






大家好,这里是 NewBeeNLP。今天分享WWW 2024上的6篇与大模型相关的工业界搜广推工作。本次主要对文章做简要介绍和梳理,后续再详细分享。
后台留言『交流』,加入NewBee讨论组
阿里:淘宝搜索大模型应用于长尾搜索词改写
Large Language Model based Long-tail Query Rewriting in Taobao Search
Wenjun Peng, Guiyang Li, Yue Jiang, Zilong Wang, Dan Ou, Xiaoyi Zeng, Derong Xu, Tong Xu and Enhong Chen
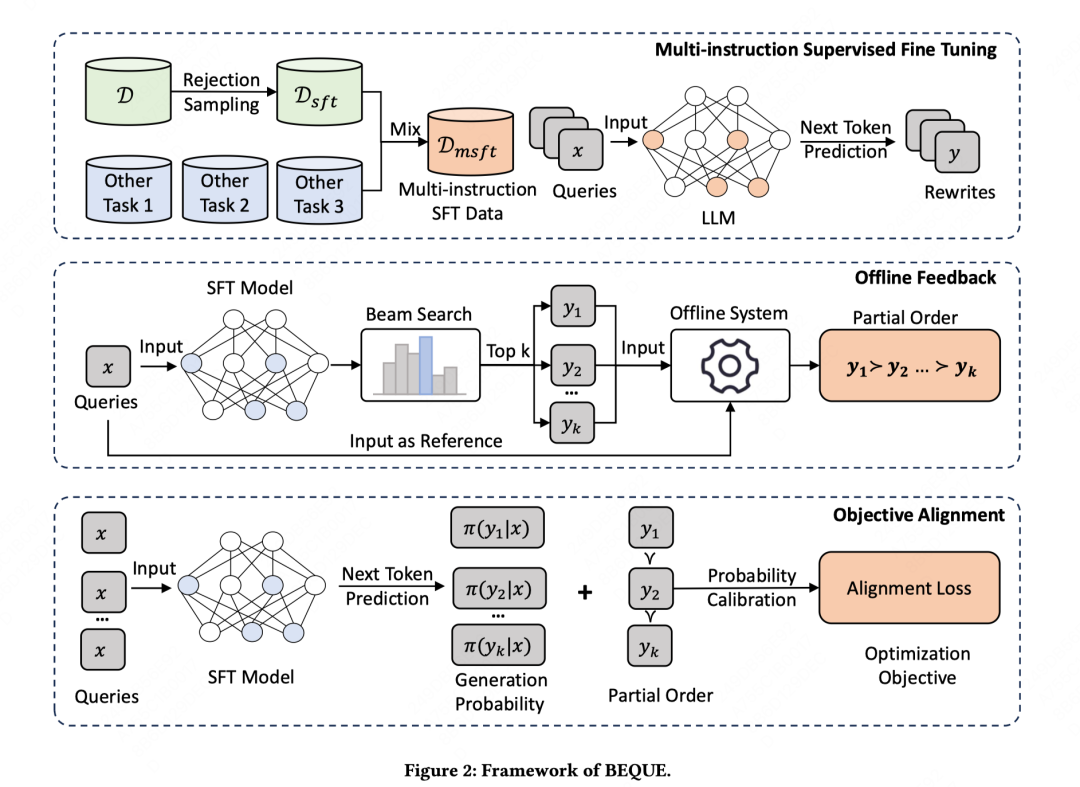
在电商搜索领域,语义匹配的重要性不言而喻,因为它直接影响用户体验和公司收入。沿着这个方向,查询改写作为一种重要的技术,用于弥补语义匹配过程中固有的语义差距,引起了行业和学术界的广泛关注。然而,现有的查询改写方法往往难以有效地优化长尾搜索,很容易由于语义差距导致“低召回”现象。本文提出了一种全面的框架BEQUE,用于弥合长尾搜索的语义差距。具体而言,BEQUE由三个阶段组成:多指令监督微调(SFT)、离线反馈和目标对齐。作者首先基于拒绝抽样和辅助任务混合构建一个改写数据集,以有监督的方式微调大语言模型(LLM)。随后,利用经过良好训练的LLM,作者使用beam search生成多个候选改写,并将它们输入到淘宝的离线系统中获取部分排序。利用改写的部分排序,作者引入对比学习方法来凸显改写之间的差异,并将模型与淘宝的在线目标对齐。离线实验证明了本文方法在弥补语义差距方面的有效性。在线A/B测试显示,本文提出的方法可以显著提高长尾查询的GMV、交易量、和访客数。BEQUE自2023年10月起已在淘宝上部署。
整体框架如下:
微软:基于知识增强大模型的个性化上下文搜索建议
Knowledge-Augmented Large Language Models for Personalized Contextual Query Suggestion
Jinheon Baek, Nirupama Chandrasekaran, Silviu Cucerzan, Allen Herring, Sujay Kumar Jauhar
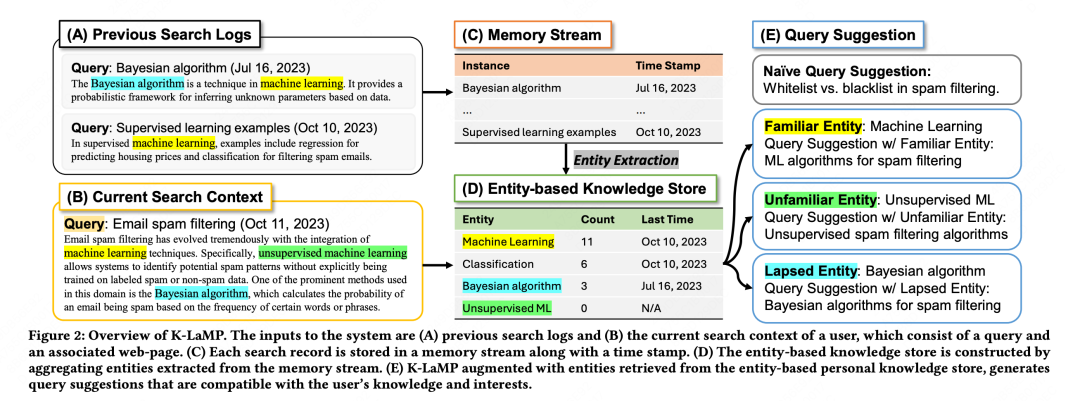
本文提出了一种基于用户与搜索引擎的互动历史的上下文信息,对大语言模型(LLM)进行个性化输出的方法。由于重新训练或微调LLM的成本较高,LLM通常是静态的且难以个性化。然而,很多应用都可以从个性化生成中获益,因为了解用户的偏好、目标和知识可以提升搜索体验。为此,提出了一种新颖的通用方法,通过用户在搜索引擎上的互动历史,为LLM提供相关上下文信息,以个性化输出。具体而言,根据用户在网络上的搜索和浏览活动,构建了一个以实体为中心的用户知识存储,然后利用该知识存储提供上下文相关的LLM提示增强。这个知识存储是轻量级的,因为它只将用户的兴趣和知识在公共知识图上进行聚合投影,利用现有的搜索日志基础设施,从而缓解了个人化建立深度用户档案所涉及的隐私、合规性和可扩展性问题。研究通过人工评估的一系列实验证实了这种方法在上下文查询建议任务上的有效性,该任务要求不仅理解用户的当前查询上下文,还要了解他们历史上知道和关心的内容。实验结果表明,相比于其他基于LLM的基准模型,这种方法生成的查询建议在上下文相关性、个性化程度和实用性方面更好。
阿里:建模用户浏览流的文章推荐系统
Modeling User Viewing Flow using Large Language Models for Article Recommendation
Zhenghao Liu, Zulong Chen, Moufeng Zhang, Shaoyang Duan, Hong Wen, Liangyue Li, Nan Li, Yu Gu and Ge Yu
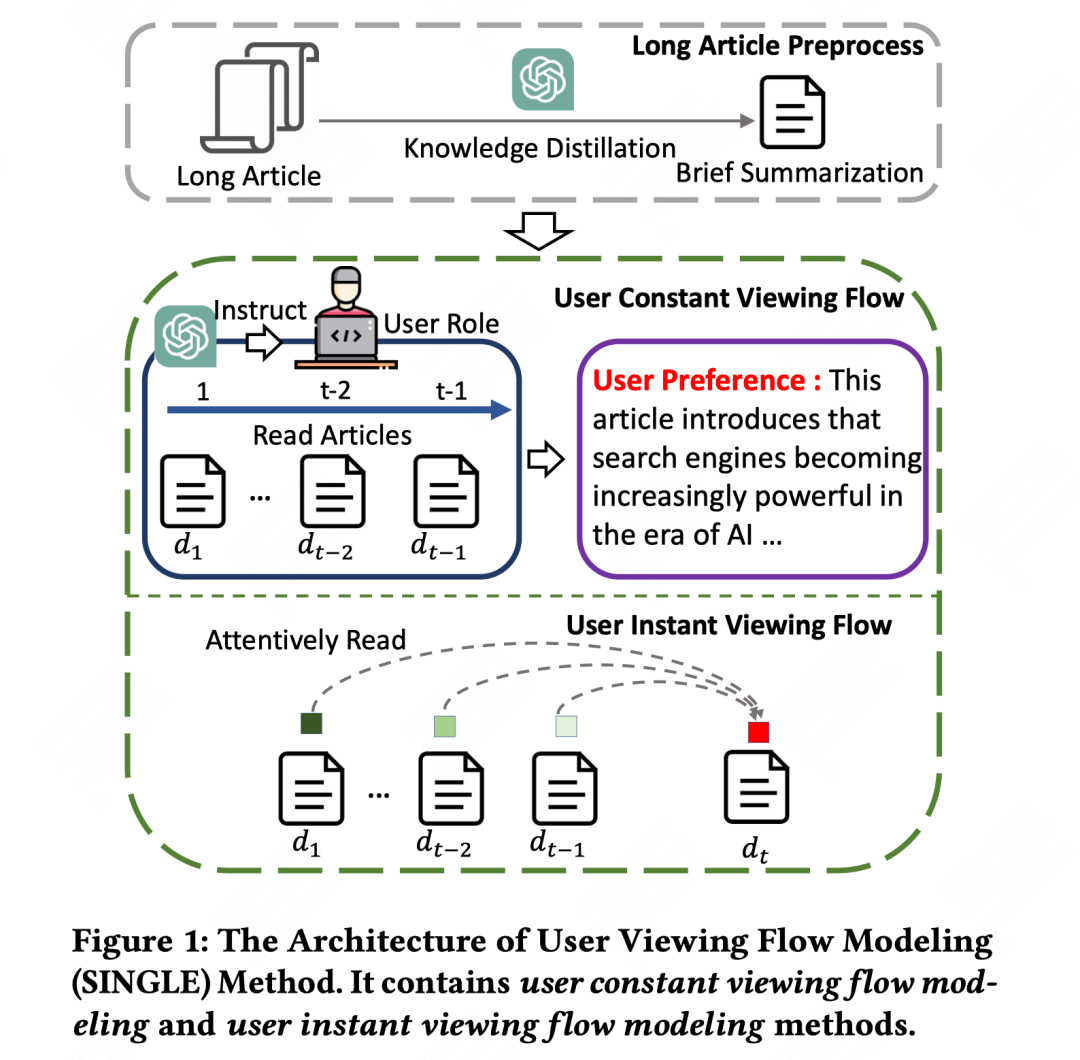
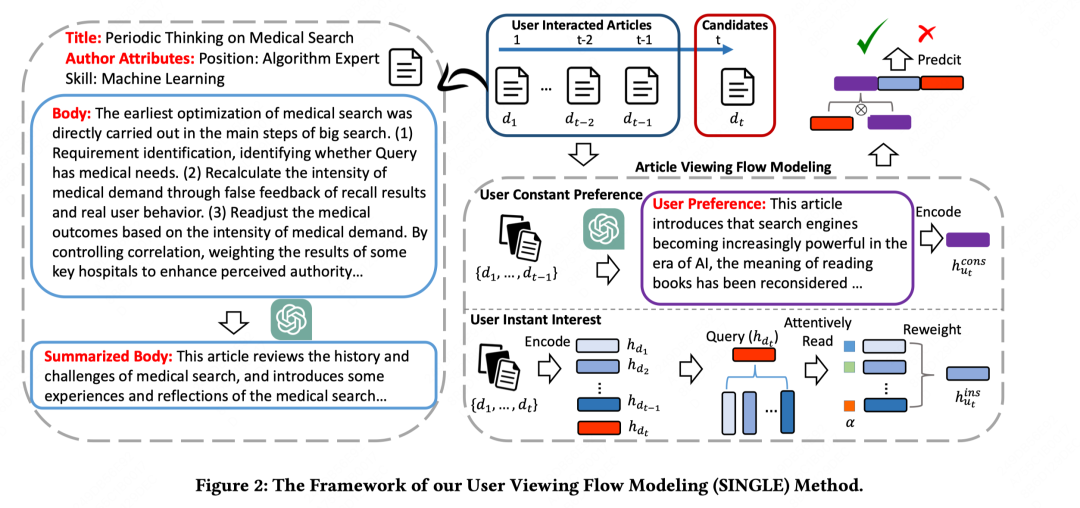
本文提出了一种用于文章推荐任务的用户浏览流建模(SINGLE)方法,该方法对用户点击的文章建模了用户的持续偏好和即时兴趣。具体而言,作者采用了用户“静态浏览流建模”方法(user constant viewing flow modeling),总结用户的通用兴趣,以便进行文章推荐。作者利用大语言模型(LLMs)从先前点击的文章中捕捉用户的持续偏好,如skills和positions。然后,作者设计了用户即时浏览流建模方法(user instant viewing flow modeling),建立用户点击文章历史与候选文章之间的交互。它会自适应地关注用户点击文章的表示,旨在学习用户的不同兴趣视角,以匹配候选文章。作者在阿里ATA上的实验结果显示SINGLE的优势,在线A/B测试中相对于之前的基准模型取得了2.4%的改进。进一步的分析表明,SINGLE能够通过模拟用户的不同文章观看行为建立更加个性化的推荐系统,并推荐更适合和多样化的文章来匹配用户的兴趣。
LinkedIn:大模型协同过滤推荐
Collaborative Large Language Model for Recommender Systems
Yaochen Zhu, Liang Wu, Qi Guo, Liangjie Hong, Jundong Li
最近,前沿研究中关于基于大模型(LLM)开发下一代推荐系统(RSs)的兴趣正在增长。然而,自然语言和推荐任务之间的语义差距仍然没有得到很好的解决,导致了多个问题,比如虚假相关的用户/物品描述符,对用户/物品数据的无效语言建模,通过自回归实现的推荐效率低等等。在这篇论文中,作者提出了CLLM4Rec,这是第一个紧密集成了LLM范式和RS范式的生成式推荐系统,旨在同时解决上述挑战。作者首先通过使用用户/物品ID标记扩展预训练LLM的词汇表,来准确地建模用户/物品的协作和内容语义。相应地,作者提出了一种新颖的软+硬提示策略,通过在RS特定语料库上进行语言建模,有效地学习用户/物品的协作/内容tokens嵌入,其中每个文档被分为一个提示和一个主要文本,提示由异构的soft(用户/物品)tokens和hard(词汇)tokens组成,主要文本由同构的item tokens令牌或vocab tokens组成,以促进稳定和有效的语言建模。此外,作者引入了一种新颖的双向正则化策略,鼓励CLLM4Rec从嘈杂的用户/物品内容中捕捉与推荐相关的信息。最后,作者为CLLM4Rec提出了一种新颖的推荐优化调整策略,将具有多项式似然的物品预测头添加到预训练的CLLM4Rec骨干中,以基于从屏蔽的用户-物品交互历史建立的软+硬提示来预测保留物品,可以高效地生成多个物品的推荐,避免产生虚假信息。
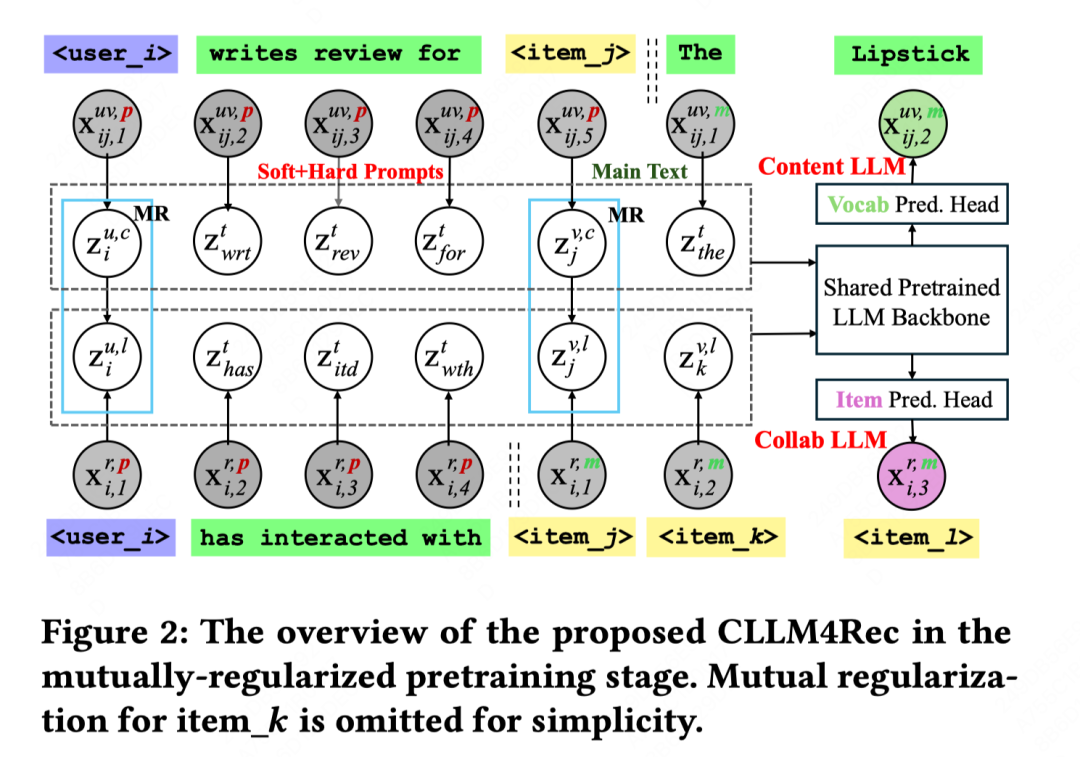
百度:基于大模型的推荐系统表征学习
Representation Learning with Large Language Models for Recommendation
Xubin Ren, Wei Wei, Lianghao Xia, Lixin Su, Suqi Cheng, Junfeng Wang, Dawei Yin, Chao Huang
推荐系统在深度学习和图神经网络的影响下取得了显著进展,特别是在捕捉复杂的用户-物品关系方面。然而,这些基于图的推荐系统在很大程度上依赖于基于ID的数据,可能忽视了与用户和物品相关的有价值的文本信息,导致学习到的表示不够丰富。此外,隐式反馈数据的利用引入了潜在的噪声和偏差,对用户偏好学习的有效性带来了挑战。虽然将大型语言模型(LLMs)集成到传统的基于ID的推荐系统中引起了关注,但在实际推荐系统中实施时需要解决可扩展性问题、仅仅依赖文本的限制以及提示输入约束等挑战。为了应对这些挑战,作者提出了一个模型无关的框架RLMRec,旨在通过LLM增强现有的推荐系统的表示学习。它提出了一种集成表示学习和LLMs的推荐范式,以捕捉用户行为和偏好的复杂语义方面。RLMRec整合了辅助文本信号,利用LLMs进行用户/物品特征建模,并通过交叉视图对齐将LLM的语义空间与协同关系信号对齐。这项工作进一步证明了通过最大化互信息来整合文本信号的理论基础,从而提高了表示的质量。作者的评估将RLMRec与最先进的推荐模型结合起来,并分析其在噪声数据下的效率和鲁棒性。
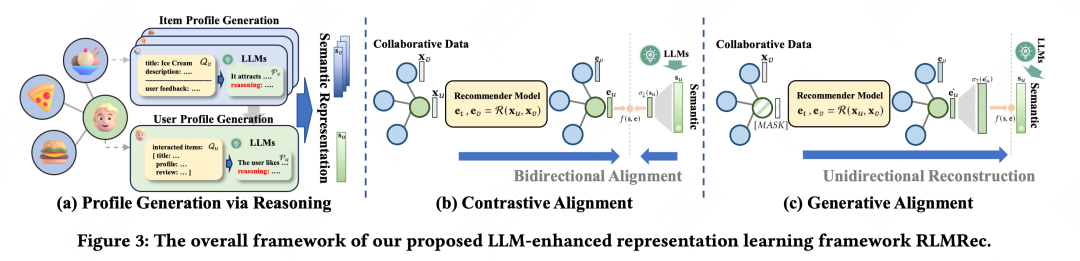
华为:基于检索增强大语言模型的推荐系统用户全生命周期序列行为理解
ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation
Jianghao Lin, Rong Shan, Chenxu Zhu, Kounianhua Du, Bo Chen, Shigang Quan, Ruiming Tang, Yong Yu, Weinan Zhang
这篇论文主要关注如何通过使用大型语言模型(LLMs)来增强推荐系统,并解决LLMs在推荐领域中的零样本和少样本推荐任务中遇到的问题。
首先,作者指出了LLMs在推荐领域中存在的一个问题,即无法从用户行为序列的文本上下文中提取有用的信息,即使上下文的长度远未达到LLMs的上下文限制。为了解决这个问题并提高LLMs的推荐性能,作者提出了一种新的框架——Retrieval-enhanced Large Language models(ReLLa),用于零样本和少样本推荐任务。
对于零样本推荐,作者使用语义用户行为检索(SUBR)来改善测试样本的数据质量,从而大大降低了LLMs从用户行为序列中提取重要知识的难度。对于少样本推荐,作者进一步设计了基于检索增强指导调优(ReiT),通过采用SUBR作为训练样本的数据增强技术。具体而言,作者开发了一个混合训练数据集,包括原始数据样本和通过检索增强处理的样本。作者在三个真实世界公开数据集上进行了大量实验证明了ReLLa相对于现有基线模型的优越性,以及其对于生命周期顺序行为理解的能力。值得一提的是,少样本ReLLa仅使用不到10%的训练样本,就能胜过使用整个训练集训练的传统点击率(CTR)模型,如DCNv2、DIN和SIM。
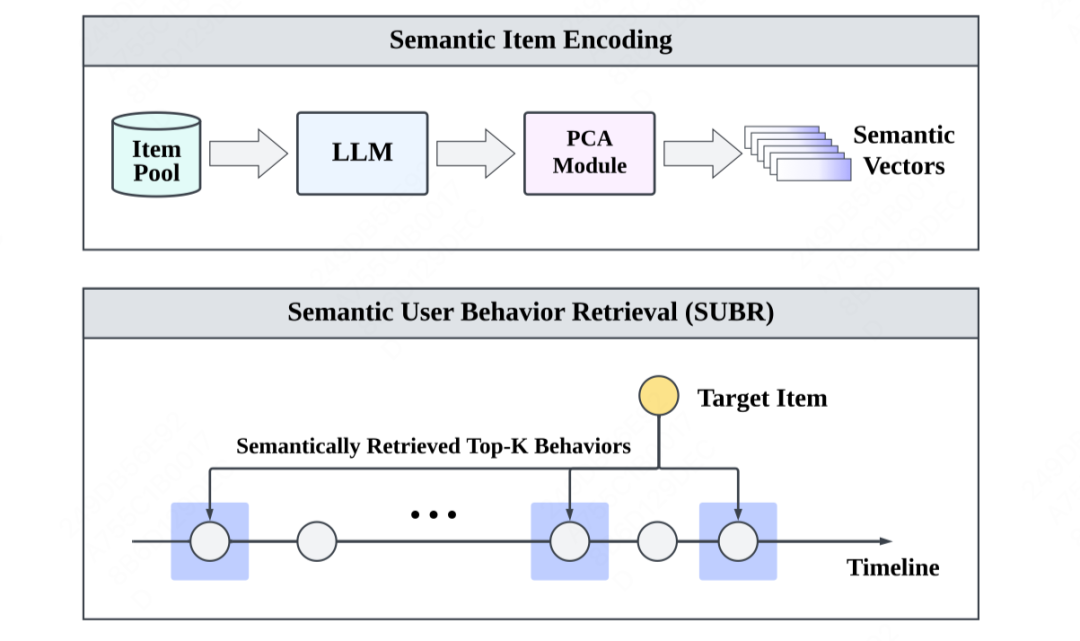
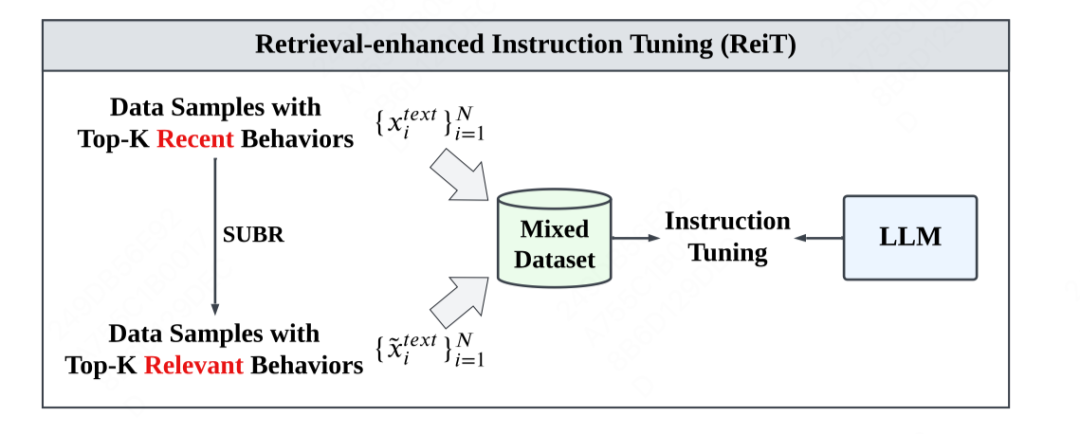
WWW'24其他大模型相关搜广推工作
CTR预估 | ClickPrompt: CTR Models are Strong Prompt Generators for Adapting Language Models to CTR Prediction
检索增强 | Search-in-the-Chain: Interactively Enhancing Large Language Models with Search for Knowledge-intensive Tasks
Shicheng Xu, Liang Pang, Huawei Shen, Xueqi Cheng, Tat-Seng Chua
序列推荐/语义表征 | Enhancing sequential recommendation via LLM-based semantic embedding learning
Jun Hu, Wenwen Xia, Xiaolu Zhang, Chilin Fu, Weichang Wu, Zhaoxin Huan, Ang Li, Zuoli Tang and Jun Zhou
笔记推荐 | NoteLLM: A Retrievable Large Language Model for Note Recommendation
Chao Zhang, Shiwei Wu, Haoxin Zhang, Tong Xu, Yan Gao, Yao Hu and Enhong Chen
序列推荐 | Harnessing Large Language Models for Text-Rich Sequential Recommendation
Zhi Zheng, Wen Shuo Chao, Zhaopeng Qiu, Hengshu Zhu, Hui Xiong
时序推理 | Back to the Future: Towards Explainable Temporal Reasoning with Large Language Models
Chenhan Yuan, Qianqian Xie, Jimin Huang, Sophia Ananiadou
NER | LinkNER: Linking Local Named Entity Recognition Models to Large Language Models using Uncertainty
Zhen Zhang, Yuhua Zhao, Hang Gao, Mengting Hu
表征学习 | Labor Space: A Unifying Representation of the Labor Market via Large Language Models
Seongwoon Kim, Yong-Yeol Ahn, Jaehyuk Park
虚假新闻检测 | Explainable Fake News Detection With Large Language Model via Defense Among Competing Wisdom
Bo Wang, Jing Ma, Hongzhan Lin, Zhiwei Yang, Ruichao Yang, Yuan Tian, Yi Chang
检索增强 | Metacognitive Retrieval-Augmented Large Language Models
Yujia Zhou, Zheng Liu, Jiajie Jin, Jian-Yun Nie, Zhicheng Dou
个性化搜索 | Cognitive Personalized Search Integrating Large Language Models with an Efficient Memory Mechanism
Yujia Zhou, Qiannan Zhu, Jiajie Jin, Zhicheng Dou
多模态|PMG : Personalized Multimodal Response Generation with Large Language Models
Xiaoteng Shen, Rui Zhang, Xiaoyan Zhao, Jieming Zhu, Xi Xiao
设计范式 | Mechanism Design for Large Language Models
Paul Duetting, Vahab Mirrokni, Renato Paes Leme, Haifeng Xu, Song Zuo
股票预测 | Learning to Generate Explainable Stock Predictions using Self-Reflective Large Language Models
Kelvin J.L. Koa, Yunshan Ma, Ritchie Ng, Tat-Seng Chua
知识图谱 | Unifying Local and Global Knowledge: Empowering Large Language Models as Political Experts with Knowledge Graphs
Xinyi Mou, Zejun Li, Hanjia Lyu, Jiebo Luo, Zhongyu Wei
大模型评估| KGQuiz: Evaluating the Generalization of Encoded Knowledge in Large Language Models
Yuyang Bai, Shangbin Feng, Vidhisha Balachandran, Zhaoxuan Tan, Shiqi Lou, Tianxing He, Yulia Tsvetkov
健康搜索 | Ask Me in English Instead: Cross-Lingual Evaluation of Large Language Models for Healthcare Queries
Yiqiao Jin, Mohit Chandra, Gaurav Verma, Yibo Hu, Munmun De Choudhury, Srijan Kumar
QA |Harnessing Multi-role Capabilities of Large Language Models for Open-domain Question Answering
Hongda Sun, Yuxuan Liu, Chengwei Wu, Haiyu Yan, Cheng Tai, Xin Gao, Shuo Shang, Rui Yan
图和大模型 |GraphTranslator: Aligning Graph Model to Large Language Model for Open-ended Tasks
Mengmei Zhang, Mingwei Sun, Peng Wang, Shen Fan, Yanhu Mo, Xiaoxiao Xu, Hong Liu, Cheng Yang, Chuan Shi
检索增强 | Query in Your Tongue: Reinforce Large Language Models with Retrievers for Cross-lingual Search Generative Experience
Ping Guo, Yue Hu, Yanan Cao, Yubing Ren, Yunpeng Li, Heyan Huang
总结
搜广推上的大模型应用在2024年预计会有不少工作出现。从目前来看,场景还是比较受限的:
1)适合"文本驱动或文本密集型"推荐场景,如:新闻推荐、文章推荐、对话推荐等。
2)大模型增强的协同过滤、图表征学习等。如:协同表征和语义文本表征的对齐。
3)搜索词、检索相关的搜索场景。如:搜索改写、query suggestion、可微分搜索等。
整体上还没看到非常亮眼的工作:对搜广推经典范式能有撼动、或者在实际应用中能大规模落地的,期待下24年新工作。

















 1254
1254

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









