







本文是以《Python机器学习及实践 从零开始通往kaggle竞赛之路》为参考书籍进行的实践
1 利用K近邻模型对生物物种进行分类,使用Iris数据集
2 实验代码以结果截图
#coding:utf-8
#K近邻模型
#读取Iris数据集细节资料
#导入iris数据加载器
from sklearn.datasets import load_iris
#读取数据并存入变量中
iris=load_iris()
print '数据规模:',iris.data.shape

#查看数据说明
print '数据说明',iris.DESCR

#数据集分割
from sklearn.cross_validation import train_test_split
#随机25%作为测试集
X_train,X_test,y_train,y_test=train_test_split(iris.data,iris.target,test_size=0.25,random_state=33)
#分类预测
#导入数据标准化模块
from sklearn.preprocessing import StandardScaler
#导入K近邻分类器
from sklearn.neighbors import KNeighborsClassifier
#标准化
ss=StandardScaler()
X_train=ss.fit_transform(X_train)
X_test=ss.transform(X_test)
#预测
knc=KNeighborsClassifier()
knc.fit(X_train,y_train)
y_predict=knc.predict(X_test)
#性能评估
#准确性测评
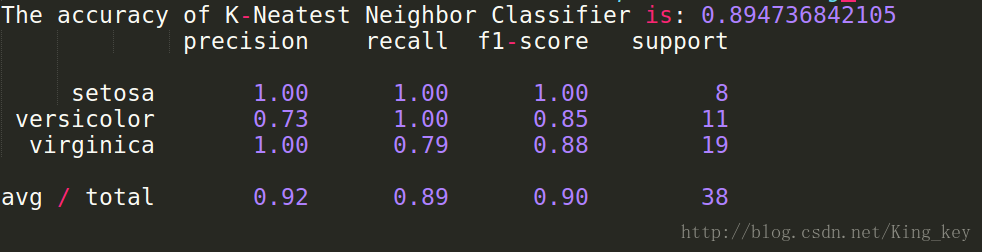
print 'The accuracy of K-Neatest Neighbor Classifier is:',knc.score(X_test,y_test)
#详细分析
from sklearn.metrics import classification_report
print classification_report(y_test, y_predict,target_names=iris.target_names)















 1798
1798

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









