







来自华为诺亚方舟实验室的王奕超老师今天给我们带来了关于大语言模型在推荐系统中的探索与应用的分享,将从数据、模型和流程三个层面展开,介绍华为在推荐系统领域的两个重要项目,并回答关于用户推理知识构造、特征交叉和在线服务流程的具体问题。通过这些前瞻性的探索和应用,推荐系统的性能和用户体验有望得到显著提升。
主要内容包括以下几大部分:
-
背景和问题
-
LLM4Rec 探索及应用
-
挑战和展望
01
背景和问题
1. 推荐系统
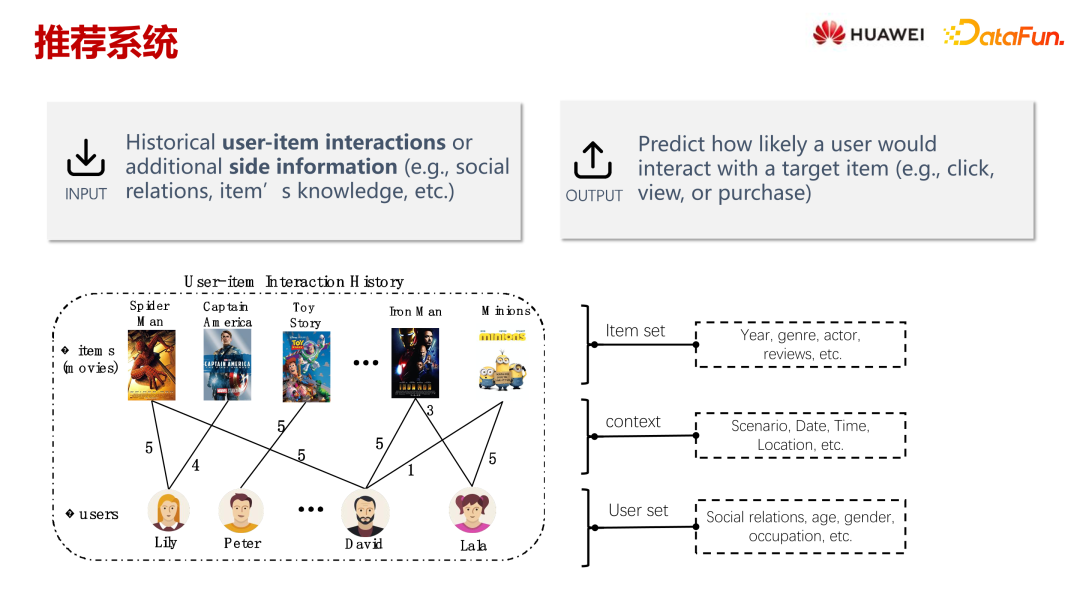
让我们从一个具体例子——电影推荐系统开始。推荐系统的输入主要是用户的交互行为,如点击或观看过的电影。这些行为反映了用户的偏好。除此之外,还有物品的特征信息,比如电影的年代、类别和演员等属性信息,以及用户的一些特征,比如年龄和性别等。推荐系统会根据这些输入信息,结合当前用户请求的一些上下文信息(如电影榜单、时间和地点等),为用户提供评分推荐。
2. 大语言模型
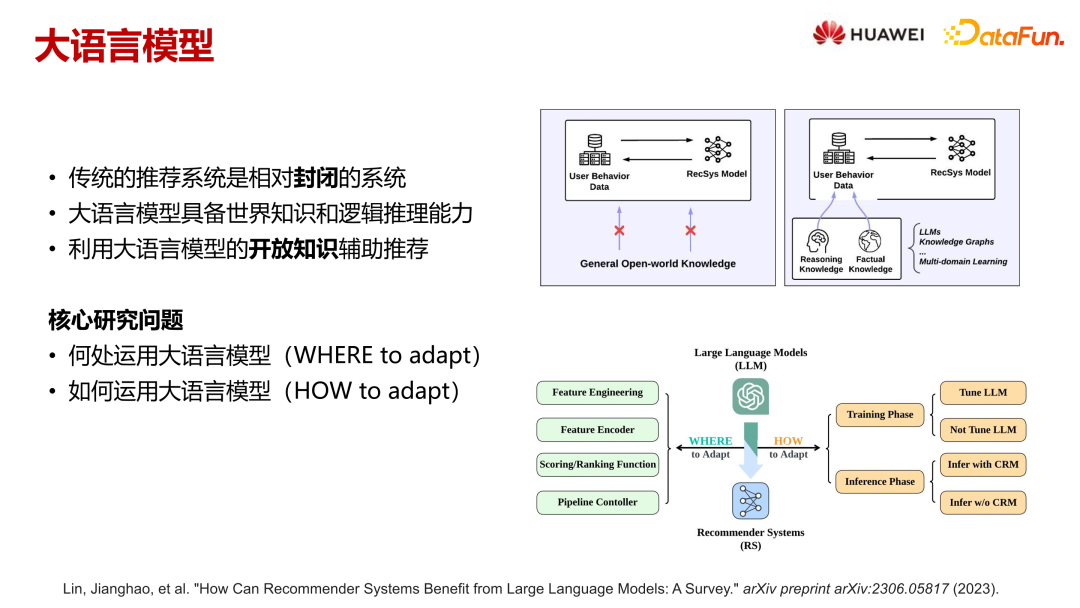
根据前面的介绍,我们可以了解到当前的推荐系统,特别是在电影或电商等领域,往往是一个相对封闭的系统。这类系统通常基于特定应用场景的日志数据进行模型训练,并部署于该场景提供服务,与外界系统交互有限。然而,理想的推荐系统应是一个开放系统,能够与外界进行交互,利用实时、事实的知识信息来提升推荐效果。大语言模型,特别是那些在互联网量级语料中训练出的模型,具备丰富的世界知识和逻辑推理能力,这些能力恰好可以弥补传统推荐系统的不足。它们不仅可以用于补充推荐系统的测试编码、模型打分等功能,还在流程控制等方面展现出巨大的潜力。在运用大语言模型时,我们可以考虑在训练阶段进行微调或固定参数,而在推理阶段,则可以选择仅使用推荐系统或直接将大语言模型作为推荐系统的推理器。这些策略的具体实施将在后续分析中详细展开。
总之,大语言模型为推荐系统的优化提供了新的思路和方法,我们期待在未来的研究和实践中,能够进一步挖掘其潜力,提升推荐系统的性能和用户体验。欢迎大家就相关话题进行阅读、了解和讨论。
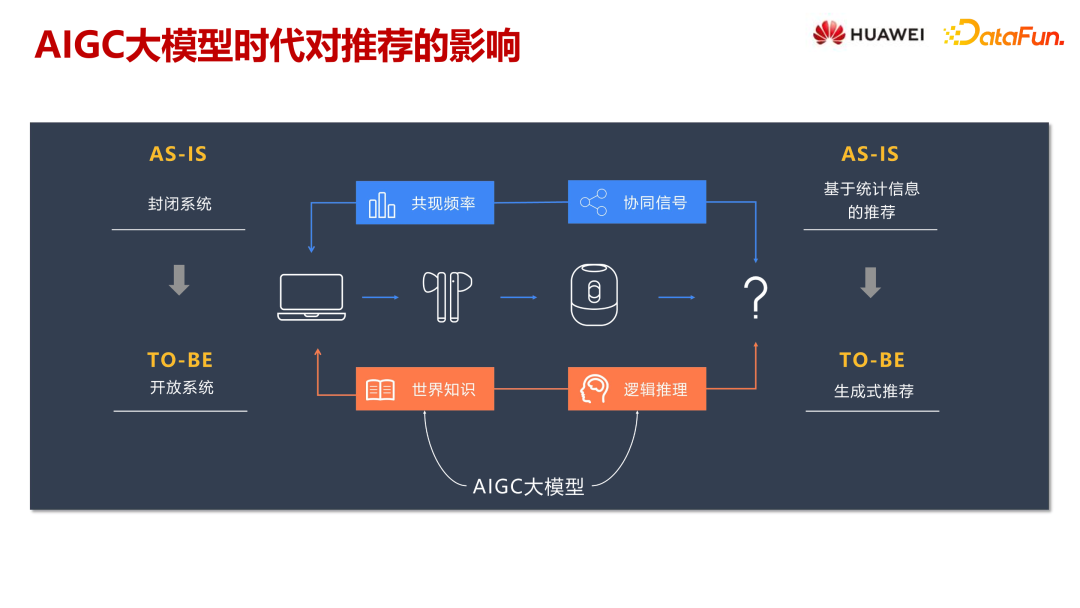
随着大语言模型的引入,推荐系统将逐渐从封闭走向开放,引入丰富的世界知识。当前,推
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









