1.1 RQ-VAE生成语义ID
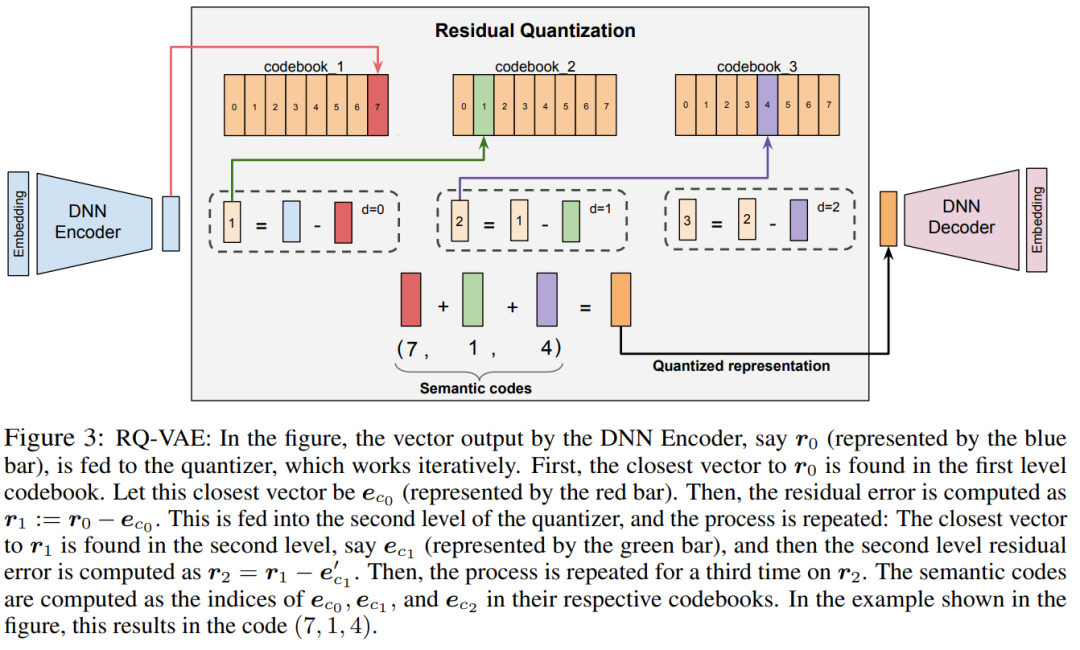 残差量化变分自动编码器(RQ-VAE)是一种多级向量量化器,在残差上进行量化来生成码字元组(语义ID)。通过更新量化码本和DNN编码器-解码器参数来联合训练自动编码器。具体流程如上面图3所示。
残差量化变分自动编码器(RQ-VAE)是一种多级向量量化器,在残差上进行量化来生成码字元组(语义ID)。通过更新量化码本和DNN编码器-解码器参数来联合训练自动编码器。具体流程如上面图3所示。
RQ-VAE首先经由编码器对输入x进行编码学习潜在表征。在第零级(d=0),初始残差被简单地定义为。
在每个层级d,有一个码本,其中K是码本大小。然后,通过将映射到该级别的码本中最近的emb来量化。在d=0处最接近的嵌入的索引(),表示第0个码字。对于下一个级别d=1,残差定义为。然后,类似于第零级,通过找到最接近的第一级的码本中的emb来计算第一级的码字。
该过程递归地重复m次,以获得表示语义ID的m个码字的元组。这种递归方法从粗粒度到细粒度来近似输入。注意,选择为m个级别中的每一个级别使用大小为K的单独码本,而不是使用单个m*K大小的码本。这样做是因为残差的范数往往随着层级的增加而降低,因此允许不同水平的不同粒度。
得到了语义ID后,就可以得到z的量化表征。然后将传给解码器,解码器尝试使用重新创建输入x。RQ-VAE损失为
是解码器的输出,sg表示停止梯度运算(stop gradient)。共同训练编码器、解码器和码本。
为了防止RQ-VAE发生码本崩溃(大多数输入仅映射到少数码本向量),使用k均值聚类来初始化码本,将k-means算法应用于第一个训练批次(first training batch),并使用质心作为初始化。当然除了使用RQ-VAE,也可以使用其他的向量化方法,如LSH等
2.1.2 处理碰撞
碰撞就是发生语义冲突了,多个item映射到同一个码字上了。为了消除冲突,本文在有序语义码字的末尾添加了一个额外的标记,以使它们具有唯一性。例如,如果两个项目共享语义ID(12,24,52),附加额外的令牌来区分它们,将这两个项目表示为(12,24,52,0)和(12,24,52,1)。为了检测冲突,需要维护一个将语义ID映射到相应item的查找表。
2.1.3 通过语义ID进行生成式检索
按时间顺序对每个用户交互过的item进行排序,构建item序列。给定序列,推荐系统预测下一个。令表示的长度为m的语义ID。然后将item序列转换为序列。训练seq-to-seq模型来预测的语义ID。
3.结果
 不同量化方法对比
不同量化方法对比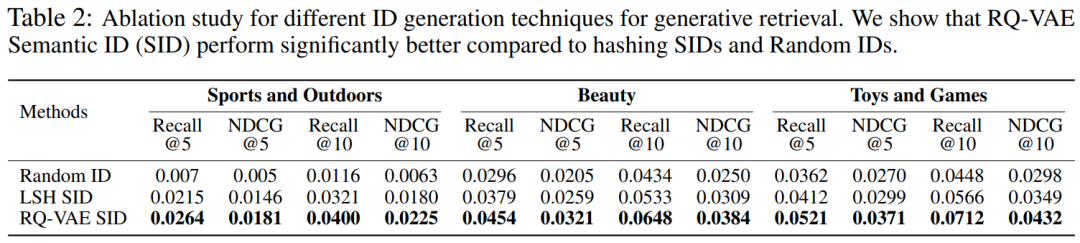
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)



















 931
931

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









