







文章目录
窗口函数
OLAP函数,OLAP是online AnalyticalProcessig简称。
常规的SELECT函数是对整个表作查询,而窗口函数可以让我们有选择的去某一部分数据进行汇总、计算和排序。
<窗口函数> OVER ([ PARTITION BY <列名> ]
[ ORDER BY <排序用列名> ])
搞明白RARTITON BY和ORDER BY的作用
PARTITON BY子句可选参数,分组作用,类似于GROUP BY的分组功能,但是PARTITION BY子句并不具备GROUP BY子句的汇总功能,并不会改变原始表中记录的行数。
ORDER BY子句可选参数,指如何对分区中的数据进行排序,按照某种规则(字段)来排序。
两种参数是可选,但是不能同时头没有,至少有一个。
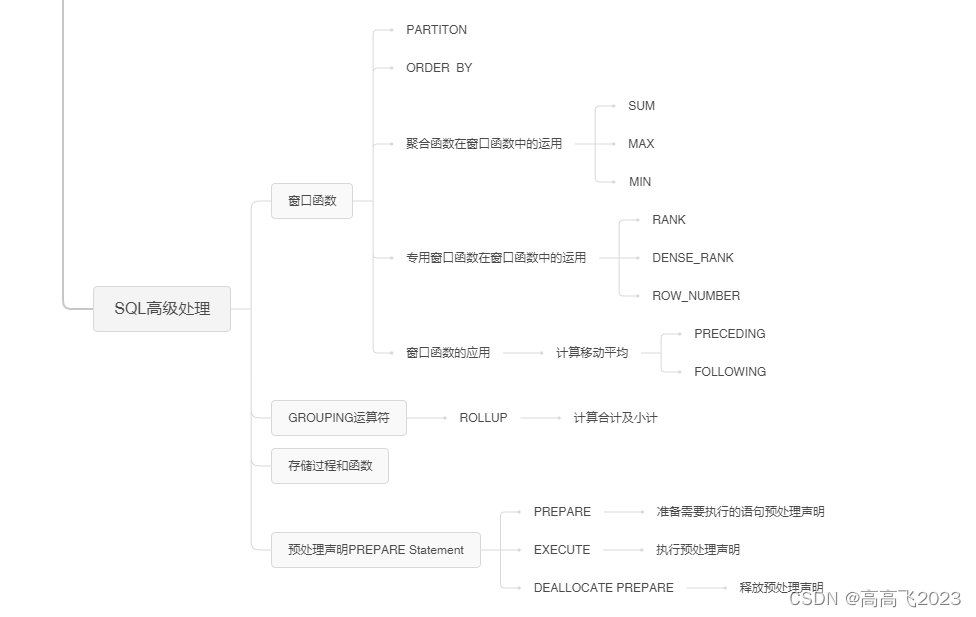
SELECT product_name
,product_type
,sale_price
,RANK() OVER (PARTITION BY product_type
ORDER BY sale_price) AS ranking
FROM product;
PARTITION BY能够设定窗口对象范围。
ORDER BY能够制定按照那一列、何种顺序进行排序。ORDER BY与SELECT语句末尾的ORDER BY一样,可以通过关键字ASC/DESC来指定升序/降序。省略就是默认按照ASC
窗口函数种类
- 聚合函数用来窗口函数中
- 专用函数用在窗口函数中
专用窗口函数
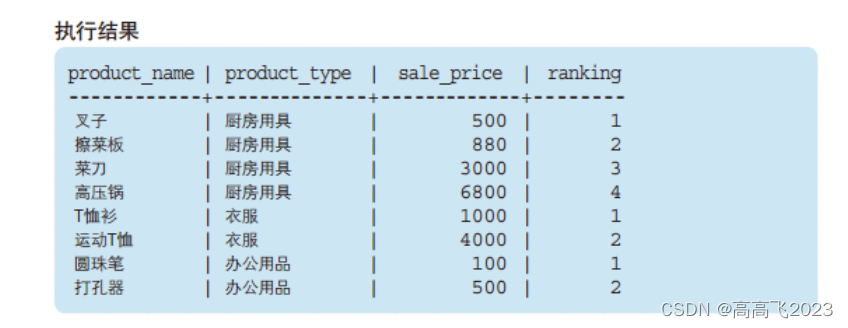
RANK
计算排序,相同位次记录,跳过之后的位次
例:1位、1位、1位、4位
DENSE_RANK
同样是计算排序,即使存在相同位次的记录,也不会跳过之后的位次。
例:1 位、1 位、1 位、2 位……
ROW_NUMBER
赋予唯一的连续位次
例:1位、2位、3位、4位
SELECT product_name
,product_type
,sale_price
,RANK() OVER (ORDER BY sale_price) AS ranking
,DENSE_RANK() OVER (ORDER BY sale_price) AS dense_ranking
,ROW_NUMBER() OVER (ORDER BY sale_price) AS row_num
FROM product;
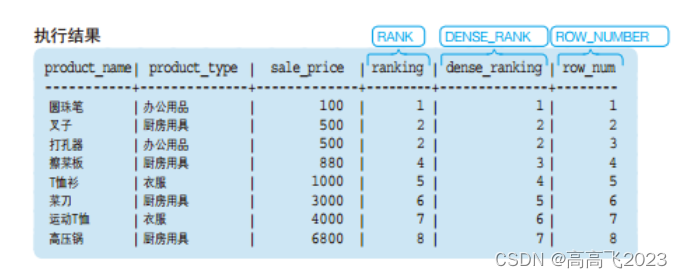
聚合函数在窗口函数上的使用
聚合函数在窗口函数中的使用方法和之前的专用窗口函数一样,只是出来的结果是一个累计的聚合函数值。
SELECT product_id
,product_name
,sale_price
,SUM(sale_price) OVER (ORDER BY product_id) AS current_sum
,AVG(sale_price) OVER (ORDER BY product_id) AS current_avg
FROM product;
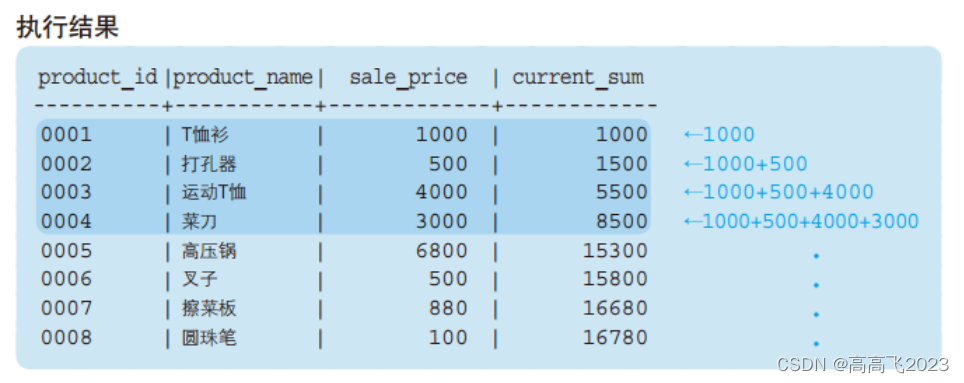
窗口函数的应用–计算移动平均
聚合函数在窗口函数使用时,计算的是累积到当前的所有的数据的聚合。实际上,还可以指定更加详细的汇总范围,称为框架。
PRECEDING(之前),将框架指定为‘’截止到之前n前‘’,加上自身行
FOLLOWING(之后),将框架指定为“截止到之后n行”,加上自身行
SELECT product_id
,product_name
,sale_price
,AVG(sale_price) OVER (ORDER BY product_id
ROWS 2 PRECEDING) AS moving_avg
FROM product;
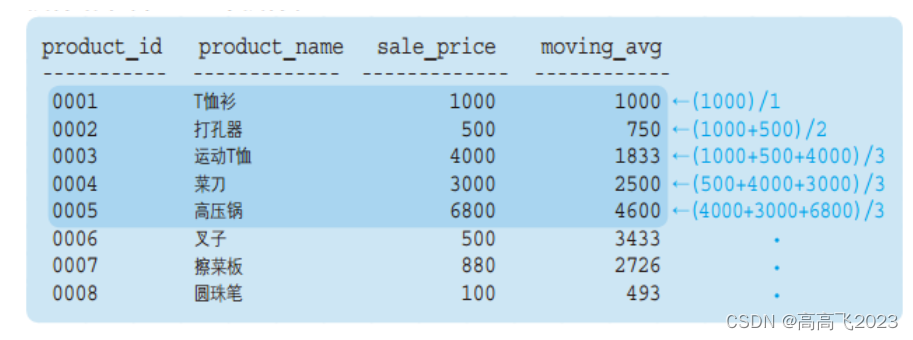
BETWEEN 1 PRECEDING AND 1 FOLLOWING,将框架指定为 “之前1行” + “之后1行” + “自身”
SELECT product_id
,product_name
,sale_price
,AVG(sale_price) OVER (ORDER BY product_id
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS moving_avg
FROM product;
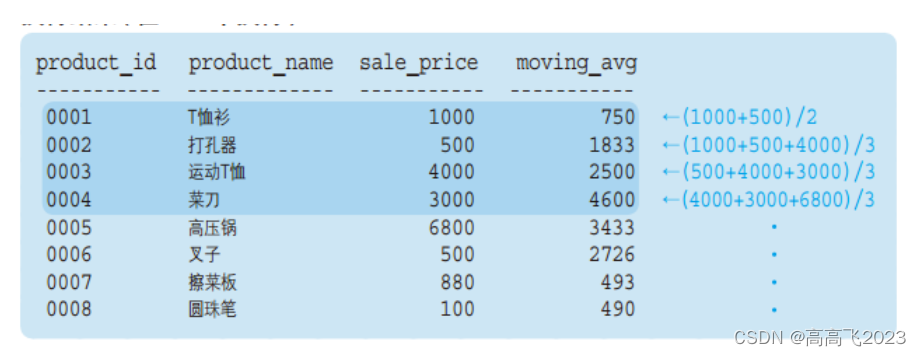
窗口函数适用范围和注意事项
- 窗口函数只能在SELECT句子中使用
- 窗口函数OVER中的ORDER BY 子句并不会影响最终结果的排序。其只是用来决定窗口函数按何种顺序计算。
GROUPING运算符
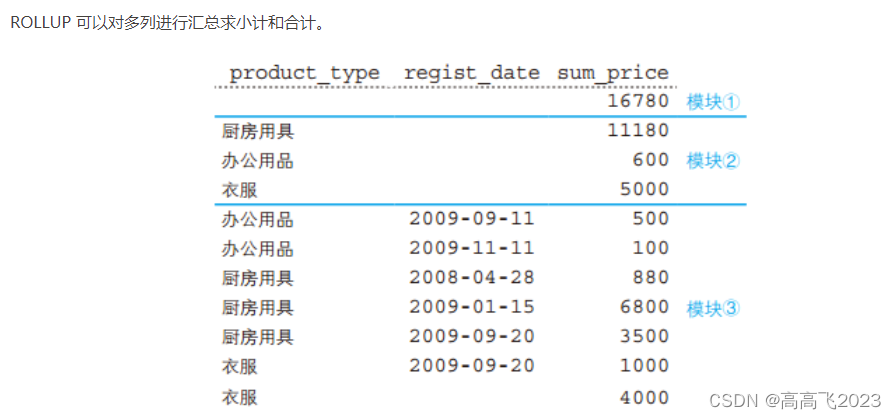
ROLLUO-计算合计及小计
常规的GROUP BY只能得到每个分类的小计,有时候还需要计算分类的合计,可以试用ROLLUP关键字
SELECT product_type
,regist_date
,SUM(sale_price) AS sum_price
FROM product
GROUP BY product_type, regist_date WITH ROLLUP;
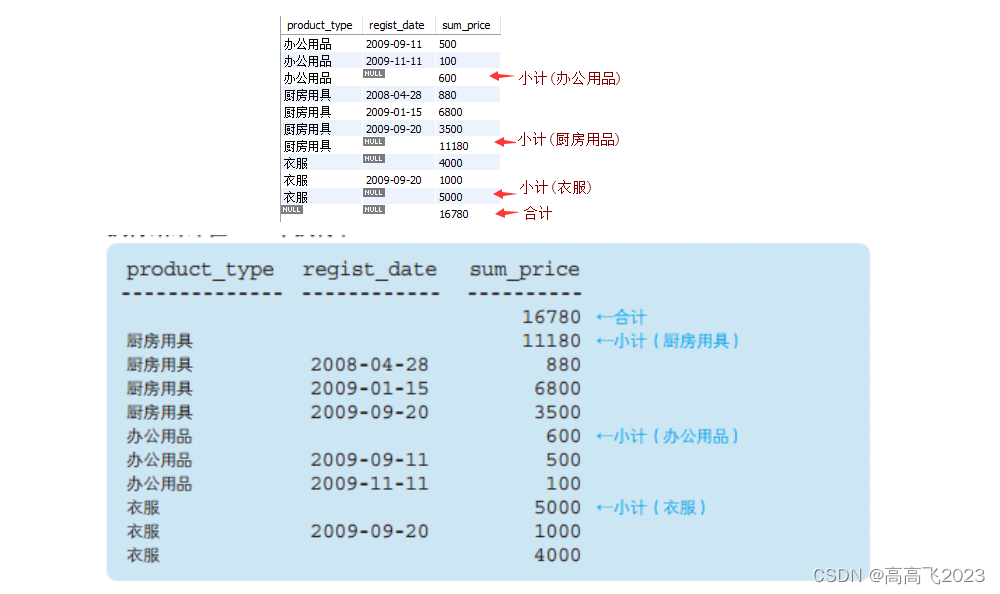
ROLLUP对product_type,regist_date两列进行合计。实际上有三层聚合,如下图 模块3是常规的 GROUP BY 的结果,需要注意的是衣服 有个注册日期为空的,这是本来数据就存在日期为空的,不是对衣服类别的合计; 模块2和1是 ROLLUP 带来的合计,模块2是对产品种类的合计,模块1是对全部数据的总计。
存储过程和函数
基本介绍
基本语法
[delimiter //]($$,可以是其他特殊字符)
CREATE
[DEFINER = user]
PROCEDURE sp_name ([proc_parameter[,...]])
[characteristic ...]
[BEGIN]
routine_body
[END//]($$,可以是其他特殊字符)
这些语句被用来创建一个存储例程(一个存储过程或函数)。也就是说,指定的例程被服务器知道了。默认情况下,一个存储例程与默认数据库相关联。要将该例程明确地与一个给定的数据库相关联,需要在创建该例程时将其名称指定为 db_name.sp_name。
使用 CALL 语句调用一个存储过程。而要调用一个存储的函数时,则要在表达式中引用它。在表达式计算期间,该函数返回一个值。
routine_body 由一个有效的SQL例程语句组成。它可以是一个简单的语句,如 SELECT 或 INSERT,或一个使用 BEGIN 和 END 编写的复合语句。复合语句可以包含声明、循环和其他控制结构语句。在实践中,存储函数倾向于使用复合语句,除非例程主体由一个 RETURN 语句组成。
参数介绍
储存过程和函数的参数有三种:IN、OUT、INOUT
- IN是入参。每个参数默认都是一个 IN 参数。如需设定一个参数为其他类型参数,请在参数名称前使用关键字 OUT 或 INOUT 。一个IN参数将一个值传递给一个过程。存储过程可能会修改这个值,但是当存储过程返回时,调用者不会看到这个修改。
- OUT 是出参。一个 OUT 参数将一个值从过程中传回给调用者。它的初始值在过程中是 NULL ,当过程返回时,调用者可以看到它的值
对于每个 OUT 或 INOUT 参数,在调用过程的 CALL 语句中传递一个用户定义的变量,以便在过程返回时可以获得其值。如果你是在另一个存储过程或函数中调用存储过程,你也可以将一个常规参数或本地常规变量作为 OUT 或 INOUT 参数传递。如果从一个触发器中调用存储过程,也可以将 NEW.col_name 作为一个 OUT 或 INOUT 参数传递。
应用案例
- 查询 下面的示例显示了一个简单的存储过程,给定一个国家代码,计算在 world 数据库的城市表中出现的该国家的城市数量。使用 IN 参数传递国家代码,使用 OUT 参数返回城市计数
mysql> DELIMITER //
mysql> DROP PROCEDURE IF EXISTS citycount //
Query OK, 0 rows affected (0.01 sec)
mysql> CREATE PROCEDURE citycount (IN country CHAR(3), OUT cities INT)
BEGIN
SELECT COUNT(*) INTO cities FROM world.city
WHERE CountryCode = country;
END//
Query OK, 0 rows affected (0.01 sec)
mysql> DELIMITER ;
mysql> CALL citycount('CHN', @cities); -- cities in China
Query OK, 1 row affected (0.01 sec)
-> SELECT @cities;
+---------+
| @cities |
+---------+
| 363 |
+---------+
1 row in set (0.04 sec)
- 创建表
mysql> use world;
Database changed
mysql> DELIMITER $$
mysql> CREATE DEFINER=`root`@`localhost` PROCEDURE `product_test`()
BEGIN
#Routine body goes here...
CREATE TABLE product_test like shop.product;
END$$
Query OK, 0 rows affected (0.01 sec)
mysql> DELIMITER;
mysql> call `product_test`();
Query OK, 0 rows affected (0.04 sec)
mysql> show tables;
+-----------------+
| Tables_in_world |
+-----------------+
| city |
| country |
| countrylanguage |
| product_test |
+-----------------+
4 rows in set (0.02 sec)
- 插入数据
CREATE DEFINER=`root`@`localhost` PROCEDURE `insert_product_test`()
BEGIN
declare i int;
set i=1;
while i<9 do
set @pcid = CONCAT('000', i);
PREPARE stmt FROM 'INSERT INTO product_test() SELECT * FROM shop.product where product_id= ?';
EXECUTE stmt USING @pcid;
set i=i+1;
end while;
END
预处理声明 PREPARE Statement
MySQL从4.1版本开始引入PREPARE Statement特性,使用client/server binary protocol 代替textual protocol其将包含占位符()的查询传递给MySQL服务器,如以下示例所示:
SELECT *
FROM products
WHERE productCode = ?;
当MySQL使用不同的 productCode 值执行此查询时,它不必完全解析查询。因此,这有助于MySQL更快地执行查询,特别是当MySQL多次执行相同的查询时。productcode
由于预准备语句使用占位符 (),这有助于避免 SQL 注入的许多变体,从而使应用程序更安全。
PREPARE stmt_name FROM preparable_stmt
使用步骤
``MySQL PREPARE Statement 使用步骤如下:
- PREPARE-准备需要执行的语句预处理声明
- EXECUTE-执行预处理声明
- DEALLOCATE PREPARE-释放预处理声明
下图说明了预处理声明的使用过程
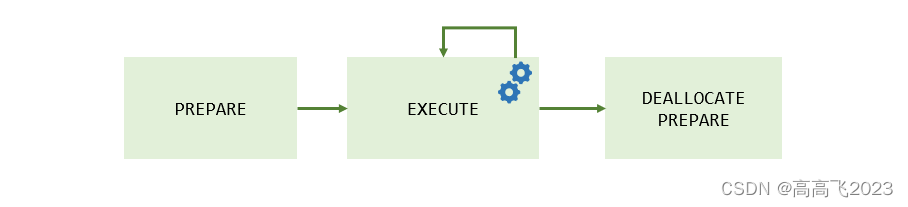
使用示例
定义预处理声明如下:
PREPARE stmt1 FROM
'SELECT
product_id,
product_name
FROM product
WHERE product_id = ?';
第二步,声明变量pcid,代表商品编号,并将其值设置为0005;
SET @pcid = '0005';
第三步,执行预处理声明;
EXECUTE stmt1 USING @pcid;
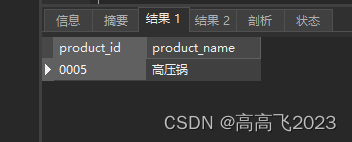
第四步,为变量pcid分配另外一个商品的编号;
SET @pcid = '0008';
第五步,使用新的商品编号执行预处理声明;
EXECUTE stmt1 USING @pcid;
第六步,释放预处理声明释放其占用的资源
DEALLOCATE PREPARE stmt1;















 30
30











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









