









一.何为聚类
聚类就是对大量未知标注的数据集,按数据的内在相似性将数据集划分为多个类别,使类别内的数据相似度较大而类别间的数据相似度较小。
1.1 相似度和距离计算
我们日常生活最常用的也似乎只会用的是欧氏距离,其实样本间距离的度量方式还有很多种。

1.2 聚类的基本思想
给定一个有N个对象的数据集,构造数据的k个簇,k≤n。满足下列条件:
每一个簇至少包含一个对象
每一个对象属于且仅属于一个簇
将满足上述条件的k个簇称作一个合理划分
基本思想:对于给定的类别数目k,首先给出初始划分,通过迭代改变样本和簇的隶属关系,使得每一次改进之后的划分方案都较前一次好。
二.kmeans算法
2.1 步骤
k-Means算法,称为k-平均或k-均值,一种广泛使用的聚类算法,或者成为其他聚类算法的基础。
假定输入样本为S=x 1 ,x 2 ,…,x m ,则算法步骤为:
选择初始的k个类别中心μ 1 μ 2 …μ k
对于每个样本x i ,将其标记为距离类别中心最近的类别
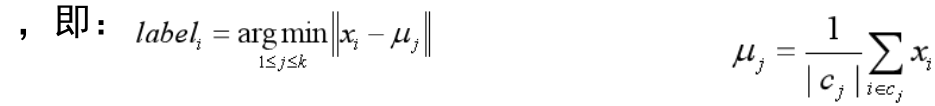
将每个类别中心更新为隶属该类别的所有样本的均值
重复最后两步,直到类别中心的变化小于某阈值。
中止条件:
迭代次数/簇中心变化率/最小平方误差MSE(Minimum Squared Error)
2.2 特点
1 平均值还是中位数?
在k-Means迭代过程中,将簇中所有点的均值作为新质心,若簇中含有异常点,将导致均值偏离严重。以一维数据为例:
数组1、2、3、4、100的均值为22,显然距离“大多数”数据1、2、3、4比较远
改成求数组的中位数3,在该实例中更为稳妥。
这种聚类方式即k-Mediods聚类(K中值距离)
2 初值的选择,对聚类结果有影响吗?
kmeans是对初始值敏感的,不同的选取得到结果可能是不同的,如何避免?
二分kmeans:
首先将所有点作为一个簇,然后将该簇一分为二
选择能最大程度降低聚类代价函数(也就是误差平方和)的簇划分为两个簇(或者选择最大的簇等,选择方法多种)
重复上一步,直到簇的数目等于用户给定的数目k为止
优点:
• 二分K均值可以加速K-means的执行速度,因为相似度计算少了
• 不受初始化问题的影响,因为不存在随机点的选取,且每一步都保证了误差最小

3 mini-batch kmeans
当数据量很大时,k-Means计算时间将变得相当长。
自然而然想到的办法是每次随机抽样。
Mini Batch K-Means能在保持聚类准确性的同时,大幅度降低计算时间从不同类别的样本中抽取一部分样本来代表各自类型进行计算。计算样本量少,减少运行时间,但因抽样必然会带来准确度下降。

4 肘部法则
“肘部法则”是选择聚类数目的一种方法。我们所需要做的是改变K值,也就是聚类类别数目的总数。我们用一个聚类来运行K均值聚类方法。这就意味着,所有的数据都会分到一个聚类里,然后计算成本函数或者计算代价函数。

选取拐点3作聚类数可能较好(图来自经典吴恩达)
2.4 kmeans优缺点
优点:
是解决聚类问题的一种经典算法,简单、快速
对处理大数据集,该算法保持可伸缩性和高效率
当簇近似为高斯分布时,它的效果很好
缺点:
在簇的平均值可被定义的情况下才能使用,可能不适用于某些应用
必须事先给出k(要生成的簇的数目),而且对初值敏感,对于不同的初始值,可能会导致不同结果。
不适合于发现非凸形状的簇或者大小差别很大的簇
对躁声和孤立点数据敏感
2.5 聚类衡量指标




三. 层次聚类算法
3.1 agnes和diana
层次聚类方法对给定的数据集进行层次的分解,直到某种条件满足为止。具体又可分为:
凝聚的层次聚类:AGNES算法
一种自底向上的策略,首先将每个对象作为一个簇,然后合并这些原子簇为越来越大的簇,直到某个终结条件被满足。
分裂的层次聚类:DIANA算法
采用自顶向下的策略,它首先将所有对象置于一个簇中,然后逐渐细分为越来越小的簇,直到达到了某个终结条件。
AGNES (AGglomerative NESting)算法最初将每个对象作为一个簇,然后这些簇根据某些准则被一步步地合并。两个簇间的距离由这两个不同簇中距离最近的数据点对的相似度来确定;聚类的合并过程反复进行直到所有的对象最终满足簇数目。
DIANA (DIvisive ANAlysis)算法是上述过程的反过程,属于分裂的层次聚类,首先将所有的对象初始化到一个簇中,然后根据一些原则(比如最大的欧式距离),将该簇分类。直到到达用户指定的簇数目或者两个簇之间的距离超过了某个阈值。
3.2 距离度量
最小距离
两个集合中最近的两个样本的距离(Prime)
容易形成链状结构
最大距离
两个集合中最远的两个样本的距离(complete)
若存在异常值,则不稳定
平均距离
两个集合中样本间两两距离的平均值(average)
两个集合中样本间两两距离的平方和(ward)
代码
自定义kmeans
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
def k_means(x, k=3):
#随机初始化质心
index_list = np.arange(len(x))
np.random.shuffle(index_list)
centroids_index = index_list[:k]
centroids = x[centroids_index]
#初始化标签数组
y = np.arange(len(x))
iter_num = 10 #自行设置迭代次数
#每次迭代计算新的将现有点分类,计算新的簇中心,当达到最大迭代次数或质点不再更新时停止
for i in range(iter_num):
y_new = np.arange(len(x))
for i, xi in enumerate(x):
y_new[i] = np.argmin([np.linalg.norm(xi - cj) for cj in centroids])
if sum(y != y_new) == 0:
break
for j in range(k):
centroids[j] = np.mean(x[np.where(y_new == j)], axis=0)
y = y_new.copy()
return y
if __name__ == '__main__':
#可自行创造其他数据
x = np.array([[1,1],[3,3],[1,7],[2,8],[10,20],[1,30],[2,29],[10,11],[15,18],[12,19],[13,13]])
y = k_means(x)
print(y)
#可视化
for i in range(np.shape(y)[0]):
if y[i] == 0:
plt.scatter(x[i][0], x[i][1], c='b', s=20)
elif y[i] == 1:
plt.scatter(x[i][0], x[i][1], c='y', s=20)
else:
plt.scatter(x[i][0], x[i][1], c='g', s=20)
plt.show()

调用sklearn中的KMeans和AgglomerativeClustering,对比在鸢尾花数据集上的分类结果
import numpy as np
import random
from sklearn.cluster import KMeans, AgglomerativeClustering
from sklearn import datasets, metrics
from sklearn.model_selection import train_test_split
import time
np.random.seed()
percentage=0.2
iter=10
def prepare_data():
iris = datasets.load_iris()
x = iris.data
y = iris.target
return x,y
#kmeans聚类
def eva_kmeans(x,y):
#运行十次,取平均分类正确样本数,运行时间,准确率
kmean_ei = 0.0 #分类正确样本数
kmean_rt = 0.0 #运行时间
kmean_aa = 0.0 #准确率
for i in range(0, iter):
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8, test_size=0.2, random_state=1)
k_begin = time.time()
kmeans = KMeans(init="random", n_clusters=3, random_state=0).fit(x,y)
kmean_pred = kmeans.predict(x_test)
k_end = time.time() - k_begin
kmean_rt = kmean_rt + k_end
accuracy_number = 0
for i in range(len(y_test)):
if kmean_pred[i] == y_test[i]:
accuracy_number += 1
kmean_ei = kmean_ei + accuracy_number
accuracy_percentage = metrics.accuracy_score(y_test, kmean_pred)*100
kmean_aa = kmean_aa + accuracy_percentage
kmean_ei = kmean_ei / (iter*1.0)
kmean_rt = kmean_rt / (iter*1.0)
kmean_aa = kmean_aa / (iter*1.0)
return kmean_ei, kmean_rt, kmean_aa
#层次聚类
def eva_hierarchical(x,y):
hier_ei = 0.0
hier_rt = 0.0
hier_aa = 0.0
for i in range(0, 10):
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8, test_size=0.2, random_state=1)
k_begin = time.time()
hier = AgglomerativeClustering(n_clusters=3, affinity="euclidean", linkage="average").fit(x,y)
hier_pred = hier.fit_predict(x_test)
k_end = time.time() - k_begin
hier_rt = hier_rt + k_end
accuracy_number = 0
for i in range(len(y_test)):
if hier_pred[i] == y_test[i]:
accuracy_number += 1
hier_ei = hier_ei + accuracy_number
accuracy_percentage = metrics.accuracy_score(y_test, hier_pred)*100
hier_aa = hier_aa + accuracy_percentage
hier_ei = hier_ei / (iter*1.0)
hier_rt = hier_rt / (iter*1.0)
hier_aa = hier_aa / (iter*1.0)
return hier_ei, hier_rt, hier_aa
if __name__ == '__main__':
x,y=prepare_data()
kmean_ei, kmean_rt, kmean_aa=eva_kmeans(x,y)
hier_ei, hier_rt, hier_aa = eva_hierarchical(x, y)
print ("total iterate:",iter)
print ("method ", "# of error instances ", "run_time/s ", "accuracy/%")
print ("K-means ", kmean_ei," ", kmean_rt," ", kmean_aa)
print ("hierarchical ", hier_ei, " ", hier_rt, " ", hier_aa)

可以看到,kmeans聚类的准确率更高,但耗时多了一个数量级。当数据量更大时,这个差距可能更大,所以当数据量很大时可以考虑使用层次聚类得到一个初步的结果。















 3146
3146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









