






1,支持向量机(Support Vector Machine, SVM)是一类按监督学习(supervised learning)方式对数据进行二元分类(binary classification)的广义线性分类器(generalized linear classifier),其决策边界是对学习样本求解的最大边距超平面(maximum-margin hyperplane)。
SVM使用铰链损失函数(hinge loss)计算经验风险(empirical risk)并在求解系统中加入了正则化项以优化结构风险(structural risk),是一个具有稀疏性和稳健性的分类器。SVM可以通过核方法(kernel method)进行非线性分类,是常见的核学习(kernel learning)方法之一 。
svm与knn的异同点
KNN算法是物以类聚,人以群分,身旁哪个种类最多就把预测的样本归为哪一类,基本原理就是找到距离最近的K个元素,然后将这K个元素进行排列,哪个种类多,就将样本进行归类。
对于SVM,是先在训练集上训练一个模型,然后用这个模型直接对测试集进行分类。这两个步骤是独立的。
对于KNN,没有训练过程。只是将训练数据与训练数据进行距离度量来实现分类。
两者调参过程不一样。
knn只有一个参数k,而svm的参数更多,在线性不可分的情况下(这种情况更普遍),有松弛变量的系数,有具体的核函数。
KNN预测时要用到全部训练样本点,为非稀疏模型。SVM只用到支持向量,为稀疏模型。
。knn没有训练过程,但是预测过程需要挨个计算每个训练样本和测试样本的距离,当训练集和测试集很大时,预测效率感人。
svm有一个训练过程,训练完直接得到超平面函数,根据超平面函数直接判定预测点的label,预测效率很高
算法详解视频
【数之道】支持向量机SVM是什么,八分钟直觉理解其本质_哔哩哔哩_bilibili
【SVM支持向量机】低维空间的混乱 高维空间的秩序_哔哩哔哩_bilibili
【数之道】支持向量机SVM是什么,八分钟直觉理解其本质_哔哩哔哩_bilibili
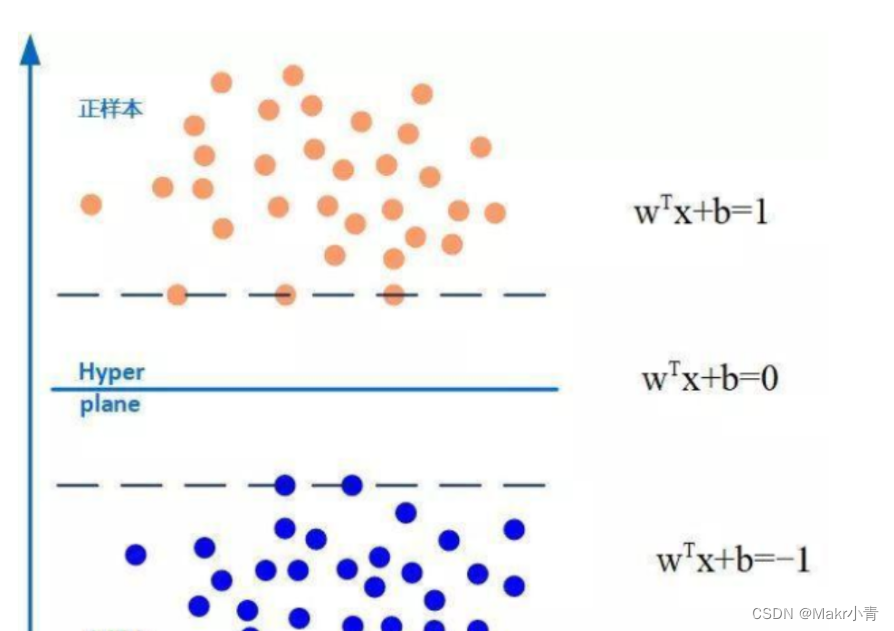
如何找到最合适的分类超平面?依据的原则就是间隔最大化。
具体详解还未理解清楚:

百度飞桨案例实现(鸢尾花分类) 
代码与结果展示
# ======判断a,b是否相等计算acc的均值
def show_accuracy(a, b, tip):
acc = a.ravel() == b.ravel()
print('%s Accuracy:%.3f' %(tip, np.mean(acc)))
# 分别打印训练集和测试集的准确率 score(x_train, y_train)表示输出 x_train,y_train在模型上的准确率
def print_accuracy(clf, x_train, y_train, x_test, y_test):
print('training prediction:%.3f' %(clf.score(x_train, y_train)))
print('test data prediction:%.3f' %(clf.score(x_test, y_test)))
# 原始结果和预测结果进行对比 predict() 表示对x_train样本进行预测,返回样本类别
show_accuracy(clf.predict(x_train), y_train, 'traing data')
show_accuracy(clf.predict(x_test), y_test, 'testing data')
# 计算决策函数的值 表示x到各个分割平面的距离
print('decision_function:\n', clf.decision_function(x_train))
def draw(clf, x):
iris_feature = 'sepal length', 'sepal width', 'petal length', 'petal width'
# 开始画图
x1_min, x1_max = x[:, 0].min(), x[:, 0].max()
x2_min, x2_max = x[:, 1].min(), x[:, 1].max()
# 生成网格采样点
x1, x2 = np.mgrid[x1_min:x1_max:200j, x2_min:x2_max:200j]
# 测试点
grid_test = np.stack((x1.flat, x2.flat), axis = 1)
print('grid_test:\n', grid_test)
# 输出样本到决策面的距离
z = clf.decision_function(grid_test)
print('the distance to decision plane:\n', z)
grid_hat = clf.predict(grid_test)
# 预测分类值 得到[0, 0, ..., 2, 2]
print('grid_hat:\n', grid_hat)
# 使得grid_hat 和 x1 形状一致
grid_hat = grid_hat.reshape(x1.shape)
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'b', 'r'])
plt.pcolormesh(x1, x2, grid_hat, cmap = cm_light)
plt.scatter(x[:, 0], x[:, 1], c=np.squeeze(y), edgecolor='k', s=50, cmap=cm_dark )
plt.scatter(x_test[:, 0], x_test[:, 1], s=120, facecolor='none', zorder=10 )
plt.xlabel(iris_feature[0], fontsize=20) # 注意单词的拼写label
plt.ylabel(iris_feature[1], fontsize=20)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.title('Iris data classification via SVM', fontsize=30)
plt.grid()
plt.show()















 424
424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









