






通过本系列上文可以体验一下我们从0到1可以快速的搭建属于自己的AI系统,非常的方便与快捷,这里分享一下以前自己搭建一个能使用的AI应用有多么繁琐。
Stable Diffusion介绍
Stable Diffusion是一种基于扩散过程的图像生成模型,可以生成高质量、高分辨率的图像。它通过模拟扩散过程,将噪声图像逐渐转化为目标图像。这种模型具有较强的稳定性和可控性,可以生成具有多样化效果和良好视觉效果的图像。
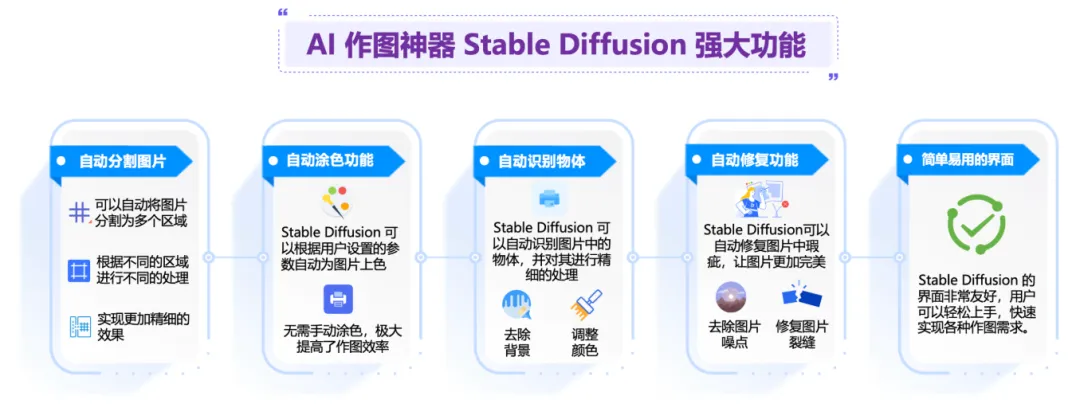
Stable Diffusion 可以通过生成多样化、高质量的图像、修复损坏的图像、提高图像的分辨率和应用特定风格到图像上等方式,辅助视觉创意的实现,它为视觉艺术家、设计师等提供更多的创作工具和素材,促进视觉艺术领域的创新和发展。
对比服务器自行部署痛点
1、安装基本软件:
sudo apt install wget git2、安装python 3.10.6
# 安装依赖
sudo apt install wget git python3 python3-venv
# 删除默认的低版本
which python3
sudo rm /usr/bin/python
# 配置软链接
ls -lh /usr/bin | grep python
ln -s /usr/bin/python3 /usr/bin/python
# 若是GPU环境的用户需要安装与cuda版本对应的torch
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 --extra-index-url https://download.pytorch.org/whl/cu117
# pip换源
pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
# 安装对应依赖
pip install -r requirements_versions.txt
# 建立虚拟环境
sudo apt-get install python3.5-venv
python3 -m venv_name
source venv_name/bin/activate3、安装CUDA
# 下载Cuda
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
# 安装cuda
sudo sh cuda_11.8.0_520.61.05_linux.run
# 配置环境变量
# 增加下面两行内容,并保存
vim ~/.bashrc
export PATH=/usr/local/cuda-11.8/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-11.8/lib64:$LD_LIBRARY_PATH
# 使配置文件生效
source ~/.bashrc4、安装stable diffusion
# 拉取stable diffusion 代码:
git clone GitHub - AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI
# 安装stable diffusion:
cd stable-diffusion-webui/
# 启动
./webui.sh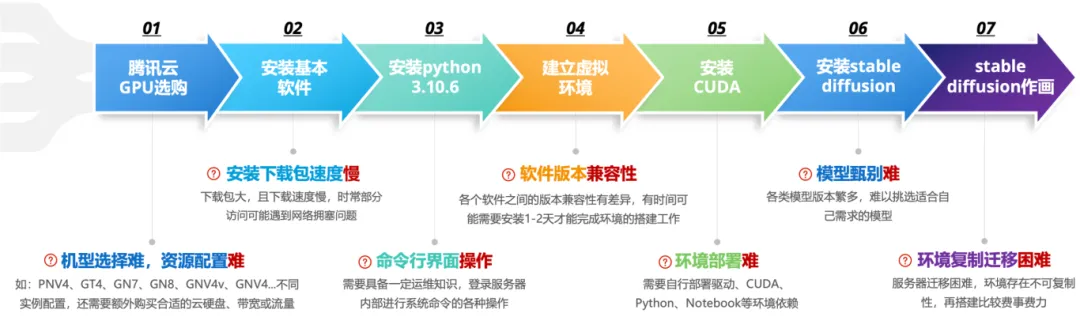
以上是自行尝试购买某云GPU服务器,自己手动搭建环境,并运行stable diffusion。大概花费了差不多一个下午的时间,而且这个还是自己以前尝鲜有过经验的前提下。
搭建自己的AI应用的痛点
自己组建AI的痛点,无论是从概念设计到最终部署,都面临着一系列的痛点,主要包括以下点:
①技术复杂性:
(1). 算法选择与实现:选择合适的AI算法(如深度学习、机器学习、自然语言处理等),不同算法有不同的适用场景和性能表现,选择不当会导致最终应用的效果不佳。
(2). 框架与库的选择:市面上存在多种AI框架和库(如TensorFlow、PyTorch等),每种框架都有其优缺点,选择合适的框架和库以支持应用需求是一个重要的决策。
(3). 模型优化与部署:模型训练完成后,需要对其进行优化以提高性能和准确性,并考虑如何将其部署到生产环境中,其中包括选择合适的硬件平台、处理并发请求、优化响应时间等。
②资源限制:
(1). 计算资源:AI应用的训练和推理过程通常需要大量的计算资源,包括CPU、GPU甚至TPU,这些资源成本高昂。
(2). 存储资源:训练数据和模型本身也需要大量的存储空间,随着数据量的增加,存储成本也会不断上升。
(3). 技术人才:AI应用的开发需要专业的技术人才,包括数据科学家、机器学习工程师等,往往这些人才在市场上供不应求,且成本较高。
③数据问题:
(1). 数据获取:高质量的数据是训练AI模型的关键。然而,在实际应用中,获取足够数量的高质量数据往往非常困难。
(2). 数据标注:对于监督学习来说,数据标注是必不可少的一步。然而,数据标注既耗时又耗力,且需要专业知识。
④维护与更新:
(1). 模型更新:随着新数据的不断涌现和算法的不断进步,AI模型需要定期更新以保持其准确性和有效性,这要求开发者具备持续维护的能力。
(2). 性能监控:在生产环境中,AI应用的性能可能受到多种因素的影响(如硬件故障、网络延迟等)。因此,需要对应用的性能进行实时监控和调整。
因为手里没有备用的TF卡,只能通过第二种方案换一种工具来进行烧录试试,如果网友可以成功启动,就不需要下一步操作。
昇思MindSpore大模型平台SOWT分析
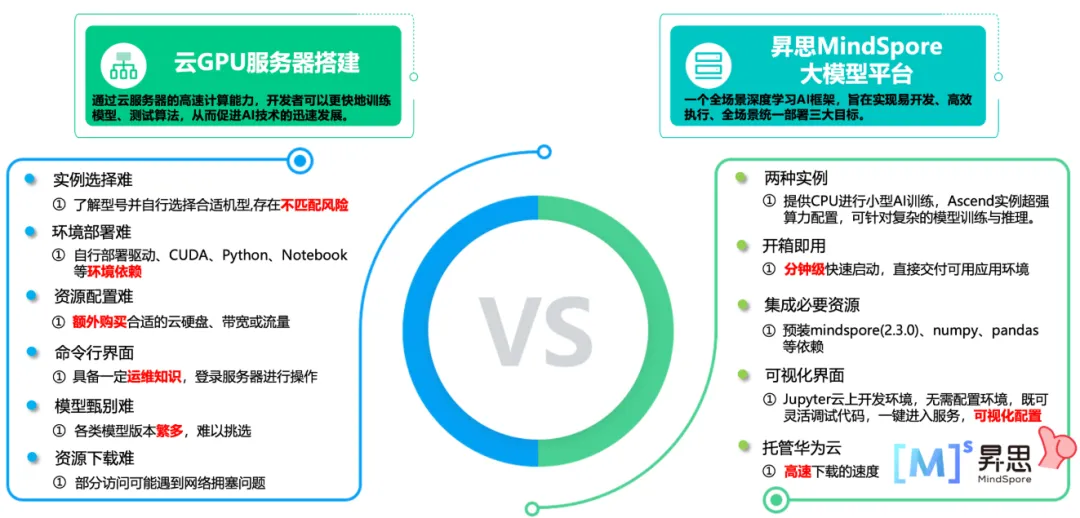
经过一个多月的昇思MindSpore大模型平台的使用与实践,可以很好的解决模型复杂度高、参数量大,对算力有极大的需求,基于昇思MindSpore大模型平台的主流框架进行大模型的开发,为大模型创新开发提供了完备的硬核技术,以下是个人的一个SOWT分析:
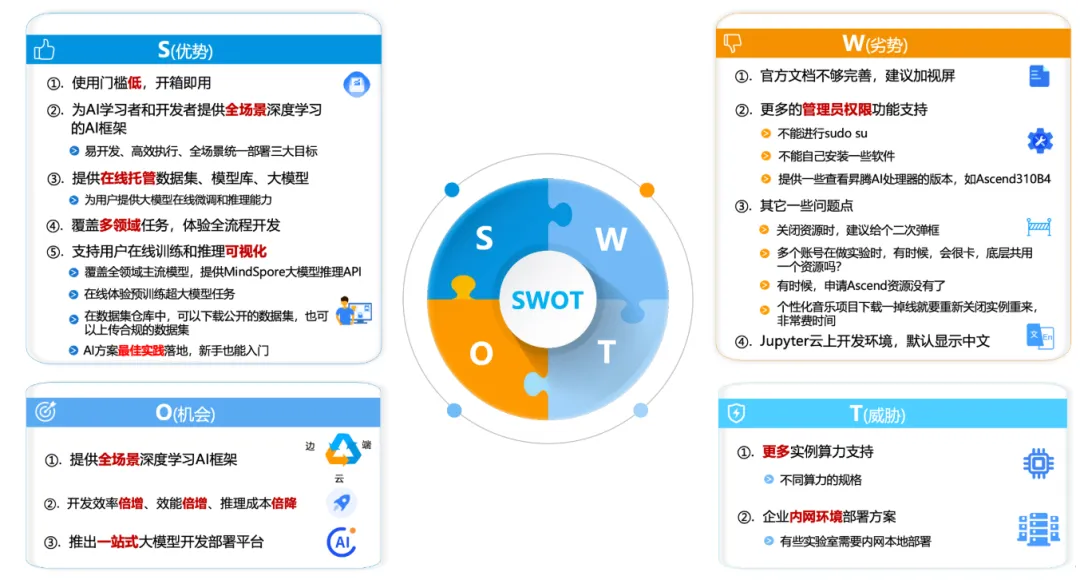
昇思MindSpore充分发挥原生支持大模型训练的能力,降低大模型创新开发门槛,为了让AI大模型更好地普惠大众,昇思社区打造了首个基于自主创新AI算力和框架、服务全球开发者的一站式大模型平台,将大模型的能力开放给开发者。
总结
在如今向人工智能发展的变迁时代,“人工智能+”意味着人工智能只有赋能千行百业才能真正落地转化为价值,这也是昇思大模型平台AI框架的价值的体现所在。
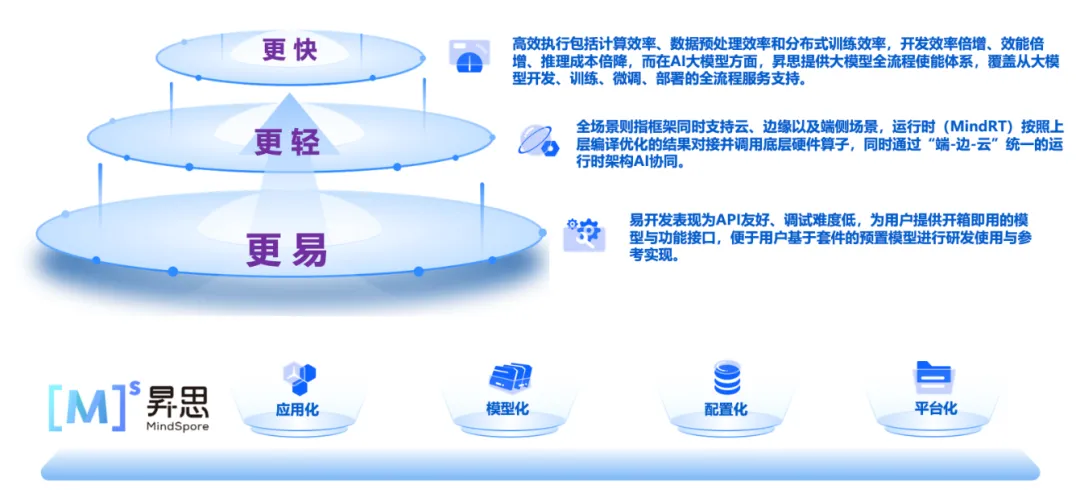
昇思人工智能框架作为算法应用和硬件算力之间的桥梁,持续帮助用户解决部署挑战。相信在不久的将来,伴随昇思MindSpore开源社区的壮大,生态圈持续繁荣,千行百业智能化产品将不断的发展。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









