






 文章分析了B站小米汽车技术发布会的弹幕数据,包括爬取、数据处理、情感分析、词云图、时间和内容热点。结果显示网友对小米汽车期待与质疑并存,且用户活跃高峰在晚上18-23时,视频内容的电机和电池部分引发大量讨论。
文章分析了B站小米汽车技术发布会的弹幕数据,包括爬取、数据处理、情感分析、词云图、时间和内容热点。结果显示网友对小米汽车期待与质疑并存,且用户活跃高峰在晚上18-23时,视频内容的电机和电池部分引发大量讨论。
一.背景
B站上面一个 小米汽车技术发布会回放 的视频受到众多网友的浏览,用户浏览量达到了20W+,填充弹幕数量6000+。我对该视频也比较感兴趣,因此对该视频进行了弹幕爬取,进行数据分析。
二.获取弹幕数据
1.通过python爬取该视频的弹幕信息(主要使用request)。

2.将爬取的数据导出为excel文件。

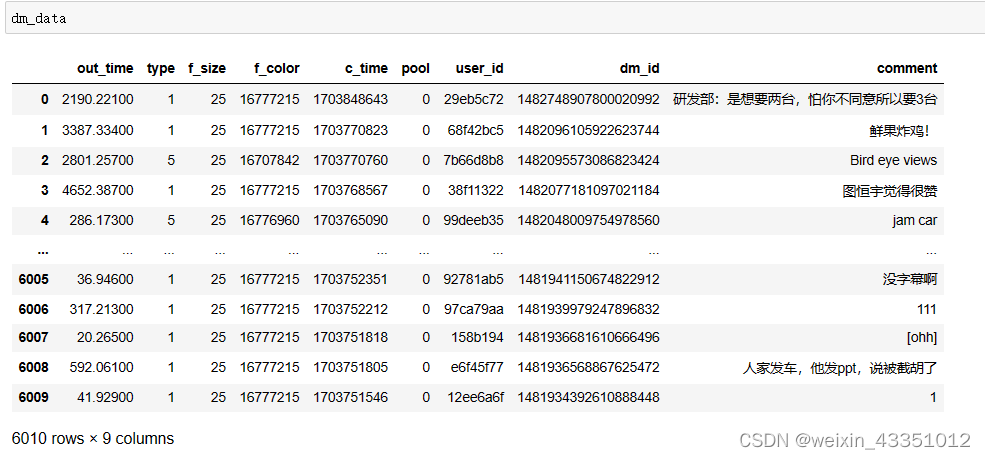
一共爬取到6010条弹幕。
三.数据处理与分析
1.数据预处理
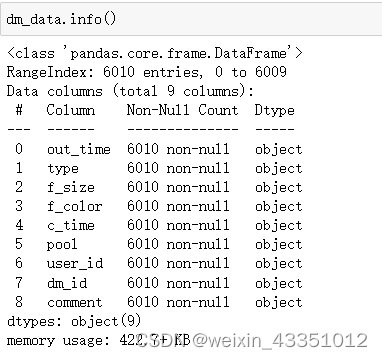
可以看到现在所有数据的类型都是字符类型,为了后续的数据分析进行操作,使用astype方法对某些属性进行类型转换。
2.弹幕词云图


去掉了停用词后,得出上面的词云图。从词云图可以看出网友们对小米汽车还是很期待的,图中也出现了华为、比亚迪、特斯拉等关键词,看来网友也是将小米和其他车企进行了一番比较。同时还能看出雷总不愧是米粉以及众多网友心中小米最好的代言人之一。
3.情感分析
需要使用的是snownlp,返回弹幕评分越高表示越积极。

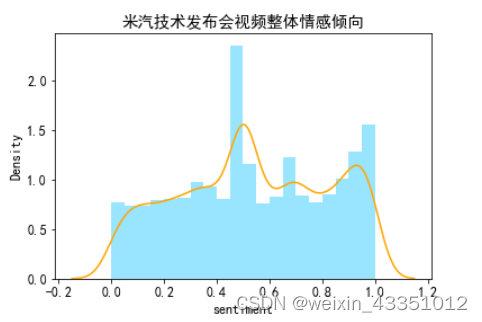
为了更直观的弹幕的总体情感倾向,将弹幕的情感评分>0.75的弹幕选作积极弹幕,<0.5的作为消极弹幕,如下:
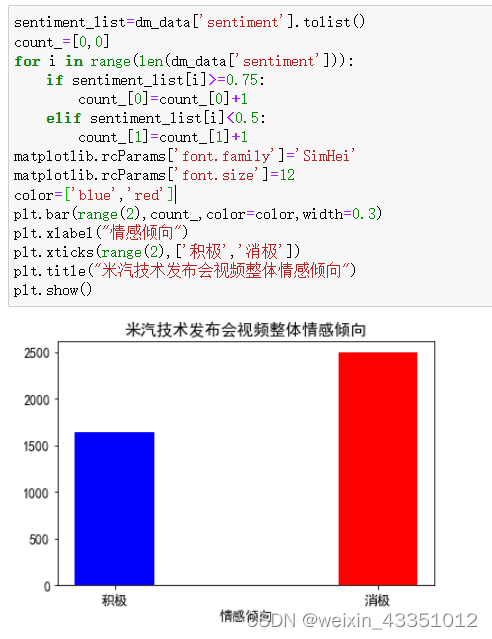
结合以上两图中可以看出(按情感评分>0.75的弹幕选作积极弹幕,<0.5的作为消极弹幕的标准),消极的弹幕比积极的弹幕数量要多。估计是网友们对小米第一次造汽车还持有怀疑的态度,或者是这次的技术发布会没有公布汽车的价格等原因。

根据sentiments对所有弹幕进行分析来看,平均值为0.53左右,标准差为0.28,总体数据评分比较离散,整体表现出网友对小米汽车的评价是褒贬不一。
4.时间分析
时间分析是很重要的,可以从中看出网友/用户的行为习惯,可以了解到他们不同时间段的偏好与活动,从而大致推断出这类视频发布的最佳时间、用户活跃高峰时间段、最受欢迎的服务/信息等等。
将时间戳转换为常见的日期格式,然后根据转换后的日期信息进行数据时间分析。
首先对日期信息进行分析,查看不同日期的弹幕数量变化。
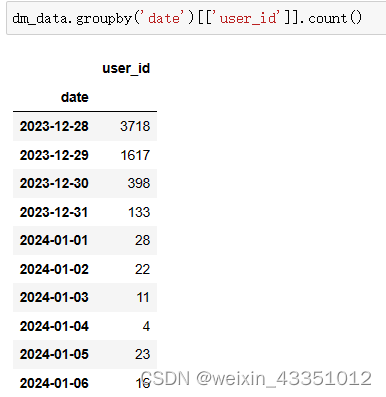
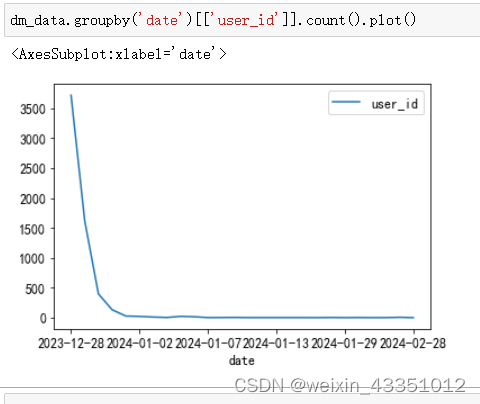
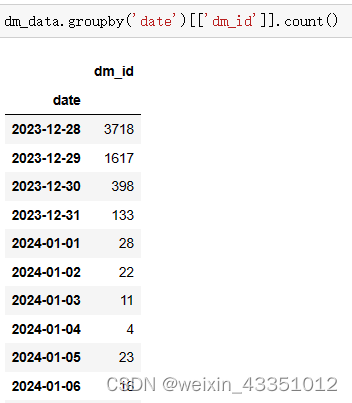
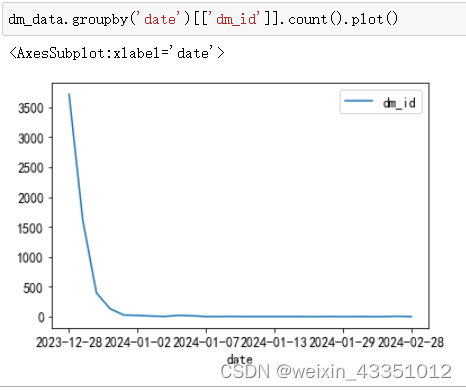
为了防止个别用户刷弹幕数量导致分析结果不准确的情况,分别根据用户id和弹幕id进行统计,从以上的图可以看出,统计的结果是相似的。弹幕数量从视频发布那天起,随着日期的增长一直下降的。可以大致的判断出这类视频的热度和流量基本是在视频发布的一周内的,热度的高点一般是前三天之内。


根据小时进行数据分析。从上两图可以看到,弹幕从16时到20时,弹幕数量都在增加,到20时达到了顶峰,这个时刻的弹幕有1011条。从中可以大致推断出用户浏览此类视频大多数在18-23时之间,制作这种类型的视频,应该在18时之前发布视频,这样或许可以让视频的浏览量更多。
(由于该视频弹幕内容主要在1周内,所有没有进行月/周/天的分析。月/周/天的分析过程跟小时相差无几)。
5.内容分析
根据发送弹幕的时间,对视频的内容进行分析,可以了解到什么时刻的什么内容引起网友发弹幕的兴趣,从而知道网友偏好什么信息。

取 弹幕数/秒 前十的视频进度,对视频的内容进行分析,从上图看出,视频的弹幕数量较多的在11分钟和18分钟的时候,具体的视频内容看下图:

在11分钟的时候,视频的主要内容是小米超级电机,也是这个发布会着重讲解的技术之一,看来网友们对小米汽车的电机充满期待。

在18分钟的时候,视频的主要内容是小米汽车的电池,是这发布会的第二个要介绍的技术,小米汽车的电池引起的网友们的讨论。
最后,查看一下法弹幕数量最多的前三位。

发弹幕最多的用户发了67条,想必该位用户在观看这场发布会回放的时候,一定是表达了很多自己独到的见解。

















 221
221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









