






 本篇内容涵盖机器学习的基础概念,包括监督学习与强化学习的区别、损失函数的作用、梯度下降法原理及其变种,以及过拟合与欠拟合问题的解决策略。此外,还深入探讨了逻辑回归、卷积神经网络、循环神经网络等模型,并介绍了PyTorch教程及图神经网络的应用。
本篇内容涵盖机器学习的基础概念,包括监督学习与强化学习的区别、损失函数的作用、梯度下降法原理及其变种,以及过拟合与欠拟合问题的解决策略。此外,还深入探讨了逻辑回归、卷积神经网络、循环神经网络等模型,并介绍了PyTorch教程及图神经网络的应用。
我真的超能鸽🕊哈哈哈
在各种方向上来回摇摆,最后还是老老实实找机器学习来听了(B站学习网站石锤了)
https://www.bilibili.com/video/BV1JE411g7XF
看评论还不错,就从这里开始吧!笔芯
机器学习×
宝可梦分享会√
(希望这一部分能在圣诞节前写完)
希望破灭,果然还是不能随便立flag
-----------------------------------------------------------------------------------------------
P1-P19
P1 Machine Learning (2020)_Course Introduction
大概内容:
1. 作业的内容和选择
2. 机器学习就是让机器自己找函数
3. 函数的Loss(损失函数)用来评价函数的好坏
4. Supervised Learning(告诉机器) V.S. Reinforcement Learning(让机器自己悟)
5. 机器怎么找出我们想要什么函数
6. RNN 循环神经网络, VNN 卷积神经网络
7. 机器学习前沿研究 Explainable AI & Adversarial Attack etc.
课程网页:

P2 Rule of ML 2020
助教介绍交作业的方法和注意事项
P3 Regression - Case Study
举例:预测宝可梦的CP值(老师老二刺螈了hhhhh)
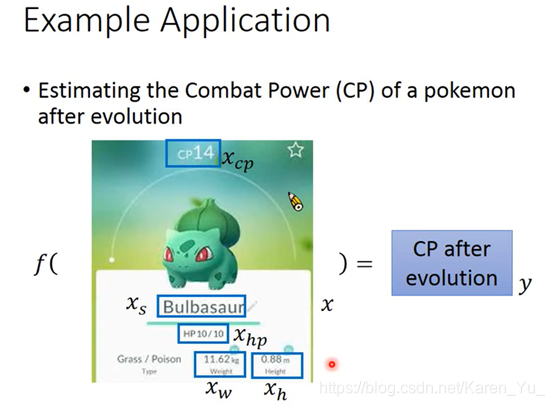
需要做什么呢?找model,评价model,找一个最好的model

x:进化前的CP值
y:进化后的CP值
w b:参数

(老师语)用上标表示一个完整的object的编号,用下标表示一个完整的object的component。进化之后的CP值,y one hat,y代表输出,上标代表完整的个体,hat表示是一个完整的整体(不是一个component)
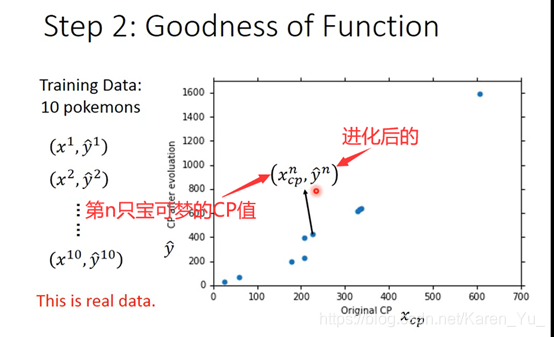

定义另一个函数,来判断函数的好坏
Loss是函数的函数(禁止套娃)
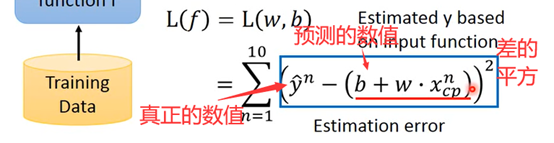
L(f)=L(w,b) 其实衡量函数的好坏也相当于是参数的好坏
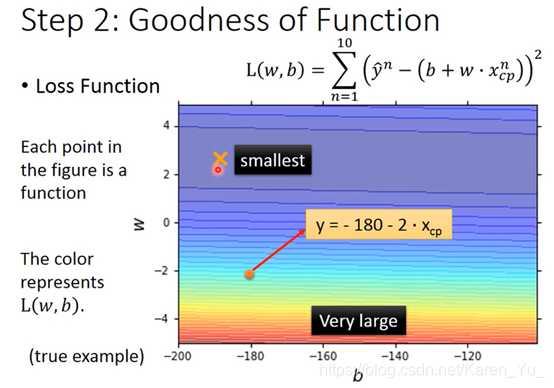
越红越不好,越蓝越好(有弹幕说颜色相当于给加上了一个Z轴)

(搬弹幕)arg min f(x):当f(x)取最小值时,x的取值
arg=argument <数,逻>自变数
(老师语)Gradient Descent 只要L是可微分的,都可以拿来找比较好的参数
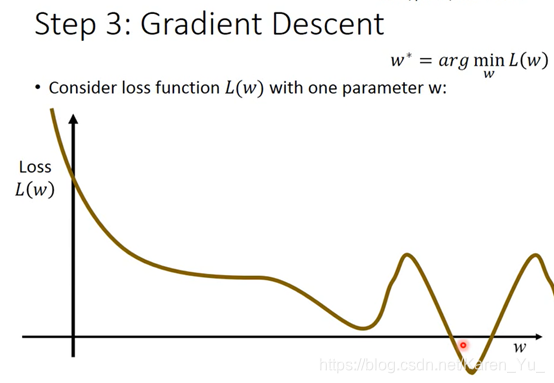
最简单的方法就是穷举所有w的值,就可以找到能让L最小的w的值,但是效率不高
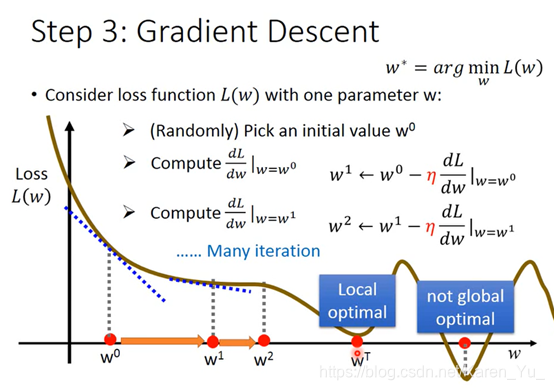
首先,随机选取一个初始的点(当然也有其他方法帮助找一个更好的点)
接着,计算在w=w0的位置,w对L的微分,i.e.切线斜率。当切线斜率是负数,说明w0左边Loss比较高,右边Loss比较低,要想得到比较好的Loss,就应该右移(增加w的值),vise versa。
向左/右走多少事可以计算的(取决于微分值,陡峭嘛&learning rate)
重复上述操作
……
……
到达局部最优(Local optimal)但是未必事not global optimal

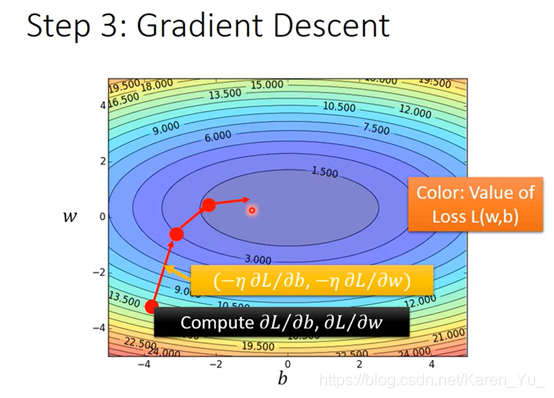
两个参数与一个参数的操作类似,选取w0和b0
计算w=w0,b=b0时,w b对L的偏微分
计算得到w1 b1
重复操作
▽L(找不到符号了,凑合意思意思):把w对L的偏微分和b对L的偏微分排成一个向量
但是gradient descent 也有问题
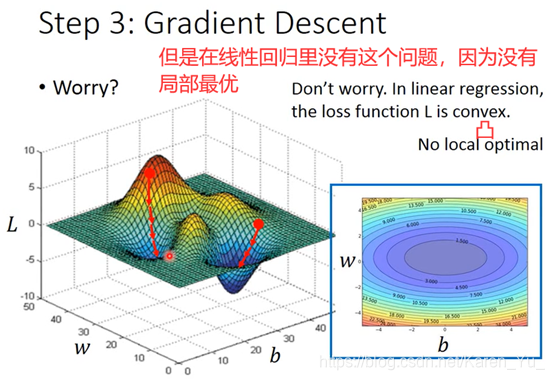
存在局部最优解可能比较拼人品(像我这种非酋估计还是不要尝试×)

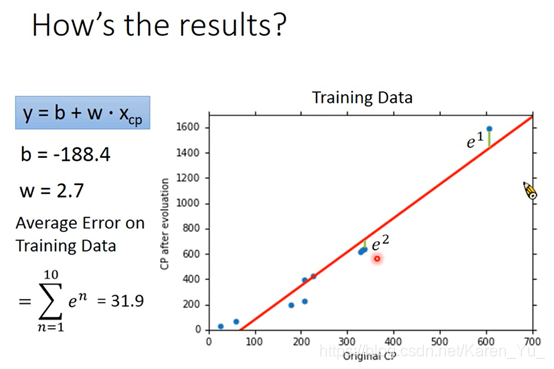
可以计算error(蓝色点和红色线的距离)
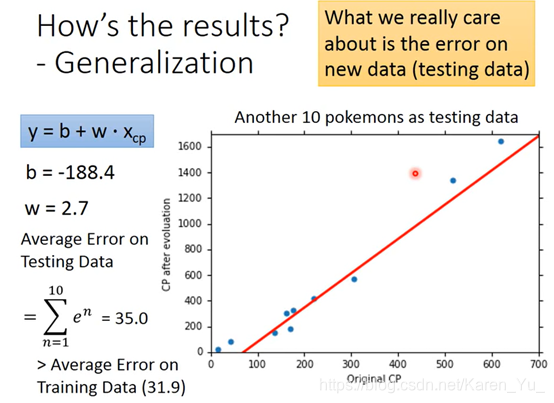
我们关注的不是函数对于训练数据的匹配问题,而是新的数据的匹配程度
那么如果想要做得更好呢?
很简单,换一个model就好了
-->引入二次项
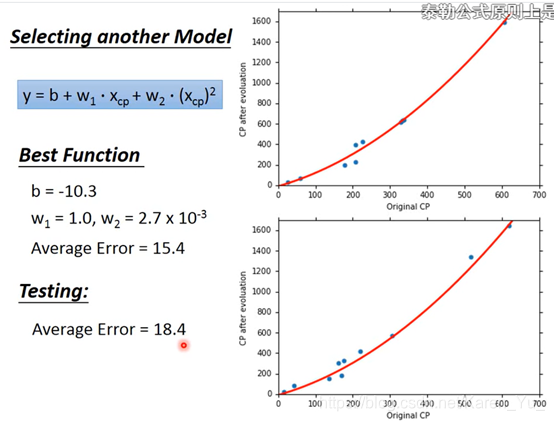
明显相比一次函数比配更好
当然引入三次项也完全OK
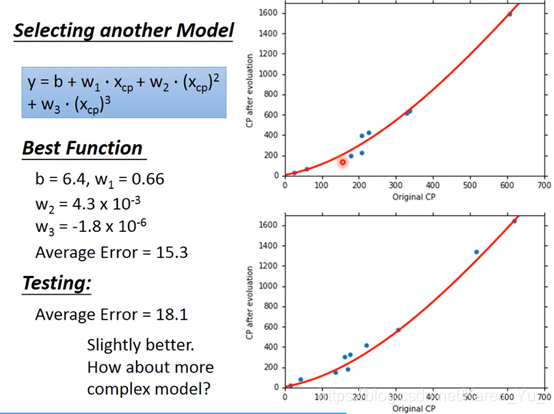
可以看到三次相比二次稍微好一点,但是并没有差距很大
要注意我们更关注的是新数据的匹配程度
当引入四次项时:
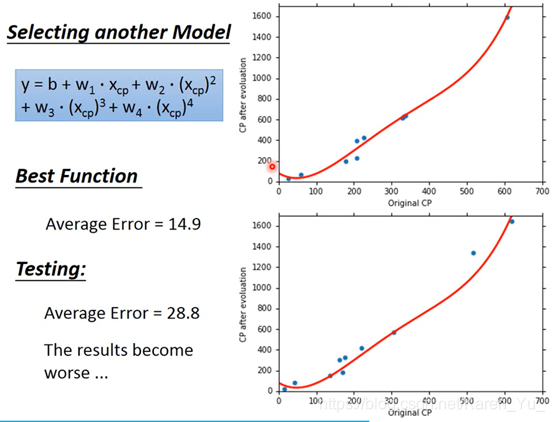
可以看到原始数据匹配度提升了,但是新数据反而匹配度下降了
当使用更高的次项,更复杂的时候,引入五次项
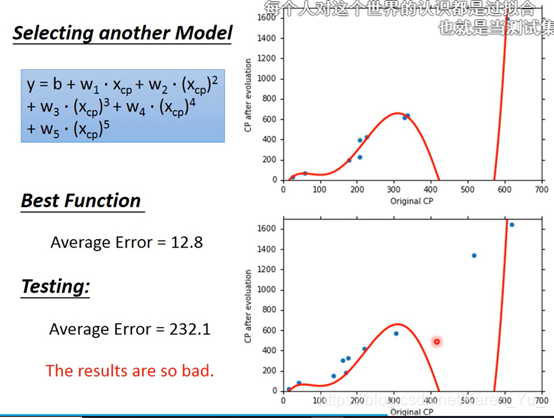
结果并没有变好(弹幕说时过拟合?龙格现象?)
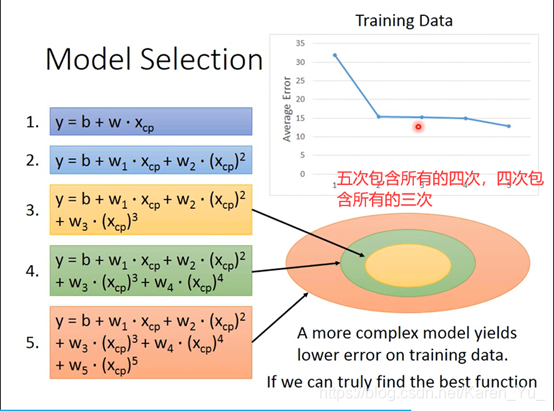
在training data上,可以看到越来越好

但是在testing data上并没有那么好-->复杂的模型并不一定拟合就更好
实锤这叫过拟合
看新的数据看出来之前全白忙活了……

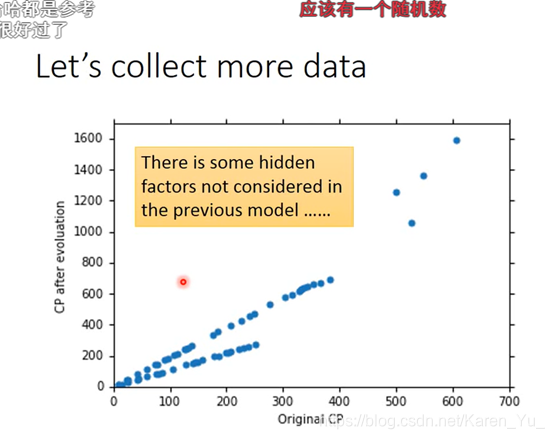
指出不同的物种模型不同
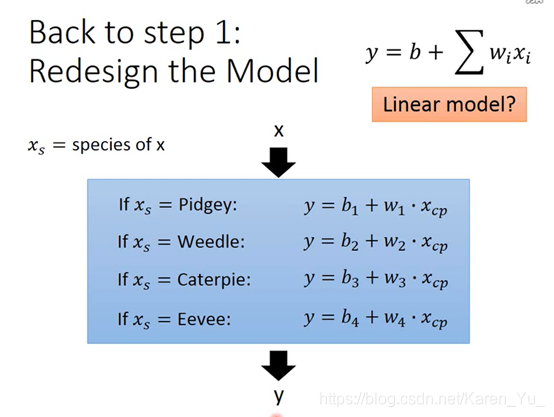
得到每个物种自己的参数,为了处理这个问题,似乎用的时冲激函数?

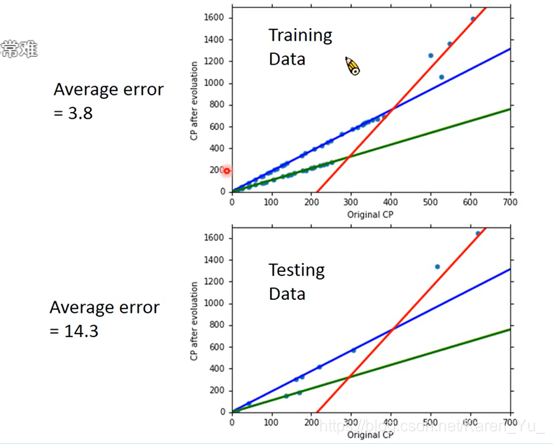
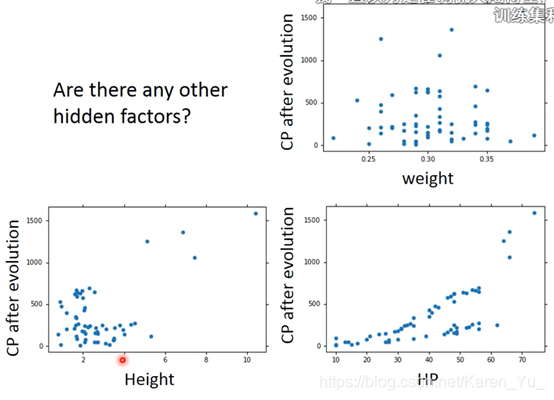
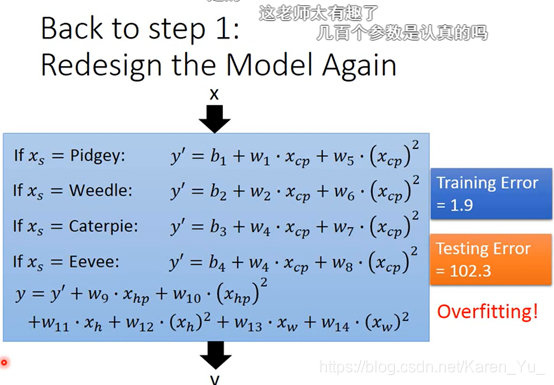
会overfitting

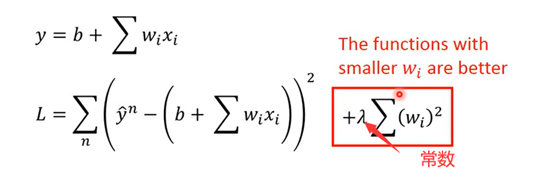
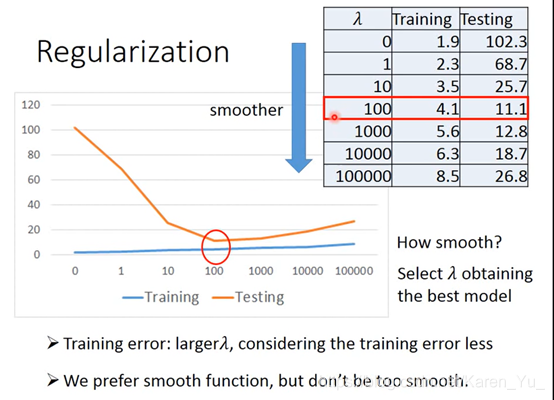
λ值越大,相对而言training data的error就会越大,但是在testing data那里的error又可能表现更好。
虽然λ↑会更平滑,但是并不一定越大越好,需要手动调参
本次课堂总结(宝可梦进化分享会×)

P4 Basic Concept
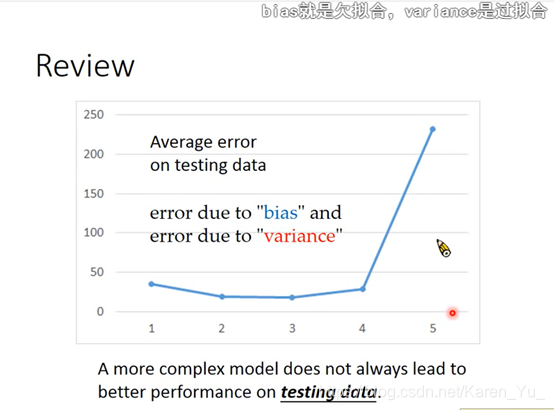
回顾:
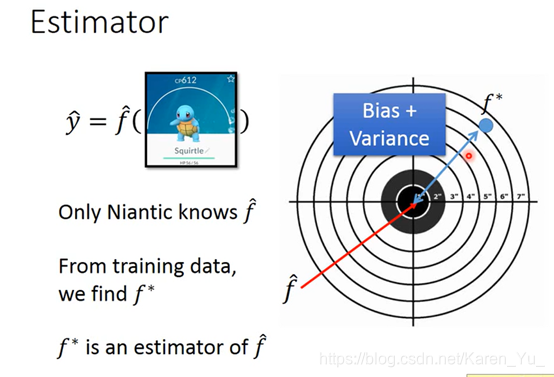
f hat 是理论上最佳匹配的函数,但是我们不知道具体的f hat 是什么,所以模拟出来的最好的函数f star最好能更接近f hat

Bias 偏差 Variance 方差
弹幕提出这个是无偏估计(概率论完全不记得了,面壁)
在知乎上看到有关问题的讨论https://www.zhihu.com/question/22983179
目前默认排序第一的回答和老师课堂上说的内容比较类似,可以参考理解一下

算出来m(对N个点取平均值)之后再求m和N个点差的平方(和正经求方差方法一致)(感觉是不是可以理解成用局部的特点描述整体?)

下面这个图老师PPT里不清楚,幸好知乎有
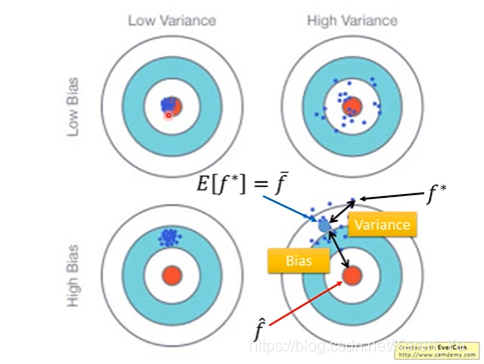
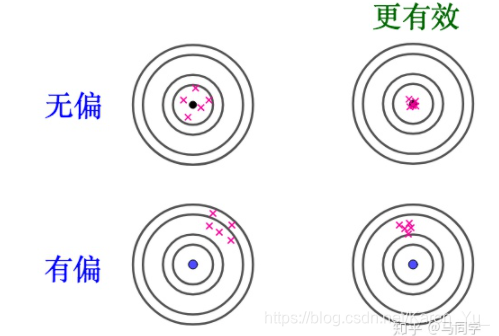
对照着看
f hat 是估测的目标,找出来的f star->f star 的期望值 f bar,f bar 和f hat之间是有误差的。同时f star 和f bar之间也有误差(希望射到靶子上对某个位置,但是并不一定能射到这个位置)
->误差来源于:1.瞄准的位置在哪里 2.射击的准确度怎么样(是不是能射到瞄准的点)

假设有不同的宇宙,那么在不同的宇宙中抓到的宝可梦也是不一样的

比如在123号宇宙中抓到的宝可梦符合的f star就和在345号宇宙中抓到的宝可梦的f star不一样(遇事不决,平行宇宙哈哈哈,仿佛在看瑞克与莫蒂)
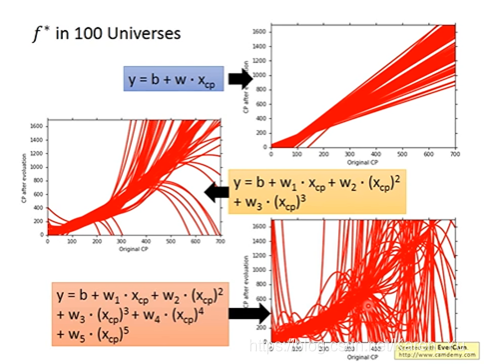
然后我们在一百个平行宇宙中各抓十个宝可梦(好家伙,真好抓),分别找每个平行宇宙的f star,然后全部画出来(如上图)
就会发现,一切皆有可能×
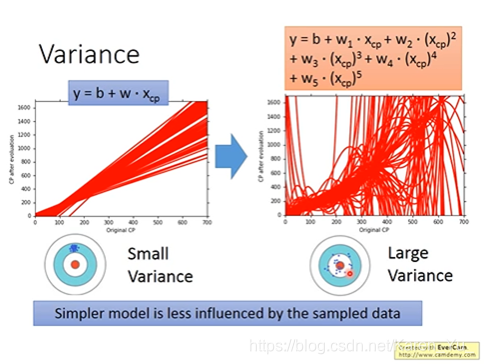
如果是简单model,variance就比较小,如果是比较复杂的model,散布就很开
因为比较简单的model受data的影响就相对很小
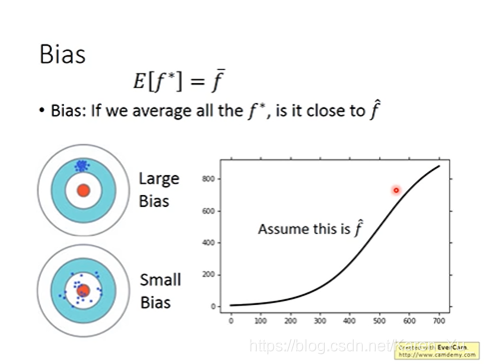
Bias:找 f star 的期望值->f bar ,f bar 与靶心 的距离是Bias(虽然可能很分散,但是平均值接近靶心)
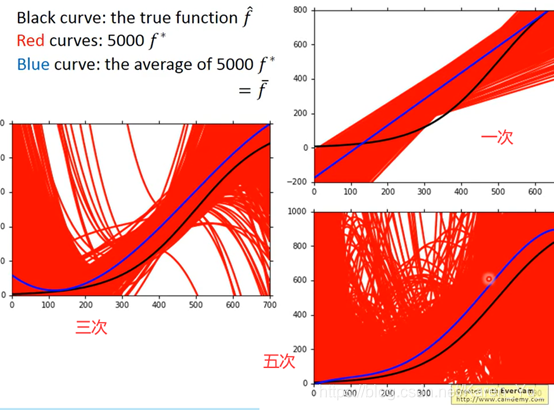
黑色的线,f hat真正的靶心的位置
红色的线:做的5000次实验得到的f star
蓝色的线:5000次实验的平均值 f bar
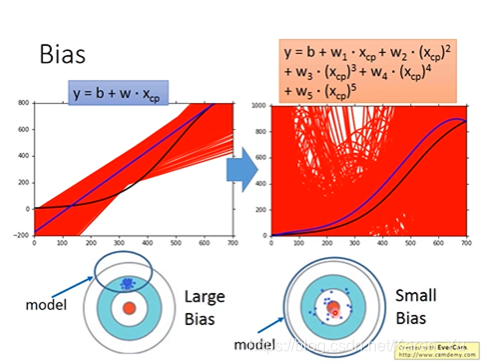
如果是一个比较简单的model,就有一个比较大的Bias,虽然复杂的model会造成每次的f star差距很大(分散),但是平均值在靶心附近
每一个model就相当于一个function set,用一个范围表示function set(见蓝色的圈),但是在这个简单的model中的set中无论是怎么找,也不包括target。
因此:
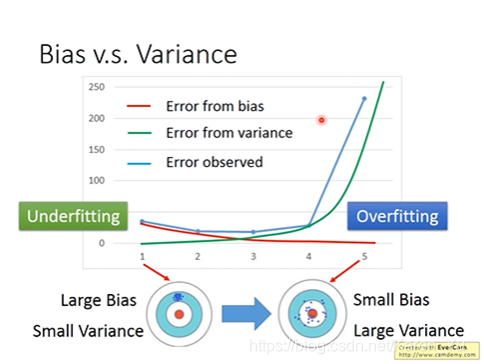
如果error来自狂野的分散,就是过拟合,如果error来自于即使数值接近也和目标相距十万八千里,就是欠拟合

怎么知道模型如何改进(Bias大还是Variance大?)↑
Bias大就要重新设计model,可能需要更复杂的,考虑更多的影响因素
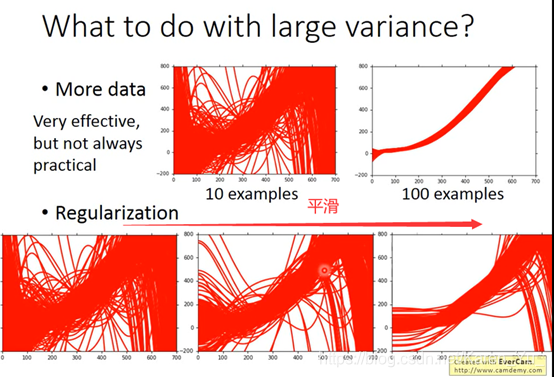
Variance大,就需要收集更多的数据,没有那么多数据可以自己做一些奇怪的操作(没有条件也要创造条件)
但是这种情况下可能会影响Bias

拿自己手上的testing set去测试model中最好的一个可能在真实的testing set测试下效果并不是最好的
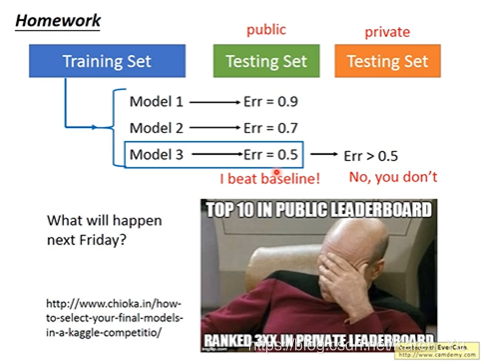
可能测试的时候觉得OK,但是别人拿来用的时候会有BUG
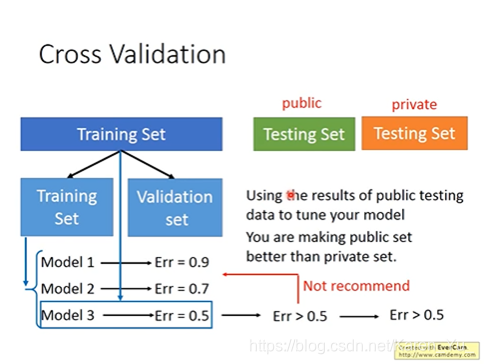
提出可以把training data分成两组,不建议在test的时候遇到问题的时候返回去改,因为最后的testing data是我们没有的,即使特别符合我们手上的testing data也不代表在之后的测试中也OK
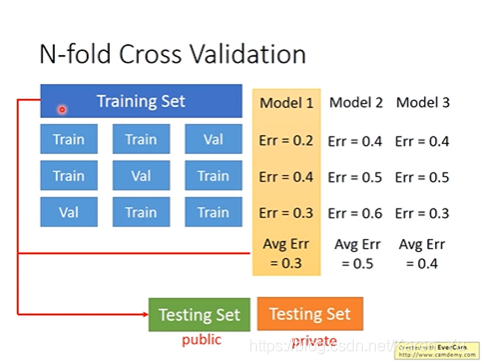
不放心的话,反复套娃验证也可以
P5 Gradient Descent_1
回顾:

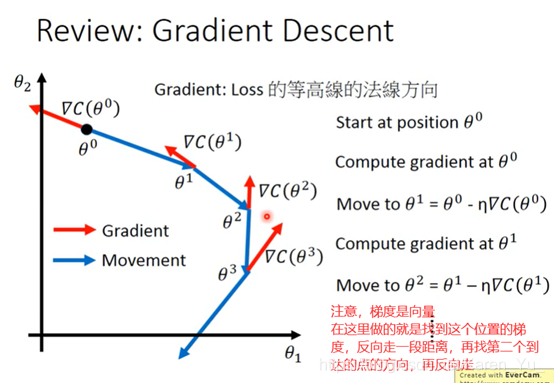
搬弹幕:
梯度是上升最快的方向,它的反方向(加上负号)就是下降最快的方向

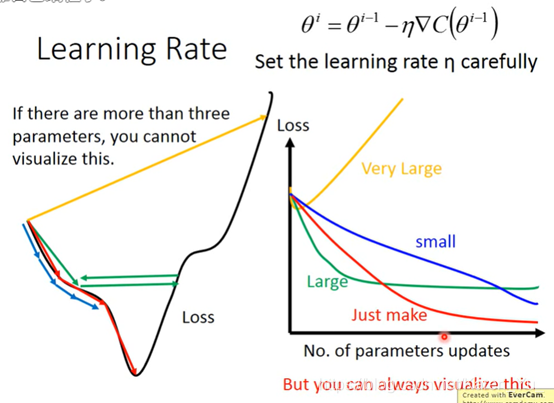
learning rate太小会导致下降速度慢或者也有可能没法走下去,learning rate 大一点可能会卡住,没法下降,如果learning rate太大,就可能跳过最优解。


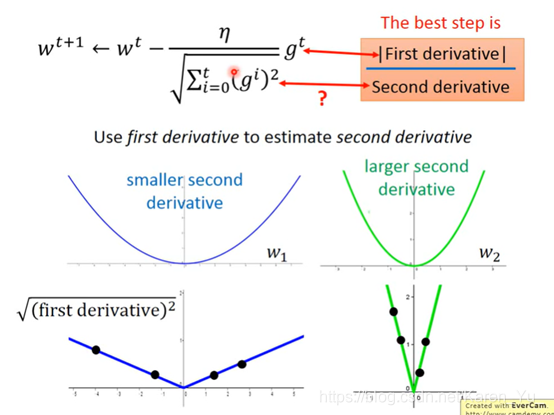
有关老师提到的AdaGrad
https://blog.csdn.net/weixin_44478378/article/details/101167706
这篇博客有相关的叙述
均方根值也称作为方均根值或有效值,在数据统计分析中,将所有值平方求和,求其均值,再开平方,就得到均方根值。
σ是过去所有算过微分值的root mean square
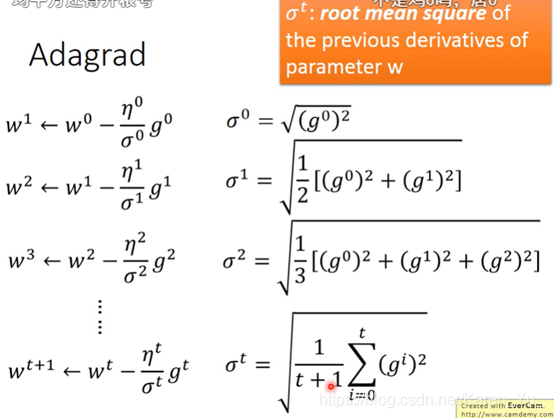

(妙蛙)
据说速度慢到令人发指
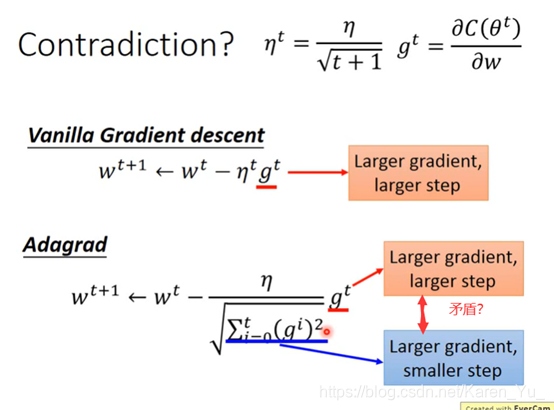
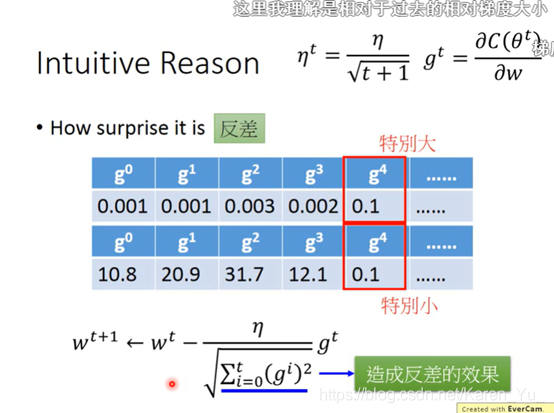
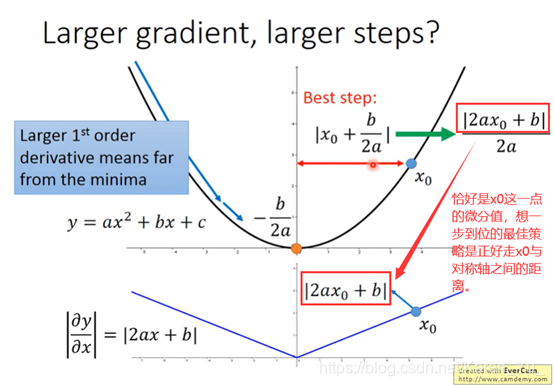
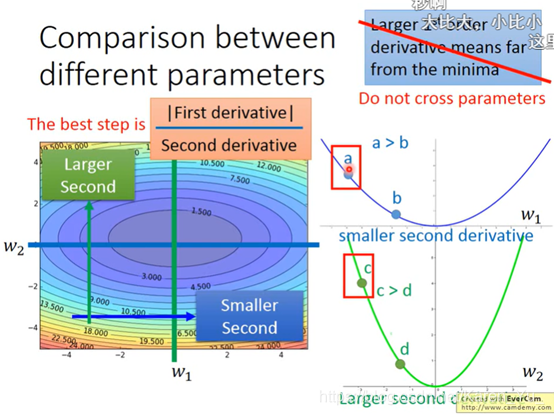
gradient的值越大,就离最低点越远
但是多个参数的时候就不能这么认为
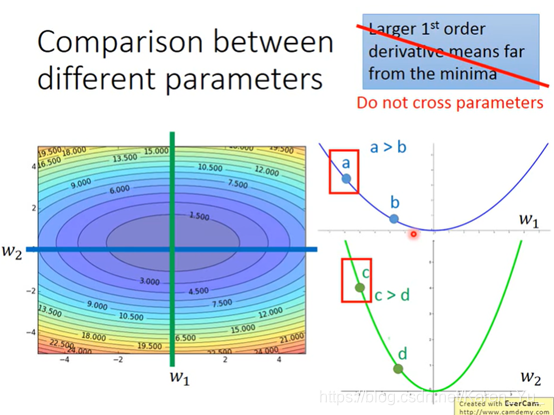
比如这里比较a和c,虽然a离的远,但是c比a陡
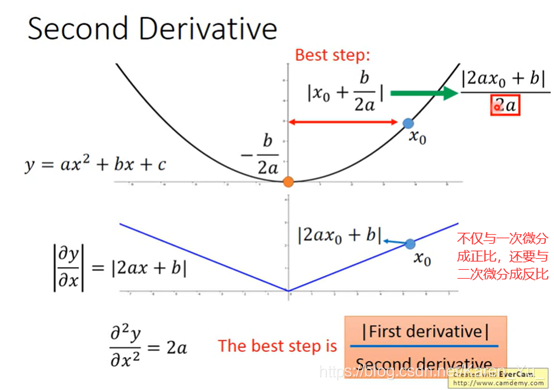


搬弹幕:
每组数据均对应一个损失函数,所以不用再求总和
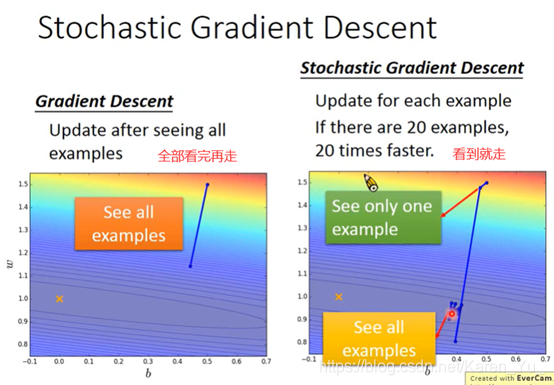
感觉正常梯度下降看起来成熟稳重
随机梯度下降就很急性子,走一步看一步,看一步走一步

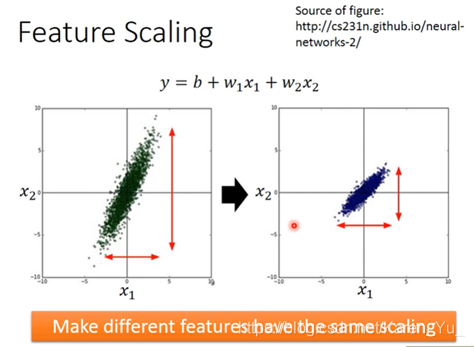
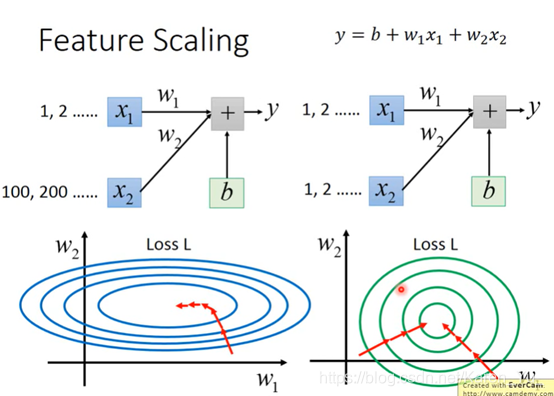
输入数据的差距过大会影响参数,就会导致有的地方陡有的地方平缓,一个learning rate就搞不定,所以如果把scale调整一下,让Loss尽量是正圆,就会方便很多
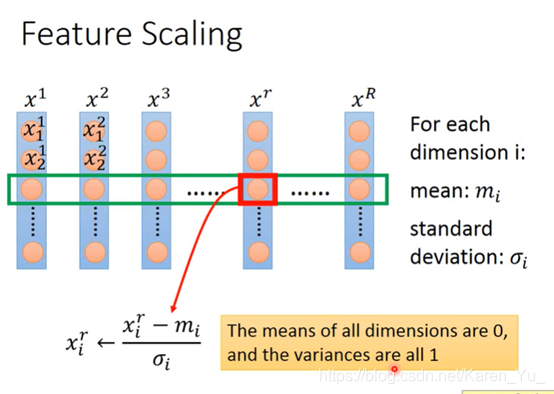
方法,对应每一行都求平均值和标准差,然后按照如图所示的式子算一下
后面是一些数学问题
泰勒级数:

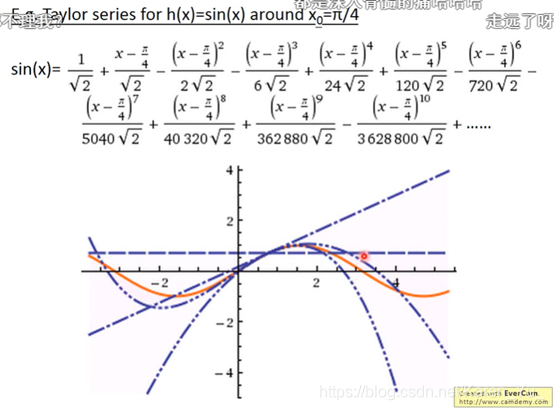
(弹幕玩梗考研数学的同学也太好笑了吧!哈哈哈哈哈哈哈哈)

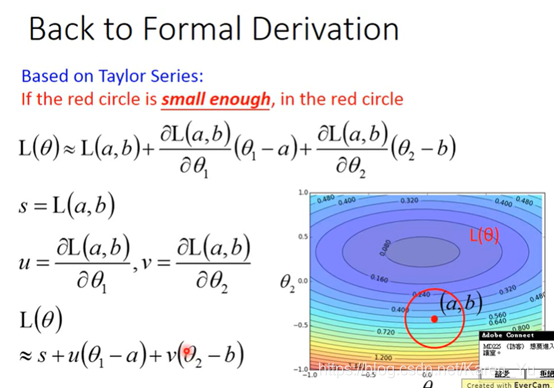
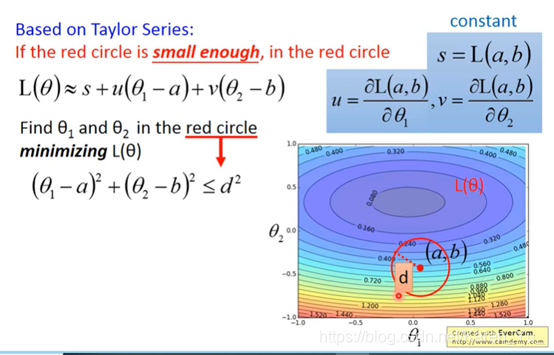

想让L(θ)最小,和(u,v)取相反方向


learning rate要小
据说二次微分的效率很低
缺陷,可能会卡住,不一定是卡在局部最优解,也可能卡在半路上的微分为0或者接近0的点,但是实际上L的值还挺大的
P6 Gradient Descent_2
硬核串台,实验演示
P7 Gradient Descent_3
硬核串台,实验演示
P8 Optimization for Deep Learning (1_2)(选学)
据说是助教提供的选修课,需要有一定的基础,所以先跳过
P9 Optimization for Deep Learning (2_2) (选学)
据说是助教提供的选修课,需要有一定的基础,所以先跳过
P10 Classification_1
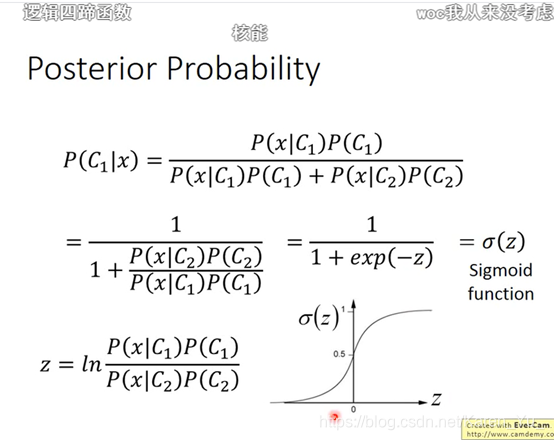
Probabilistic Generative Model

举例

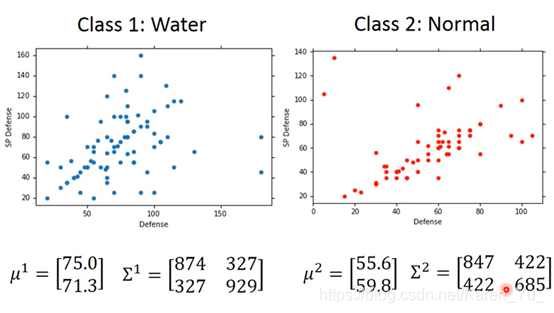
还是熟悉的配方,还是熟悉的味道哈哈哈,给宝可梦分类

举例:皮卡丘,就可以用七个数值取描述它,也就可以理解成是一个七个数值组成的向量
那么能不能把这七个数据输入,然后输出告诉我们这是什么种类的宝可梦

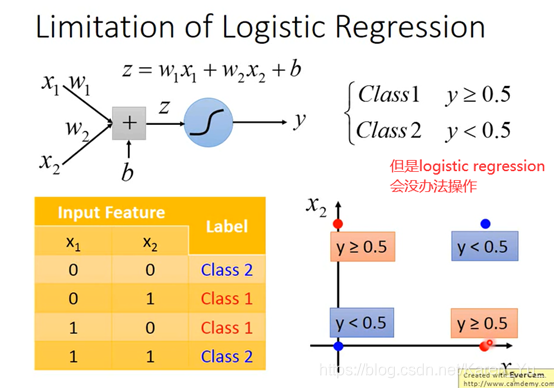
如果使用分类(只考虑分成两类),当值接近1就是1类,当值接近-1就是2类
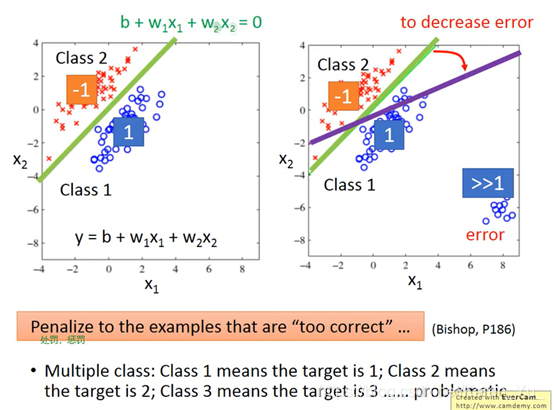
最好的情况当然是左边的图,能正好分开,大于0的就是第一类,小于0的就是第二类,但是如果出现了如右图所示的,有远大于1的情况,为了更好的分类,电脑就会偏移分类的直线,以期减少误差(我愿称之为自作聪明……)


有两个盒子,B1和B2,其中都有一些蓝球和绿球,现在从这两个盒子里拿出了一个蓝球,那么这个蓝球从B1中抽取的概率是多少(选盒子也有概率)
补充贝叶斯公式:P(A|B)=P(B|A)*P(A)/P(B)
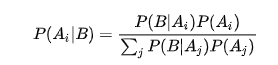

可以知道某一个x出现的机率:![]()
补充:
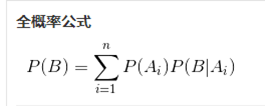
有关这两个内容,或者回去翻一下概率论的笔记,或者可以参考博客和知乎
https://blog.csdn.net/u010164190/article/details/81043856
https://zhuanlan.zhihu.com/p/78297343


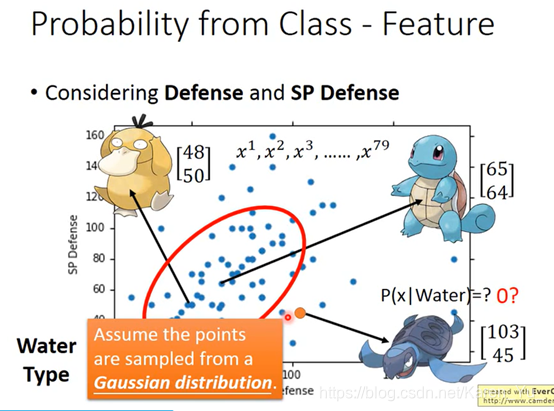
假设符合高斯分布(高斯分布一般指正态分布。正态分布(Normal distribution),也称“常态分布”,又名高斯分布(Gaussian distribution))
弹幕提到概率密度函数,附相关链接方便学习:
https://www.zhihu.com/question/263467674
https://blog.csdn.net/sigai_csdn/article/details/83586458
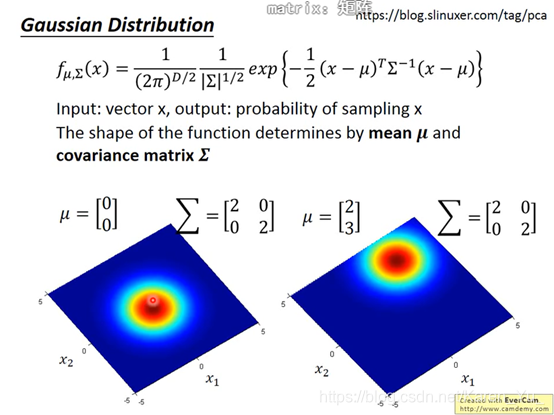
同样的∑不同的μ表示机率分布最高点的位置是不一样的
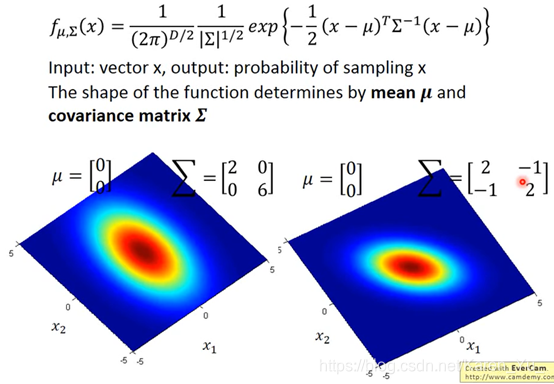
同样的μ不同的∑代表机率分布最高点是一样的,但是分散的程度是不一样的
注(搬弹幕):μ的两个参数,一个是防御力的均值,一个是特殊防御力的均值。∑是协方差矩阵(反应随机变量的相关程度)

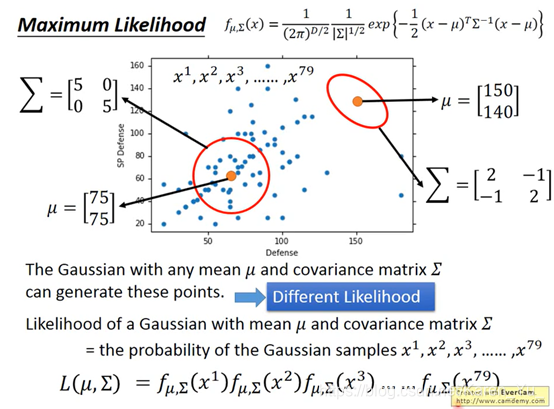
理论上任意一个高斯分布都有可能sample出这79个点,但显然,左下角的sample出来的机率要比右上角的高。只要给出高斯分布的μ和∑,就可以得出sample出79个点的机率是多少。
maximum likelihood [统计] 极大似然;[数] 最大似然率 最大似然估计
L(μ,∑)算出来的是sample出来79个点的机率到底有多大
因为sample出来每个点都是相互独立的,直接乘就OK了

likelihood 最大的高斯写作,μ star和∑ star
直觉告诉我们这个μ star就是平均值(这些三点的最中心的点就是正态分布的那个尖儿,所以极大似然的中心点是均值)
计算
弹幕推荐的相关文章https://zhuanlan.zhihu.com/p/26614750

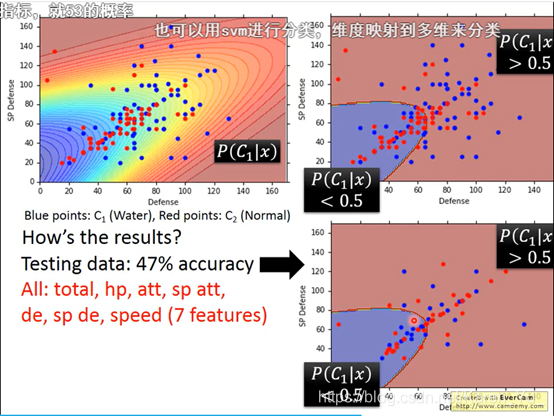
有一个弹幕特别搞笑,说可以反向选择,另一边正确率是53%哈哈哈哈
所以可以算: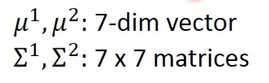 但是这个正确率也只有54%
但是这个正确率也只有54%
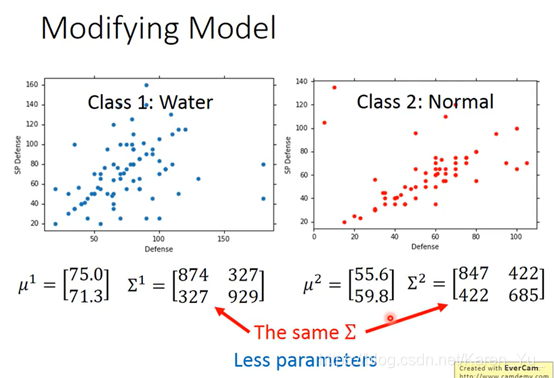
现在让两个用一样的∑

(加权)因为第一类有79个,所以∑要按比例乘以79/140,同样第二类也是按照比重乘以61/140
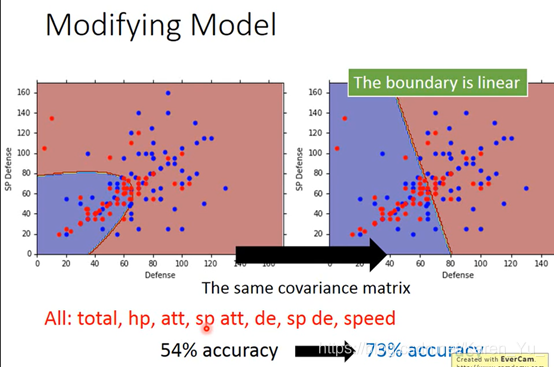
在共用∑的时候,正确率明显提高。得到的结果可以近似看成线性


数学过程



结论:

(搬弹幕)共用∑之后参数减少,防止过拟合
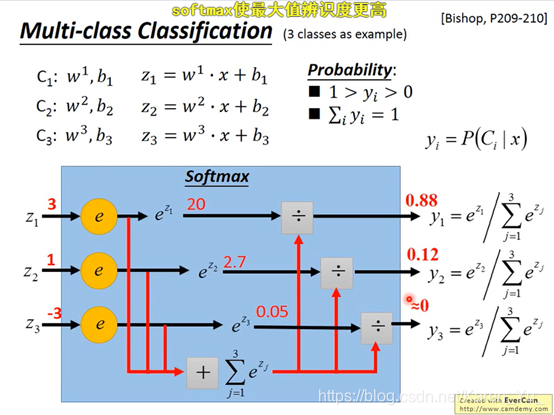
P11 Logistic Regression
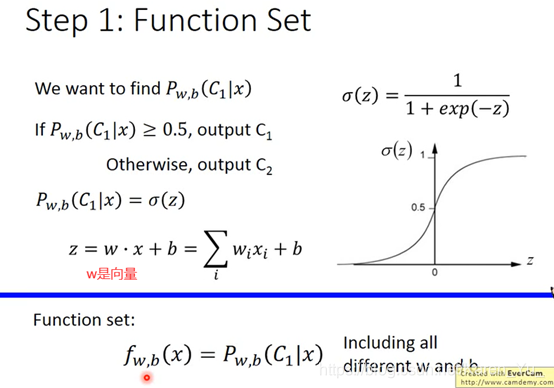
f下标w和b表示function set受w和b控制的



(搬弹幕)这里的L是likelihood(最大似然函数)

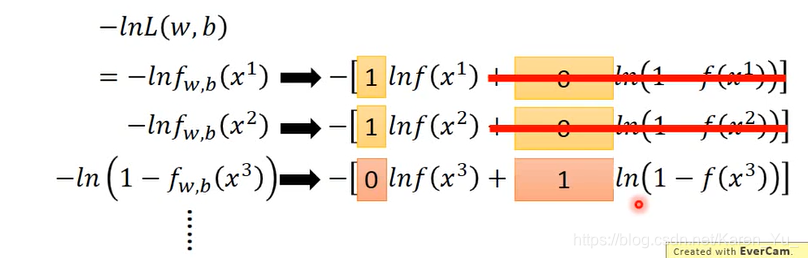

交叉熵:https://zhuanlan.zhihu.com/p/35709485
https://blog.csdn.net/joaming/article/details/89116305

为什么不用square error?
(搬弹幕)逻辑回归假设的是概率分布,线性回归假设的是函数值
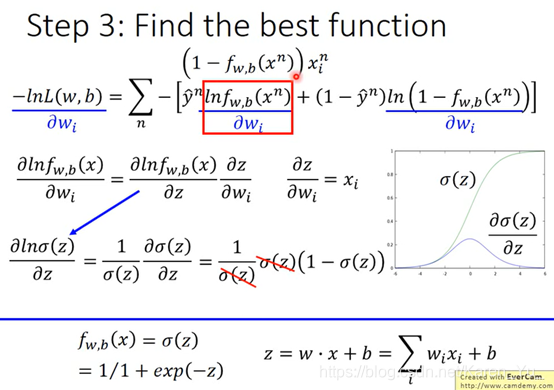
计算图中红色框框里的

计算途图中右边红色框框里的

w的update取决于:1. learning rate(自己调)2.xi(来自于data) 3. 图中紫线
紫线:离目标的差距
yn hat:目标
fwb:model的output

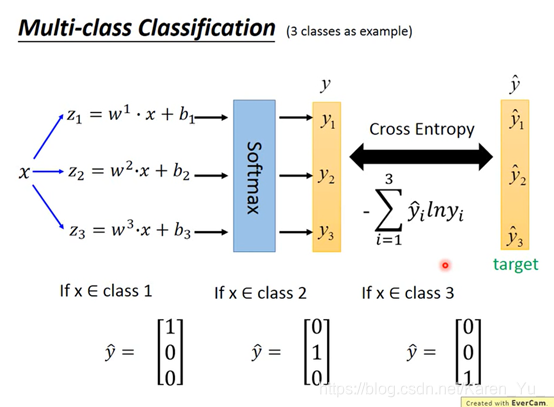
解释上面提到的问题:为什么不用square error

class1
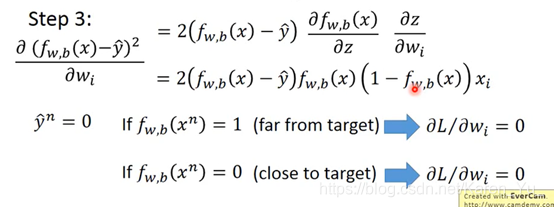
class 2
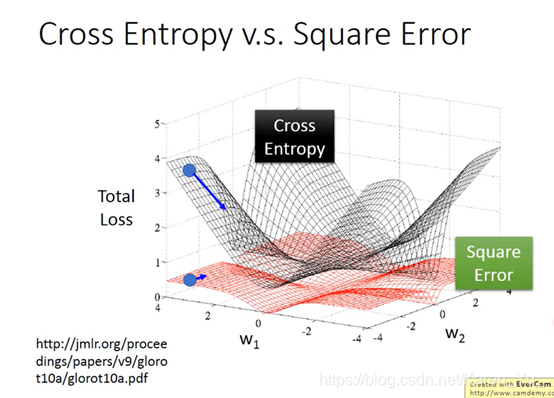
黑色的是交叉熵,红色的是square error
cross entropy在距离目标远的时候update的变化量就很大,但是square error 在离目标远的地方迈步也很小(很可能在开头随机选点的时候就卡住了,但是也不能说为了提高速度就增大learning rate,因为不知道开始选的点是不是在目标附近)
discriminative model v.s. generative model

虽然是同一个training data,但是做出的假设不一样,最后得到的参数也不一样
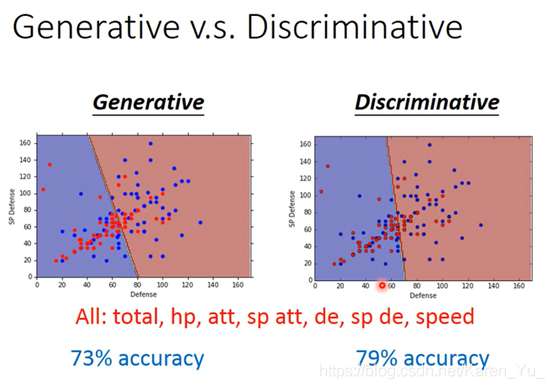


朴素贝叶斯,反而认为是class 2
(搬弹幕)朴素贝叶斯基于已有数据,但不拘泥于已有数据,判别模型也是基于自由数据,也拘泥于已有数据
(搬弹幕)gm模型提前假设,包含的函数会受限,dm则包含更多可能,因此可以得到比较好的效果
精髓是脑补

但是Discriminative model并不是永远都比Generative model好,因为D是看数据说话,如果data少的情况下,会脑补也是一种能力
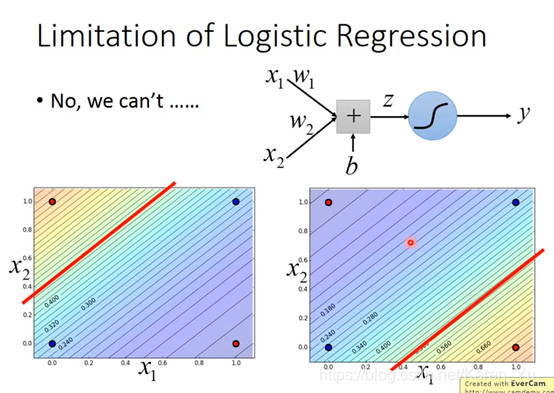
一条直线没法完全分开红色和蓝色的点
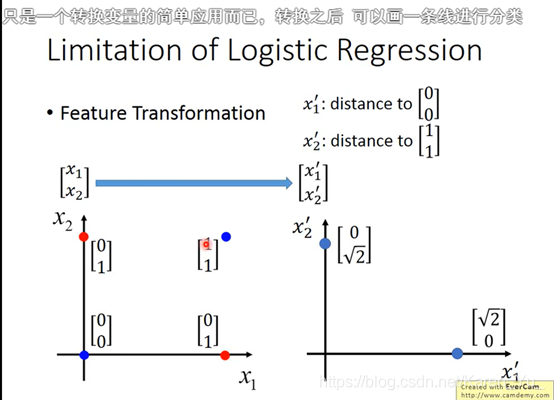
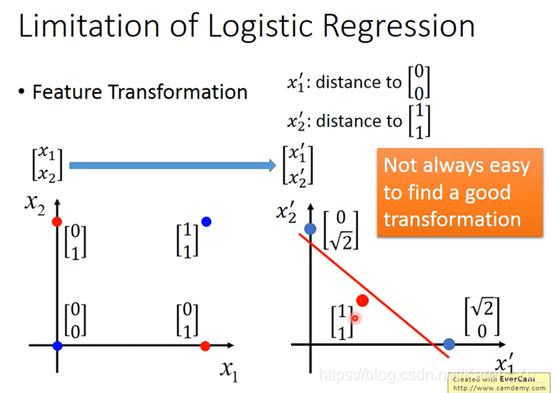
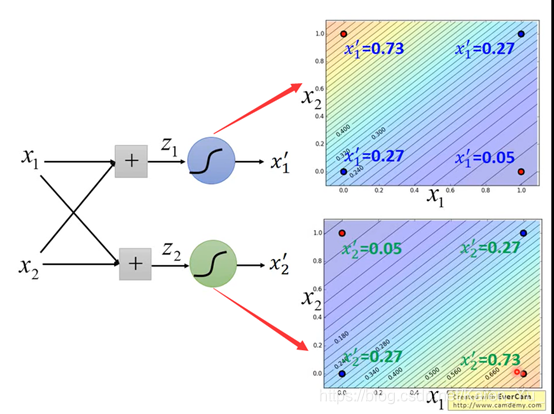
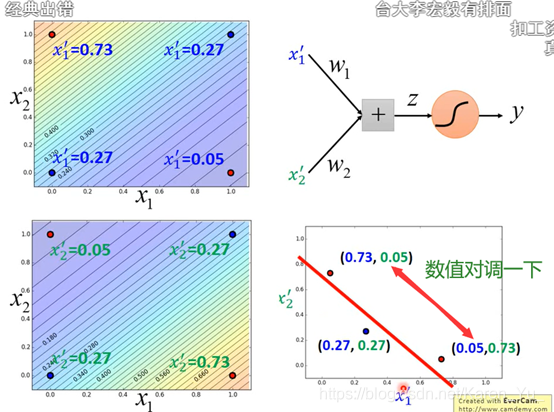
右下是(0.73,0.05)左上是(0.05,0.73)
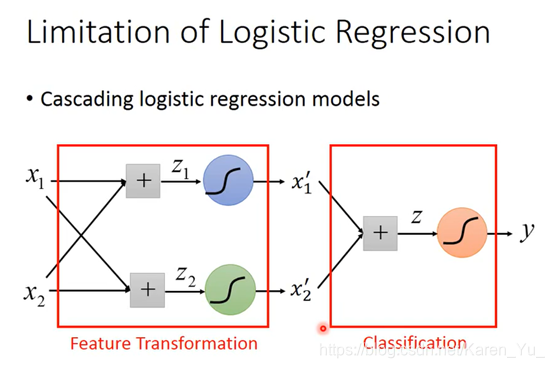
一个output可以作为另一个的input,然后无限套娃
然后就可以去骗麻瓜了×
P12 Brief Introduction of Deep Learning
deep learning 运用广泛
deep learning 的历史

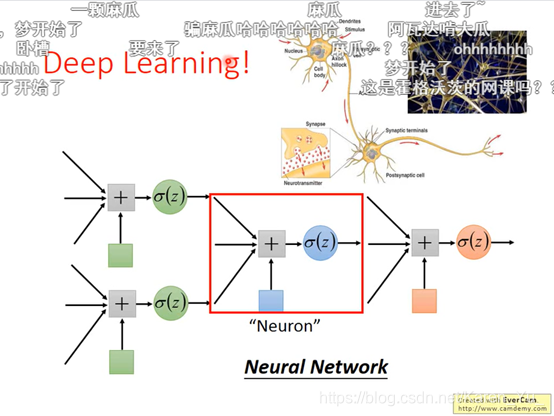
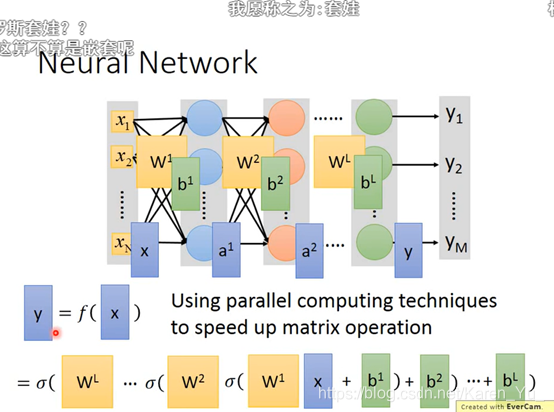
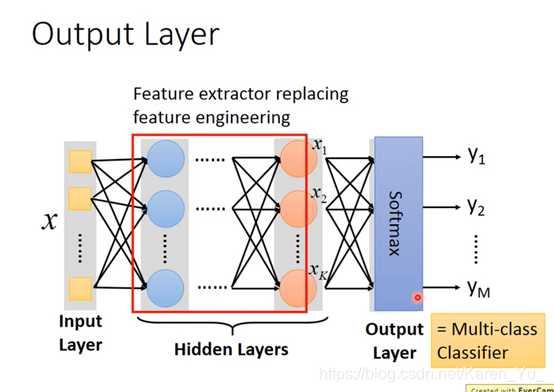
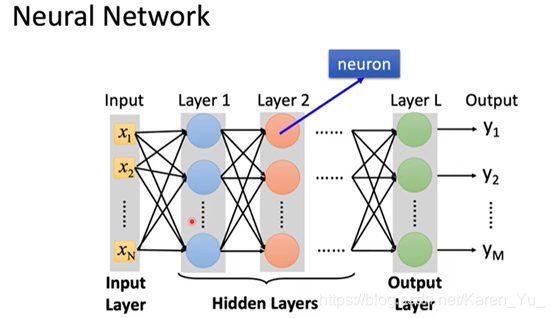
STEP 1其实就是Neural Network
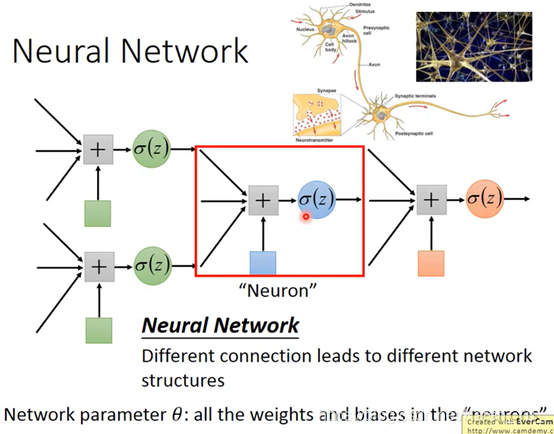
可以用不同的方法连接Neural Network,不同的连接方法得到不同的structure
每个logistics regression都有自己的bias和weight
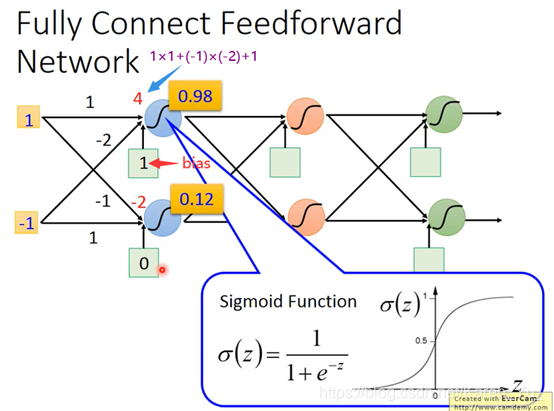
怎么连接是自己手动操作的,最常见的是fully connect feedforward network(全连接前馈网络)
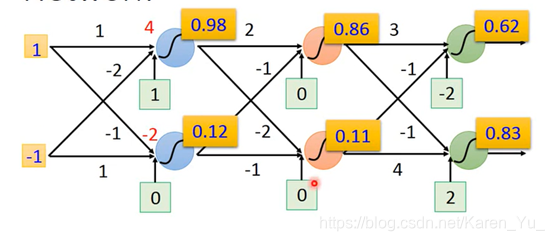
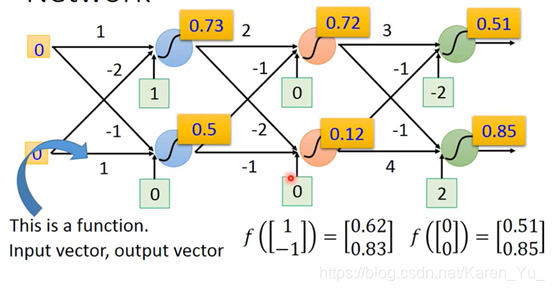
同理,如果每一层的weight和bias都知道,就可以一致这样算下去
一个neural network,就相当于一个function。
input和output都是vector
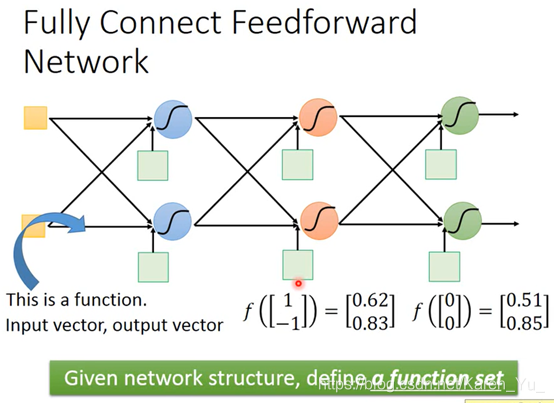
当给定了某个特定的结构之后,就相当于给了function set,向里面喂不同的数字就是在构造不同的函数
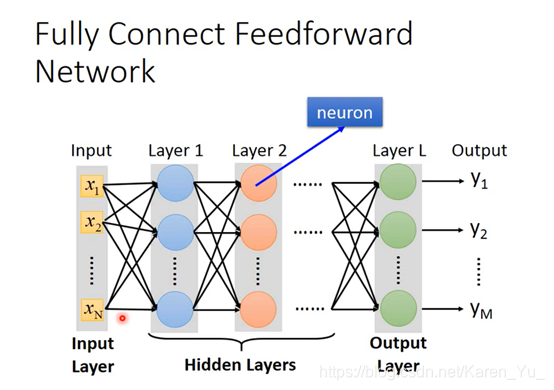
Deep = Many hidden layers
层数越多,正确率越高
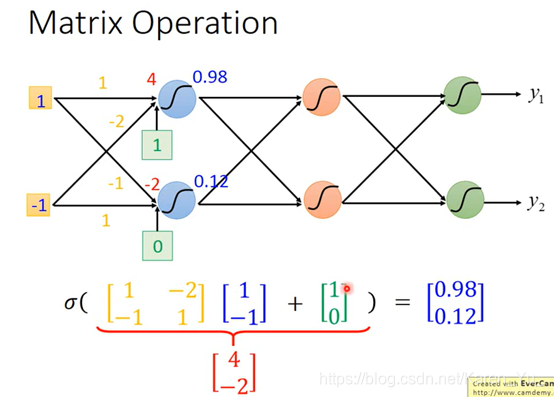
橙色是weight,绿色是bias
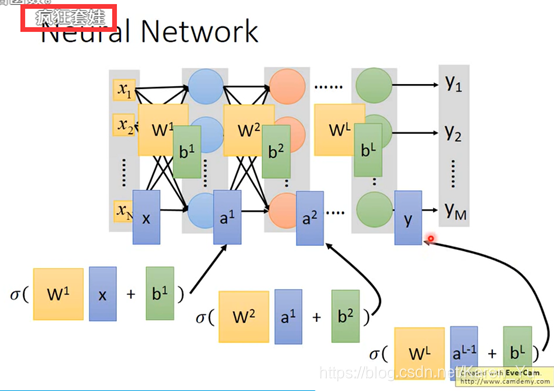
如弹幕,疯狂套娃
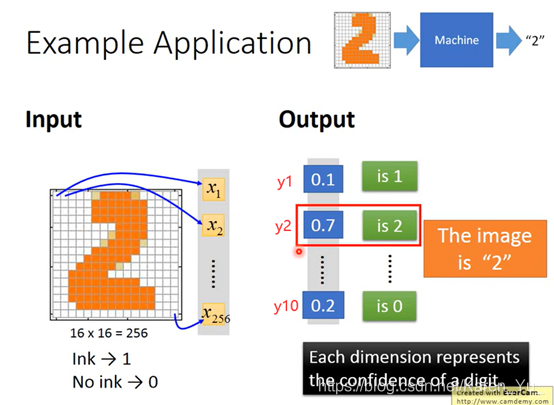
有墨迹就是1,没有墨迹就是0。图片就变成一个256维的vector,十个输出可以看作是0-9
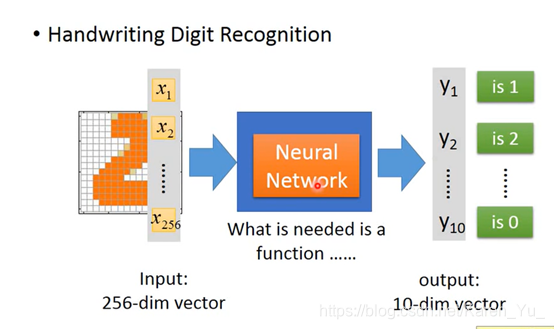
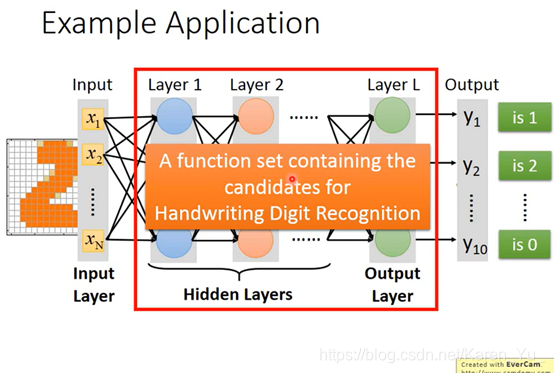
这里需要设计structure
You need to decide the network structure to let a good function in your function
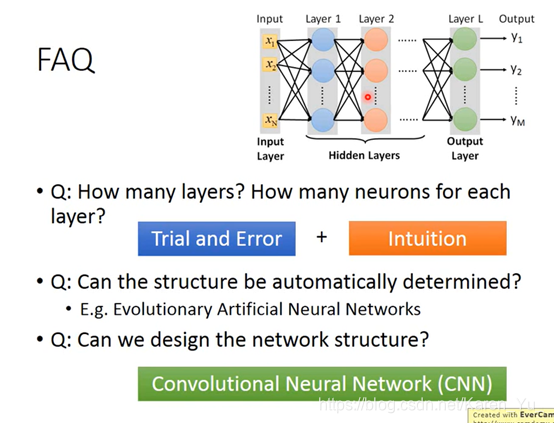


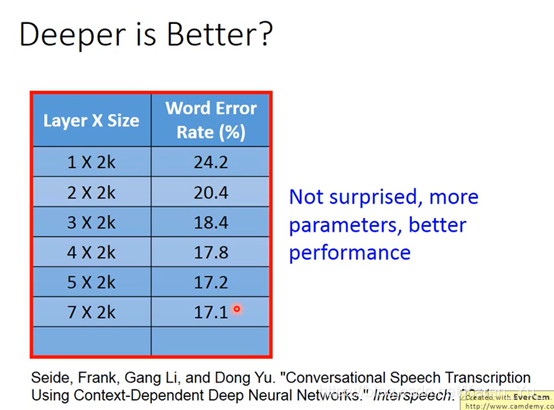

PS.此处为P15内容
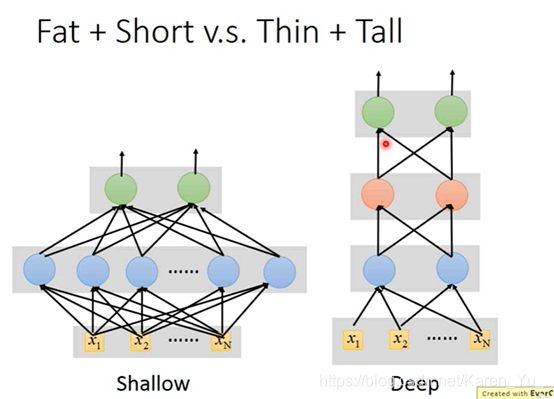
当参数个数一样的时候,shallow的module就相对矮胖,deep的module就比较瘦长。
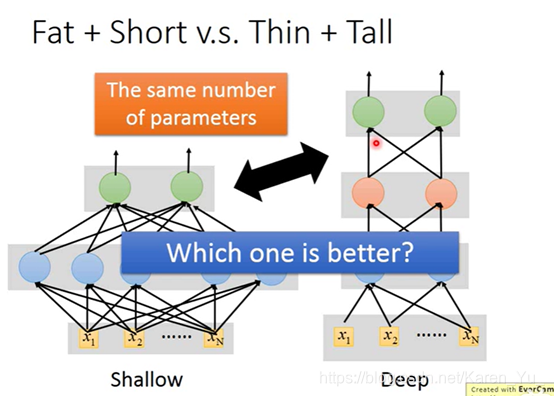
在参数个数相同的情况下,哪个更好?
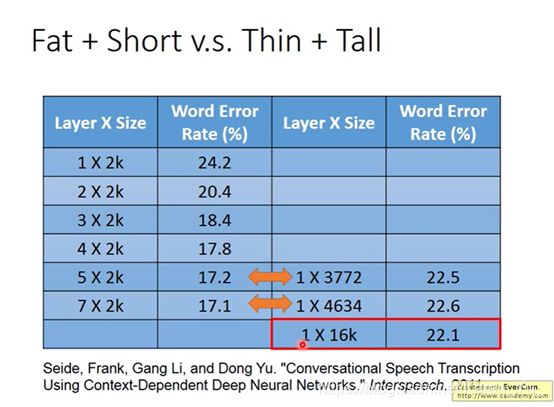
PS.第三列的neuron个数(口误?)是为了保证和第一列size差不多
(搬弹幕)neuron数目和参数数目是不一样的概念,参数是w和b大数目
(搬弹幕)参数的个数不是简单相乘,因为很多洗漱都是多个乘积
why?
单纯的增加parameter(只让neuron长宽,不让长高)对performance帮助不大
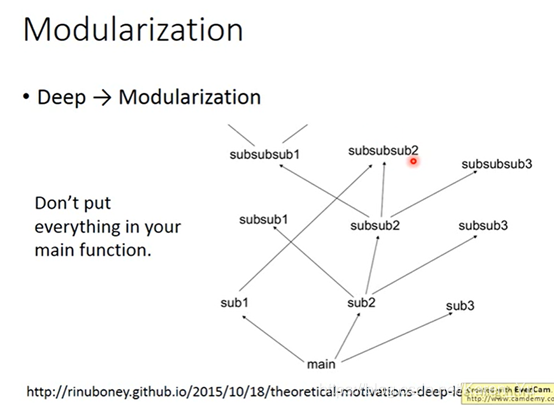
结构化的架构
(搬弹幕)老千层饼了
(搬弹幕)深度结构,后面可以利用前面的结果
(搬弹幕)g(f(x))的表达能力要高于一个复杂的f(x),结构化提高了复用率,单位神经元效率更高
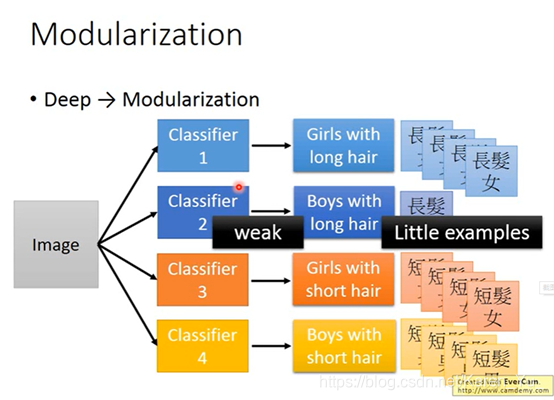
比如:假设我们去train长头发的女生、长头发的男生、短头发的女生、短头发的男生。因为长头发的男生很少,所以train出来的module就比较weak

可以用模组化的概念,假设我们现在不是直接去解这个问题,而是把原来的问题切成比较小的问题。
比如,任意classify,看看有没有特定的attribute出现,不是直接detect是长头发的男生还是短头发的男生,而是把原来的问题切成比较小的问题。
这样每个basic classify都有足够的data。
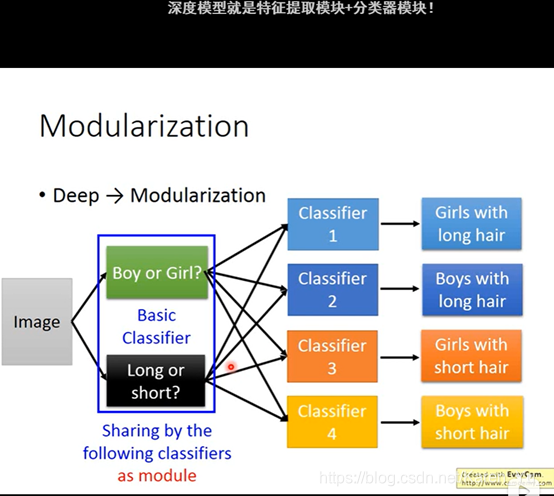 →
→
每一个classify就去参考basic attribute的output
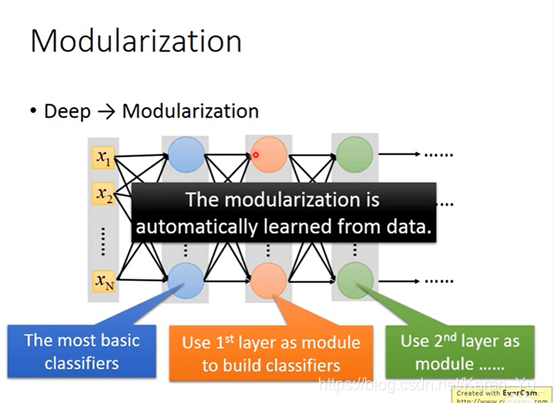
第二层neuron(比较复杂的classify)把第一层的output当做它的input
第三层的neuron又把第二层的output当做input
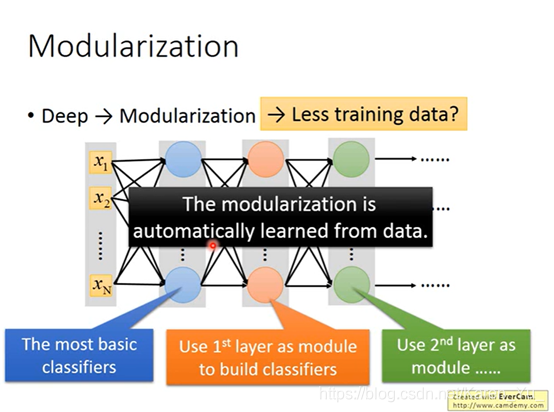
怎么做模组化这件事是machine自己搞定的
(搬弹幕)深层模型,是因为非线性能力很强,所以相比单层模型拟合效果好
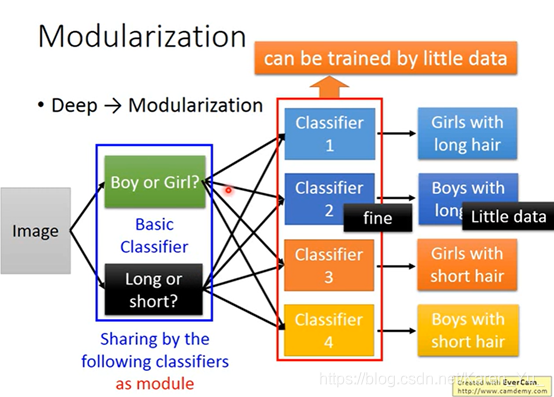
模组化少数据也能train的比较好
就是因为数据不够多所以才要做machine learning
这样data用的就很efficient
(剩下部分请回到P15)
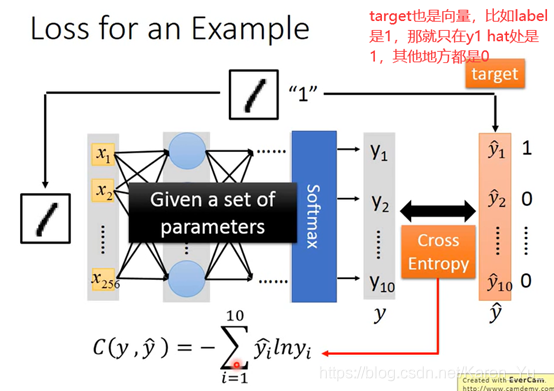
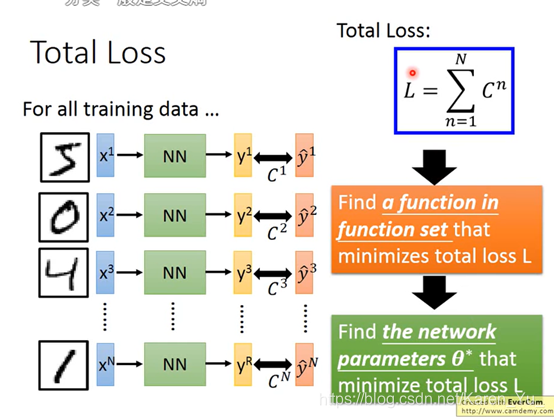
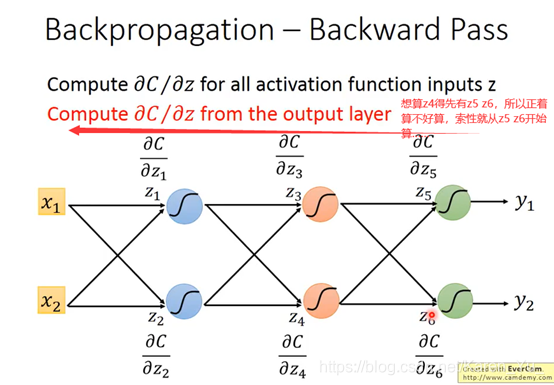
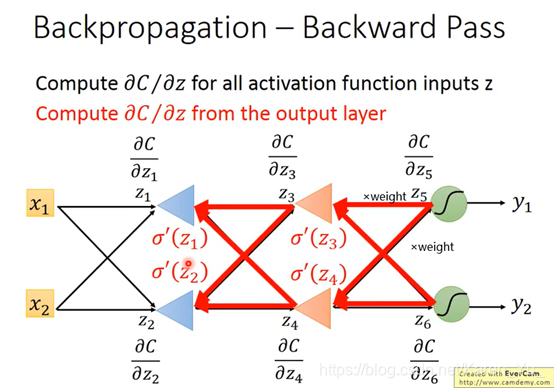
P13 Backpropagation

假设neural network有一堆参数w和b,首先先选择一个初始参数:θ0,然后计算θ0对loss function的gradient(gradient是一个vector)->计算每一个network里的参数w1 w2 b1 b2……对loss θ 的偏微分
然后就可以更新参数——>θ1

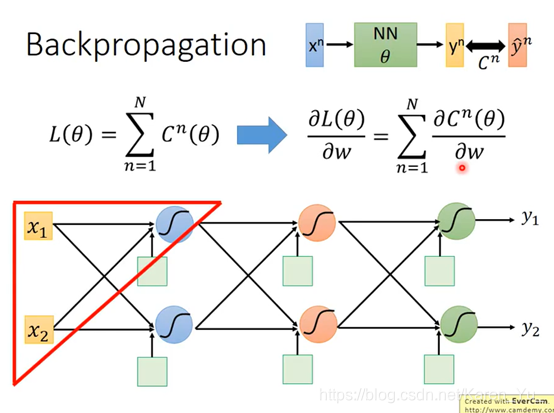
Cn表示yn和yn hat之间的距离,如果Cn大,代表yn和yn hat之间的距离远,说明parameter loss大
讨论左下的红色三角:
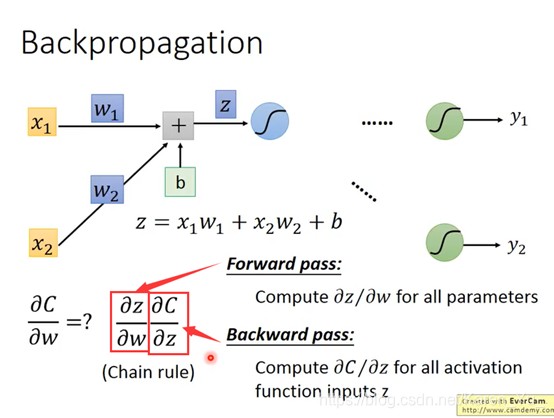
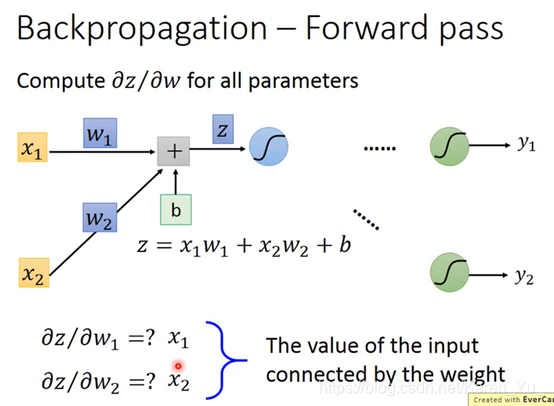
看w1 w2前面接的是什么,接的是什么偏微分出来就是什么
比如:
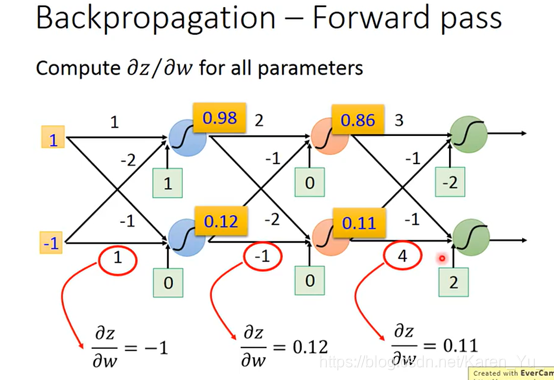
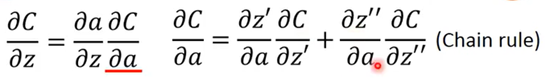
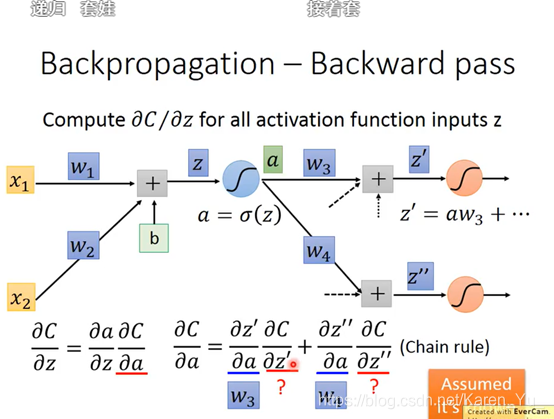
按照前面的理论,很容易算出一部分的值,另一部分就先当作我们知道他的值,继续向下:

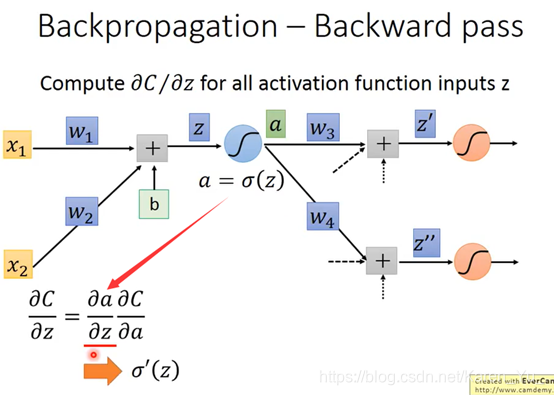
现在假设有另外一个neural
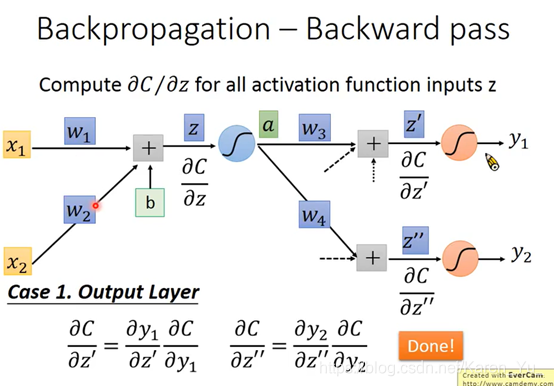
假设两个case:
1.假设现在红色的两个neural已经是output layer(也就是说它的output就是整个network的output)
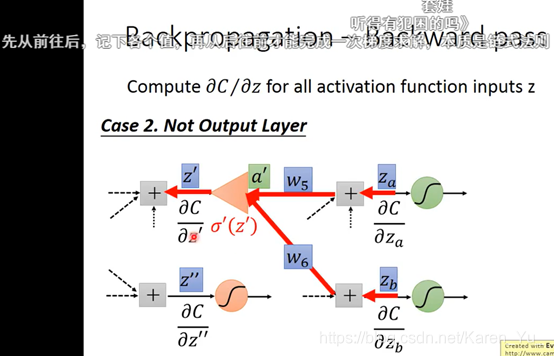
那么:
2.假设红色的两个neural并不是整个neural network的output,后面还有其他内容
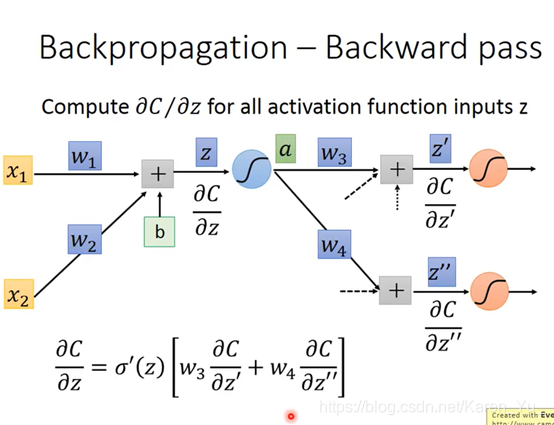
然后就可以反复套娃:
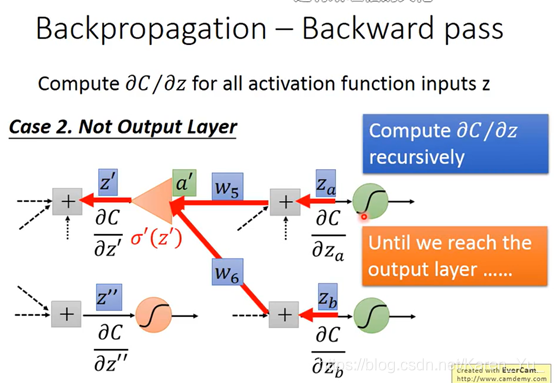
建立反向的neural network
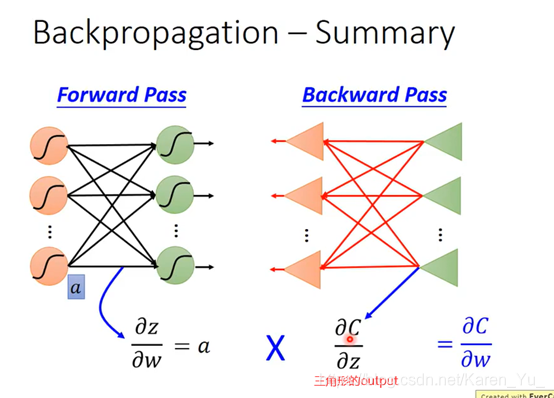
前×后=weight
P14 Tips for Training DNN
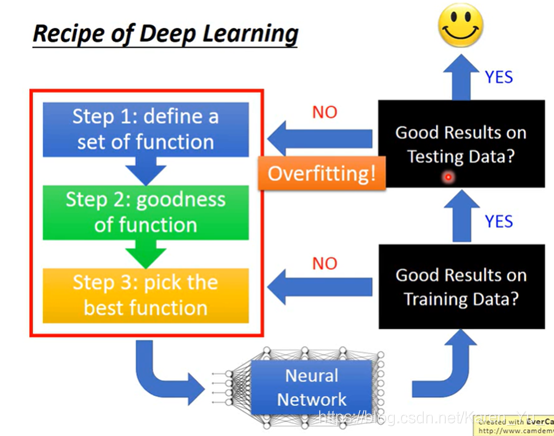
在neural network确定之后,要先检查这个neural network在training set上有没有得到好的结果,如果没有,就要回头重新找(看三个step中有没有哪里出问题)
这里,检查training set performence 是deep learning比较独特的地方。其他的方法,如K近临、决策树,他们在training set上的正确率一定是100%(所以更容易过拟合->在training set上表现很好,在testing set上表现不尽如人意。因此deep learning相对不容易over fitting)
如果得到的是好的结果,就可以去testing set上测试了。如果这里匹配的不好,就又需要从头再来一遍(step1->step3->测试training set)
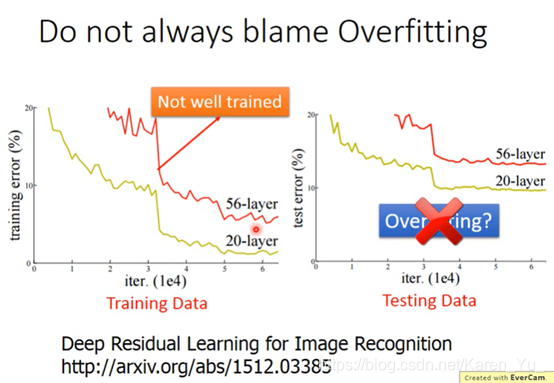 不一定层数多的效果不如层数少的就是因为over fitting(也可以是没有训练好)
不一定层数多的效果不如层数少的就是因为over fitting(也可以是没有训练好)
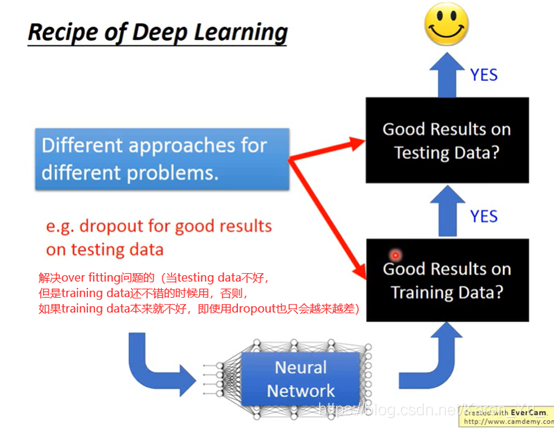
(搬弹幕)dropout就是给定概率随机删除神经元,从而达到减少参数对更新梯度下降的影响,可以一定程度上解决过拟合问题
(搬弹幕)dropout就是随机将一些神经元丢弃,来提高模型的泛化能力
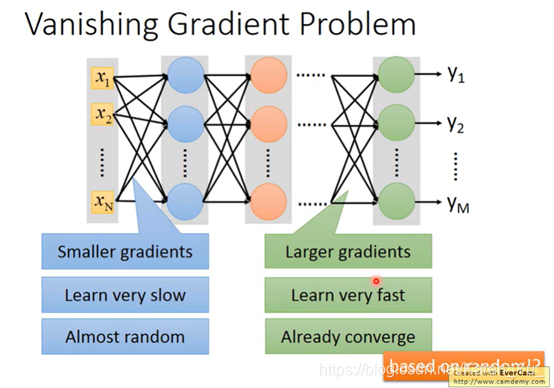
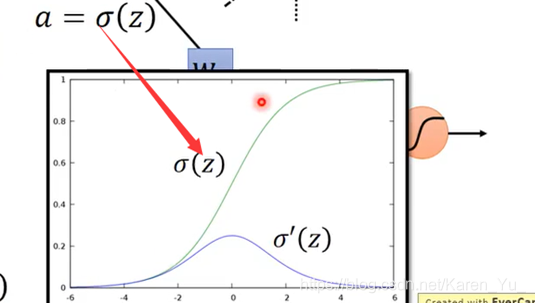
梯度消失(vanishing gradient)
当network叠的很深的时候,在最靠近input的地方,参数对最后loss function的微分是很小的,而在靠近output处的微分值(gradient)是很大的。因此,当设定同样的learning rate时,靠近input处的参数的update时很慢的,但是在output处的参数update很快。->在output处已经收敛了,input还是random分布的。得到的结果不好。
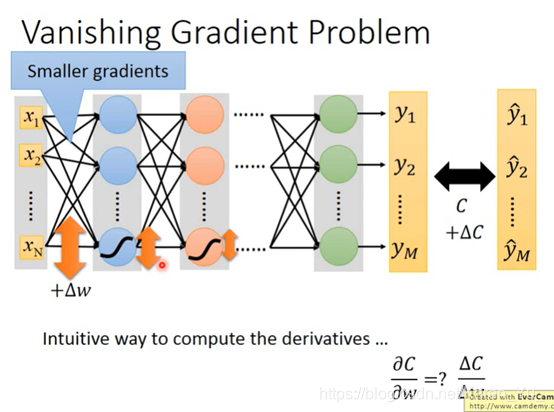
怎么知道到底影响大不大呢?在前面加一个Δω,然后看后面变化多少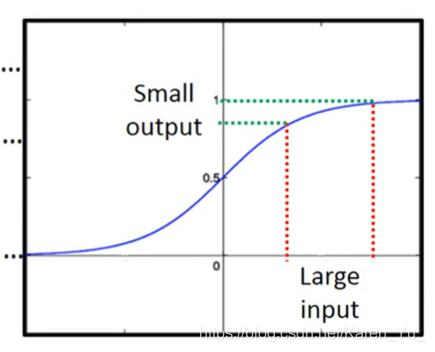

ReLU,线性整流函数(Rectified Linear Unit)
输入时z输出是a,当输入小于0时,输出0,当输入大于0 的时候,输出等于输入(线性的)。
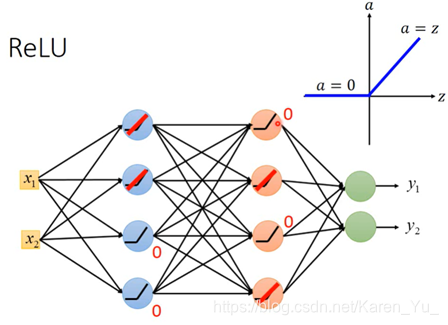 =》
=》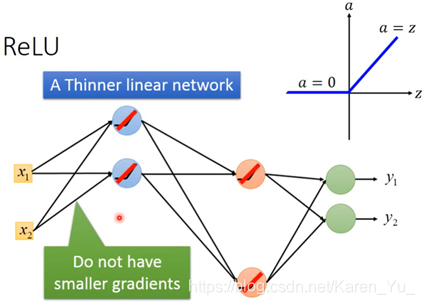
对于output是0的neural,不会影响最后output的值,所以直接拿掉也没关系
但是因为分段的原因,在0处是不可微的(虽然老师提到在0处没什么关系,因为也很少输入需要时0)
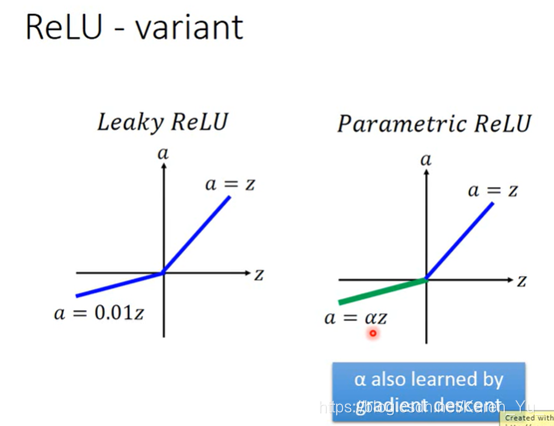
ReLU有一些变体,为了能在input小于0的时候也能update参数,所以可以在小于0的地方赋予一些小的斜率,当然也不一定要0.01
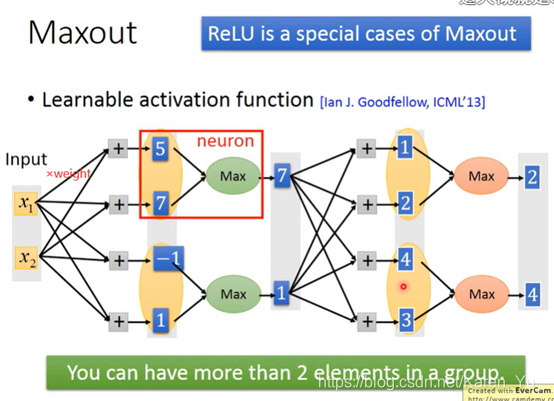
input时一个vector
具体几个element放一组,然后从中挑选最大的时可以自己决定的
maxout network是可以做到与ReLU一样的事的(可以模仿ReLU的)
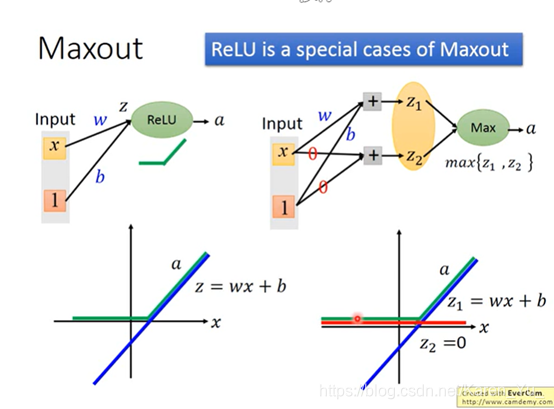
假设我们拥有一个ReLU的neural,他的input就一个value:x,把x乘上这个neural的weight(w)再加上常数b,通过execution function得到a(此时z与x的关系就是线性的)当z小于0的时候,a=0,当z大于0的时候,a=z。
可以理解成总是如PPT右侧显示的那样,总是在z1 z2中选取较大的数作为输出。
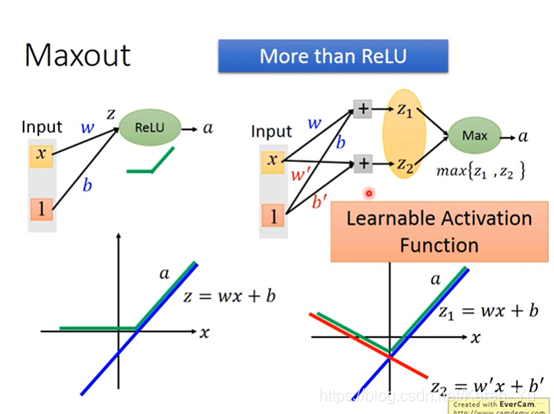
同理当然根据前一张PPT的思路,也可以通过改变weight得到不同的execution function(就是绿色的线)

(搬弹幕)maxout网络中的激活函数可以事任意分段线性凸函数一组中有多少个元素,就有多少个元素。(PPT翻译)
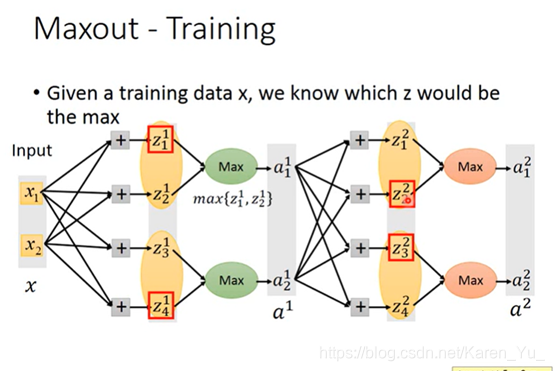
假设红色框框框出来的是比较大的值,比较大的值就会被output出来
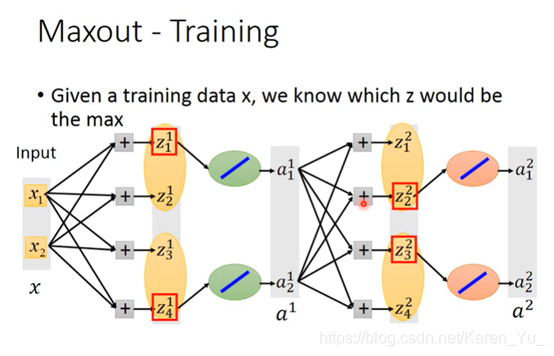
因此max operation在这里就是linear operation
那些没有被红框框框上的即使拿掉也不会影响结果:
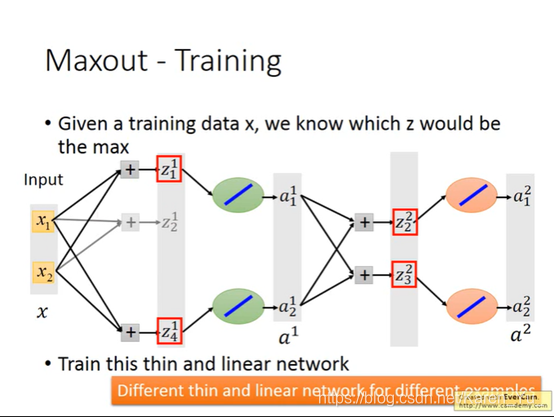
那么那些被拿掉,没有被train的值怎么办呢?实际上,因为有多个training data,所以每个weight实际上都会被train到
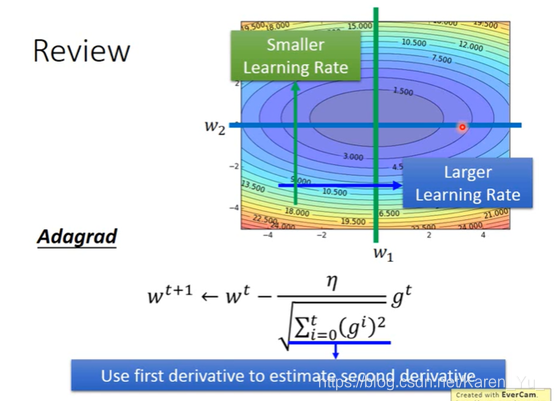
像这种,在陡一些的方向上让learning rate小,在平坦一些的方向上让learning rate大实际上未必有效,比如:
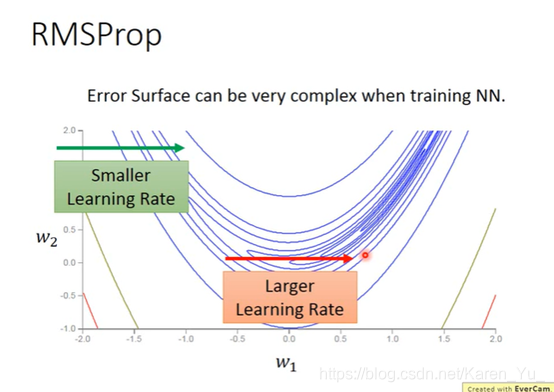
即使是同一个方向上,也需要learning rate快速变动

这里,α的值是自己设置(手动调),可以给目前的gradient大一点的权重,之前的gradient小一点的权重。
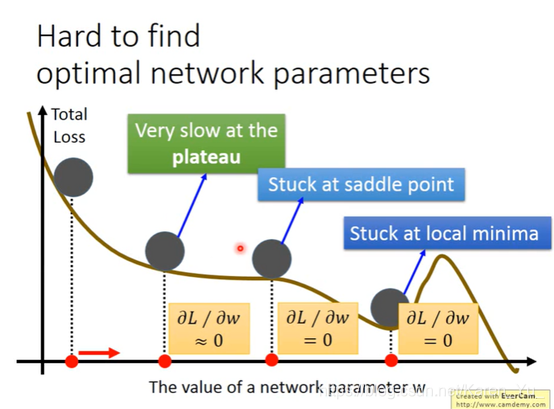
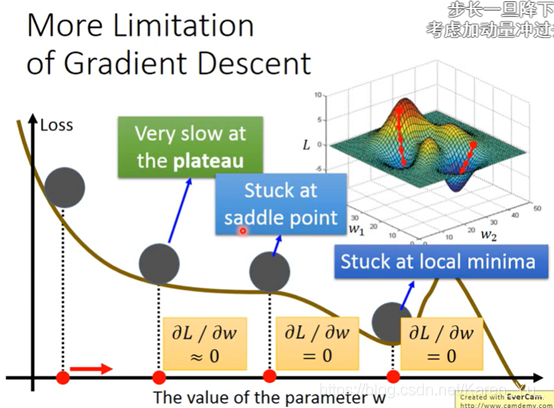
据老师描述,大佬认为其实不用很担心遇到local minimal的,因为当数据非常多的情况下,很大概率是我们认为的local minimal也就是global minimal(山坡很平滑)
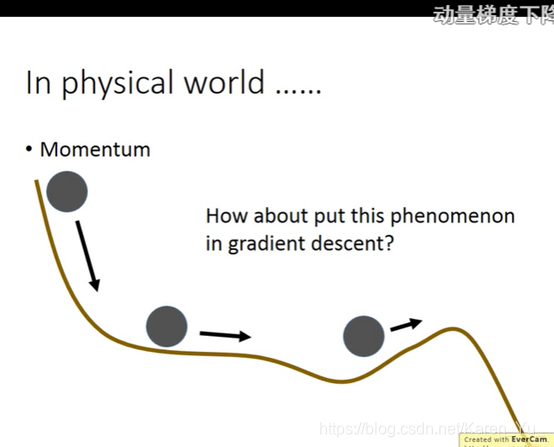
受到现实世界的启发,当一个小球从山坡上滚下来,即使中途遇到平地也会向前再滚,甚至遇到上坡也能滚过去
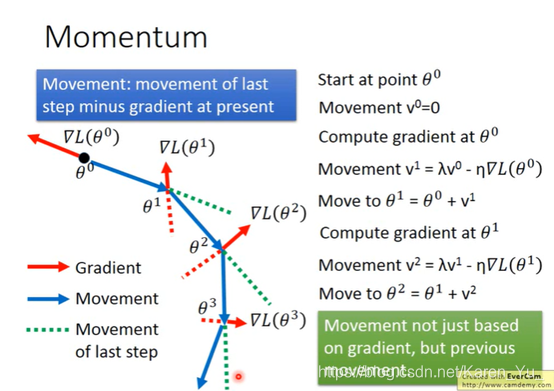
每次移动的方向不仅考虑现在的gradient还要考虑前一个时间点的方向。选一个初始值θ0,用v记录前一个时间点移动的方向(v0因为之前没有移动过所以,v0=0)。
现在移动的方向并非红色箭头所指的方向,而是过去的方向加上负的现在的方向
(λ决定之前的方向留多少)

因此v2不仅收v2此时方向的影响,v1甚至v0都会再一定程度上影响到v2(但是离得越远影响越小)
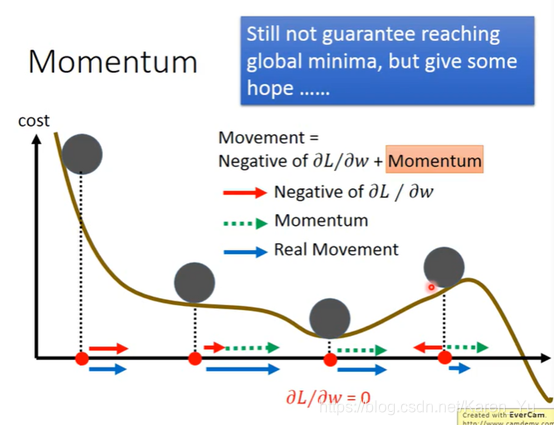
甚至有可能如上图这样跳过local minimal

m0是momentum,前一个时间点的movement
v0就是θ,就是之前gradient的平方和
mt就是现在要走的方向
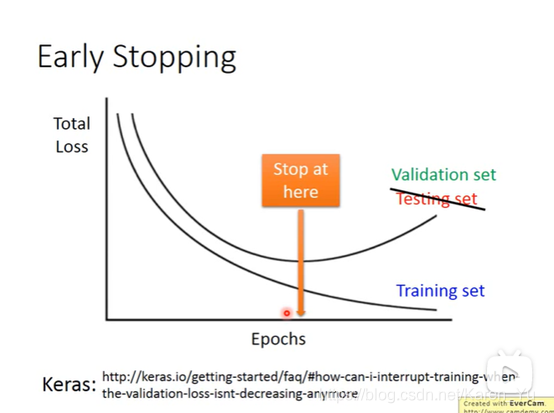
early stopping,随着training,total loss(如果learning rate调的对的话)也会越来越小。又因为training set和testing set的distribution不完全一样,有可能training data的loss逐渐减小的时候,testing data的loss反而增大了。最好能停在中间的某个地方,使得两者都不会太大。但是,我们并不知道testing set error是什么,因此此处用validation set来verify(用validation set来模拟testing set)(validation验证)。
此处PPT上所说的testing set并非实际意义上的testing set,而是有label data的testing set(?)。

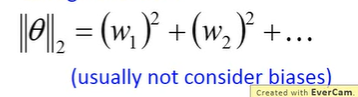
regularization:重新定义的一个需要minimized的loss函数
不考虑bias(∵加regularization的目的是为了让function更平滑,而bias跟平滑没关)
(搬弹幕)两个竖线就是欧几里得范数

(搬弹幕)为了防止梯度爆炸
(搬弹幕)范数少了根号
因为||θ||是所有w的平方和,所以取偏微分之后剩下w
η:learning rate(通常是很小的值)->所以1-η通常是一个接近1的值
λ(通常也是很小的值)
虽然(1-ηλ)wt会越来越接近0,但是总体是不会变成0的(因为后面还有η)
如果使用L2的regularization的时候,每次都会让weight小一点小一点小一点->称为weight decay
(搬弹幕)就好像我每学一点都会忘一点,最后就会不清楚知识细节,但是又整体的知识体系
(搬弹幕)正则化会导致训练集误差,但会减少测试集误差
做regularization希望参数不要离0太远,加上regularization造成的效果与减少updating次数(early stoping)的效果(也是不要离0太远)是很像的。

||θ||2里的w有平方,那么能不能不要平方呢?
当然可以,e.g.,L1的regularization
都是让参数变小,如果w是正数,就减掉一个正数ηλsgn(wt),如果w是负数就加上一个正数(负负得正),最后都向0靠拢。
注:sgn(w),当w是正数,函数output就是+1,当w是负数,函数output就是-1。
||θ||1中的w1 w2都是取绝对值,是一个V的形状,在V的一边求导是+1,在另一边求导是-1,只有在0处不可导(真遇到0的情况,可以不用管,随意赋值0就可以)
(搬弹幕)(与L2)相比,一个是线性的,一个是定步长的
所以用L1 learn出来的参数有很接近0的值也有非常大的值(sparse),但是L2learn出来的结果平均都比较小。
(搬弹幕)L1训练出来的就依靠某几个特征,L2就相对平均。

老师举例,比如人脑
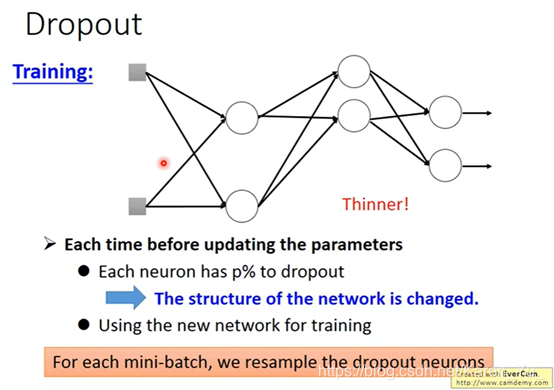
在进行training的时候,每次update参数之前,都对每一个neuron(包括input的每一个element)做sampling(没听懂什么单词),每个neuron都有p%的可能性被丢掉
当一个neuron被丢掉的时候,与其相连的weight也被舍弃
(搬弹幕)随机丢掉一些神经元
丢掉之后network就变瘦了,此时再去train这个比较细长的network
要注意的是,这个sampling是每一次update参数之前都要做一次,所以每次training的时候,拿来的network structure是不一样的。—>所以每一次做sample得到的结果是不一样的。
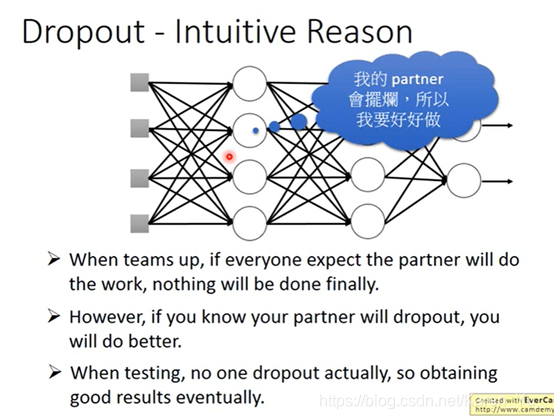
注意用dropout时performance是会变差的(神经元被莫名其妙地丢弃了)但是dropout的目的是让training的结果变差,但是testing的结果变好。

在testing的时候要注意:
不做dropout(所有neuron都要用)

为啥要做dropout↑(老师老二刺螈了
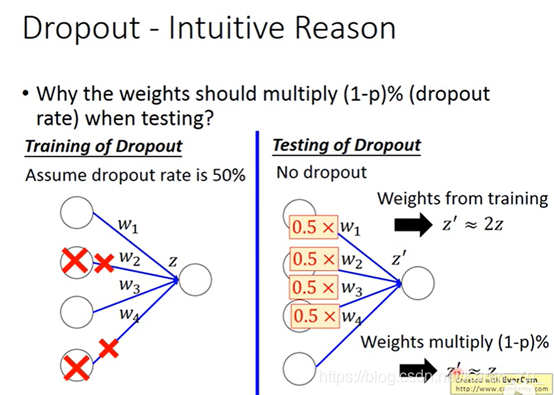
那么为什么要weight×0.5。
在train的时候有一半被丢掉了,但是在test的时候没有丢掉,相对来说就多了一倍
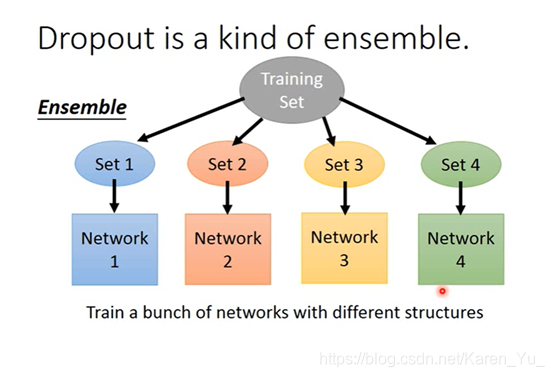
(dropout是一种终极的ensemble的方法)
什么是ensemble方法?
我们有一个很大的training set,每次从training set中只sample一部分的data出来。从原来的training set中提取出很多的subset,然后train很多个module(每个module的structure都不一样,虽然每个之间的varies很大,但是平均起来很小)
(搬弹幕)因为每次失活都随机产生一个NN(neuron network)
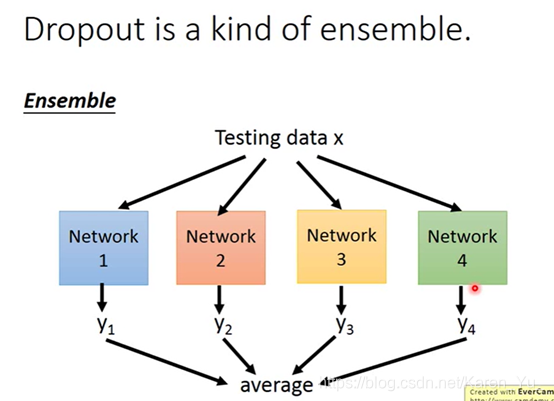
所以真正在testing的时候,train了100个module,在testing的时候丢一个testing data进来,通过所有的module,得到一大堆的结果,再把这些结果平均起来,当做最后的结果。如果module很复杂的时候很好用(老师实名讽刺决策树容易overfitting)
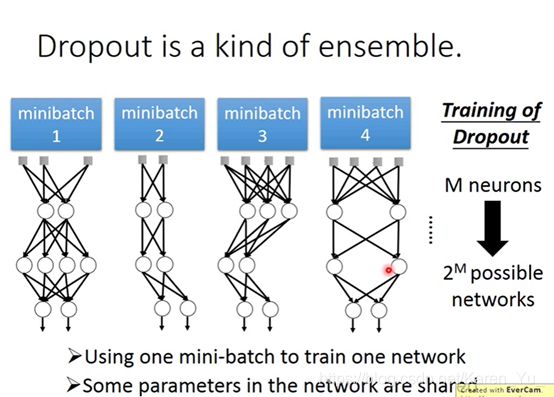
dropout为什么是一种终极的ensemble方法?
在做dropout的时候,我们每次要update参数的时候拿出一个minibatch都会做一次sample(拿第一个、第二个、第三个、第四个……)相当于有2^M个module
因为update的次数是有限的,可能不能把2^M个module都train一遍
(搬弹幕)相当于建立一个随机森林模型
一个structure可能由一个batch来train,但是一个weight可以由好多个batch来train
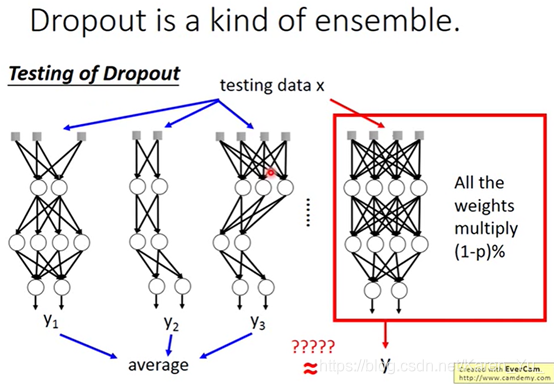
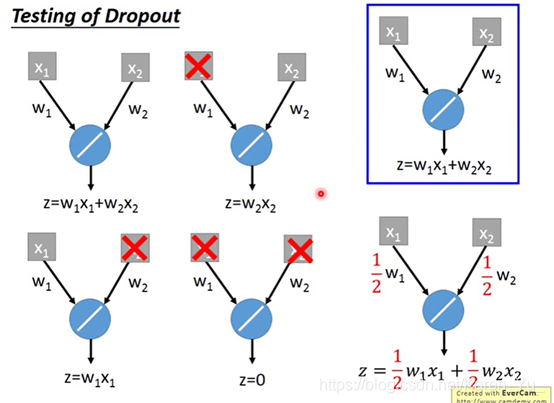
一个neuron 做dropout有四种可能,把四个结果average一下,得到的结果就是½w1x1+½w2x2
原来的neuron的weight直接乘以½就能得到同样的结果
P15 Why Deep Learning
(此处为P12续集内容,请移步P12阅读)
PS. 如果是按顺序看到这里的不需要看返回P12了
以下为P15内容

在语音上为什么要用到模组化的概念?
当我们说一句话的时候,这句话实际上是由遗传phoneme所组成的。
any one of the set of smallest units of speech in a language that distinguish one word from another. In English, the /s/ in sip and the /z/ in zip represent two different phonemes . 音位,音素(区分单词的最小语音单位,英语sip中的s和zip中的z是两个不同的音素)
同样的phoneme可能会有不同的发音(所以会给同样的phoneme不同的module)
一个phoneme的contest不一样就用不同的module表示它
一个tri-phone又可以分成若干个state
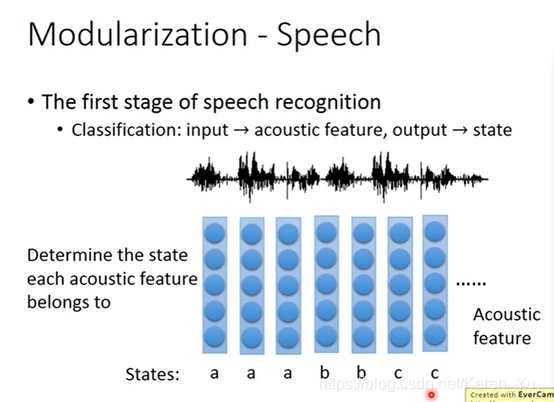
第一步是把acoustic feature(声音信通常是一串,取一个window,通常是250ms,归类到某一个state)
一个window用一个feature来描述它的特性(称acoustic feature)
每隔一小段时间就取一个window
所以一串声音信号就会变成一串vector sequence(acoustic feature sequence)
做语音辨识度第一阶段就是决定每一个acoustic feature属于哪一个state(然后再把state转成phoneme,再把phoneme文字,然后还要考虑同音异字的问题)

对比在用deep learning之前和之后做语音辨识的区别

高斯混合模型
但是一般语言都有特别多的phoneme,contest不同就要用不同的module,所以就有数万个state

传统上,在有deep learning之前,某一些不同的state会共用同样的module distribution(称为tied-state)
具体哪些要共用,哪些不要需要经验或者语言学的知识
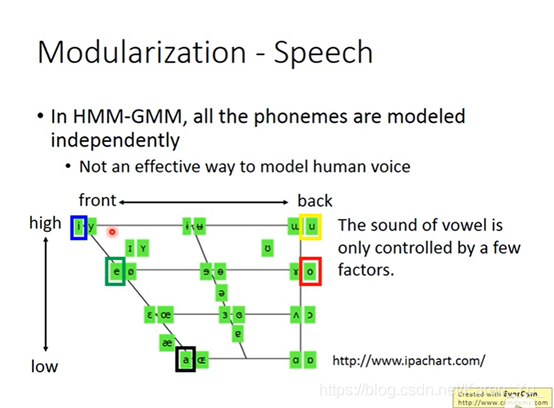
舌头的位置&嘴型
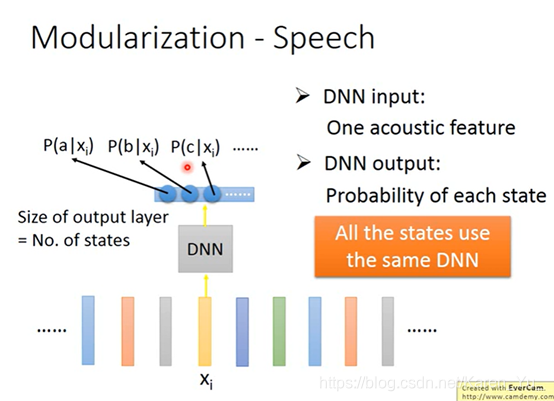
DNN只用一个很大的module,但是GNN用很多很小的module(但是参数的个数是差不多的)
(搬弹幕)现在语音识别叫ASR,都是由acoustic module+language module组成
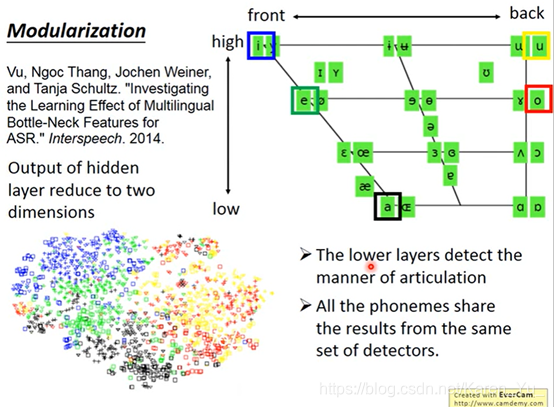
降维
(搬弹幕)就是在DNN某个隐层后面的输出减成二维(x,y)把这个数据化成坐标可视化输出
(搬弹幕)前面说深度学习的优势在于模组化,本来是将state分类但是现在并不直接处理分类结果,而是观察人类发音位置
(搬弹幕)可以这么理解吧,好的DNN算出来的模型,第一层能够表达我们未曾注意到的特征
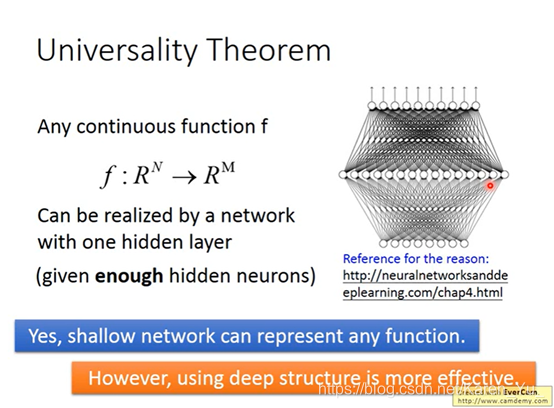
理论上,任何continuous function都可以用一层neuron network来完成,只要那一层neuron network够宽的话
(搬弹幕)刚才其实是在讲DNN经过训练后的每一个中间层都变成了一个分类模块,并且这种自动行程的分类模块与刚才讲的人类发现的按照舌头高低和嘴型来分类的方法一致。即机器学会了人类的分类方法。
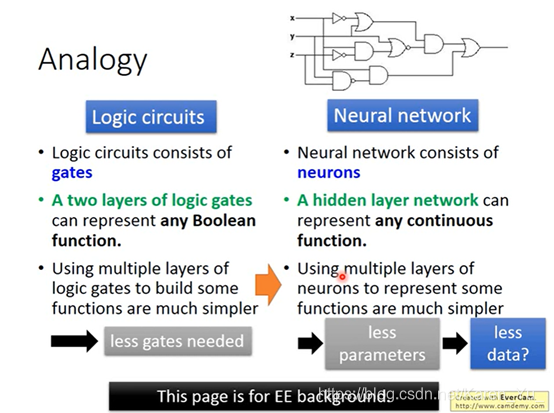
(搬弹幕)function set相同的情况下,层数越多,所需要的神经元越少,效率越高。而因为function set相同,所以准确率也相同。
//EE狂喜
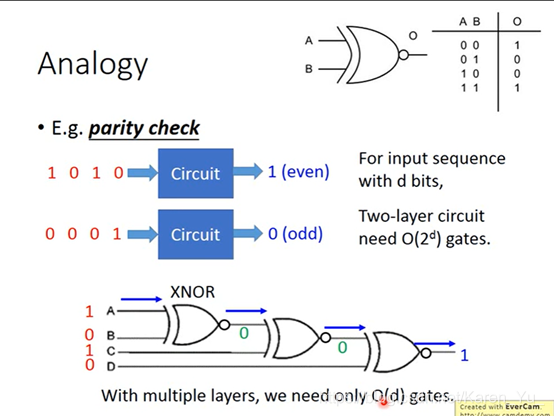
e.g.2:假如我们要设计一个parity check电路(奇偶校验)
一串数字,如果里面1的个数是偶数,output就是1,如果1的个数是奇数,output就是0
假设input的sequence总共是d bits,需要2^d个gate才能描述。但是如果用多层次的架构的话,用比较少的逻辑闸就可以做到。
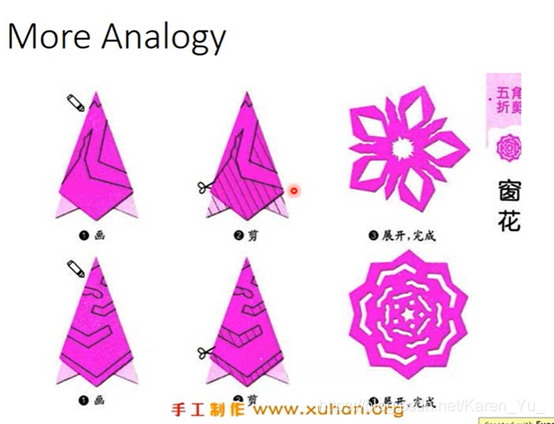
(搬弹幕)多折几次,少剪好多刀
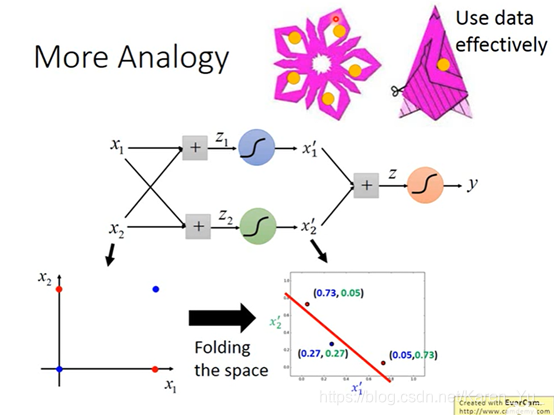
(搬弹幕)空间折叠
(搬弹幕)神经网络做的本质就是超高维度线性变换

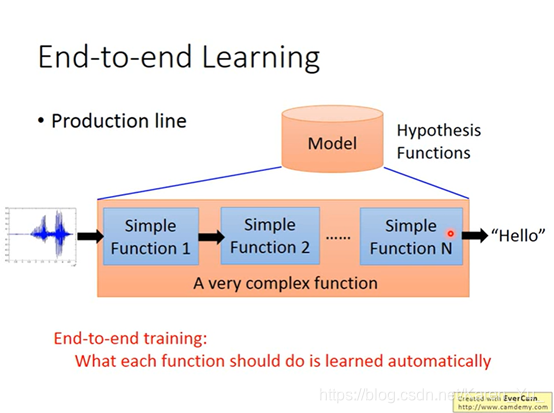
end-to-end learning是只提供输入和输出,让机器自己学
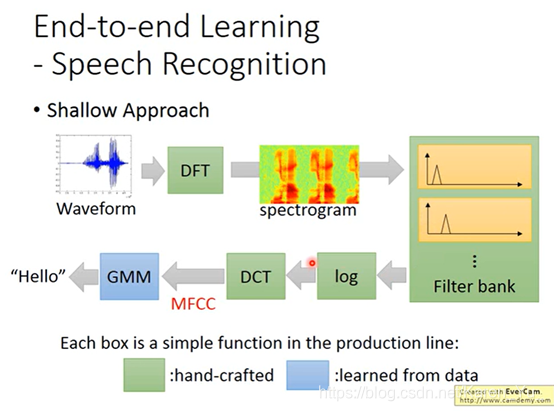
(deep learning之前)只有GNN是让机器自己学的,其他的都是之前确定下来的函数
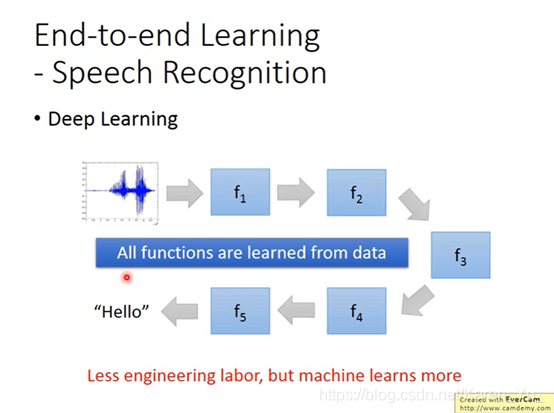
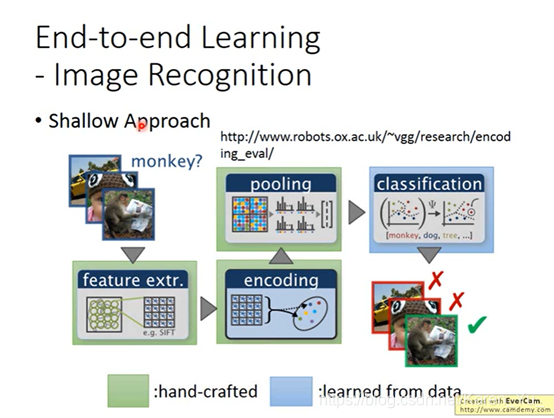
(来听课学习的初衷2333)

(搬弹幕)end-to-end方式学的效果比传统复杂方法准确率更高


不同的颜色代表的是不同的人说的话,但是这些人说的句子是一样的。
一样的句子,不同的人说,生声音信号看起来是非常不同的→经过很多层之后看到不同的句子被连到了一起(像了)

e.g.手写数字
把看起来很像的数字分开


P16 PyTorch Tutorial
(助教课,声音有点小,过年回家用外放再学)
P17 Convolutional Neural Network

CNN(卷积神经网络,Convolutional Neural Network)经常用于影像处理(一般都neural network当然也可以用来做影像处理)
第一层neuron是最简单的classify做的是detect,比如说,有没有绿色出现,有没有黄色出现,有没有斜的条纹
第二层做的是更复杂的东西……
假设是一张100×100的彩色图片,就有100×100×3个pixel(一个很长很长的vector)→太多了(所以不需要用fully connected network)

第一层是检查某些pattern有没有出现,但是很多pattern比整张image小。所以看某个pattern是否出现不需要看整个image,只要看image的一小部分就可以决定。

同样的pattern可能出现在image的不同的位置,但是代表的是同样的含义。
侦测左上角有没有鸟嘴的neuron和侦测中间有没有鸟嘴的neuron做的事是一样的(所以不需要两个→共用参数→减少使用参数的量)。
(搬弹幕)局部特征,权值共享
(搬弹幕)“如果一个东西看起来像鸭子,叫起来像鸭子,走起来也像鸭子,那完全就可以认定它是鸭子”

可以对一个image做subsampling(把一张image的奇数行偶数列的pixel拿掉,变成原来十分之一的大小),其实不会影响人对这张image的理解。所以可以这样把image变小,减少要使用的参数。
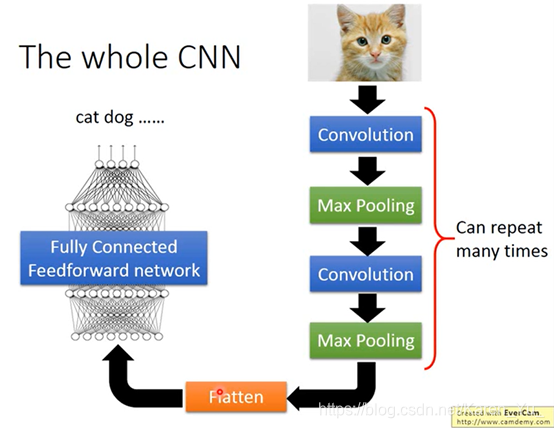
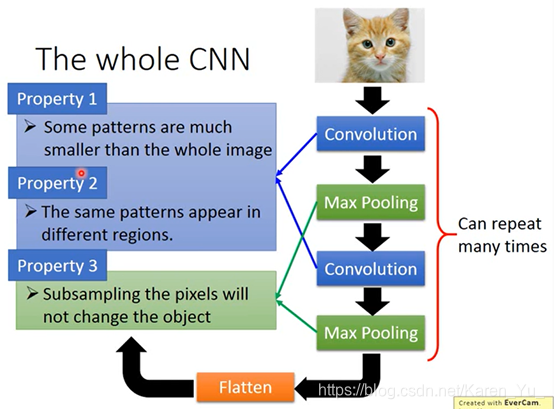
convolution和Max Pooling反复做几次(几次需要自己提前决定,就像network有几层也要提前决定)

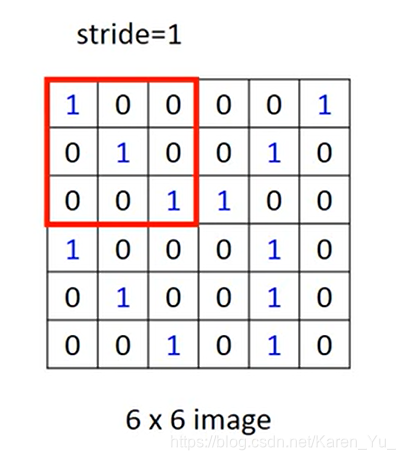
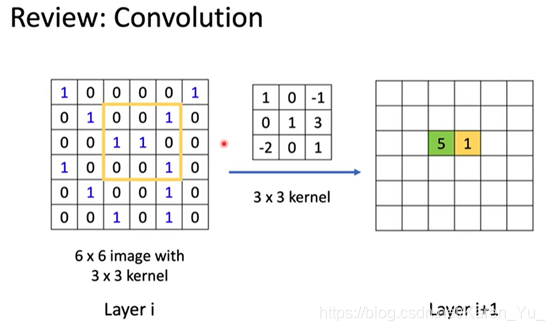
假设有一个6×6的image、黑白的(每个pixel只要用一个value0/1表示)
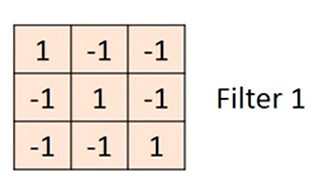
这些filter里面的参数就是network的parameter(就像weight和bias一样),是学出来的
把一个filter放在image的左上角,把这框住的值和filter做内积:
1×1+1×1+1×1=3
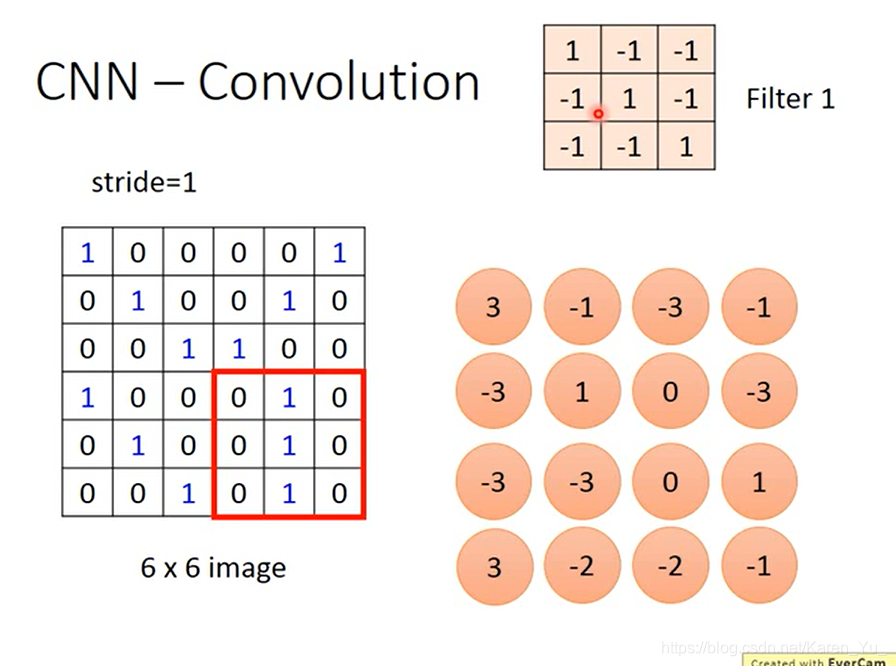
然后再挪动filter的位置(具体挪多少要事先决定),挪动的距离叫做stride(此处取stride=1)
这样本来是一个6×6的metrix,经过convolution之后就得到一个4×4的metrix
这里用的filter:
1 -1 -1
-1 1 -1
-1 -1 1
就是detect在这张image里面有没有左上到右下的1出现
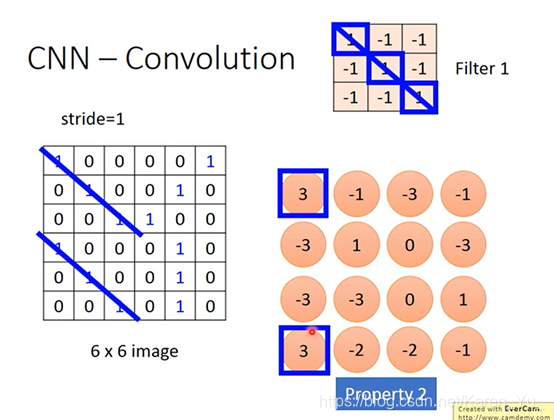
测出来的在这张图片的左上角和左下角出现3(最大值)
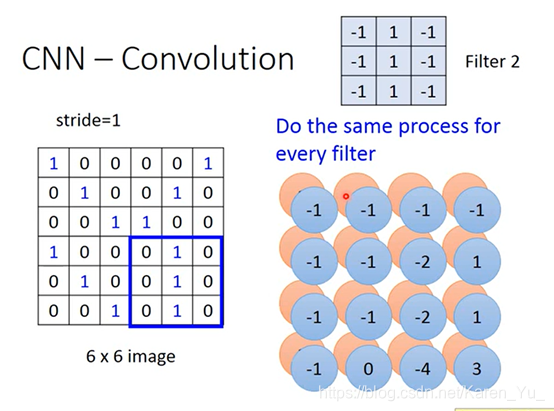
也会有其他的filter做类似的事
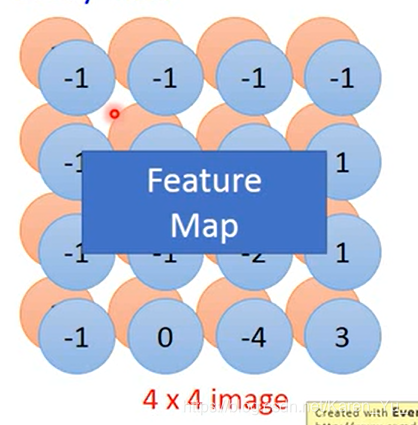
看有多少个filter,就会出现多少个feature map
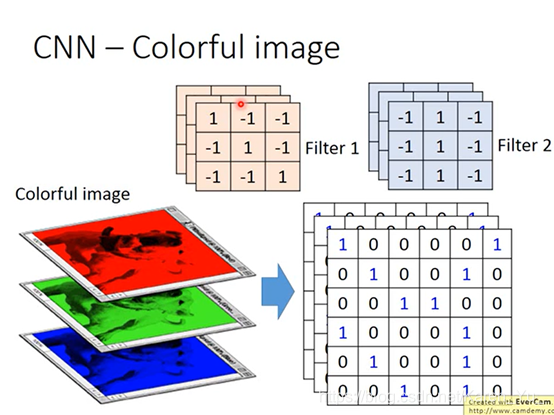
如果要处理一张彩色的image(好几张黑白的image叠在一起)
这时filter就不是一个metrix,也是一个立方体
如果用RGB表示一个pixel的话,一张image是3×6×6,那么filter就是3×3×3
做convolution就是把filter里面的9个值和image里面的9个值做内积(并不是把每一个channel分开算→并非RGB分开算,而是合在一起算)
(搬弹幕)channel,颜色通道
(搬弹幕)内积越大越符合该filter的特征
(搬弹幕)filter三个通道的参数不同,分别卷积后求和得到一个通道
(搬弹幕)这个filter类似于一个方向,如果内积大,说明方向近似
(搬弹幕)卷积的值大意味着和pattern相似,所以是feature
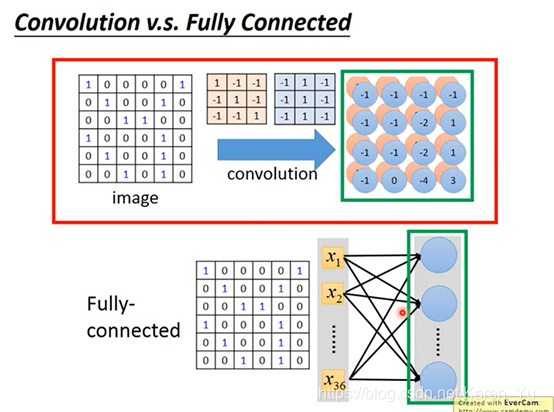
convolution和fully-connected有什么关系?
convolution其实就是fully-connnected的layer把一些weight拿掉
(feature map的output其实就是一个hidden layer的neuron的output)
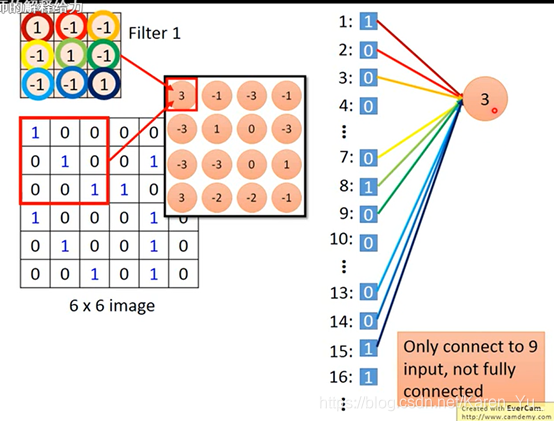
举个例子,如果我们把metrix拉直的话,红色框出来的地方对应的是1、2、3、7、8、9、13、14、15→就相当于是有一个neuron,这个neuron的weight就只有1、2、3、7、8、9、13、14、15和它连接。
这个neuron的9个weight就是filter的metrix里的9个weight
本来要连接36个input,但是这里只要连接9个input就可以了→ less parameter
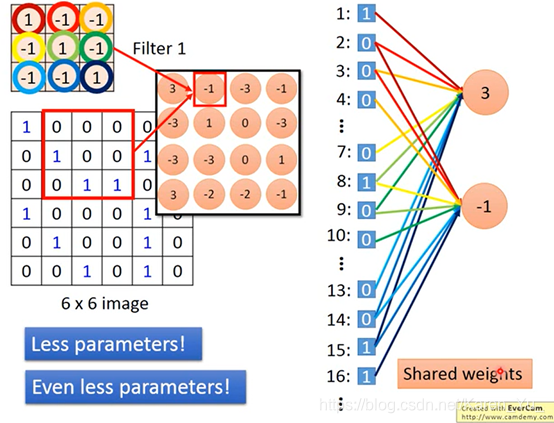
再向右移动一格就能得到2、3、4、8、9、10、14、15、16
这样做就可以使这两个neuron并不是拥有独立自己的weight,共用同一组weight
(搬弹幕)局部相关性和权值共享
↓
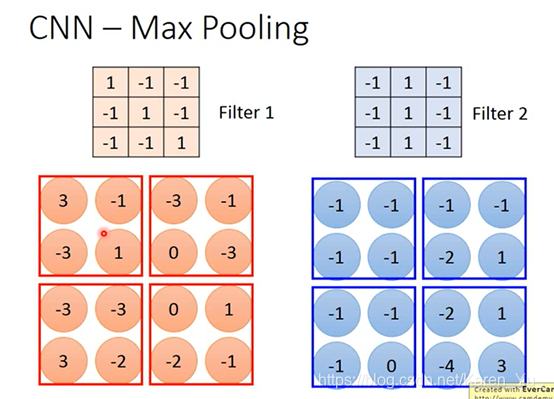
根据filter1得到一个4×4的metrix,根据filter2得到另一个4×4的metrix
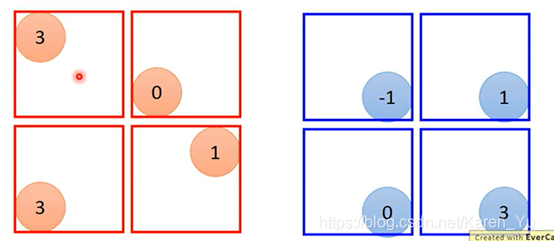
把output四个一组四个一组,每一组里面可以选他们都平均,也可以选他们的最大(把原来的四个value合成一个value)
假设我们每个里面都选最大的保留下来
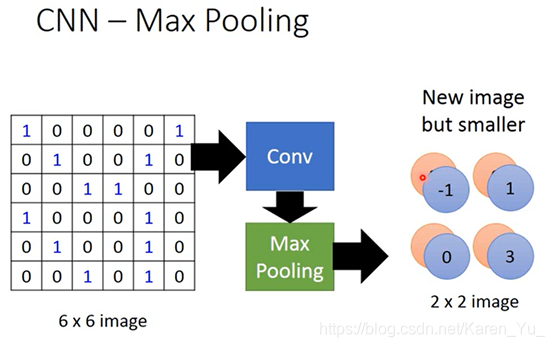
此时我们就把6×6的image变成一个2×2的image
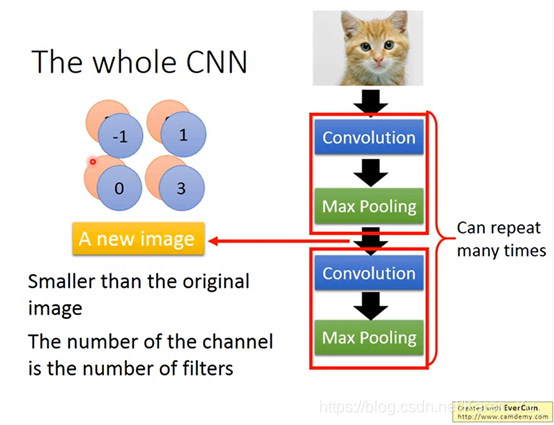
(搬弹幕)输入层指图像通道数,中间层则指feature map的层数
(搬弹幕)feature map深度和filter深度一致,然后对应层卷积
并非每一个channel分开考虑,是一次考虑所有的channel,所以convolution有多少个filter,output就有多少个filter。只是每一个filter都是一个cubic
(搬弹幕)僵尸相当于升维拉,但数量不变
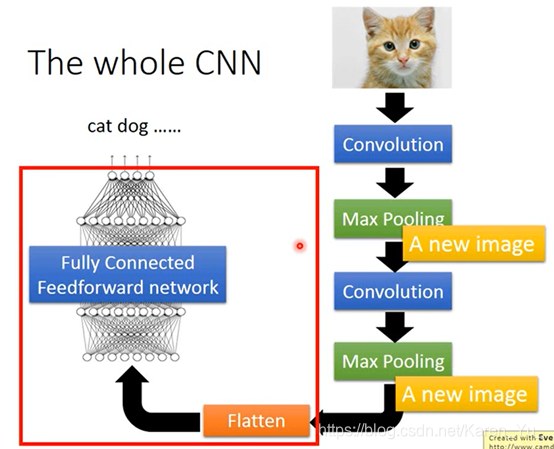
最后一步操作flatten:
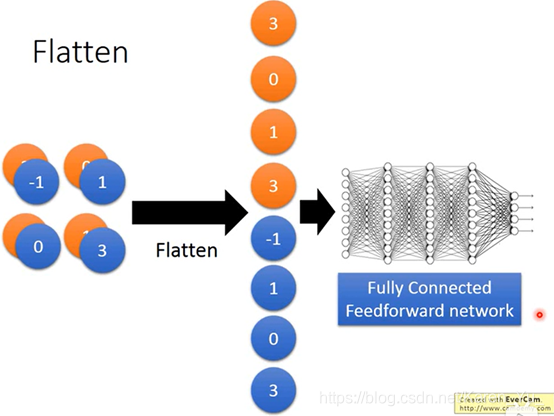
就是把之前得到的拉直,丢到fully connected network里就可以了
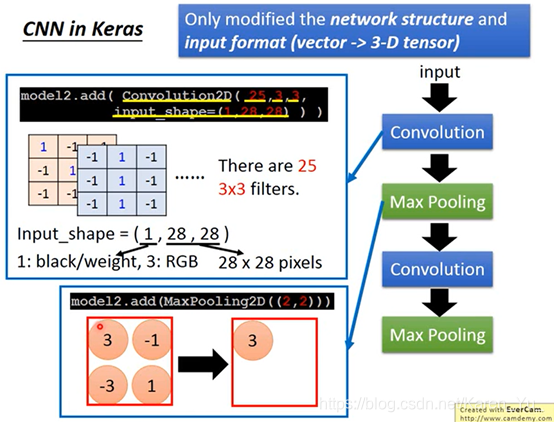
怎么样可让keras来implement CNN?
在compile和fitting的部分一模一样,只要改一下network structure和input format
本来在DNN里面input是一个vector,CNN是会考虑这个input的image的几何空间的,所以不能input给它一个vector(要一个tensor→就是一个高维的vector→三维的vector)
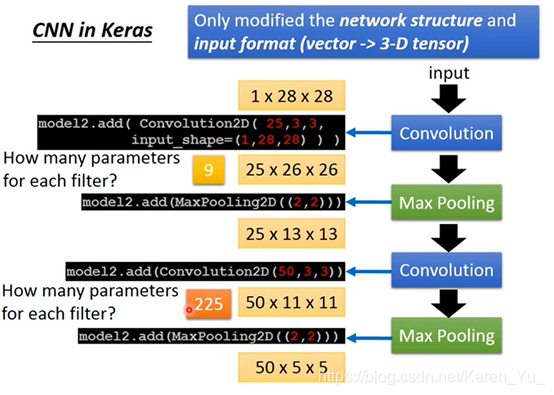
26:(n-m+1) 28-3+1
11=13-3+1
(搬弹幕)填充边缘部分,使得stride为1,采样feature map大小不变
5:池化操作多的一行或者一列直接删掉
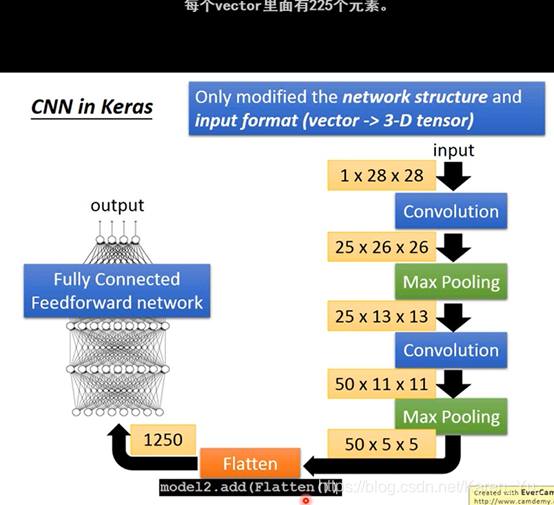
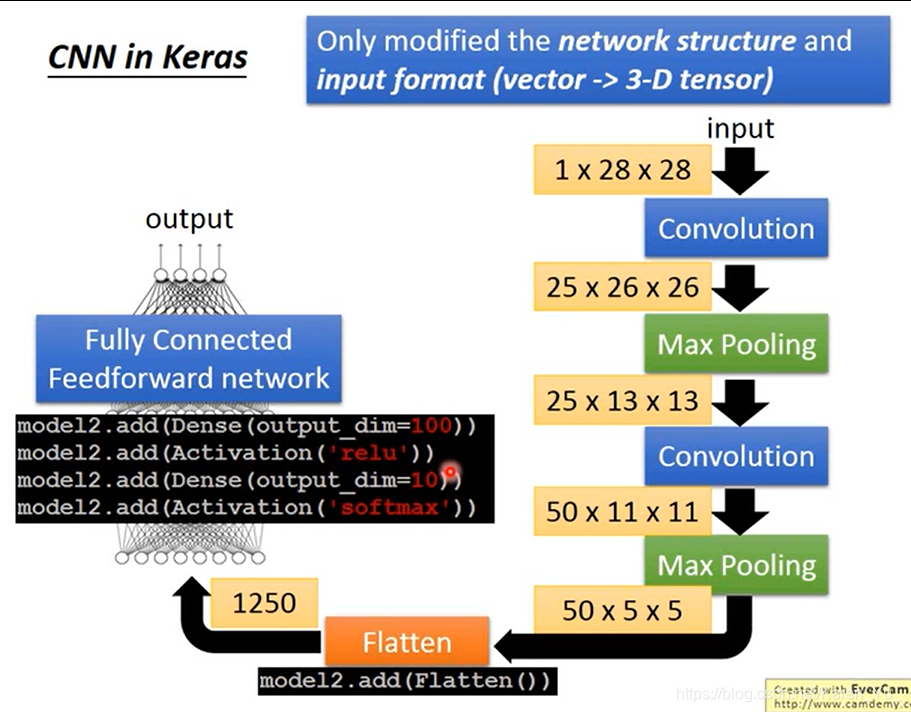
拉直
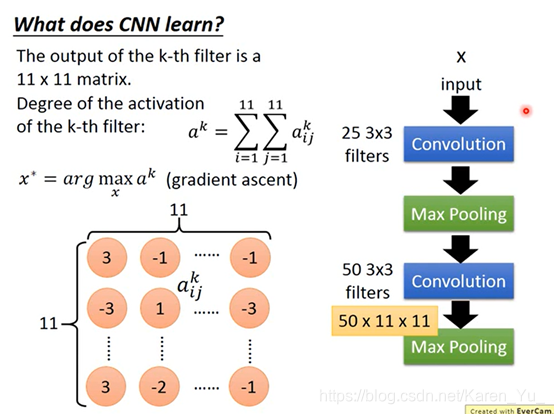
↓
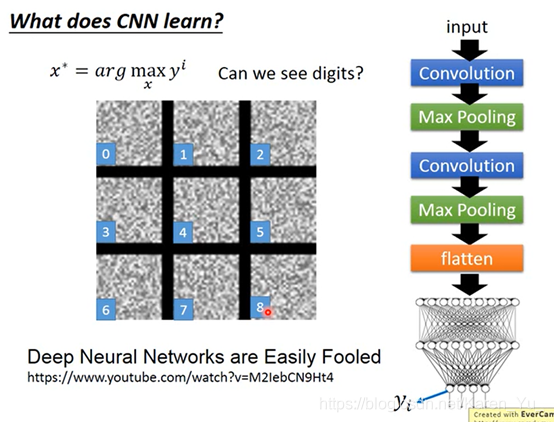
module的参数是固定的,要让gradient decent去update x,让degree function最大
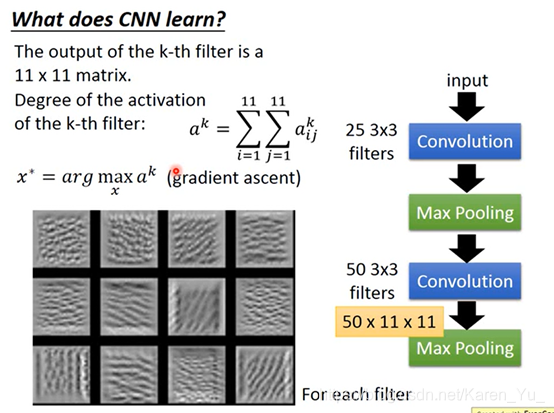
(搬弹幕)看输出特征最大的,通过观察这个input就可以知道filter长啥样子(或者说对什么图形特征最敏感)
(搬弹幕)通过梯度上升可以找到让filter激活值最大的input
(搬弹幕)每个卷积核对应某一个特征,满足这个特征就让这个卷积核activation最大……
(搬弹幕)这里就是AB输入端当未知数,然后通过训练好的模型,从filter开始往回推,能推断出filter学习到了什么图形
p.s.有个弹幕笑死我了——我只对你有感觉


(搬弹幕)这里在试图乐姐一个训练过的网络实际对图像的什么更敏感

↓

把照片丢到CNN里,把某一个hidden layer的output拿出来(是一个vector)
把positive的值调大,negative的值调小(正的更正,负的更负)→让CNN夸大它看到的东西

↓

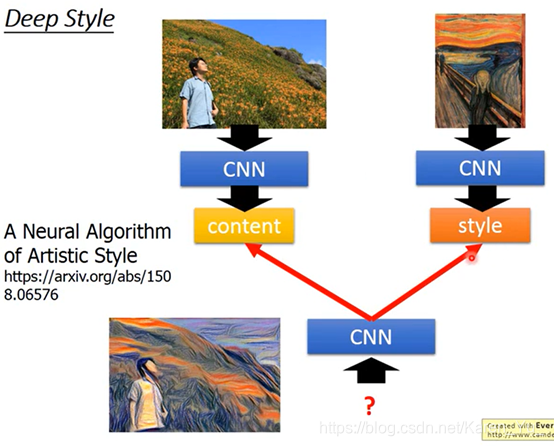
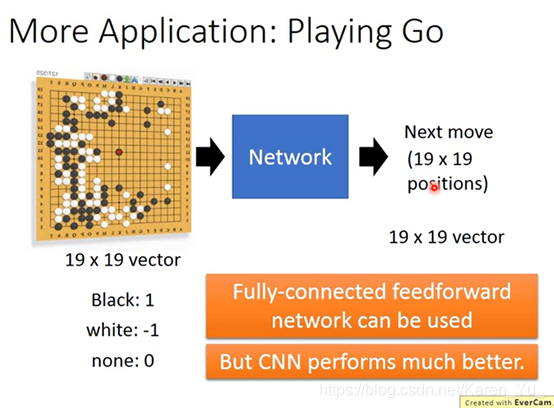
其他运用,下围棋

CNN看作一个matrix
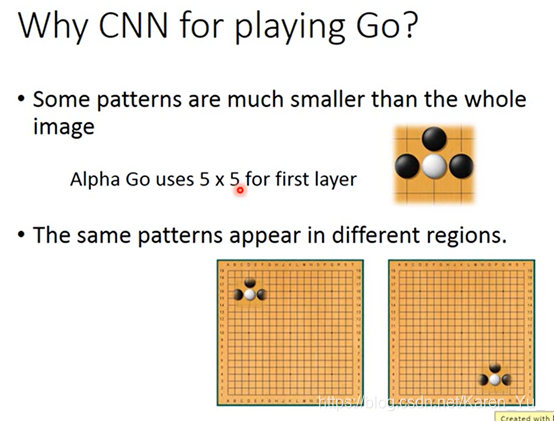
什么时候可以用CNN:要有image的特性,可以用在围棋上是因为围棋的某些特性和影像处理很类似的:


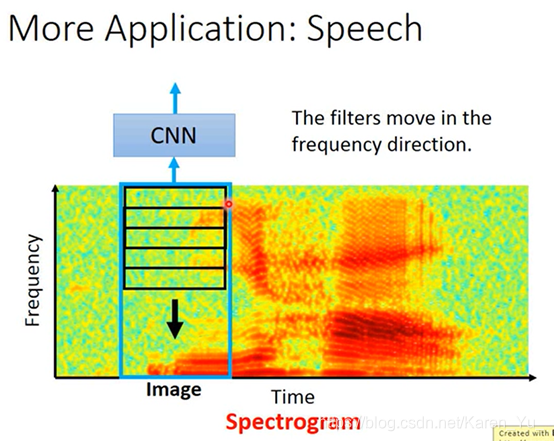
其他应用,红色代表在这一段时间以内,这一个情侣的energy是比较大的
也可以把里面一段看成image,然后丢到CNN里。
在time方向上的移动并没有什么帮助,虽然男生和女生说话的frequency会不一样,但是图画只是做了平移而已
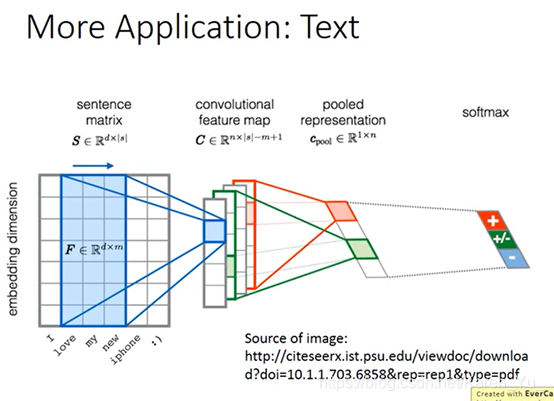
其他应用,文字处理
每一个word都用一个vector来表示
如果两个word的含义越接近,他们都vector在高维空间上就越接近
filter沿着句子的顺序移动(只在时间方向上移动)

reference
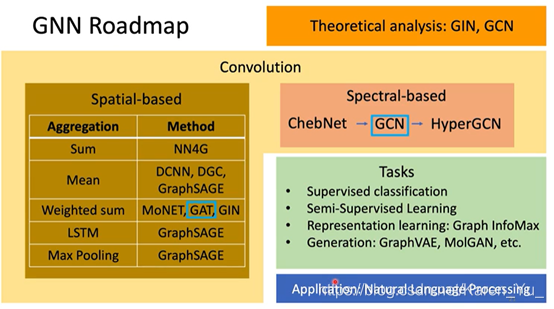
P18 Graph Neural Network(1_2)(选学)
(本来助教课是打算先跳过的,但是这个声音太有磁性了,声控狂喜)
graph+neural network
RB tree,是一种特殊的graph
此处介绍图
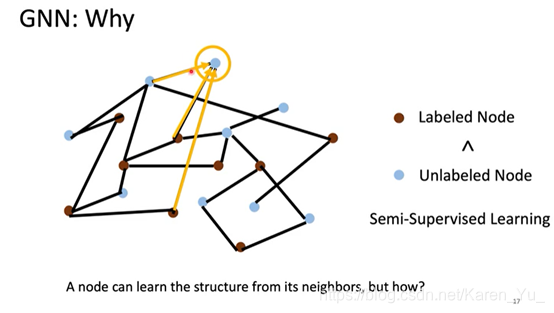
那么怎么将图塞进neural network里呢


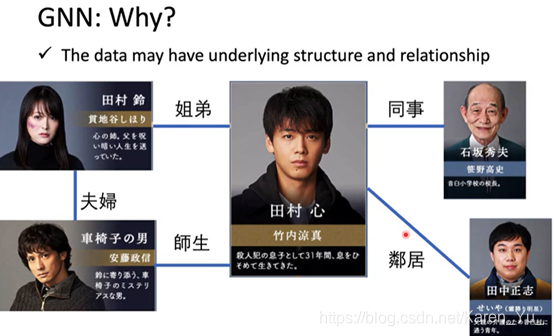
GNN的应用
(搬弹幕)在频域上对信号和滤波器做相乘,就可以得到原信号经过滤波器做卷积后的信号
(搬弹幕)在时域上做卷积相当于在频域上做乘法
(搬弹幕)空间域和频率域滤波
(搬弹幕)基于空间域的卷积和基于频率域的卷积


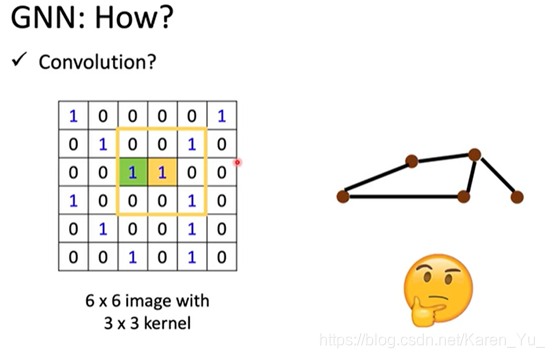
(搬弹幕)图中节点与边的构造是比较随意的,要根据实际情况来构建
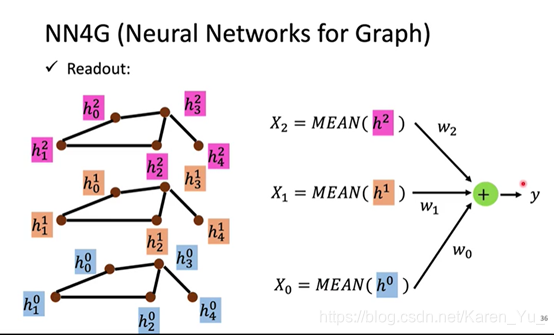
(搬弹幕)MN4G和其他模型一样,各种看似“随便”的操作都是为了实现非线性的拟合。
——————————————不行,听不懂了2333——————————
P19 Graph Neural Network(2_2)(选学)
和P18一起补了
P20 Recurrent Neural Network (Part I)
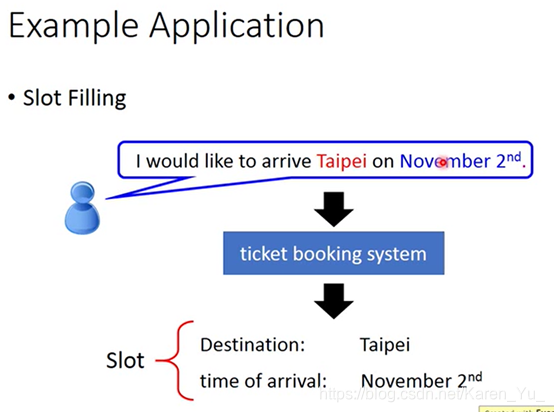
系统要自动知道每一个词汇属于哪一个slot
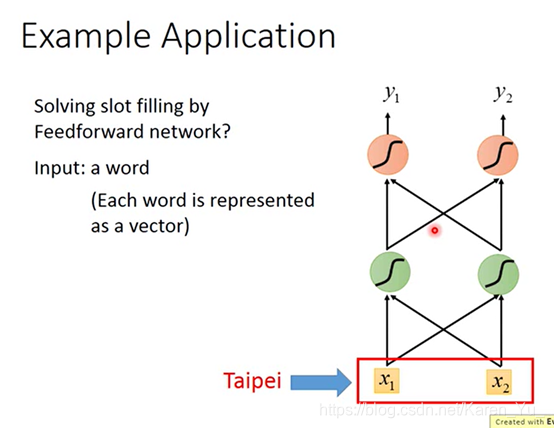
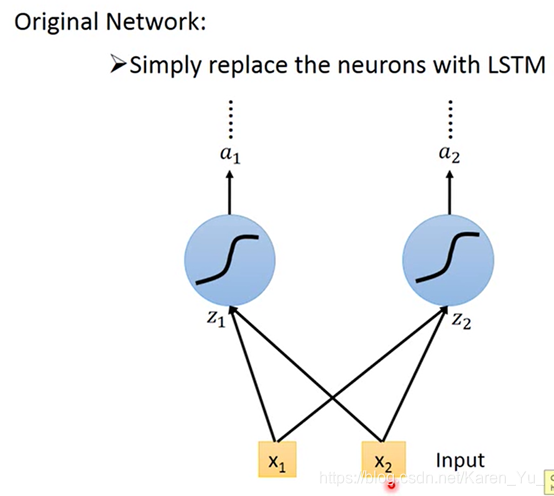
可以你用一个feedforward neural network来解。
叠一个feedforward neural network,input是一个词汇(比如说taipei),把词汇变成vector,丢到neural network里面去

怎么把词汇变成vector呢?最简单的方法就是1-of-N encoding
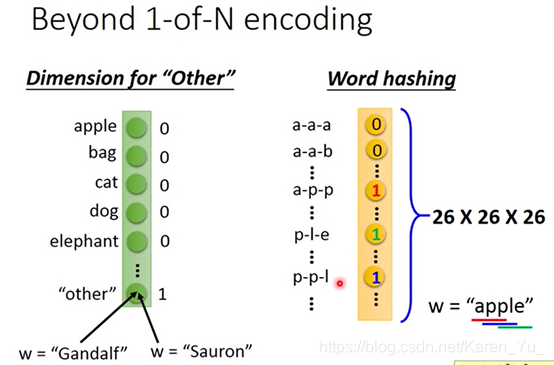
有时候只是用1-of-N encoding来描述一个词的话,会遇到一些问题,因为有很多词汇可能从来都没有见过。所以会需要在1-of-N encoding里面加一个dimension——“other”。那么所有不是在我们词典里的词汇就会归类到“other”中
也可以用某个词汇的字母来表示他的vector(这样就不会出现某个词汇没有出现在词典中的问题)
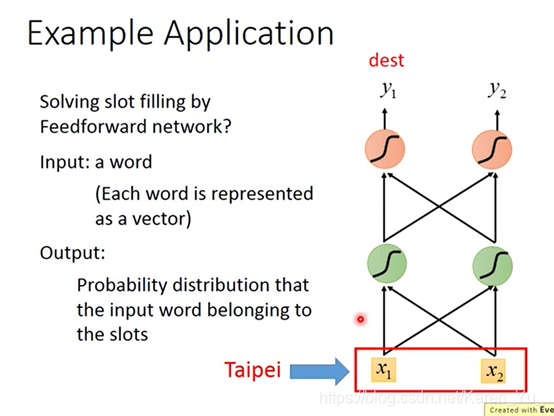
假设我们已经把一个词汇转换成一个vector了,这时候就可以把这个vector丢到feedforward neural network里面去,这时候就希望output是一个probability distribution。这个probability distribution代表input的词汇属于一个slot的几率(比如“taipei”属于destination和time of arriving的机率)。
(搬弹幕)slot除了指水槽之类的槽或储钱罐的投币口外,还可以指一个时段,这里应该是指每个时段,就是网络每循环一次
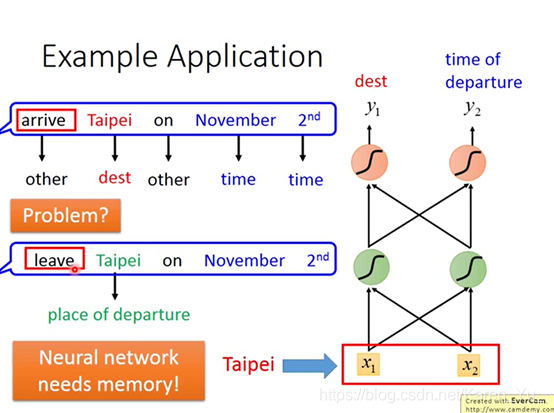
但是光这样是不够的,因为feedforward network没办法解决这个问题。why?
到达、离开的时候taipei代表的一个是目的地,一个是出发地。但是input一样的东西,那么output也是一样的,要不然就是出发地的概率最高,要不然就是目的地的概率最高,没办法让有时候出发地的概率高,有时候目的地的概率高。这个时候我们就希望neural network是有记忆的(这样它就记得它在看到红色的taipei之前就看到了arrive,在看到绿色的taipei之前就看到了leave),就可以根据一句话都上下文产生不同的output。
(搬弹幕)semantic slot filling——理解一段文字的一种方法是标记那些对句子有意义的单词或记号(slot)。在自然语言处理领域,这个问题被称为语意槽填充
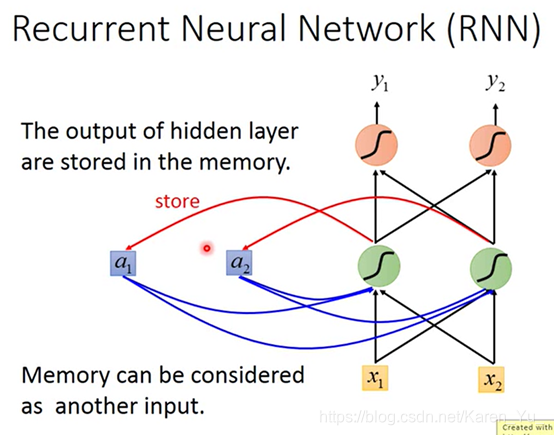
这种有记忆的network就称为recurrent neural network(RNN)
每一次hidden layer里的neuron产生output的时候,这个output都会被存到memory里面去。下一次当有input的时候,这些neuron不是只会考虑input的x1和x2,还会考虑存在memory里面的值
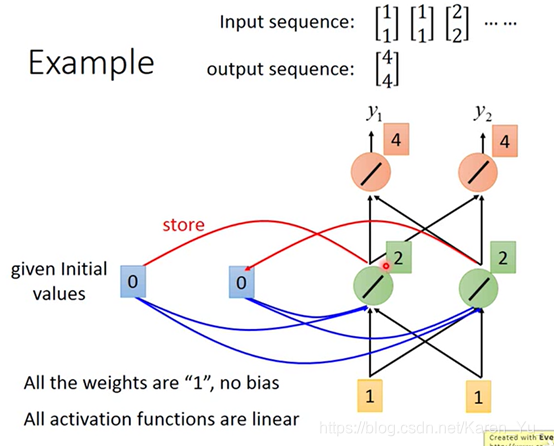
假设如图的network所有的weight都是1,没有任何bias,假设所有的activation function都是线性的。
假设我们的input是一个sequence
那么这个sequence input到这个neural network里去会发生什么事呢?
首先在要开始使用这个recurrent neural network的时候,必须要给memory起始值(在还没有放东西之前,里面的值是0)
现在输入第一个输入——1 1
对于绿色的neuron来说,它除了接收到input的1和1之外,还接受到memory里的0和0.因为所有的weight都是1,所以绿色neuron的output是2和2.因为所有的weight都是1,所以橙色的neuron理所当然output就是4和4,同事绿色的neuron输出的2也会被写入memory里面,memory里的0和0就变成了2和2.
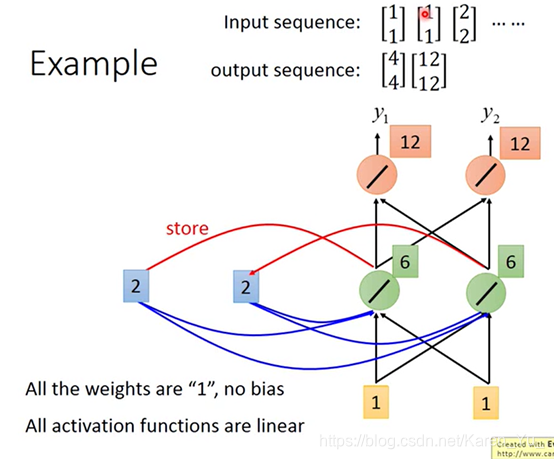
接下来再输入1和1。
这时候绿色的neuron的输入有四个,(来自input的)1和1,(来自memory的)2和2,因此得到的结果就是6和6(1+2+1+2=6)
最后红色的neuron的output就是12和12(6+6=12)
所以就算输入的都是1和1,输出也可能是不一样的,因为存在memory里面的值是不一样的。
绿色neuron输出的6和6接下来就会被存到memory里面去

接下来的input是2和2,此时绿色neuron的output是16和16(2+6+2+6=16)
红色的neuron的output就是32和32
要注意调整input顺序会导致output也不相同(比如把2和2调整到前面会导致输出也完全不一样了)
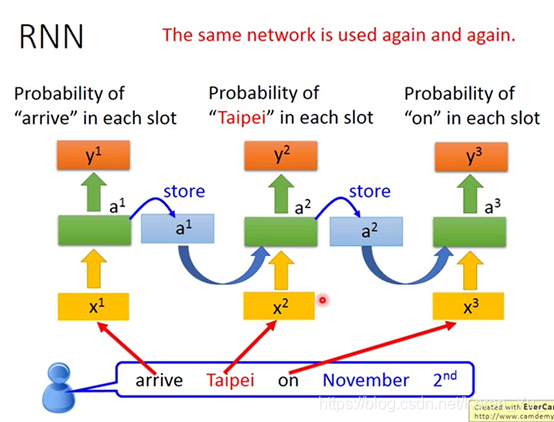
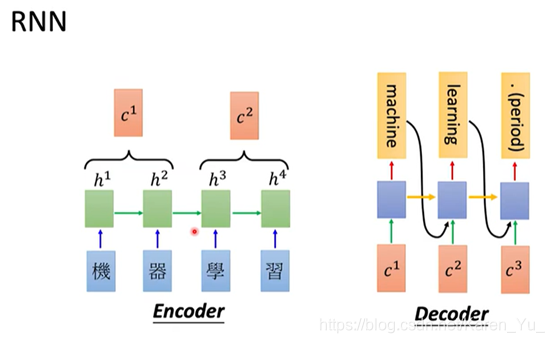
带入刚刚到例子,就相当于,arrive变成要给vector,丢到neuron network里面去。(绿色的是hidden layer),y1就是arrive属于某一个slot的机率。接下来a1会被存到memory里面去。
Taipei变成input,此时hidden layer会同时考虑这个input(x2,Taipei)和存在memory里面的a1,得到a2,在根据a2得到y2(Taipei属于某一个slot的几率)。再把a2丢到memory里面去。
此时on变成input,hiddenlayer同事考虑x3(on)和memory里的a2(Taipei)得到a3,再得到y3
……
要注意这是同一个network在不同的三个时间点被使用了三次。
同样的weight用同样的颜色来表示
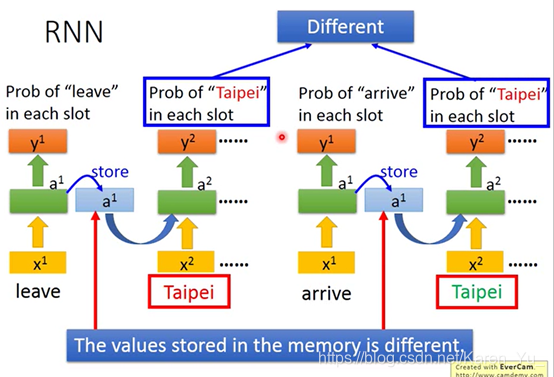
因为leave和arrive的vector不一样,所以他们都output也不同
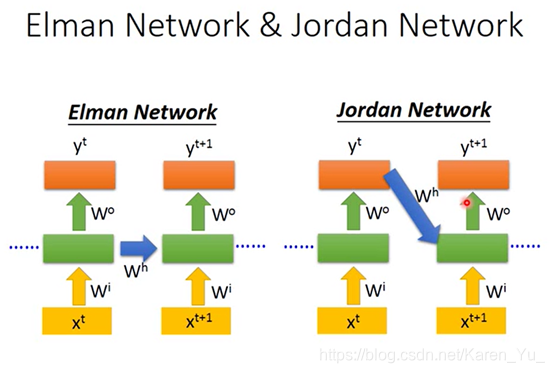
有另一种Jordan Network,存的是output的值,据说perfomance不错

RRN也可以是双向的,可以xt→xt+1→xt+2也可以是xt+2→xt+1→xt.
可以同事train一个正向train一个反向的,然后把他们都hidden layer拿出来都接给output,得到最后的y
好处是在产生network的时候看到范围是比较广的。
如果只有正向的network,在产生yt、yt+1、yt+2……的时候,就只看过x1、x2……xt+1的input。如果是bidirectional RNN就不止看过从句首到xt,还看过了从句尾到xt(等于是看了整个的input,sentence),这样会比只看了句子的一半要得到更好的performance。
(搬弹幕)正向时序和反向时序,这是一个时间钳形运动
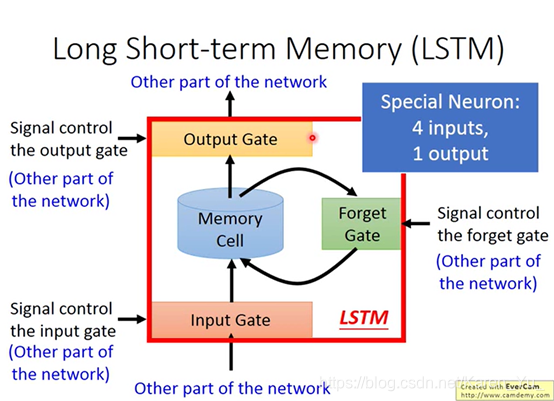
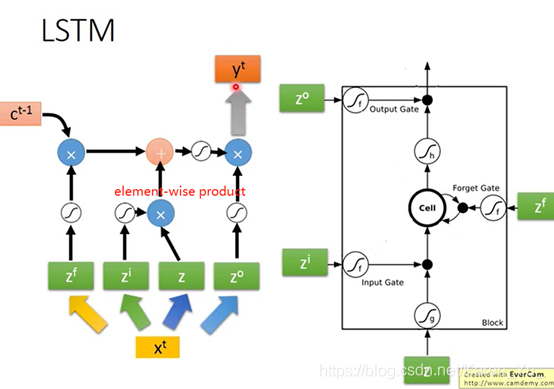
目前常用的memory是Long Short-term Memory(LSTM)
LSTM有三个gate,当neural network的output想被写到memory里的时候,必须先通过要给闸门(input gate),只有input gate打开的时候才能把数据写到memory cell里去。当input gate关上灯时候,其他neuron就没法把值写进去。
input gate是打开还是关闭是neural network自己学。
输出的地方也有一个output gate,决定外界可不可以从memory里面把值读出来(output gate关闭的时候值是没办法读出来的)。
类似input gate,output gate什么时候打开,什么时候关闭也是network自己学的。
forget gate是决定memory什么时候要把过去记得的memory忘掉。
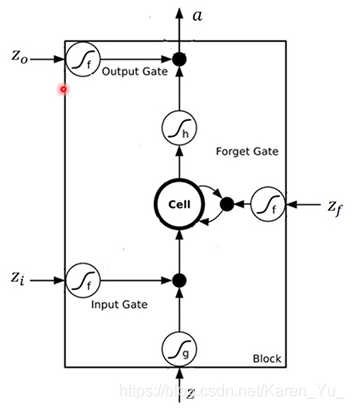
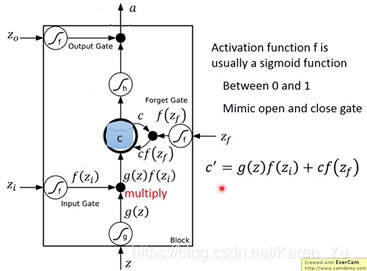
整个memory cell可以看成是有四个input(想要被存到memory cell里面的词 ‘但是不一定能被存进去’、操控input gate的信号、操控output的信号、操控forget gate的信号)和一个output。
冷知识,这其实还是一个short-term memory,只要有新的input进来都会把之前的信息洗掉
 →
→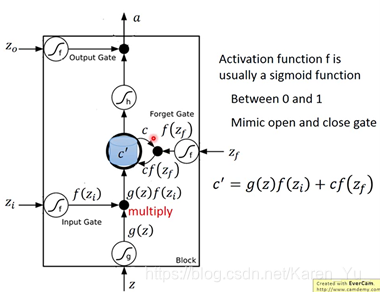
注意forget gate打开的时候代表的是记得,关闭的时候代表的是遗忘
(搬弹幕)这里forget gate应该是一个连续函数,可以用记忆程度来理解
(搬弹幕)数值越大,原来的memory被记住的程度越高
(搬弹幕)记忆门激活函数是sigmoid

举例:
假如在network里面只有一个LSTM都cell,input都是三维的vector,output都是一维的vector
假设当x2=1的时候,x1会被写到memory里面去
x2=-1的时候,memory就会被reset(遗忘)
都指下一个时间点
当x3=1的时候,output会被打开,才能够看到输出
假设原来存在memory里面的值是0
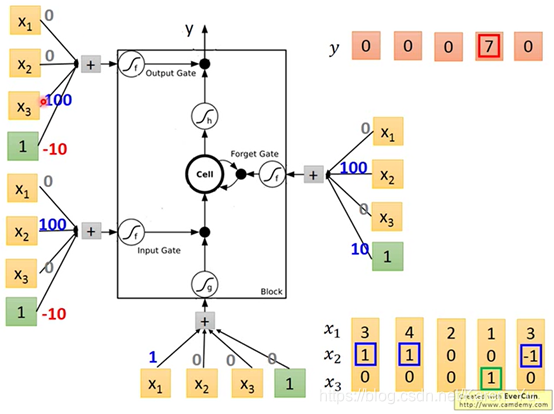
绿色是bias
input gate只有x2有值的时候,就会比bias的值要大
forget gate平常都是被打开的(bias是10=1×10),只有x2给一个很大的负值的时候才会把bias压下去,把forget gate关上
output gate平常也是被关闭的(bias是一个很大的负值 -1×10=-10),但是只要x3有一个恒大的正值的时候就会压过bias,把output打开。
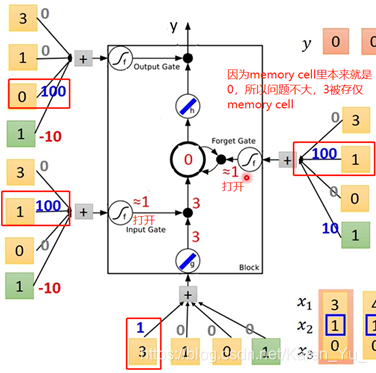
假设先输入 3 1 0,现在没办法输出
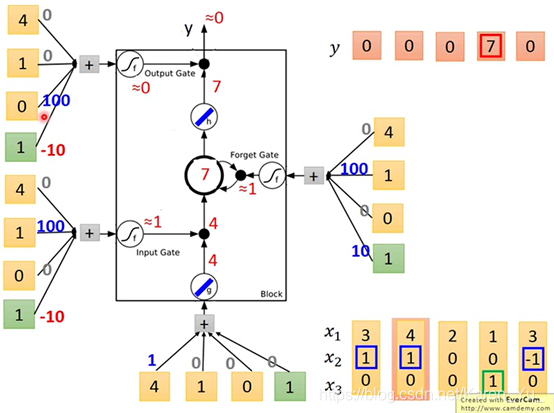
再输入4 1 0
3×1+4=7
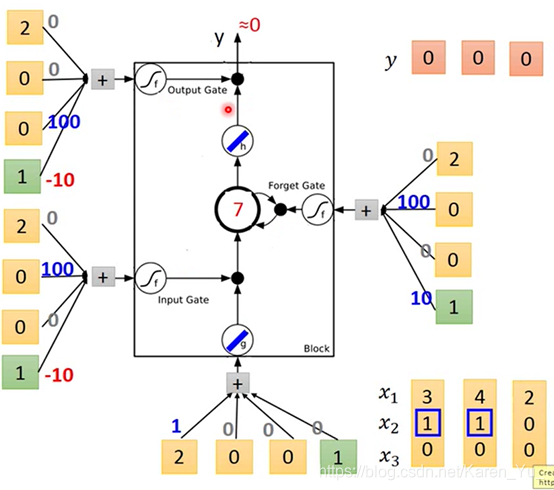
input 2 0 0
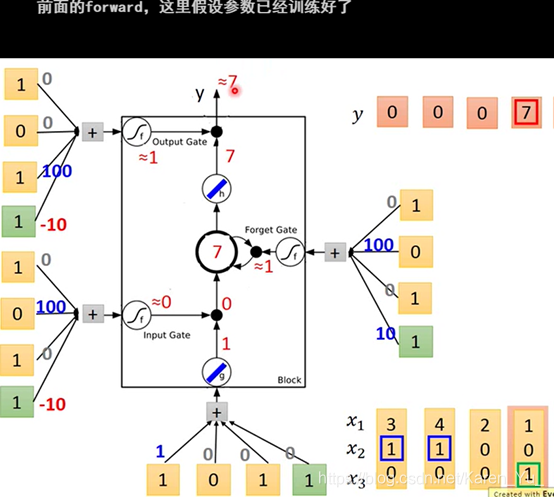
input 1 0 1
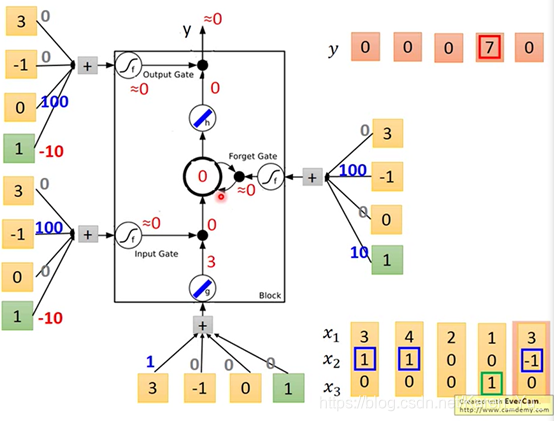
input 3 -1 0,memory里面的值被洗掉,output好事关上灯
(搬弹幕)最开始随机初始化,然后给网络训练数据,调整这些权重参数。这里假设训练结束了,参数已经训练好了。
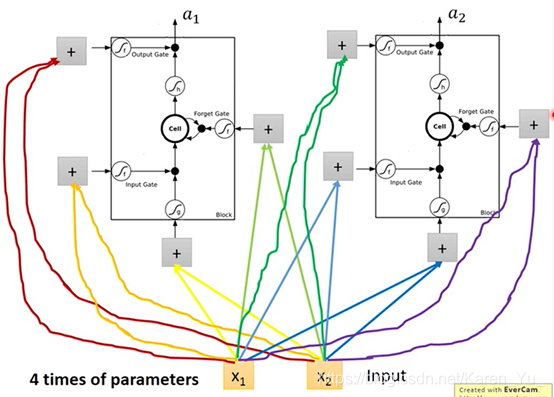
老师举例,就像有点机器插一个电源线就可以跑,有的机器插四个电源线才可以跑(这四个input是不一样的)
→LSTM需要的参数两是一般都neural network的四倍
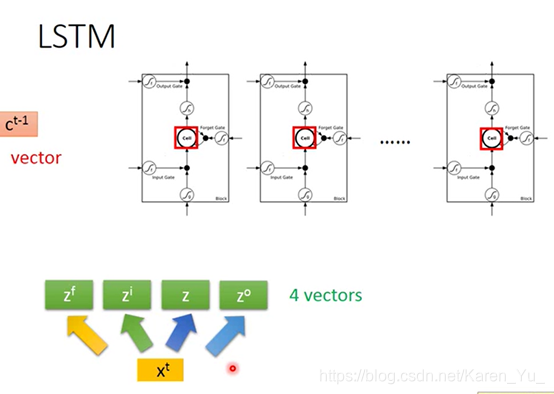
假设现在有一整排的LSTM,每一个cell里都存了一个值。把这些值接起来就形成了一个vector
z也是一个vector,z的每一个dimension代表操控每一个LSTM的input。所以z都dimension的数目就是LSTM的memory cell的数目。(第一维就丢给第一个cell,第二维就丢给第二个cell……)
这四个vector的dimension都和cell的数目一样
(搬弹幕)z是句子向量,一个对应一个cell
(搬弹幕)z是xt乘以一个矩阵的结果
(搬弹幕)z=Ax,A是矩阵,也就是一个线性变换
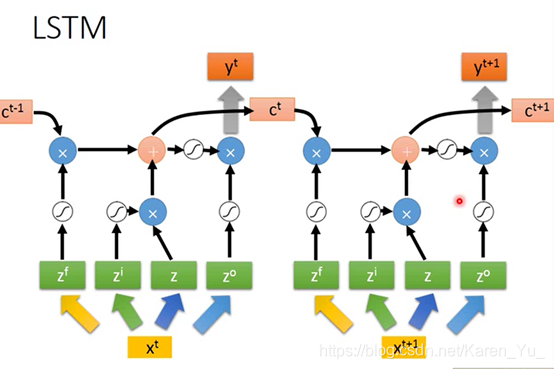
simplify版本
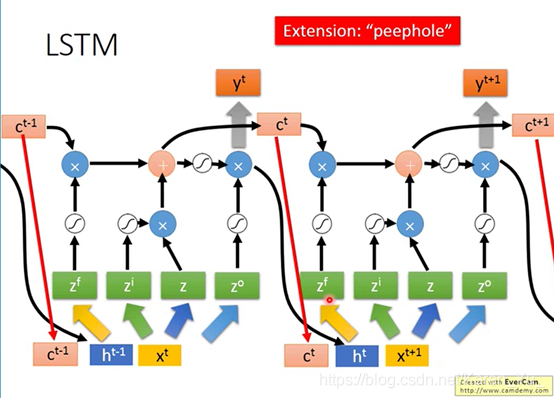
但是实际上,下一个时间点操控gate的input的值不是只看下一个时间点的x还要看前一个时间点的output h
还要在加上“peephole”,把存在memory cell里面的值也拉过来
同时考虑x h c

——————————————————————————————————————————
P21后续内容会写在笔记2中,之后写完了会附上链接
提前,新年快乐

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









