







前言
个人拙见,如果我的理解有问题欢迎讨论 (●′ω`●)
文章出处:https://openreview.net/forum?id=WJ5fJhwvCl
研究背景和意义
深度强化学习(DRL)在各种游戏和任务中表现出色,但对抗性扰动(adversarial perturbations)会显著降低其性能。为了提升DRL代理的鲁棒性(robustness),本文提出了S-DQN和S-PPO两种新算法,通过在训练和测试阶段引入随机平滑(Randomized Smoothing, RS)技术,有效地增强了模型的鲁棒性和干净奖励(clean reward)。
原理部分
去噪器原理
去噪器(denoiser)是用来处理噪声状态的一种模型,其目的是将加噪后的状态恢复为尽可能接近原始状态的形式。去噪器通过优化重建损失(Reconstruction Loss),学习如何去除高斯噪声,使得输出状态与真实状态之间的误差最小。
- 重建损失:衡量去噪后的状态 ( S~) 和原始状态 ( S) 之间的均方误差(MSE):
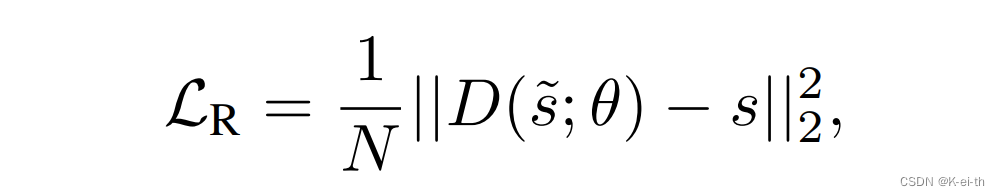
其中D是去噪器,其输出就是去噪之后的状态
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6501
6501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









