








说到文本串和模板串匹配的情况,我们首先采用BF算法,也就是直接使用蛮力,一个一个比对。
一下关于kmp算法篇幅取自于作者oceanLong,简书地址:KMP算法详解
BF算法
BF算法,即暴风(Brute Force)算法,是普通的模式匹配算法,BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符;若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果。BF算法是一种蛮力算法。
/**
* 暴力破解法
* @param ts 主串
* @param ps 模式串
* @return 如果找到,返回在主串中第一个字符出现的下标,否则为-1
*/
public static int bf(String ts, String ps) {
char[] t = ts.toCharArray();
char[] p = ps.toCharArray();
int i = 0; // 主串的位置
int j = 0; // 模式串的位置
while (i < t.length && j < p.length) {
if (t[i] == p[j]) { // 当两个字符相同,就比较下一个
i++;
j++;
} else {
i = i - j + 1; // 一旦不匹配,i后退
j = 0; // j归0
}
}
if (j == p.length) {
return i - j;
} else {
return -1;
}
}BF算法的时间复杂度为:O(m*n)
这样的方法显然是不够巧妙的。比如在下面的例子:
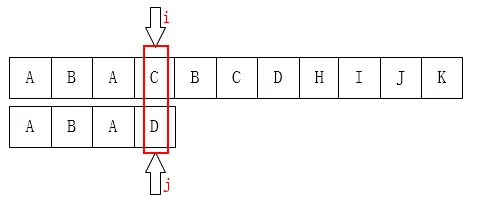
当我们发现在i=j=3不匹配时,我们并不需要 i = 1 , j = 0 。我们可以从 i = 3 , j = 1开始匹配。
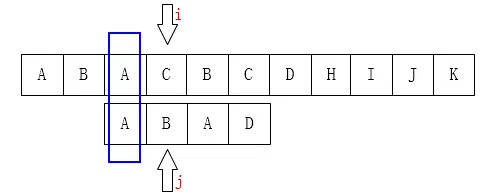
究其原因,是因为我们的p串(模式串)中,有两个A。如果我们已经成功到了j=3,就说明在t串(主串)中也有两个A。那在j==3后面失败之后,我们可以从t串(主串)中的第二个A开始匹配。而不用盲目地从t串的下一位开始匹配。
所以,我们可以得到,在ABAD这样的串中,如果j==3时失败。我们一定是i不变,j从1开始匹配。
注意,这个规则只与p串(模式串)的内容有关,与t串(主串)的内容无关。
所以,我们只需要将上面的BF算法,稍作修改,就可以优化我们的时间复杂度,优化之后的算法,就是KMP算法。
KMP算法
KMP算法要解决的问题就是在字符串(也叫主串)中的模式(pattern)定位问题。说简单点就是我们平时常说的关键字搜索。模式串就是关键字(接下来称它为P),如果它在一个主串(接下来称为T)中出现,就返回它的具体位置,否则返回-1(常用手段)。
先说结论,KMP算法,其实就是将上面的BF算法的。不相等时的情况,进行修改,将:
else {
i = i - j + 1; // 一旦不匹配,i后退
j = 0; // j归0
}换成了:
else {
int[] next = getNext(ps);
j = next[j]; // j回到指定位置
}所以接下来,我们就是要思考,getNext的原理。
public static int[] getNext(String ps) {
char[] p = ps.toCharArray();
int[] next = new int[p.length];
next[0] = -1;
int j = 0;
int k = -1;
while (j < p.length - 1) {
if (k == -1 || p[j] == p[k]) {
next[++j] = ++k;
} else {
k = next[k];
}
}
return next;
}这一段函数是比较难理解的。我们需要根据每一个判断条件,循徐渐进的思考。
if 中的条件有两个 k == -1 || p[j] == p[k]
后面一个条件很容易理解,当我们的串中,有两个元素相等时,我们就可以做一些特殊的操作,就像我们上面举的例子一样。至于具体是做什么操作,我们先不看。
假设,我们的字符串中,没有任何相同的元素。
那么 p[j] == p[k] 就永远不会实现。此时的代码是:
next[0] = -1;
int j = 0;
int k = -1;
while (j < p.length - 1) {
if (k == -1 ) {
next[++j] = ++k;
} else {
k = next[k];
}
}此时,next所有值都会为0。而k只会在0和-1之间徘徊。
我们再看回之前的循环:
public static int[] getNext(String ps) {
char[] p = ps.toCharArray();
int[] next = new int[p.length];
next[0] = -1;
int j = 0;
int k = -1;
while (j < p.length - 1) {
if (k == -1 || p[j] == p[k]) {
next[++j] = ++k;
} else {
k = next[k];
}
}
return next;
}
当p串中,某两个元素相等时,那么后者的下一位,如果失败就可以跳回到前者的下一位了。此处j是后者,k是前者。
如果两个元素不相等时,k = next[k],就是整个算法中最难理解的一句话。
我们知道,k是p串中,两个比较指针的靠前者。next数组是存放,如果对比不想等时的回跳指针。所以 k = next[k]从原理上来讲,是单纯的指针回跳。
k只有在p[j] == p[k]时,才会一直增长,所以我们可以理解为:p[0-k]和p[j-k]这两段是完全相等的。此时接下来如果发生不相等,k回跳到一个更小的串,进行比较。如果比较相等,就只需要回这个小串。
举一个特例就很容易明白了
// a b a d a b a b e
// -1 0 0 1 0 1 2 3 当最后j = 6 k = 2时
next[7] = 3 , k = 3
然后因为p[7] != p[3]
k = next[3] = 1
此时因为p[1] == p[7]
所以如果 e 匹配不到时,我们依然可以从2进行匹配,因为我们虽然不能确保a b a d a b a b 但我们至少确定了前面的串 a b 不需要再匹配了。
所以,k = next[k]是一个缩小匹配串的操作。
当我们到第7位时,发现 a b a d的匹配串,无法出现两次时,我们的k回到第1位,去确定b。如果b与当前相等,那a b的串还是出现了。
以上,KMP的时间复杂度为:O(m+n),空间复杂度为:O(n)
示例代码:
import java.util.*;
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
* 计算模板串S在文本串T中出现了多少次
* @param S string字符串 模板串
* @param T string字符串 文本串
* @return int整型
*/
public int kmp (String S, String T) {
//特殊情况判断
int m = S.length(), n = T.length();
if (m > n || n == 0) return 0;
//初始化计数,获取next数组
int cnt = 0;
int[] next = getNext(S);
//遍历主串和模式串
for (int i = 0, j = 0; i < n; i++) {
//只要不相等,回退到next数组记录的下一位
while (j > 0 && T.charAt(i) != S.charAt(j)) {
j = next[j - 1];
}
if (T.charAt(i) == S.charAt(j)) j++;
//如果j为m,说明完全匹配一次
if (j == m) {
//计数加一,索引回退到next数组记录的下一位
cnt++;
j = next[j - 1];
}
}
return cnt;
}
//确定next数组
private int[] getNext(String S) {
int len = S.length();
int[] next = new int[len];
for (int i = 1, j = 0; i < len; i++) {
//只要不相等,回退到next数组记录的下一位
while (j > 0 && S.charAt(i) != S.charAt(j)) {
j = next[j - 1];
}
//前缀索引后移
if (S.charAt(i) == S.charAt(j)) j++;
//确定应该回退到的下一个索引
next[i] = j;
}
return next;
}
}















 187
187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









