








作者:王磊
更多精彩分享,欢迎访问和关注:https://www.zhihu.com/people/wldandan
在【AI设计模式】01-数据表示-特征哈希(Feature Hashed)模式文章中,我们介绍了特征哈希模式,它通过哈希桶对分类数据进行降维,侠小说,其包含金庸的《射雕英雄传》、《倚天屠龙记》、古龙的《天涯明月刀》、梁羽生的《七剑下天山》、黄易的《寻秦记》,如果使用特征哈希模式(根据书名中是否出现武器进行哈希),会将这些书放到2个哈希桶里:桶A:(倚天屠龙记、天涯明月刀、七剑下天山)、桶B(射雕英雄传、寻秦记 )。
而A桶的《射雕英雄传》和B桶的《倚天屠龙记》都是金庸所写,我们期望它们之间的关系更紧密一些。但如果直接应用特征哈希模式进行处理,这个关系就丢失了。
因此,如果想在降维的同时,保留数据间关系,则可以引入嵌入模式(Embeddings)。
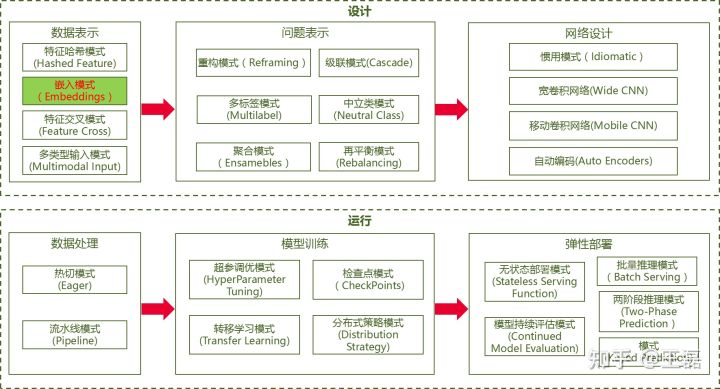
AI设计模式总览
模式定义
嵌入模式是一种数据表示模式,它通过新增神经网络的隐藏层,保留数据间的关联关系,控制隐藏层的输出维度,使其少于该层输入维度,从而实现高基数分类数据的降维。嵌入模式是现代机器学习的核心实践,在NLP、图像处理等领域都有应用。
问题
机器学习模型需要寻找输入的特征值和输出的标签的关联,因此,数据的质量直接决定了模型的质量(garbage in, garbage out)。对于结构化的数字输入,处理相对简单,但对于训练机器学习模型所需的其它数据,如分类特征、文本、图像、音频、时间序列等等,需要将它们转换成数值来作为机器学习模型的输入,以便这些特征能够适合典型的训练范式。这些数据通常使用独热编码方式来处理,而使用这种方式可能会存在如下问题:
- 分类数据每个字段可能有上百万个类别,独热编码将分类数据编码为向量,输入会变成稀疏矩阵,导致训练过程中大量无意义的运算,延长训练时间。比如邮政编码,中国总的邮政编码数量不超过360000,以西安的邮政编码710000为例,编码后为10101101010101110000,总共21位,表示为矩阵,总的元素数量超过2097151,83%的元素都是0。
- 对分类数据应用独热编码后,每个分类数据都是独立,正交的,但有些场景下,分类数据间会存在关联,独热编码会遗失关联的信息。比如对于女性生孩子的数量可能会包含:单胞胎、多胞胎(2+),多胞胎(2+)又可以是双胞胎(2),三胞胎(3),四胞胎(4),五胞胎(5)。提到多胞胎,大家往往会想到双胞胎和三胞胎,因为五胞胎的情况比较少,表示为向量距离的话,双胞胎和三胞胎的距离会近些。独热编码后无法反映出这个关系。相同的问题在文本和图片处理中也存在,图片有很多像素,相互之间有关联。自然语言中单词也有关联性,比如“走路”和“跑步”关系更近些,和“图书”的关系更远些。
- 特征哈希模式虽然也可以通过控制哈希桶来对高基数的数据做降维处理,但是它也无法保留数据的关系信息,本文的开头也给出了相关的例子介绍。
解决方案
通过嵌入模式将输入数据传递给持有训练权重的嵌入层,解决高基数数据通过低维度密集表达的问题。在具体的实践中,会将高维的稀疏独热编码向量映射到低维空间的密集向量,体现出数据的关联度,并且嵌入层的权重可以视为模型的优化参数。以《机器学习设计模式》一书中的婴儿体重预测的模型为例,输入特征值为性别、孕期、母亲年龄、胎儿数量,输出为婴儿体重的预测值。针对胎儿数量,引入嵌入层,起到类似于k-means聚类的作用,保留分类数据之间的关系。
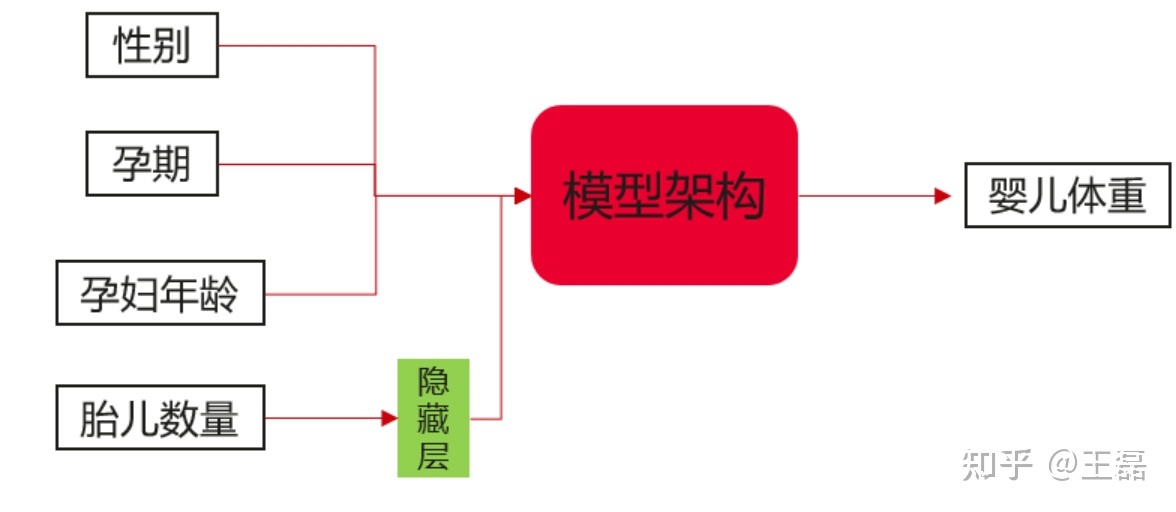
经过训练后,最终得到的胎儿数量的权重(编码)信息可能如下:
| 胎儿数量 | one-hot encoding | 训练后的编码 |
|---|---|---|
| Single(1) | [1,0,0,0,0,0] | [0.4, 0.6] |
| Multiple(2+) | [0,1,0,0,0,0] | [0.1, 0.5] |
| Twins(2) | [0,0,1,0,0,0] | [-0.1, 0.3] |
| Triplets(3) | [0,0,0,1,0,0] | [-0.2, 0.5] |
| Quadruplets(4) | [0,0,0,0,1,0] | [-0.4, 0.3] |
| Quntuplets(5) | [0,0,0,0,0,1] | [-0.6, 0.5] |
嵌入层只是神经网络的一个隐藏层。权重与每个高基数维度关联,输出通过神经网络的其余部分传递。所以,嵌入层的权重是通过梯度下降的过程学习的,和神经网络中的其他权重一样。这意味着生成的权重向量代表了对于特征值最有效的低维表示。
案例
多数AI框架都提供了嵌入模式的模块/接口,如MindSpore,它提供了nn.Embedding模块,用来存储词向量并使用索引进行检索,详细的接口如下:
class mindspore.nn.Embedding(vocab_size, embedding_size, use_one_hot=False, embedding_table="normal", dtype=mstype.float32, padding_idx=None)参数包括词典大小(vocab_size)、嵌入向量大小(embedding_size)等内容,输入为Tensor类型的shape为 (批量大小, Tensor长度) ,元素为整型值(int32或int64),并且元素数目必须小于等于词典大小,否则相应的嵌入向量将为零。
通过MindSpore提供的nn.Embedding模块,可以完成前面提到的婴儿体重预测模型中,对于胎儿数量使用的嵌入模式编码。
假设我们的输入数据前五行如下,可以看到输入数据中包含了两个单胞胎,一个双胞胎,一个三胞胎和一个多胞胎:
weight_pounds,is_male,mother_age,plurality,gestation_weeks
5.2690480617999995,false,15,Single(1),28
6.37576861704,Unknown,15,Single(1),30
1.25002102554,true,14,Twins(2),25
1.99959271634,Unknown,44,Multiple(2+),29
5.06181353552,false,12,Triplets(3),29然后将输入数据保存到babyweight.csv中,开始处理:
import mindspore
import pandas as pd
from mindspore import Tensor
from mindspore.nn import Embedding
df = pd.read_csv("./babyweight.csv")
df.plurality.head(5)
df.plurality.unique()
CLASSES = {
'Single(1)': 0,
'Multiple(2+)': 1,
'Twins(2)': 2,
'Triplets(3)': 3,
'Quadruplets(4)': 4,
'Quintuplets(5)': 5
}
N_CLASSES = len(CLASSES)
plurality_class = [CLASSES[plurality] for plurality in df.plurality]
EMBED_DIM = 2 然后基于MindSpore的Embedding类构件隐藏层,完成编码:
embedding_layer = Embedding(vocab_size=N_CLASSES, embedding_size=EMBED_DIM)
embeds = embedding_layer(Tensor(plurality_class, mindspore.int32))
print(embeds[:5]) 运行后输出婴儿数量的编码:
[[ 0.00107764 0.01330051]
[ 0.00107764 0.01330051]
[-0.01124579 0.00154593]
[-0.0111084 -0.00735236]
[ 0.01125109 -0.01859649]]简单计算下单胞胎和双胞胎、单胞胎和双胞胎的向量距离,可以看到单胞胎和三胞胎的向量距离要大于单胞胎和双胞胎的向量距离,也就是说它在编码后一定程度上保留了数据间的关系信息。
>>> import math
>>> one_to_two = math.sqrt((0.00107764 + 0.01124579)**2 + (0.01330051- 0.00154593)**2)
>>> print(one_to_two)
0.0170304749769729
>>> one_to_three = math.sqrt((0.00107764 + 0.0111084)**2 + (0.01330051+ 0.00735236)**2)
>>> print(one_to_three)
0.02398000438111928总结
嵌入模式可以很好的应对分类数据高基数,以及通过独热编码造成稀疏矩阵的问题。同时,和特征哈希模式类似,嵌入编码后数据从高维到低维表示虽然会丢失信息,但是数据间的关系会有一定程度的保留,这点要好于哈希模式。通过嵌入层的大小可以控制数据转换损失。嵌入层维度过小,信息塞进一个小的矢量空间可能会导致上下文丢失。嵌入层过大,则起不到压缩数据规模的效果。所以,通过要将嵌入层的大小作为超参(经验值为分类数据独立元素总数的四次方根和二次方根*1.6倍之间),努力在编码空间和上下文保留间实现平衡。
我们已经介绍了两个数据表示模式,数据表示完成后,需要对数据进行处理。下一篇文章我们为您介绍数据处理有哪些模式,在什么场景下选择什么样的数据模式。
参考资料
说明:严禁转载本文内容,否则视为侵权。















 1566
1566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









