







选取了论文中对生成式检索技术的介绍,利用工具进行总结概括🤯
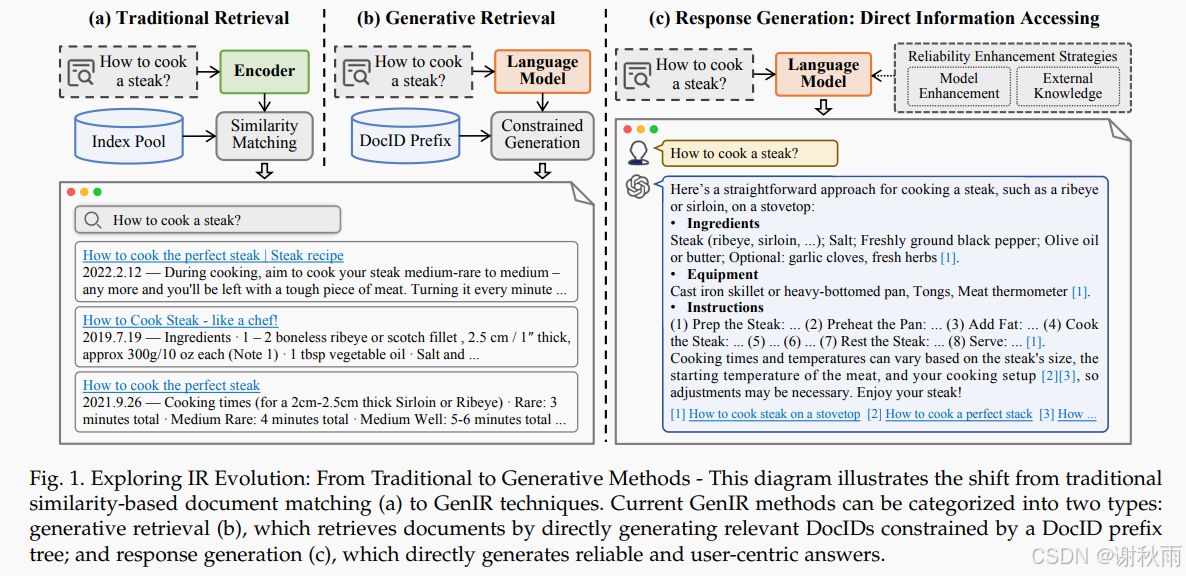
生成式检索(GR):基于生成模型的检索方法,它不仅仅是检索相关信息,还可以生成新的内容以满足用户需求。在这种方法中,模型会根据用户的查询生成准确且个性化的答案,而不仅仅是从现有文档中找到匹配的内容。生成检索的核心是利用生成式模型(如GPT系列)来构建回答,尤其适用于用户不清楚如何表达查询或寻求复杂的、个性化的信息时。
前置知识——LLM介绍
最初,LLMs基于统计学和神经网络的语言模型,通过在大规模文本语料库上进行预训练,学习了语言的深层语义特征,大大提高了文本理解能力。生成式语言模型,特别是GPT系列,通过模型规模和参数数量的增加,显著提升了文本生成和理解的能力。
LLMs主要分为两类:编码器-解码器模型和仅解码器模型。编码器-解码器模型(如T5和BART)将输入文本转化为向量表示,通过解码器基于这些表示生成输出文本,处理NLP任务时将其视为文本到文本的转换问题。而仅解码器模型(如GPT和GPT-2)仅依赖Transformer解码器,通过自注意力机制一步步生成文本。GPT-3的推出,拥有1750亿个参数,是这一领域的重要里程碑,之后还涌现了InstructGPT、Falcon、PaLM和LLaMA等模型。
在信息检索领域,LLMs主要采用两种策略:上下文学习(ICL)和参数高效微调。ICL利用预训练模型中的知识,通过提供一系列相关示例和任务描述,帮助模型快速适应新任务,无需额外训练,具有高度灵活性和成本效益。而参数高效微调(如LoRA、PEFT、QLoRA等)则通过调整模型中少量参数来适应特定任务,避免重新训练整个模型,显著减少计算资源的需求,同时保持性能。
通过这些策略,LLMs在查询重写、文档检索、结果重排序、文档阅读理解和基于代理的搜索机制等信息检索任务中展现了出色的潜力。LLMs的应用不仅限于提高搜索结果的相关性,还能直接生成用户所需的准确信息,这标志着生成式信息检索新时代的到来。在这一时代,检索过程不仅仅是定位现有信息,还包括生成符合用户特定需求的新内容,尤其在用户不清楚如何表达查询或寻求复杂个性化信息时,比传统的匹配方法更具优势。
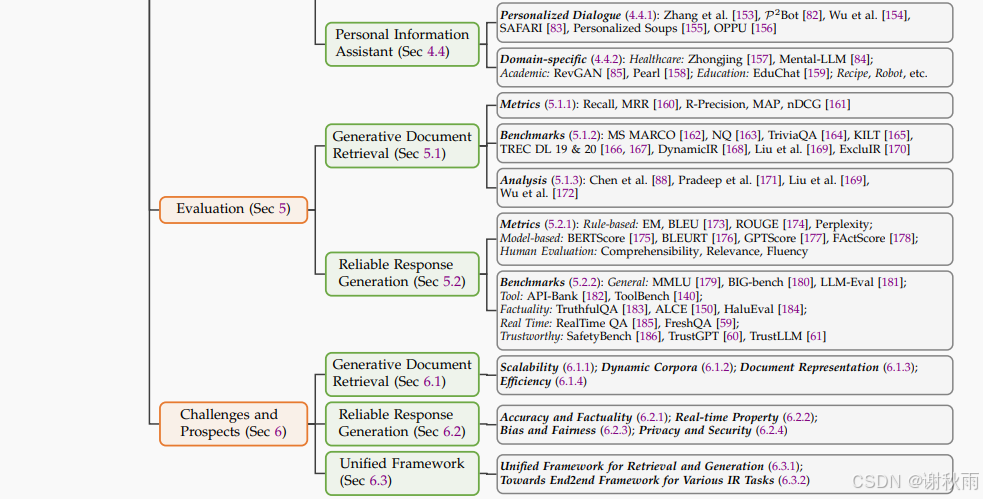
思维导图
好伟大的一篇工作😯
生成式检索方法
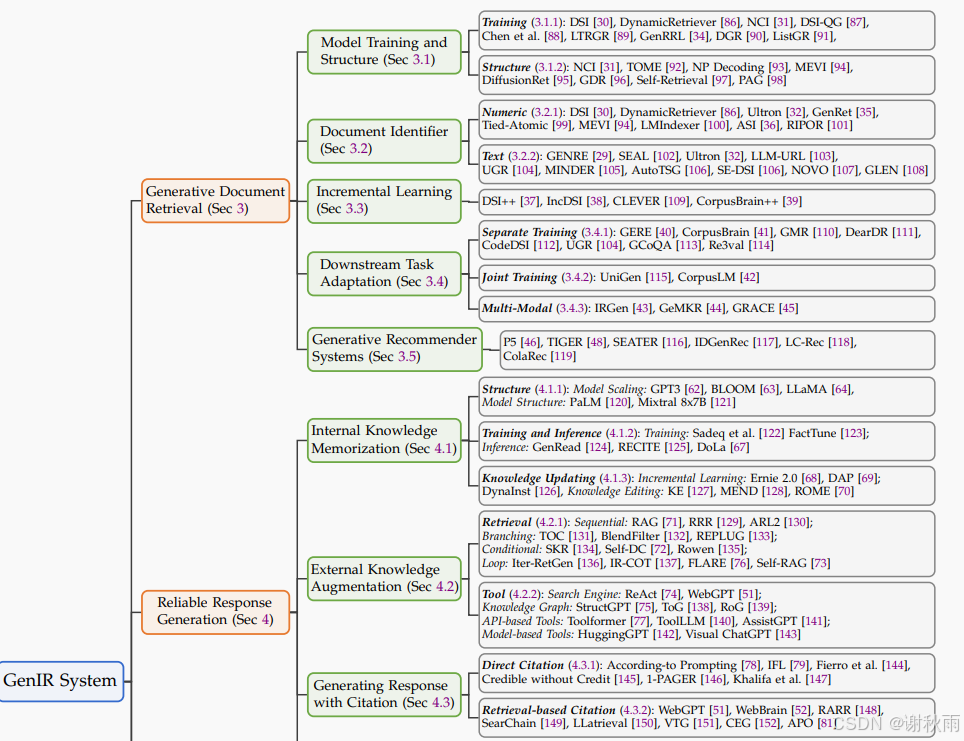
3.1 模型训练与结构
3.1.1 模型训练
在生成检索(GR)中,模型训练的核心目标是提升模型将文档与对应的文档标识符(DocID)关联的能力。常见的训练方法是通过序列到序列(seq2seq)方法将查询映射到相关的DocID。为了进一步提高检索性能,研究者提出了多种训练策略,如:
- 数据增强:例如通过采样文档片段或从文档内容生成伪查询,扩充训练数据。
- 索引与检索策略:如DSI模型提出的“索引”(将文档令牌与DocID关联)和“检索”(通过标注的查询-DocID对进行微调)方法。
- 提升排序能力:通过多任务蒸馏、强化学习或从高级排序模型蒸馏来改善GR模型的排序能力。
3.1.2 模型结构
生成检索模型通常采用像T5或BART这样的编码器-解码器架构,并进行DocID生成任务的微调。为了更好地适应GR任务,研究者提出了多种定制的模型结构,如:
- 解码方法:如Prefix-Aware Weight-Adaptive(PAWA)解码器和NP-Decoding方法,用于处理DocID的层次语义结构和扩展模型容量。
- 结合生成与密集检索:像MEVI和生成密集检索(GDR)方法结合生成模型与密集检索模型,提升召回率和检索效率。
- 多模型方法:一些模型如TOME和DiffusionRet,将GR任务分解为多个阶段,通过生成文本或URL来提高检索精度,或使用扩散模型生成文档。
3.2 文档标识符(DocID)的设计
3.2.1 数值型标识符
数值型DocID通过数字表示文档,可以是静态的或可学习的:
- 静态DocID:如DSI模型最初提出的三种静态DocID类型:原子DocID(随机分配唯一整数)、简单结构化字符串DocID(将整数当作可分割的字符串)和语义结构化DocID(通过层次聚类方法将语义相似的文档归为相似前缀)。
- 可学习DocID:如GenRet模型提出的可学习文档表示,通过离散自编码器生成短的DocID,并通过最小化重构误差进行训练,优化模型性能。
3.2.2 文本型标识符
文本型DocID利用文档内容的强语义能力,具有较好的可解释性。常见的文本型标识符包括:
- 文档标题:例如GENRE模型通过使用文档标题作为DocID,结合BART生成模型,在KILT数据集上取得了较好性能。
- 文档子字符串:如SEAL模型采用N-gram子字符串作为DocID,通过FM-Index进行索引检索。
- 关键词集:例如AutoTSG提出的基于关键词集的文档表示,通过生成有效的DocID进行检索。
此外,文本型DocID也可以是可学习的,如NOVO和GLEN提出的基于关键词和动态词汇的DocID,通过自监督学习和排序优化提升检索精度。
3.3 基于动态语料库的增量学习
随着动态语料库中文档的不断更新和扩展,研究者提出了一系列方法优化生成式检索(GR)模型以适应这种动态环境。以下是主要研究方法的总结:
1. 优化器与文档复习
- DSI++:为解决动态语料库的增量学习挑战,DSI++ 使用 Sharpness-Aware Minimization (SAM) 优化器,通过优化“平坦损失盆地”稳定模型学习过程。同时引入生成式记忆,利用 DocT5Query 生成伪查询以增强训练数据,缓解模型遗忘问题。
2. 约束优化
- IncDSI:将新文档的实时添加视为约束优化问题,目标是:(1)确保新文档能被相关查询正确检索;(2)维持现有文档的检索性能不受影响。IncDSI 实现了每个文档大约 20-50 毫秒的增量更新,大幅减少重新训练的计算成本,同时保持竞争力的检索性能。
3. 增量产品量化
- CLEVER:基于产品量化 (PQ) 提出增量产品量化 (IPQ),通过设计自适应阈值,仅更新部分质心,减少计算成本。IPQ 利用动态内存库存储与新增文档相似的样本文档,从而增强模型记忆。
4. 任务特定的微调适配器
- CorpusBrain++:引入 KILT++ 基准和动态架构,使用骨干-适配器结构。通过固定共享骨干模型提供基本检索能力,并为特定任务的新增文档增量学习设计适配器,避免灾难性遗忘。此外,CorpusBrain++ 通过基于语义相似性的文档聚类和重训练策略维护旧文档的记忆。
这些方法为动态语料库中生成式检索模型的增量学习提供了多样化的解决方案,分别在优化器设计、增量更新效率、记忆机制以及任务适配方面取得了重要进展。
3.4 下游任务自适应
生成式检索(Generative Retrieval, GR)方法不仅用于单一的检索任务,还被扩展应用于多种下游生成任务,包括事实验证、实体链接、开放域问答、对话、槽位填充、知识密集型任务、代码检索、会话问答以及多模态检索场景。主要方法分为以下三类:
3.4.1 单独训练
- 事实验证:GERE 使用编码器-解码器结构代替传统索引方法,依次对输入声明进行编码、生成相关文档标题并生成证据句标识,显著提升了性能和效率。
- 知识密集型任务:
- CorpusBrain 提出三种预训练任务(如超链接识别)以增强模型的检索能力。
- UGR 使用多粒度 N-gram DocIDs,将检索任务统一为生成式框架,通过学习任务特定提示生成文档标识。
- DearDR 通过远程和自监督学习实现零样本任务能力,进一步优化性能。
- Re3val 结合生成式重排序和强化学习,优化页面标题排序与上下文选择,提升信息检索准确性。
- 多跳检索:GMR 使用语言模型记忆和多跳记忆,通过伪造多跳查询数据模拟
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









