







本文仅供参考学习,如有侵权,请联系作者删。
目标网站:aHR0cHM6Ly93d3cuYmlsaWJpbGkuY29tL3ZpZGVvL0JWMWVVNDExbzdxcA==
上课!!!(写在前面)
有时候js逆向也是很简单的一件事,不要想的那么复杂,js逆向如果代码简单,完全可以用python算法还原代替,不用老老实实一步一步跟着网站的js去做。
找到目标请求包
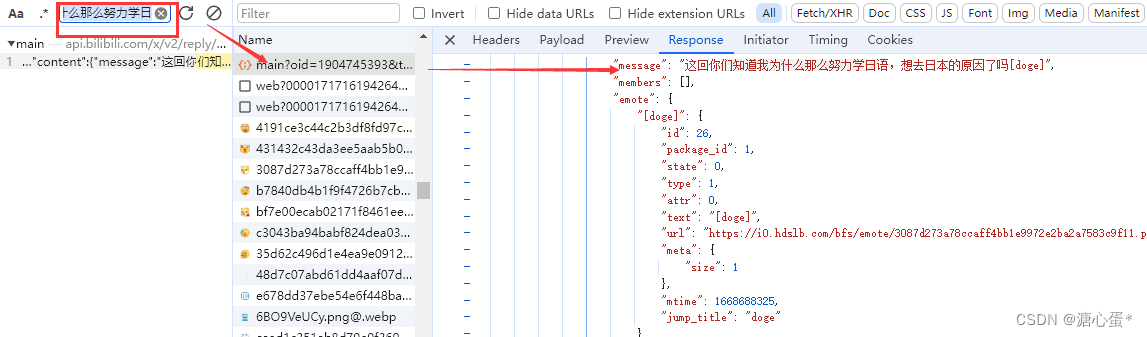
咱就是说,直接search评论的内容,找到目标请求发的包。
curl 大法
通过将目标包的curl复制下来,获取到 headers 和 cookies,再注意排除参数。具体方法在我之前的文章有写过就不再赘述了。
包含curl详细分析的链接
最后得出结果:
- 只需要headers中的UA即可请求。
请求参数
通过不同的视频链接评论得到如下:
# 每一条视频的oid不一样,wts是目前请求的时间戳, w_rid 是变值,可以怀疑加密
{
"oid": "视频的id", # 变值
"type": "1", # 固定值
"mode": "2", # 固定值
"pagination_str": "{\"offset\":\"\"}", # 页数信息
"plat": "1", # 固定值
"web_location": "1315875", # 固定值
"w_rid": "aa0d326e91ff1afd8783f029b2aee993", # 加密值
"wts": "1716191206" # 时间戳
}
w_rid 的 分析
定位生成位置
w_rid 的值肯定是在js中生成的,请求的包是发送的 fetch 请求
- 打xhr断点,找分析的位置
- 全局搜索w_rid的值,在每个位置都打断点
- 观察,因为是32位数字和字符串组成的,可以猜想是 md5 的加密。
方法很多就不一样讲解了,主要是方法2是最常用的。
断点分析
往下滑网页,在断点处暂停

直接断住,可以看到
控制台输出:

>> ee
'mode=2&oid=1904745393&pagination_str=%7B%22offset%22%3A%22%7B%5C%22type%5C%22%3A3%2C%5C%22direction%5C%22%3A1%2C%5C%22Data%5C%22%3A%7B%5C%22cursor%5C%22%3A2270%7D%7D%22%7D&plat=1&type=1&web_location=1315875&wts=1716195383'
>> H
'ea1db124af3c7062474693fa704f4ff8'
>> K
1716195383
>> ee + H
'mode=2&oid=1904745393&pagination_str=%7B%22offset%22%3A%22%7B%5C%22type%5C%22%3A3%2C%5C%22direction%5C%22%3A1%2C%5C%22Data%5C%22%3A%7B%5C%22cursor%5C%22%3A2270%7D%7D%22%7D&plat=1&type=1&web_location=1315875&wts=1716195383ea1db124af3c7062474693fa704f4ff8'
>> md5(ee + H)
'7dfe2e3a5b400d4f77a59a05ad116df1'
| 请求参数 | 含义 |
|---|---|
| ee | url 带的请求参数 |
| H | 固定值 |
| K | 时间戳(10位) |
w_rid 就是将参数拼接起来然后运用md5算法加密,还很规范。

wts 就是现在的时间戳。
生成出来加密就ok啦。
还有一件事
- 关于翻页
网站不支持从第一页到第三页,必须要连续的翻。
因为第二页的请求参数在第一页请求的返回值中,所以只能一页一页请求。
看一下效果
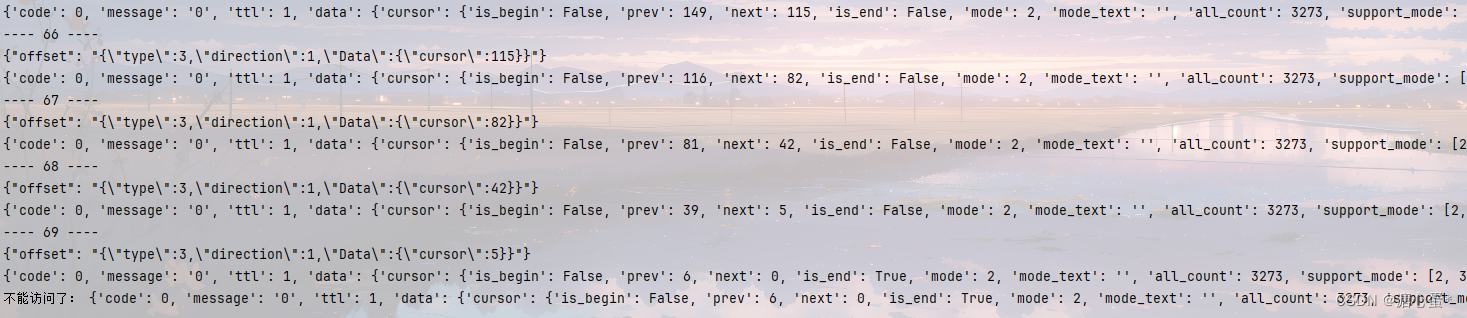
不能访问是因为参数中没有 下一页的参数了,目前 7000+ 评论可以拿到。
秒了~

















 718
718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











