







 文章介绍了从SqueezeNet到MobileNet系列的轻量化CNN模型,强调了深度分离卷积和模型压缩在提高效率和保持性能方面的作用。MobileNetV3利用NAS优化,实现了更高的精度和更快的速度。此外,还提及了ShuffleNet的channelshuffle技术和Xception的深度可分离卷积。文章还提到了面向嵌入式设备的VoVNet、VarGNet和PeleeNet,以及ENet和ErfNet在轻量级实时语义分割中的应用。
文章介绍了从SqueezeNet到MobileNet系列的轻量化CNN模型,强调了深度分离卷积和模型压缩在提高效率和保持性能方面的作用。MobileNetV3利用NAS优化,实现了更高的精度和更快的速度。此外,还提及了ShuffleNet的channelshuffle技术和Xception的深度可分离卷积。文章还提到了面向嵌入式设备的VoVNet、VarGNet和PeleeNet,以及ENet和ErfNet在轻量级实时语义分割中的应用。
CNN从实验室走向移动端通常会遇到效率问题(包括存储问题和速度问题),通常的操作是对训练好的模型进行模型压缩,另一个角度则是设计轻量化模型。
轻量化模型设计主要思想在于设计更高效的「网络计算方式」(主要针对卷积方式),从而使网络参数减少的同时,不损失网络性能。
SqueezeNet,MobileNet,ShuffleNet,Xception(轻量级backbone)
这四个轻量化模型都在卷积方式上做了改变。
1. SqueezeNet:
提出fire module(包含两部分:squeeze层+expand层),主要目的是减少feature map的维数。
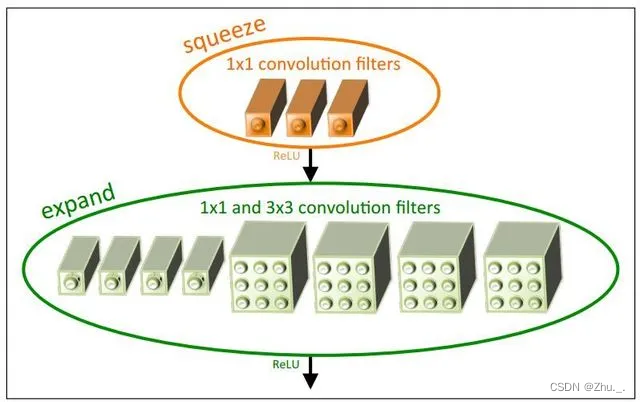
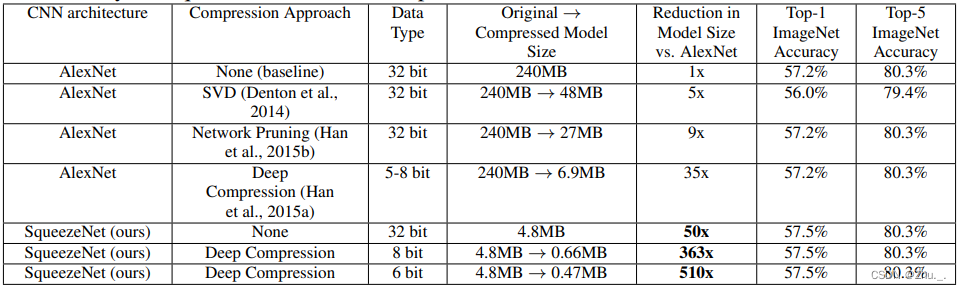
SqueezeNet在不同压缩方式下的模型大小与ImageNet中的分类效果如下:
2. MobileNet:
v1:采用深度分离卷积(depth-wise separable convolution)方式代替传统卷积方式,将卷积过程分解为depthwise convolution和pointwise convolution,以达到减少网络权值参数的目的。
- 深度分离卷积为分组卷积(group convolution)的一种特殊形式,分组卷积的形象化解释如下:

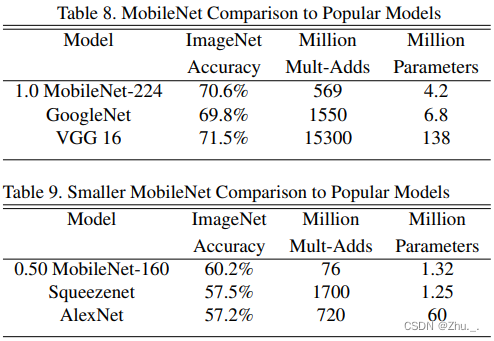
MobileNetV1结果对比如下(第一列为ImageNet中的分类效果,第二列为乘加操作次数,第三列为参数量):
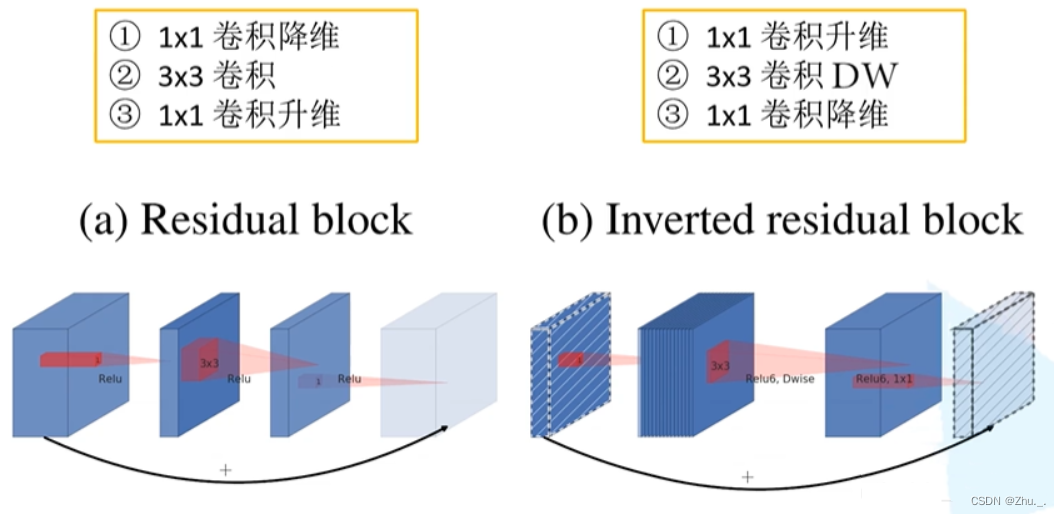
v2:提出Inverted residual模块;结构的最后一层采用线性层
Inverted residual模块与普通残差模块对比如下:
模型效果如下:
ImageNet分类结果:
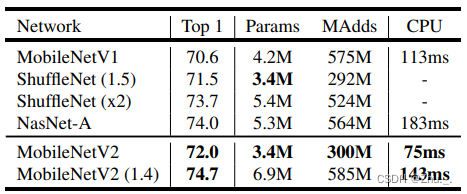
COCO目标检测结果:
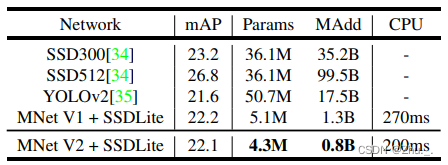
v3:利用NAS算法;分为mobilenet-v3 large 以及mobilenet-v3 small
mobilenet-v3 small在imagenet分类任务上,较mobilenet-v2,精度提高了大约3.2%,时间却减少了15%;
mobilenet-v3 large在imagenet分类任务上,较mobilenet-v2,精度提高了大约4.6%,时间减少了5%,mobilenet-v3 large 与v2相比,在COCO上达到相同的精度,速度快了25%。
2.1 MobileNet+SSD/SSDLite:
采用SSD的思想,在Mobile Net基础上,实现目标检测的功能。
2.2 MobileDet:
将常规卷积纳入搜索空间进行backbone搜索,并采用简单SSDLite进行目标检测架构组成
- 基于同等终端CPU推理延迟,以1.7mAP性能优于MobileNetV3+SSDLite,以1.9mAP性能优于MobileNetV2+SSDLite;
- 在EdgeTPU平台上,以3.7mAP性能优于MobileNetV2+SSDLite且推理更快;
- 在DSP平台上,以3.4mAP性能优于MobileNetV2+SSDLite且推理更快。
3. ShuffleNet:
提出channel shuffle,以减少模型使用的参数数量,解决group convolution带来的“信息流通不畅”问题
基本原理如下:

模型计算量如下:
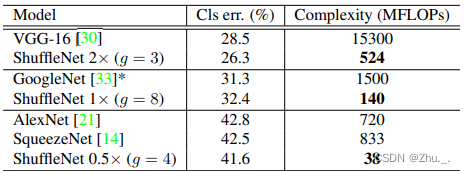
在COCO下的检测精度如下:

在移动设备上的表现如下:
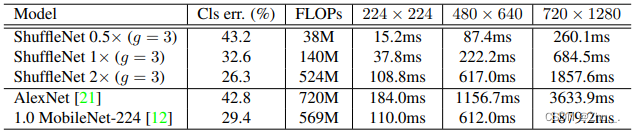
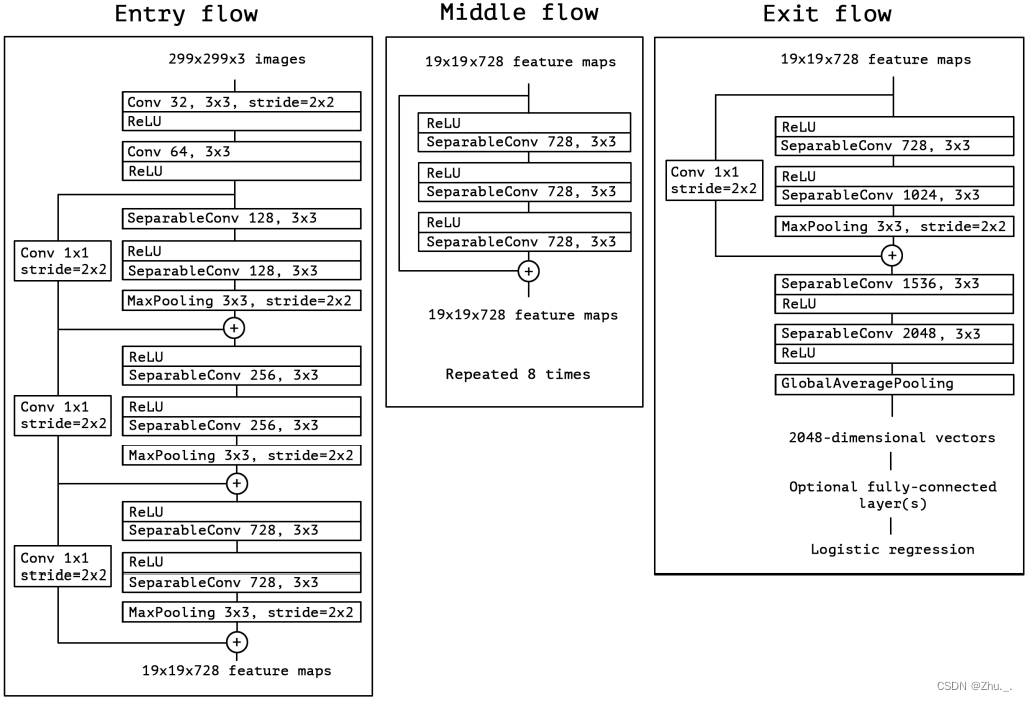
4. Xception:
借鉴depth-wise convolution改进Inception V3
结构如下:
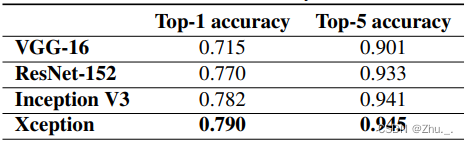
识别效果如下:
资源占用如下:

VoVNet、VarGNet、PeleeNet(面向嵌入式)
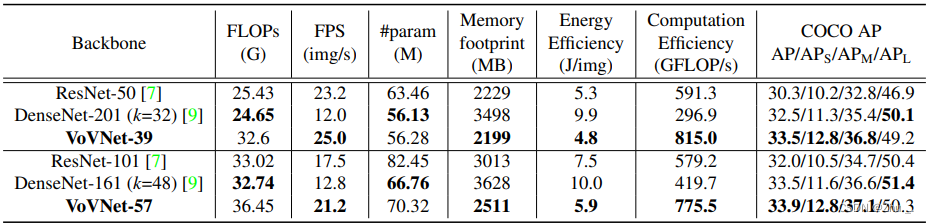
1. VOVNet:
一种专注GPU计算、能耗高效的网络结构。引入了One-Shot Aggregation来改进Dense Block
资源使用情况如下:
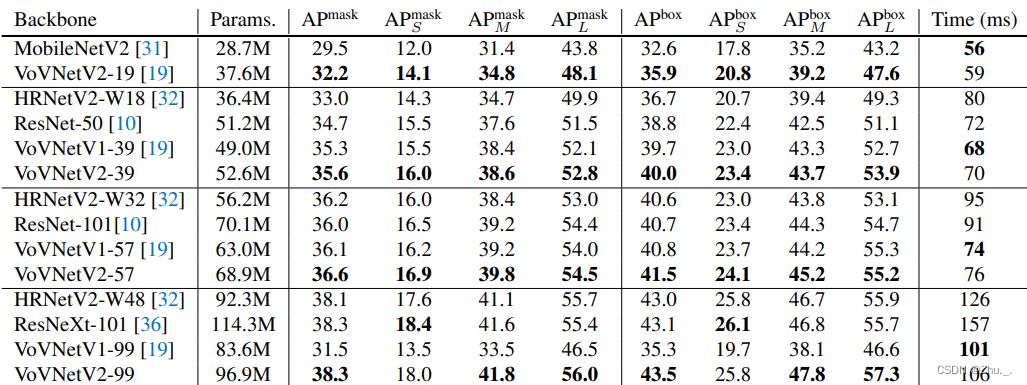
2. VOVNet2:
引入ResNet的残差连接和SENet的SE模块
资源使用情况如下:
3. VarGNet:
地平线2019年新提出的一种轻量级网络。提出基于深度可分离卷积的可变组卷积,更适合于编译器优化。
在COCO上的检测效果与乘加计算次数:
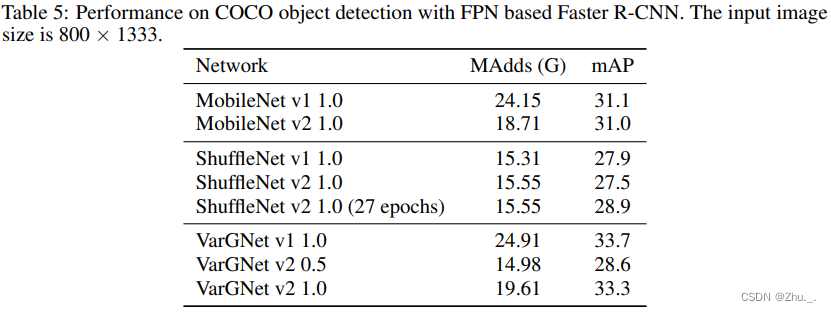
4. PeleeNet:
改进DenseNet
资源使用情况如下:
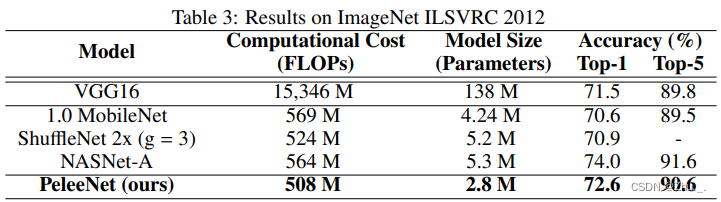
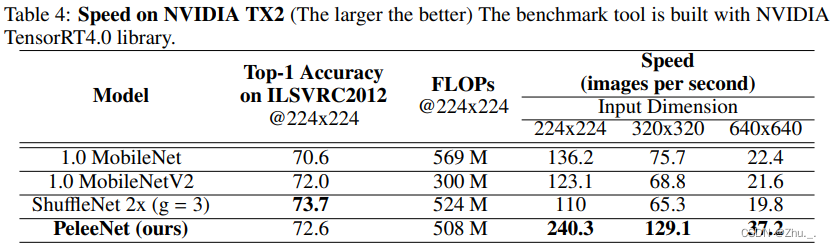

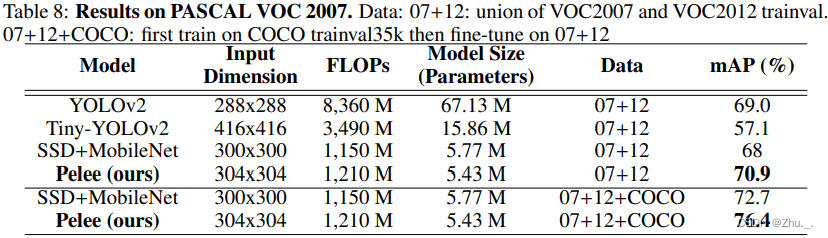
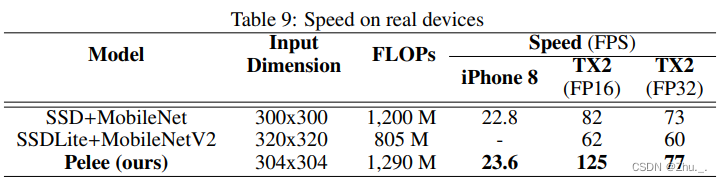
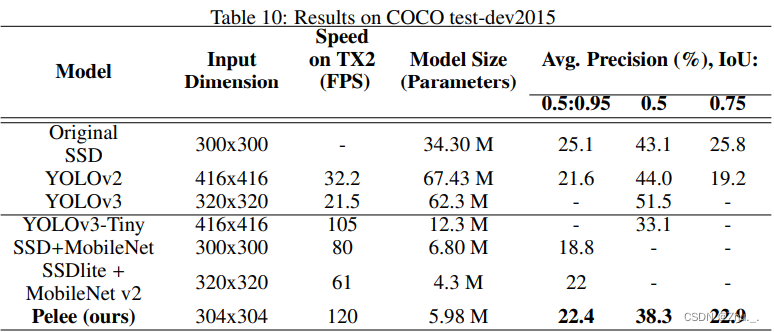
ENet、ErfNet(轻量级实时语义分割)
1. ENet(Efficient Neural Network)
参数小,速度快,但精度差。
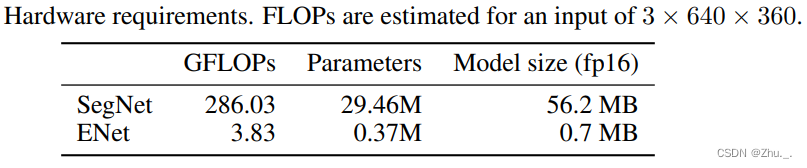
ENet的计算速度与算力需求如下:

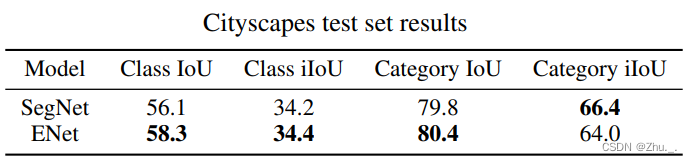
ENet在CityScapes下的识别结果:
ENet在CamVid下的识别结果:
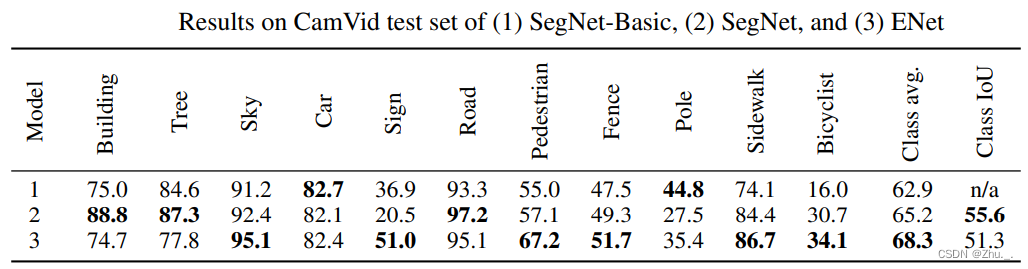
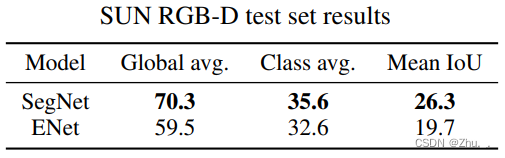
ENet在SUN RGB-D下的识别结果(非道路场景):
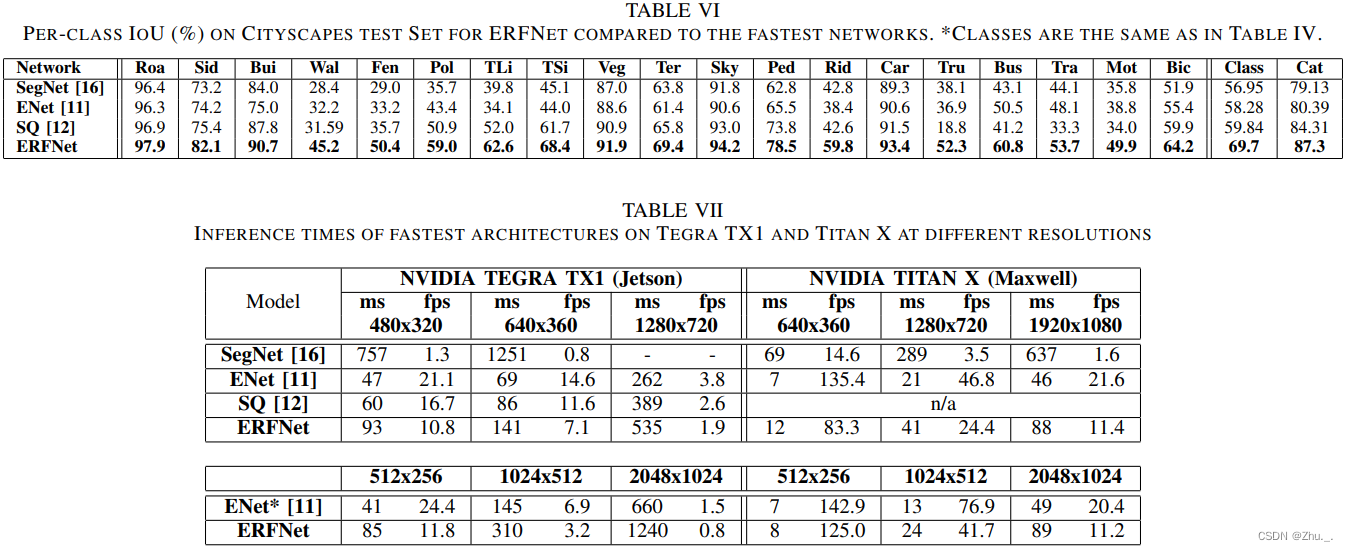
2. ErfNet(Efficient Residual Factorized ConvNet)
相比ENet提升精度,但参数量更多、速度变慢
效果如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









