







flume/kafaka/spqrk测试用例
一、
flume+spark(一)
flume代码
#exec source + memory channel + hdfs sink
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = exec
a2.sources.r1.command = tail -F /opt/tmp/access.log
# hdfs sink
a2.sinks.k1.type = hdfs
a2.sinks.k1.channel = c1
a2.sinks.k1.hdfs.path = /test_logs/events/%y-%m-%d/
a2.sinks.k1.hdfs.filePrefix = events-
# hfds??????????
#a2.sinks.k1.hdfs.round = true
#a2.sinks.k1.hdfs.roundValue = 10
#a2.sinks.k1.hdfs.roundUnit = minute
# hfds??????????? %y-%m-%d
a2.sinks.k1.hdfs.useLocalTimeStamp = true
# ??????,???sequenceFile
a2.sinks.k1.hdfs.fileType = DataStream
# ???????????
a2.sinks.k1.hdfs.rollInterval = 0
# ?????????? ????
# ???? ?????Block??? 128M ~ 120M??
a2.sinks.k1.hdfs.rollSize = 10240
# ???????????,????
a2.sinks.k1.hdfs.rollCount = 0
# Use a channel which buffers events in memory
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
运行flume
flume-ng agent --name a2 --conf /opt/cloudera/parcels/CDH-5.8.4-1.cdh5.8.4.p0.5/lib/flume-ng/conf/ --conf-file /opt/tmp/aa.sh -Dflume.root.logger=INFO,console
运行窗口:
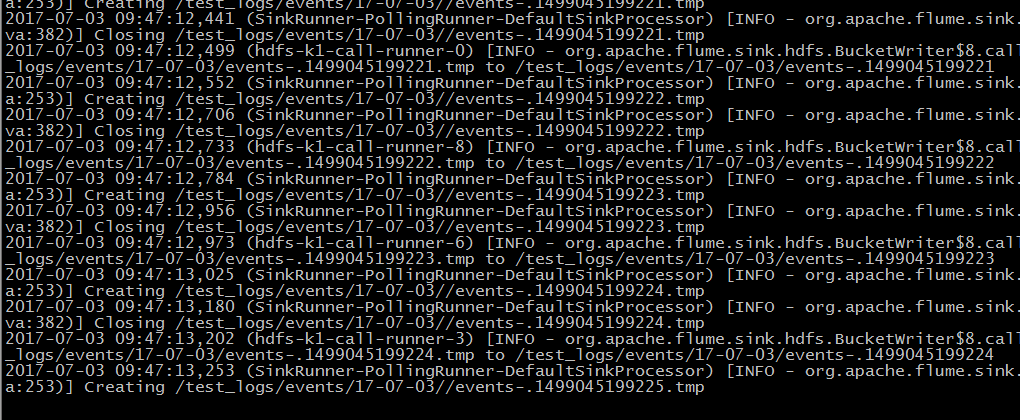
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val ssc = new StreamingContext(sc, Seconds(10))
//读取hdfs上/sdzn_yhhx/tours_details/目录下的文件
val ssc = new StreamingContext(sc, Seconds(2))//Seconds(2)刷新间隔时间
val lines = ssc.textFileStream("hdfs://test:8020/test/")
val words = lines.flatMap(_.split(","))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
wordCounts.saveAsTextFiles("hdfs://test:8020/spark/")//指定计算结果的存储路径
ssc.start()
ssc.awaitTermination()
运行窗口:
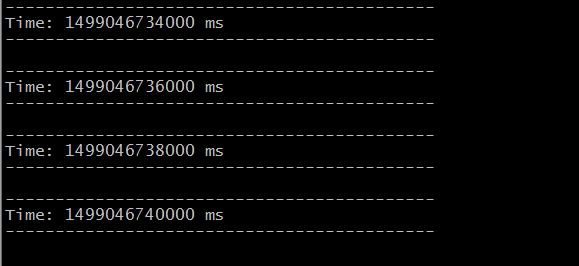
kafka_spark集成
kafka创建话题、消费者、生产者
1、话题
bin/kafka-topics.sh --create --zookeeper 192.168.20.10:2181 --replication-factor 1 --partitions 1 --topic test
2、生产者
bin/kafka-console-producer.sh --broker-list 192.168.20.10:9092 --topic test
3、消费者
bin/kafka-console-consumer.sh --zookeeper 192.168.20.10:2181 --topic test --from-beginnig
bin/spark-shell
import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.streaming.{StreamingContext, Seconds} import org.apache.spark.streaming.kafka._ import kafka.serializer.StringDecoder val ssc = new StreamingContext(sc, Seconds(5)) val kafkaParams = Map("metadata.broker.list" -> "192.168.200.120:9092") val topics = Set("test") val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics).map(_._2) val words = kafkaStream.flatMap(_.split(" ")) val stream = words.map((_, 1)).reduceByKey(_ + _) stream.print() stream.saveAsTextFiles("hdfs://sdzn-cdh02:8020/spark/test") ssc.start() ssc.awaitTermination() ssc.stop()















 606
606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









