







NASNet(network architecture search)
NASNet架构特点是由两个AutoML设计的Layer组成——Normal Layer、Reduction Layer,
这样的效果是不再需要相关专家用human knowledge来确定超参数(Hyperparameter),直接用RNN把超参计算出来,这样就实现了AI自动学习。
- 超参数(Hyperparameter)/调优参数(tuning parameters):模型在训练之前就需要确定下来的参数,如学习速率、迭代次数等,“调参”即是指调“超参数”;
- 相对应的概念为模型参数,即模型本身的参数,如权值和偏置等,在模型训练过程中会根据loss自动调整。
在NASNet中,基本的网络结构还是需要手动设计的,NASNet学习的是完整网络中被堆叠、被重复使用的网络单元。
EfficientNet
经验表明,对于卷积神经网络的提升,着重点在于网络深度,网络宽度,分辨率这三个维度;
EfficientNet平衡深度、宽度和分辨率这三个维度,通过一组固定的缩放系数统一缩放这三个维度
例如,如果我们需要使用2^N的计算机资源,我们可以对网络深度放大α^N,对网络宽度放大β^N,对分辨率放大γ^N。
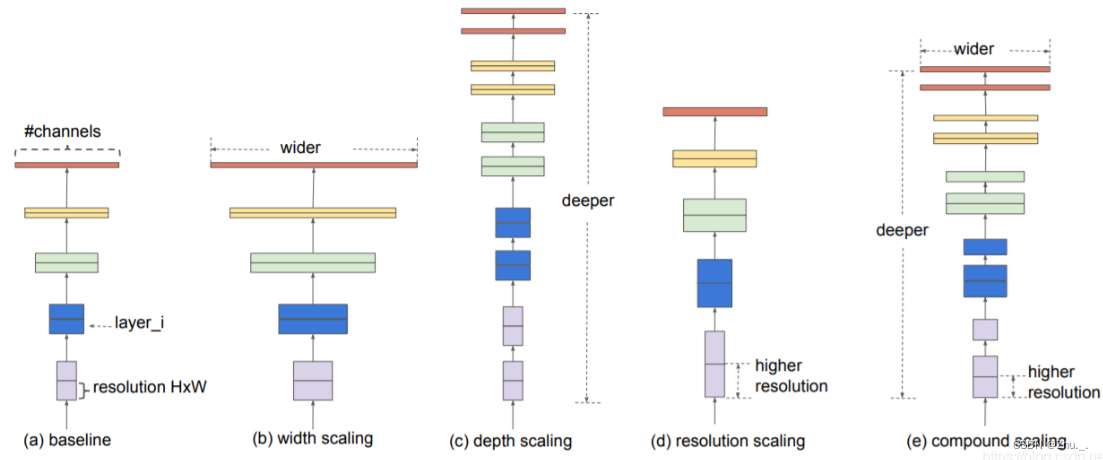
其中,baseline基准网络是通过网络结构搜索得到,基于baseline基准网络进行放大得到的一系列网络就是EfficientNet网络。
RegNet
RegNet核心思想在于如何去设计一个有效的空间,并发现一些网络的通用设计准则,然后根据相应数据集,自动找到最优的参数。
分为RegNetX和RegNetY,两者的区别仅在于RegNetY在block中的Group Conv后接了个SE模块。
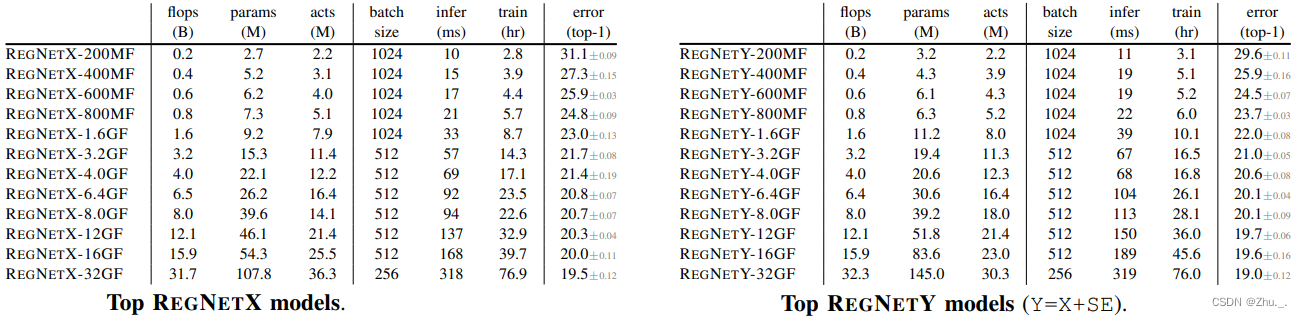
各RegNet的性能对比:
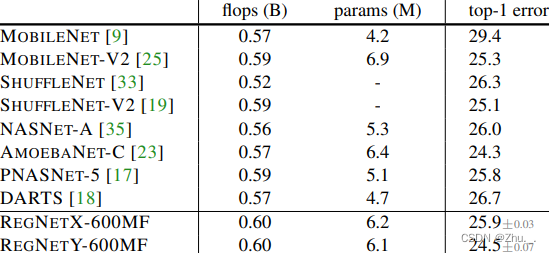
与其他模型的对比如下:
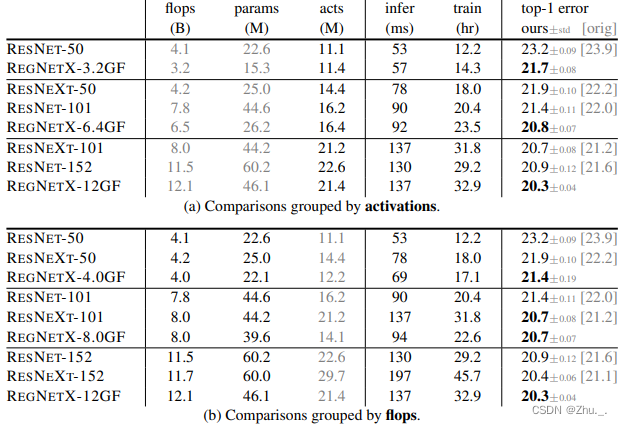
vs ResNet:
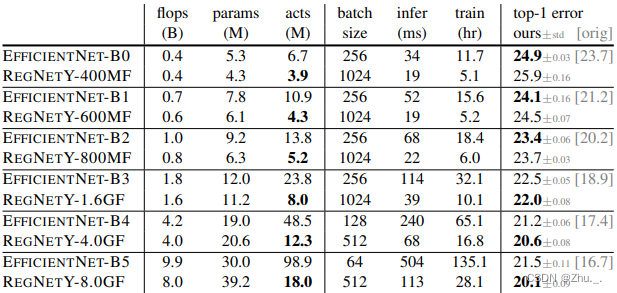
vs EfficientNet:















 3632
3632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









