









题目

概括
一种特征选择器,用来移除不相关的特征,减少计算量,加速计算过程提升性能表现。
结构
模型分成三部分:
-
通过深度自动编码器得到的受正交约束的
indicator matrix指示矩阵。 -
使用非负最小二乘法,获得近似的、非负的
指示矩阵(算法第8部) -
通过
指示矩阵来选择出特征选择矩阵(feature selection matrix),并且使用K-means算法来评估模型。(算法性能评估部分)
Related works
- LS Laplacian score作为过滤方法。但是LS不考虑特征间关系。
- MCFS unsupervised feature selection method . 忽略了非负的限制,提升了获得cluster label的难度。
- UDFS unsupervised discriminative feature selection method、NDFS 比UDFS更平滑,但是对于轮廓和噪声都没有很好的健壮性。
- RUFS robust unsupervised feature selection, better
与图的结合
-
SPFS sparsity preserving fearure selection
-
NPFS neighborhood preserving feature selection,强化了SPFS的限制,
-
NEFS neighborhood embedding feature selection .联合框架
-
URAFS uncorrelated regression model with adaptive graph structure
为了减少时间开销和计算复杂度:
- AEFS auto-encoder feature selection,不能保证indicator matrix正交性和非负性的限制
- CAE Concrete auto-encoders for differentiable feature selection
原理
面临的问题:
- 正交性、稀疏性矩阵特点
H矩阵正交性、稀疏性:
- 正交性:保证了H矩阵能够在整个学习过程中作为indicator matrix的性质。(什么性质?)这个特性可以提高模型的可解释性
- 使用范数约束保证矩阵的稀疏性和平滑性。
理论过程:
整体就是希望优化这个:
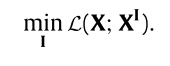
X是原始的数据集, X I X^I XI是维度缩减后的数据集。目标就是缩减维度后仍然能够最大限度的保证原始数据的内特征。 X I = X H Z X^I = XHZ XI=XHZ,得到如下:
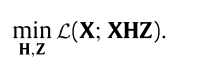
-
X n × d = [ X 1 ; X 2 ; . . . X n ] X_{n\times d} = [X_1;X_2;...X_n] Xn×d=[X1;X2;...Xn] ,每一行代表一个样本。每个样本有d个维度的特征。
-
H d × k H_{d\times k} Hd×k是选择矩阵,每个样本都选择其中的某些特征,删去其他特征。想要达到这种效果,每列只能有一个1,其他为0。例如,从4个特征中,选择每个样本的第1,2,4特征,不要第三列特征。则H为:
H 4 × 3 = [ 1 0 0 0 1 0 0 0 0 0 0 1 ] H_{4 \times 3} = \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 0 \\ 0 & 0 & 1 \\ \end{bmatrix} H4×3=⎣⎢⎢⎡100001000001⎦⎥⎥⎤
这里就是一个矩阵相乘计算的技巧。H的每个列只有一个1,而为1的那个行号,就代表这个特征被选上了。如果H行每列有两个1,那么生成的维度是这两个特征的加和。
H每行也尽量有一个1,如果某有一行有两个1,说明这个特征被选择了两次。
当然实际操作中,不一定是1,可以是一个相对较大值等。因为这个值要乘在原始数据的前面。如果为0.5,说明原始特征缩小0.5.
- Z k × d Z_{k \times d} Zk×d矩阵是用来进行反向恢复的,从选择的特征中恢复为X的近似

-
μ \mu μ是一个系数。
-
∣ ∣ H ∣ ∣ 2 , 1 = ∑ j = 1 k ∑ i = 1 d H i j 2 ||H||_{2,1} = \sum^k_{j=1}\sqrt{\sum_{i=1}^d H^2_{ij}} ∣∣H∣∣2,1=∑j=1k∑i=1dHij2 H ∈ R d × k H \in R^{d \times k} H∈Rd×k
2,1范数是为了让矩阵的每列有尽量多的0。(根号里是列和。)这是为了保证稀疏性
-
H T H = I H^TH = I HTH=I正交性使得H矩阵在学习过程中具有可解释性。(正交性这里应该是广义正交性。)
1) 所有的列向量都是单位正交向量
2) 所有的行向量都是单位正交向量
这里其说白了就是为了限制某一个行、列尽量只有一个较大的数(不一定是1,上述的1只是一个例子。),其他为0。
Here, orthogonality and non-negativity jointly guarantee that each column of H has only one large element and the others are close to zero. These
继而可以写成:
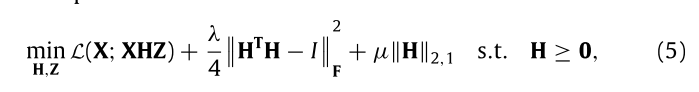
具体实现:
得到这个公式,重点在于
X
H
XH
XH是特征选择的过程(类似编码器的编码过程),Z是恢复矩阵,即从选择的特征中恢复为
X
X
X的过程,即
X
H
Z
XHZ
XHZ是
X
X
X的近似(类似解码器解码)。
所以就得到这个过程优化函数:
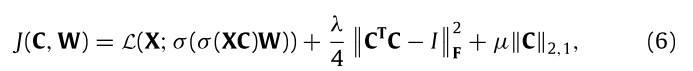
- σ ( X C ) \sigma(XC) σ(XC)作为encoder,用来近似求解XH,C为权重 。
- σ ( σ ( X C ) W ) \sigma(\sigma(XC)W) σ(σ(XC)W)外层的用来近似求解W,W为decoder的权重矩阵
- C T C − I C^TC-I CTC−I为了保证正交性,后面21范数是保证C的稀疏性。
C和W矩阵的梯度更新公式:
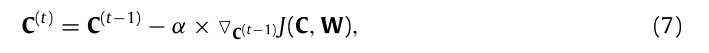
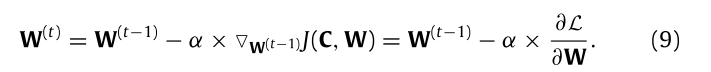
但是要注意一点就是H是非负的,通过梯度训练出来的权重C是可能为负数。解决这个的办法是:

-
E = σ ( X C ) E = \sigma(XC) E=σ(XC)
-
F范数是每个元素平方 求和 再开根号
-
这里是求一个矩阵H,使得等式11最小,是一个优化问题,自变量为H。其他为已知 。
算法过程

要注意的
-
第8步收敛之后,我们使用公式11来计算非负的矩阵H。因为此时 σ ( X H ) 、 X \sigma(XH)、X σ(XH)、X都是已知的了。在此处就是求一个非负的H满足整个等式最小。
-
第9步,这样做是为了让近似的H矩阵中前k个特征选择最明显的留下,其他的都置零。相当于近似保证有k个行的F范数接近于1,留下这k行,其他的清0,才能近似保证只选择k个特征。
实验
待补充,在几个图像数据集上提升效果很好
Reference
[1]. Zhang, Y., Lu, Z., & Wang, S. (2021). Unsupervised feature selection via transformed auto-encoder. Knowledge-Based Systems, 215, 106748. https://doi.org/10.1016/j.knosys.2021.106748















 1738
1738











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









