









1.什么是决策树
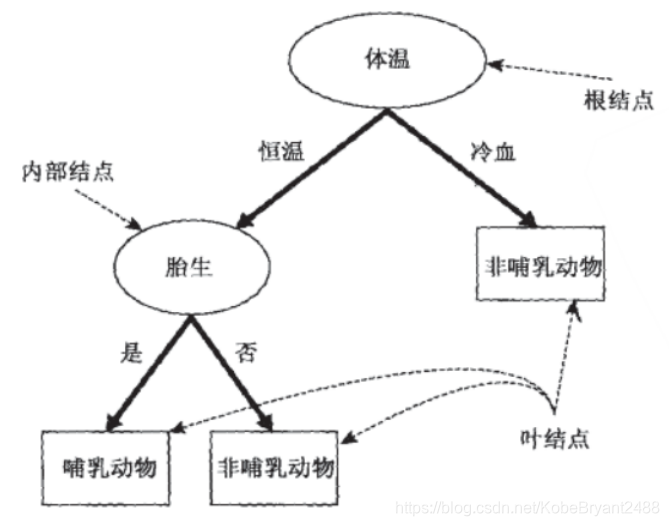
决策树是一种树型结构,其中每个内部结点表示在一个属性上的测试,每个分支代表一个测试输出,每个叶结点代表一种类别。
决策树学习是以实例为基础的归纳学习,通过一系列规则对数据进行分类的过程。
决策树学习采用的是自顶向下的递归方法,其基本思想是以信息熵为度量构造一棵熵值下降最快的树,到叶子节点处的熵值为零,此时每个叶节点中的实例都属于同一类。
简单来说,我们生活中随时会用到这样的判断方法,比如这样:
2.决策树的特点
决策树学习算法的最大优点是,它可以自学习
在学习的过程中,不需要使用者了解过多背景知识,只需要对训练实例进行较好的标注,就能够进行学习
属于有监督学习:从一类无序、无规则的事物(概念)中推理出决策树表
示的分类规则
包含特征选择、决策树的生成和决策树的剪枝
3.基本概念
要用上算法,先来看基本几个概念。
3.1 信息量
定义随机变量X的概率分布为p(x),则定义X信息量:
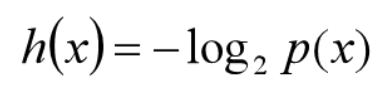
特性:
某事件发生的概率小,则该事件的信息量大。
如果两个事件X和Y独立,即p(xy)=p(x)p(y) ,假定X和Y的信息量分别为h(X)和h(Y),则二者同时发生的信息量应该为h(XY)=h(X)+h(Y)。
3.2 熵
对随机事件的信息量求期望,得熵的定义:
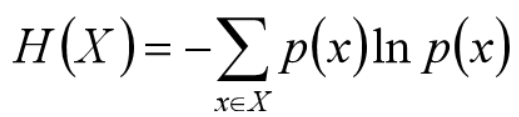
经典熵的定义,底数是2,单位是bit
本例中,为分析方便使用底数e,单位是nat(奈特)
熵只依赖于X的概率分布,与X的取值无关
熵越大,随机变量(样本)的不确定性就越大
3.3 条件熵
两个随机变量X,Y的联合分布,可以形成联合熵用H(X,Y)表示
H(X,Y) – H(X)
(X,Y)发生所包含的熵,减去X单独发生包含的熵:在X发生的前提下,Y发生“新”带来的熵,该式子定义为X发生前提下,Y的熵:
条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性。
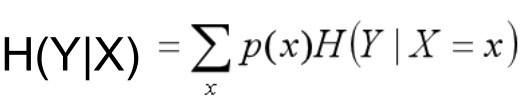
3.4 信息增益
特征选择的准则之一
信息增益表示得知特征A的信息而使得类X的信息的不确定性减少的程度 。
定义:特征A对训练数据集D的信息增益g(D,A),定义为集合D的经验熵H(D)与特征A给定条件下D的经验条件熵H(D|A)之差,即:
g(D,A)=H(D)–H(D|A) ,即为训练数据集D和特征A的互信息。
当熵和条件熵中的概率由数据估计(特别是极大似然估计)得到时,所对应的熵和条件熵分别称为经验熵和经验条件熵。
熵H(Y) 与条件熵 H(Y|X)之差成为互信息,决策树学习中的信息增益等价于训练数据集中类与特征的互信息。
3.5 决策树的生成算法
这是建立决策树的关键,即在当前状态下选择哪个属性作为分类依据。根据不同的目标函数,建立决策树经典算法主要有以下三种:
ID3:使用信息增益/互信息g(D,A)进行特征选择
信息增益是以某特征划分数据集前后的熵的差值。熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大。因此,可以用某特征划分数据集前后的熵的差值来衡量此特征对于样本集合D划分效果的好坏。
信息增益的缺点是偏向取值较多的特征。特征的值较多时,根据此特征划分更容易得到纯度更高的子集,故划分之后的熵更低,因为划分前的熵是一定的,所以信息增益更大,更偏向取值较多的特征
容易训练得到的是一棵庞大且深度浅的树:不合理。
C4.5:信息增益率
gr(D,A) = g(D,A) / H(A)
CART:分类与回归树(CART)
它即可以用于分类,也可以用于回归。回归生成树采用平方误差最小化策略,分类生成树采用基尼指数最小化策略。
4 基本流程
说了这么多,我们的决策树是怎么工作的呢。

在整个决策过程中,我们一直在对记录的特征进行提问。最初的问题所在的地方叫做根节点,在得到结论前的每一个问题都是中间节点,而得到的每一个结论(动物的类别)都叫做叶子节点。
这样一层一层的分下去,我们就会得到前面那样的类似于树状的结构。
5. 代码环节
首先我们自己现实一棵树
//定义类DecisionTreeClassifier的初始化函数init(),包括self.degree每个属性的取值。
class DecisionTreeClassifier(object):
def __init__(self, criterion, degree=16):
self.criterion = criterion
self.order = []
self.degree = degree
self.de1 = np.zeros([self.degree, x_train.shape[1]])
self.rate = np.zeros([self.degree, x_train.shape[1]])
self.feature = []
self.classes_num = np.zeros([self.degree, self.degree])
self.max = np.zeros(x_train.shape[1])
self.min = np.zeros(x_train.shape[1])
//定义信息熵,信息熵是度量样本集合纯度最常用的一种指标。
def info(self, y_train):
Ent_D = 0
for i in range(3):
pk = np.sum(y_train == i) / y_train.shape[0]
if pk > 0:
Ent_D -= pk * math.log(pk, 2)
return Ent_D
//计算信息增益,在鸢尾花的2个属性下,信息增益只需要计算一次,选择长度和宽度某一属性作为最优属性。Gain为每一个属性的信息增益值,按照从小到大的顺序排序得到gain_sort,self.feature为对应的最优属性从大到小的索引。
def best_feature(self, x_train, y_train):
Ent_D = self.info(y_train)
gain = []
for k in range(x_train.shape[1]):
gain_var = 0
for i in range(self.degree):
self.rate[i, k] = np.sum(x_train[:, k] == i)
ent = self.info(y_train[x_train[:, k] == i])
gain_var = gain_var + self.rate[i, k] / y_train.shape[0] * ent
gain.append(Ent_D - gain_var)
gain_sort = sorted(gain)
for k in range(x_train.shape[1]):
self.feature.append(np.where(gain == gain_sort[x_train.shape[1] - 1 - k])[0][0])
return 0
//因为鸢尾花的四个属性取值是连续变量,将其离散化。此处设置鸢尾花的每个属性self.degree有8个或者16个离散值,因为鸢尾花一共有四种类别,所以必须大于4。属性的取值为0~self.degree。
def normal(self, x_train, flag=0):
for k in range(x_train.shape[1]):
if (flag == 0):
x1_max = max(x_train[:, k]);
x1_min = min(x_train[:, k]);
for j in range(self.degree):
self.de1[j, k] = x1_min + (x1_max - x1_min) / self.degree * j
else:
x1_max = self.max[k]
x1_min = self.min[k]
var = x_train[:, k].copy()
for j in range(self.degree):
var[x_train[:, k] >= self.de1[j, k]] = j
x_train[:, k] = var
if (flag == 0):
self.min[k] = x1_min
self.max[k] = x1_max
return x_train
//最大值求解。在决策树算法流程中叶节点被标记为对应样本子集中样本数最多的类别,argmax函数实现了这一功能。
def argmax(self, y_train):
maxnum = 0
for i in range(4):
a = np.where(y_train == i)
if (a[0].shape[0] > maxnum):
maxnum = i
return maxnum
//定义fit训练函数,实现决策树。首先数据离散化,并求解最优属性,计算每一个叶结点的类,下式中从根节点中得到2级属性样本集合a,从a中选择叶节点b,如果叶节点的样本为零,则从a中选择样本最多的类作为叶节点的类别。同样如果a样本为0,则从根节点选择类别。
def fit(self, x_train, y_train):
x_train = self.normal(x_train, flag=0)
self.best_feature(x_train, y_train)
for i in range(self.degree):
a = np.where(x_train[:, self.feature[0]] == i)
print(a)
for j in range(self.degree):
var2 = []
var2_y = []
if (a != []):
b = []
for k in a[0]:
if (x_train[k, self.feature[1]] == j):
b.append(k)
if (b != []):
self.classes_num[i, j] = self.argmax(y_train[b])
else:
self.classes_num[i, j] = self.argmax(y_train[a[0]])
else:
self.classes_num[i, j] = self.argmax(y_train)
return (0)
//定义预测函数,同样对测试集离散化,需要注意离散化的最小值和最大值是从训练集得到的,而不能从测试集中选择。根据属性值选择对应的类别。
def predict(self, x_test):
y_show_hat = np.zeros([x_test.shape[0]])
x_test = self.normal(x_test, 1)
for j in range(x_test.shape[0]):
var = int(x_test[j, self.feature[0]])
var2 = int(x_test[j, self.feature[1]])
y_show_hat[j] = self.classes_num[var, var2]
return y_show_hat
//添加如下所示代码,分别为鸢尾花数据集的特征和分类,包含4个特征和3种分类。x数组包含150个植物的数据,y为对应的分类标签,用0、1、2表示。
iris_feature_E = ['sepal length', 'sepal width', 'petal length', 'petal width']
iris_feature = ['elength', 'ewidth', 'blength', 'bwidth']
iris_class = 'Iris-setosa', 'Iris-versicolor', 'Iris-virginica'
//定义main函数,将数据集特征和标签按照7:3的比例分为训练数据集和测试数据集。数据集仅使用前两个特征训练和测试。
if __name__ == "__main__":
mpl.rcParams['font.sans-serif'] = [u'simHei']
mpl.rcParams['axes.unicode_minus'] = False
data = load_iris()
x = data.data
print(x.shape)
y = data.target
print(y.shape)
x = x[:, :2]
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.7, test_size=0.3, random_state=1)
model = DecisionTreeClassifier(criterion='entropy', degree=16)
model.fit(x_train, y_train)
y_test_hat = model.predict(x_test)
y_test = y_test.reshape(-1)
result = (y_test_hat == y_test)
accuracy = np.mean(result)
print( u'准确度: %.2f%%' % (100 * accuracy))
//画图
N, M = 50, 50
x1_min, x2_min = [min(x[:, 0]), min(x[:, 1])]
x1_max, x2_max = [max(x[:, 0]), max(x[:, 1])]
t1 = np.linspace(x1_min, x1_max, N)
t2 = np.linspace(x, x2_max, M)
x1, x2 = np.meshgrid(t1, t2)
x_show = np.stack((x1.flat, x2.flat), axis=1)
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
y_show_hat = model.predict(x_show)
y_show_hat = y_show_hat.reshape(x1.shape)
plt.figure(1, figsize=(10, 4), facecolor='w')
plt.subplot(1, 2, 1)
plt.pcolormesh(x1, x2, y_show_hat, cmap=cm_light)
plt.scatter(x_test[:, 0], x_test[:, 1], c=y_test.ravel(), edgecolors='k', s=150, zorder=10, cmap=cm_dark,marker='*')
plt.scatter(x[:, 0], x[:, 1], c=y.ravel(), edgecolors='k', s=40, cmap=cm_dark)
plt.xlabel('sepal length', fontsize=15)
plt.ylabel('sepal width', fontsize=15)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.grid(True)
plt.title('class', fontsize=17)
plt.show()
degree为16时:
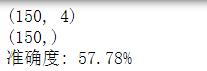
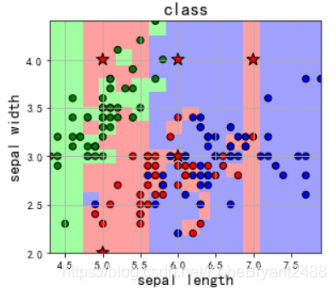
degree为8时:
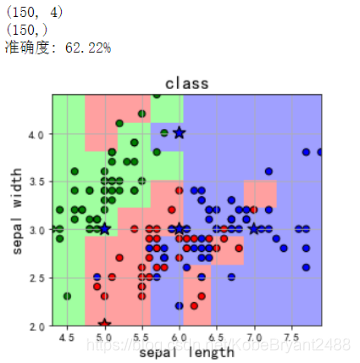
然后我们看下选经典鸢尾花数据不同特征数带来的影响
//调用sklearn中的库完成拟合,并探究特征选取数和最大树高度max_degree不同时的测试集测试结果
from sklearn import *
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from numpy import *
import matplotlib.pyplot as plt
//分别选前两个特征和前四个特征,按70-30划分训练-测试集
data = datasets.load_iris()
x = data.data
y = data.target
x_2 = x[:, :2] # only 2 features
x_4 = x[:, :4] # 4 features
x_train2, x_test2, y_train2, y_test2 = train_test_split(x_2, y, train_size=0.7, test_size=0.3, random_state=1)
x_train4, x_test4, y_train4, y_test4 = train_test_split(x_4, y, train_size=0.7, test_size=0.3, random_state=1)
//分别设置树的最大高度为1-15,对x2和x4训练模型,记录每次的正确率,用两个数组记录。
Accuracy2 = []
Accuracy4 = []
for i in range(15):
depth = i+1
clf = DecisionTreeClassifier(criterion='entropy', max_depth=depth)
clf.fit(x_train2, y_train2)
score2 = clf.score(x_test2, y_test2)
print("Depth: " , depth," | Accuracy:",score2)
Accuracy2.append(score2)
for i in range(15):
depth = i+1
clf = DecisionTreeClassifier(criterion='entropy', max_depth=depth)
clf.fit(x_train4, y_train4)
score4 = clf.score(x_test4, y_test4)
print("Depth: " , depth," | Accuracy:",score4)
Accuracy4.append(score4)


就酱,希望对大家有帮助,欢迎点赞和在评论区讨论^














 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









