






要说最近一两周AIGC领域最被关注的内容,非Suno AI莫属。
作为“音乐界的ChatGPT”,Suno AI最新推出的V3模型以其生成广播质量级别音乐的非凡能力火速引爆了音乐圈,网友们也纷开始放飞自我,在AI音乐生成的二创道路上越走越远。
B站网友Mr_Mr_han[1]和一玄青基于Suno AI的二创[2]
对AI开发者与爱好者来说,目前最大的遗憾可能就是Suno V3还没有开源,也没有任何训练的细节,但没有关系,我们现在可以通过MindSpore NLP玩转音乐生成。
MindSpore NLP已支持Meta推出的人工智能音乐生成器——MusicGen!!!它是目前在AI音乐领域难得的开源且可以充当商用训练基础的模型。支持随机生成一段音乐,也可以通过你输入的文本生成指定风格的音乐。
先来试听几段由MusicGen生成的音乐:
基于MindSpore NLP+MusicGen生成自己的个性化音乐
MindSpore NLP如今已全面拥抱HuggingFace,基于动态图实现一天完成热点SOTA模型快速适配。熟悉开发的小伙伴可能会发现基于MindSpore NLP实现的接口和HuggingFace并没有太多的差别,接下来我们借音乐生成的案例来进行阐明。
音乐生成的方式有以下3种:
-
无提示生成:让模型“自力更生“,随机生成一段音乐,体验开音乐盲盒的惊喜。
-
文本提示生成:通过文本指定生成音乐的风格,如:生成一段80s的朋克风音乐,需要有很密集的鼓点。
-
音频提示生成:通过音频提示来生成音乐。
在此之前,需要完成一点点“准备工作“。
首先,我们将本次生成音乐用到的MusicGen-small模型进行实例化。
from mindnlp.transformers import MusicgenForConditionalGeneration
model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")复制MusicGen提供了small、medium和big三种规格的预训练权重文件,本次指南默认使用small规格的权重,生成的音频质量较低,但是生成的速度是最快的。感兴趣的小伙伴也可以尝试不同其他规格的MusicGen。
接下来,就到了生成音乐的正式环节了。
MusicGen都是通过调用model.generate接口,但可以通过变换不同的输入(即代码中的inputs)来实现不同方式的音乐生成。
补充一点,MusicGen支持贪心(greedy)和采样(sampling)两种生成模式。在实际执行过程中,采样模式得到的结果要显著优于贪心模式。因此我们默认启用采样模式,并且可以在调用MusicgenForConditionalGeneration.generate时设置do_sample=True来显式指定使用采样模式。
在了解了音乐生成的整体思路后,我们就可以尝试上述的三种不同的音乐生成方式了。
方式1:无提示生成
我们可以通过方法 `MusicgenForConditionalGeneration.get_unconditional_inputs` 获得网络的随机输入,然后使用 `.generate` 方法进行自回归生成,指定 `do_sample=True` 来启用采样模式:
unconditional_inputs = model.get_unconditional_inputs(num_samples=1)
audio_values = model.generate(**unconditional_inputs, do_sample=True, max_new_tokens=768)复制接下来,我们需要使用第三方库`scipy`将输出的音频保存为`musicgen_out_unconditional.wav` 文件。
import scipy
sampling_rate = model.config.audio_encoder.sampling_rate
scipy.io.wavfile.write("musicgen_out_unconditional.wav", rate=sampling_rate, data=audio_values[0, 0].asnumpy())
复制方式2:文本提示生成
首先通过AutoProcessor对输入进行预处理,基于文本提示生成音频样本。然后,可以将预处理后的输入传递给.generate方法以生成文本条件音频样本。最后,我们将生成出来的音频文件保存为`musicgen_out_text.wav`。
from mindnlp.transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
inputs = processor(
text=["80s pop track with bassy drums and synth", "90s rock song with loud guitars and heavy drums"],
padding=True,
return_tensors="ms",
)
audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=768)
scipy.io.wavfile.write("musicgen_out_text.wav", rate=sampling_rate, data=audio_values[0, 0].asnumpy())复制大家可以通过修改processor中的文本描述,定制自己个人风格的音乐。
方式3:音频提示生成
AutoProcessor同样可以对用于音频预测的音频提示进行预处理。在以下示例中,我们首先加载音频文件,然后进行预处理,并将输入给到网络模型来进行音频生成。最后,我们将生成出来的音频文件保存为` musicgen_out_audio.wav `。
from datasets import load_dataset
dataset = load_dataset("sanchit-gandhi/gtzan", split="train", streaming=True)
sample = next(iter(dataset))["audio"]
sample["array"] = sample["array"][: len(sample["array"]) // 2]
inputs = processor(
audio=sample["array"],
sampling_rate=sample["sampling_rate"],
text=["80s blues track with groovy saxophone"],
padding=True,
return_tensors="ms",
)
audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
scipy.io.wavfile.write("musicgen_out_audio.wav", rate=sampling_rate, data=audio_values[0, 0].asnumpy())
复制大家如有其他的音频文件,也可以通过这种方式来引导模型输出。
附录:MusicGen是什么?
MusicGen是来自Meta AI的Jade Copet等人提出的基于单个语言模型(LM)的音乐生成模型,能够根据文本描述或音频提示生成高质量的音乐样本,相关研究成果参考论文《Simple and Controllable Music Generation》[3]。
MusicGen模型基于Transformer结构,可以分解为三个不同的阶段:
1) 用户输入的文本描述作为输入传递给一个固定的文本编码器模型,以获得一系列隐形状态表示。
2) 训练MusicGen解码器来预测离散的隐形状态音频token。
3) 对这些音频token使用音频压缩模型(如EnCodec)进行解码,以恢复音频波形。
与传统方法不同,MusicGen采用单个stage的Transformer LM结合高效的token交织模式,取消了多层级的多个模型结构,例如分层或上采样,这使得MusicGen能够生成单声道和立体声的高质量音乐样本,同时提供更好的生成输出控制。MusicGen不仅能够生成符合文本描述的音乐,还能够通过旋律条件控制生成的音调结构。
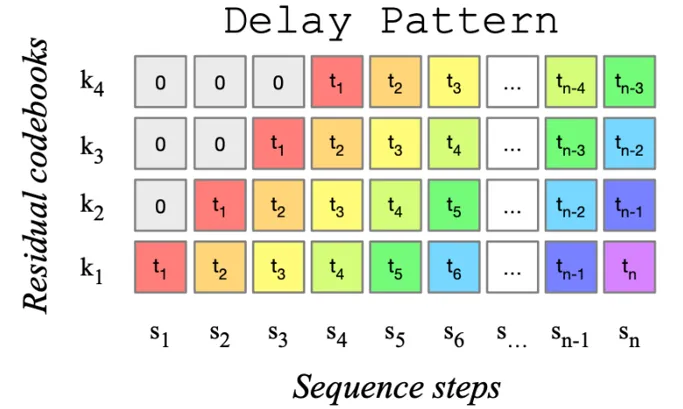
图表1 MusicGen使用的码本延迟模式
MusicGen直接使用谷歌的t5-base[4]及其权重作为文本编码器模型,并使用EnCodec 32kHz[5]及其权重作为音频压缩模型。MusicGen解码器是一个语言模型架构,针对音乐生成任务从零开始进行训练。
参考链接
[1]https://www.bilibili.com/video/BV1w1421D7tQ/?spm_id_from=333.337.search-card.all.click&vd_source=71c01b2a505751311824aae7033733ad
[2]https://www.bilibili.com/video/BV1Cx421S7fD/?spm_id_from=333.337.search-card.all.click&vd_source=71c01b2a505751311824aae7033733ad
[3]https://arxiv.org/abs/2306.05284
[4]https://huggingface.co/t5-base
[5]https://huggingface.co/facebook/encodec_32khz


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









