






推荐算法–协同过滤
什么是协同过滤
协同过滤推荐(Collaborative Filtering recommendation)是在信息过滤和信息系统中正迅速成为一项很受欢迎的技术。与传统的基于内容过滤直接分析内容进行推荐不同,协同过滤分析用户兴趣,在用户群中找到指定用户的相似(兴趣)用户,综合这些相似用户对某一信息的评价,形成系统对该指定用户对此信息的喜好程度预测。
协同过滤是迄今为止最成功的推荐系统技术,被应用在很多成功的推荐系统中。电子商务推荐系统可根据其他用户的评论信息,采用协同过滤技术给目标用户推荐商品。
协同过滤算法主要分为基于启发式和基于模型式两种。
其中,基于启发式的协同过滤算法,又可以分为基于用户的协同过滤算法(User-Based)和基于项目的协同过滤算法(Item-Based)。
启发式协同过滤算法主要包含3个步骤:
1)收集用户偏好信息;
2)寻找相似的商品或者用户;
3)产生推荐。
“巧妇难为无米之炊”,协同过滤的输入数据集主要是用户评论数据集或者行为数据集。这些数据集主要又分为显性数据和隐性数据两种类型。其中,显性数据主要是用户打分数据,譬如用户对商品的打分,五分制的1分,2分等。
但是,显性数据存在一定的问题,譬如用户很少参与评论,从而造成显性打分数据较为稀疏;用户可能存在欺诈嫌疑或者仅给定了部分信息;用户一旦评分,就不会去更新用户评分分值等。
而隐性数据主要是指用户点击行为、购买行为和搜索行为等,这些数据隐性地揭示了用户对商品的喜好。
隐性数据也存在一定的问题,譬如如何识别用户是为自己购买商品,还是作为礼物赠送给朋友等。
1.基于用户的协同过滤
用相似统计的方法得到具有相似爱好或者兴趣的相邻用户,所以称之为以用户为基础(User-based)的协同过滤或基于邻居的协同过滤(Neighbor-based Collaborative Filtering)。
1.1方法步骤:
1.收集用户信息
收集可以代表用户兴趣的信息。一般的网站系统使用评分的方式或是给予评价,这种方式被称为“主动评分”。另外一种是“被动评分”,是根据用户的行为模式由系统代替用户完成评价,不需要用户直接打分或输入评价数据。电子商务网站在被动评分的数据获取上有其优势,用户购买的商品记录是相当有用的数据。
2.最近邻搜索(Nearest neighbor search, NNS)
以用户为基础(User-based)的协同过滤的出发点是与用户兴趣爱好相同的另一组用户,就是计算两个用户的相似度。例如:查找n个和A有相似兴趣用户,把他们对M的评分作为A对M的评分预测。一般会根据数据的不同选择不同的算法,目前较多使用的相似度算法有Pearson Correlation Coefficient(皮尔逊相关系数)、Cosine-based Similarity(余弦相似度)、Adjusted Cosine Similarity(调整后的余弦相似度)。
基于用户(User-Based)的协同过滤算法首先要根据用户历史行为信息,寻找与新用户相似的其他用户;同时,根据这些相似用户对其他项的评价信息预测当前新用户可能喜欢的项。
给定用户评分数据矩阵R,基于用户的协同过滤算法需要定义相似度函数s:U×U→R,以计算用户之间的相似度,然后根据评分数据和相似矩阵计算推荐结果。
1.2如何选择合适的相似度计算方法
在协同过滤中,一个重要的环节就是如何选择合适的相似度计算方法,常用的两种相似度计算方法包括皮尔逊相关系数和余弦相似度等。皮尔逊相关系数的计算公式如下所示: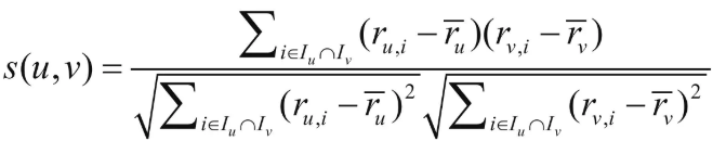
皮尔逊相关系数
其中,i表示项,例如商品;Iu表示用户u评价的项集;Iv表示用户v评价的项集;ru,i表示用户u对项i的评分;rv,i表示用户v对项i的评分;表示用户u的平均评分;表示用户v的平均评分。
另外,余弦相似度的计算公式如下所示: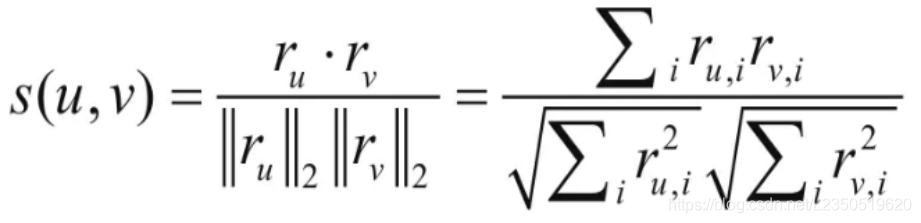
余弦相似度
1.3计算用户u对未评分商品的预测分值
另一个重要的环节就是计算用户u对未评分商品的预测分值。首先根据上一步中的相似度计算,寻找用户u的邻居集N∈U,其中N表示邻居集,U表示用户集。然后,结合用户评分数据集,预测用户u对项i的评分,计算公式如下所示: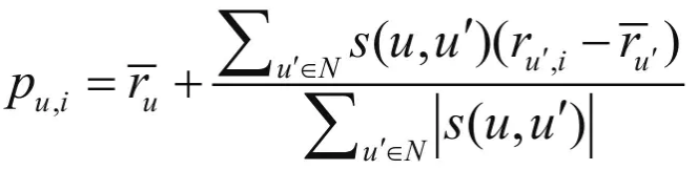
预测用户u对项i的评分
其中,s(u,u’)表示用户u和用户u’的相似度。
1.4通过例子理解
假设有如下电子商务评分数据集,预测用户C对商品4的评分。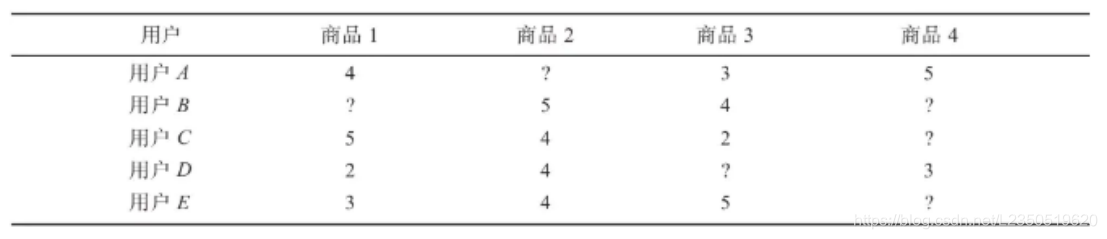
电子商务评分数据集
表中?表示评分未知。根据基于用户的协同过滤算法步骤,计算用户C对商品4的评分,其步骤如下所示。
(1)寻找用户C的邻居
从数据集中可以发现,只有用户A和用户D对商品4评过分,因此候选邻居只有2个,分别为用户A和用户D。用户A的平均评分为4,用户C的平均评分为3.667,用户D的平均评分为3。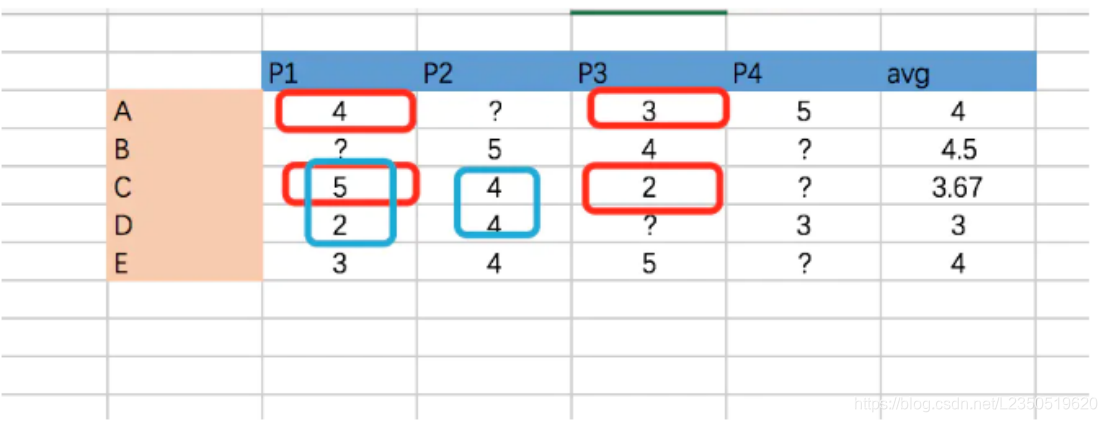
根据皮尔逊相关系数公式:
红色区域计算C用户与A用户,用户C和用户A的相似度为: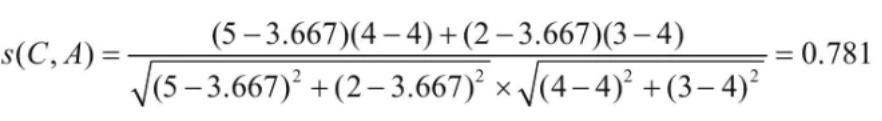
蓝色区域计算C用户与D 用户的相似度为: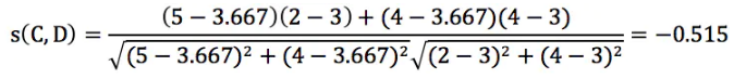
C用户与D 用户的相似度
(2)预测用户C对商品4的评分
根据上述评分预测公式,计算用户C对商品4的评分,如下所示: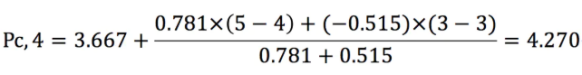
用户C对商品4的评分
依此类推,可以计算出其他未知的评分。
1.5代码实现
import numpy as np
from math import sqrt
def pex(ls_1,ls_2,M): #求余弦相似度的函数
fenzi=0#余弦相似度分子
fenmu=0#分母
abs_1=0#分母左边绝对值里的值
abs_2=0#分母右边绝对值里的值
for i in range(M):
fenzi += ls_1[i] * ls_2[i]
abs_1 += pow(ls_1[i],2)
abs_2 += pow(ls_2[i],2)
fenmu=sqrt(abs_1*abs_2)
return fenzi/fenmu#ls_1,ls_2用户相关系数
def yuping(lst_u,R,u_u,M,N,n):#求预测评分函数
fenzi=0
fenmu=0
aver_1=0#平均值
aver_2=0
a=0#当前用户购买物品数量
b=0
for i in range(M):
if lst_u[i]!=0:
a+=1
aver_1 +=lst_u[i]
aver_1=aver_1/a
for o in range(N):
if R[o][m]!=0:
for i in range(M):
if R[o][i]!=0:
b+=1
aver_2 +=R[o][i]
aver_2=aver_2*1.00/b
fenzi+=u_u[n][o]*(R[o][m]-aver_2)
fenmu+=abs(pex(lst_u,R[o],M))
return aver_1+fenzi*1.00/fenmu
R=np.array([[4.,0.,3.,5.],#生成原始矩阵R
[0.,5.,4.,0.],
[5.,4.,2.,0.],
[2.,4.,0.,1.],
[3.,4.,5.,0.]]) #输入二维数组,同行数字用空格分隔,不同行则用回车换行
N=len(R)#列长
M=len(R[0])#行长
u_u=np.zeros((N,N))#建立用户与用户之间相关性矩阵u_u
for n in range(N):#建立一个对R的循环筛选未评分item并进行预测评分
for m in range(N):
if n<m:
u_u[n][m]=pex(R[n],R[m],M)
u_u[m][n]=u_u[n][m]
print("得到的用户-用户相似度矩阵:")
print(u_u)#打印用户与用户相关系数矩阵
user=['A','B','C','D','E']#用户集合
items=['p1','p2','p3','p4']#商品集合
for n in range(N):#建立一个对R循环寻找未评分项并且对未评分项进行预测
for m in range(M):
if R[n][m]==0:
R[n][m]=yuping(R[n],R,u_u,M,N,n)
if R[n][m]>3:
print("将商品{:}推荐给用户{:}".format(items[m],user[n]))
print("评分预测矩阵R^:")
print("{:.2f}".format(R))
2.基于项目的协同过滤
以用户为基础的协同推荐算法随着用户数量的增多,计算的时间就会变长,所以在2001年Sarwar提出了基于项目的协同过滤推荐算法(Item-based Collaborative Filtering Algorithms)。以项目为基础的协同过滤方法有一个基本的假设“能够引起用户兴趣的项目,必定与其之前评分高的项目相似”,通过计算项目之间的相似性来代替用户之间的相似性。
2.1方法步骤:
1.收集用户信息
同以用户为基础(User-based)的协同过滤。
2.针对项目的最近邻搜索
先计算已评价项目和待预测项目的相似度,并以相似度作为权重,加权各已评价项目的分数,得到待预测项目的预测值。例如:要对项目 A 和项目 B 进行相似性计算,要先找出同时对 A 和 B 打过分的组合,对这些组合进行相似度计算,常用的算法同以用户为基础(User-based)的协同过滤。
3.产生推荐结果
以项目为基础的协同过滤不用考虑用户间的差别,所以精度比较差。但是却不需要用户的历史数据,或是进行用户识别。对于项目来讲,它们之间的相似性要稳定很多,因此可以离线完成工作量最大的相似性计算步骤,从而降低了在线计算量,提高推荐效率,尤其是在用户多于项目的情形下尤为显著。
基于项目(Item-Based)的协同过滤算法是常见的另一种算法。与User-Based协同过滤算法不一样的是,Item-Based协同过滤算法计算Item之间的相似度,从而预测用户评分。也就是说该算法可以预先计算Item之间的相似度,这样就可提高性能。Item-Based协同过滤算法是通过用户评分数据和计算的Item相似度矩阵,从而对目标Item进行预测的。
2.2相似度计算方法
和User-Based协同过滤算法类似,需要先计算Item之间的相似度。并且,计算相似度的方法也可以采用皮尔逊关系系数或者余弦相似度,这里给出一种电子商务系统常用的相似度计算方法,即基于物品的协同过滤算法,其中相似度计算公式如下所示: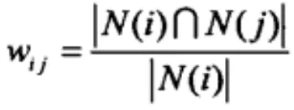
这里,分母|N(i)|是喜欢物品i的用户数,而分子|N(i)∩N(j)|是同时喜欢物品i和j的用户,但是如果物品j很热门,就会导致Wij很大接近于1。因此避免推荐出热门的物品,我们使用下面的公式: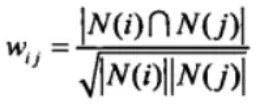
这里的分子是共同喜欢物品i和物品j的用户数
分母是喜欢物品i的用户数和喜欢物品j的用户数乘积开根号
基于物品的相似度
从上面的定义可以看出,在协同过滤中两个物品产生相似度是因为他们共同被很多用户喜欢,也就是说每个用户都可以通过他们的历史兴趣列表给物品“贡献”相似度。
计算物品相似度首先建立用户-物品倒排表(即对每个用户建立一个包含他喜欢的物品的列表),然后对每个用户,将他物品列表中的物品两两在共现矩阵中加1。
若用户的访问记录如下:
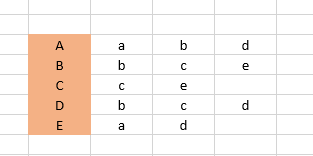
则相似度函数的代码
图例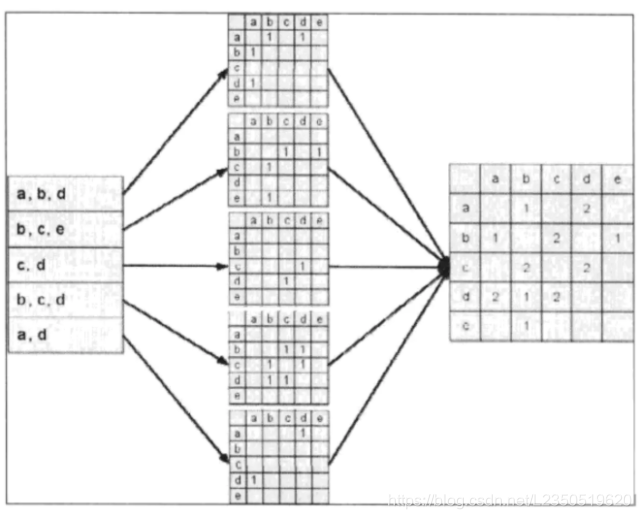
根据矩阵计算每两个物品之间的相似度wij。
///若想了解整个过程的具体代码,私信。
2.3用户u对于物品j的兴趣
得到物品之间的相似度后,可以根据如下公式计算用户u对于物品j的兴趣:
用户u对于物品j的兴趣
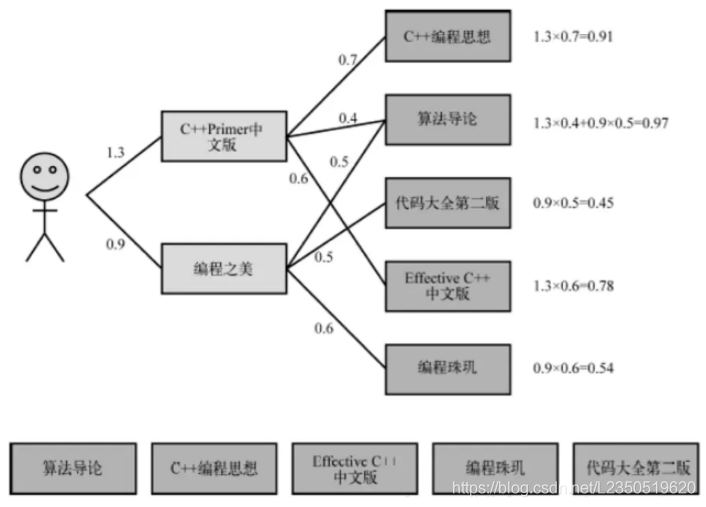
这里N(u)是用户喜欢的物品的集合,S(j,K)是和物品j最相似的K个物品的集合,wji是物品j和i的相似度,rui是用户u对物品i的兴趣。(对于隐反馈数据集,如果用户u对物品i有过行为,即可令rui=1。)该公式的含义是,和用户历史上感兴趣的物品越相似的物品,越有可能在用户的推荐列表中获得比较高的排名。
当我们看到这里的时候很可能由于自己功底不足,很难看懂公式中的i∈N(u)∩S(j,K)。
我们来看另外一种计算方式: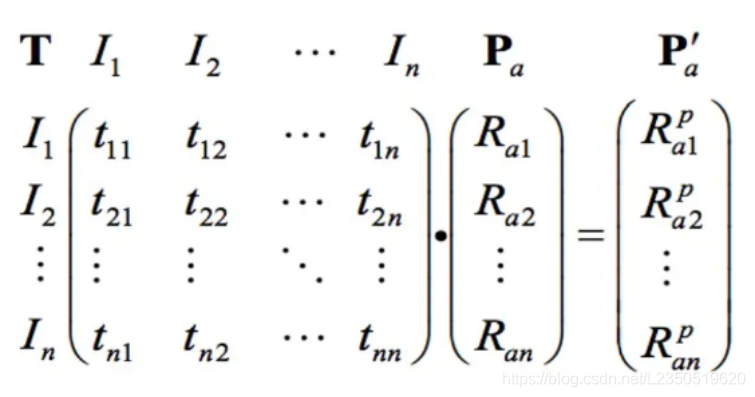
矩阵
其中,Pa为新用户对已有产品的向量,T为物品的共现矩阵,得到的P`a为新用户对每个产品的兴趣度。
那么就可以理解上述公式的i∈N(u)∩S(j,K),我们在下面的例子中详细讲解。
2.4举例
现有用户的访问的记录如下图所示:
用户的访问
喜欢物品i也喜欢物品j的人数的共现矩阵: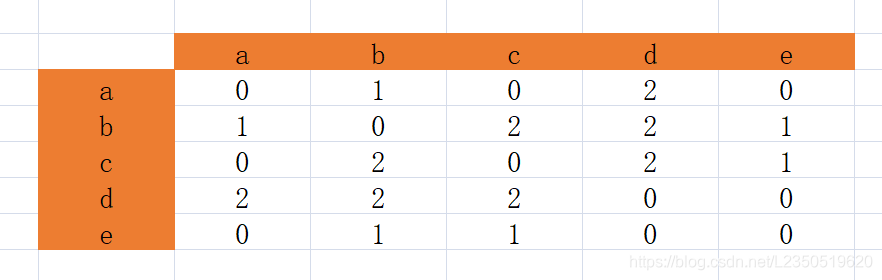
喜欢物品i的总人数
a:2 b:3 c:3 d:4 e:1
共现矩阵
通过公式计算相似度:Wa,b在这里插入图片描述
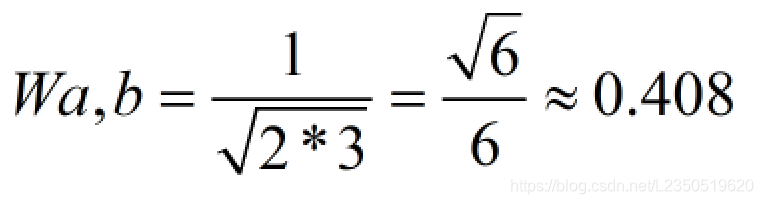
以此类推得到相似度的共现矩阵: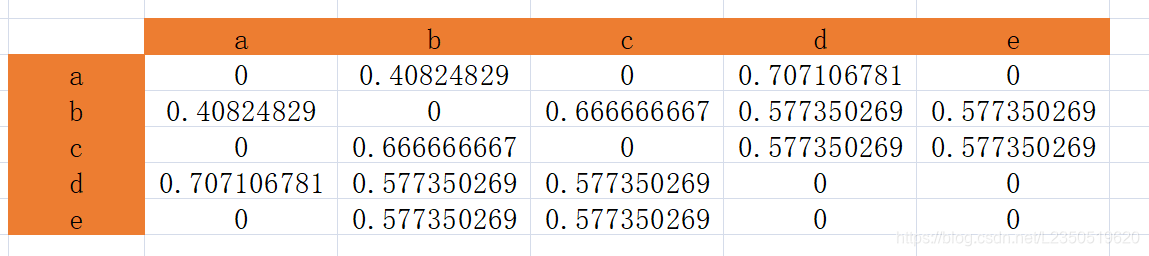
相似度的共现矩阵
此时对于用户A,访问的a,b,d三个物品,那么可以看做向量P:
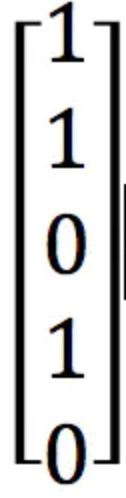
那么P`为矩阵相乘:
P`
此时得到了对于用户A,c和e的兴趣度,由于c的兴趣度大于d的兴趣度,因此把物品c推荐给用户E。
2.5理解公式i∈N(u)∩S(j,K)
那么现在我们来理解公式i∈N(u)∩S(j,K):
对于用户A,已经访问了a,b,d,那么,N(u)={a,b,d};还有两个未访问物品c,e,那么j={c,e};
当j=c时,对于和物品j最相似的K个物品的集合为{b,d},那么S(j,K)={b,d};得出N(u)∩S(j,K)={b,d},如下图所示:
再来看矩阵相乘中的c行,乘以P,实际上就是上述N(u)∩S(j,K)={a,d}的相似度求和。
同理,当j=e时,对于和物品j最相似的K个物品的集合为{b,c},那么S(j,K)={b,c};得出N(u)∩S(j,K)={b};
再来看矩阵相乘中的e行,乘以P,实际上就是上述N(u)∩S(j,K)={b,d}的相似度求和。
2.6代码实现
第一种实现方法:
用户/物品 | 物品a | 物品b | 物品c | 物品d | 物品e |
用户A | √ | √ | | √ | |
用户B | | √ | √ | | √ |
用户C | | | √ | | √ |
用户d | | √ | √ | √ | |
用户e | √ | | | √ | |
————————————————
from math import sqrt
import operator
# 1.构建用户-->物品的倒排
def loadData(files):
data = {}
for line in files:
user, score, item = line.split(",")
data.setdefault(user, {})
data[user][item] = score
print("----1.用户:物品的倒排----")
print(data)
return data
def loadData2(files):
data = {}
for line in files:
user, item, score, timestamp = line.split(",")
data.setdefault(user, {})
data[user][item] = score
print("----1.用户:物品的倒排----")
print(data)
return data
# 2.计算
# 2.1 构造物品-->物品的共现矩阵
# 2.2 计算物品与物品的相似矩阵
# (这里采用的是余弦相似度算法计算的物品间的相似度)
def similarity(data):
# 2.1 构造物品:物品的共现矩阵
N = {} # 喜欢物品i的总人数
C = {} # 喜欢物品i也喜欢物品j的人数
for user, item in data.items():
for i, score in item.items():
N.setdefault(i, 0)
N[i] += 1
C.setdefault(i, {})
for j, scores in item.items():
if j not in i:
C[i].setdefault(j, 0)
C[i][j] += 1
print("---2.构造的共现矩阵---")
print('N:', N)
print('C:', C)
# 2.2 计算物品与物品的相似矩阵
W = {}
for i, item in C.items():
W.setdefault(i, {})
for j, item2 in item.items():
W[i].setdefault(j, 0)
W[i][j] = C[i][j] / sqrt(N[i] * N[j])
print("---3.构造的相似矩阵---")
print(W)
return W
# 3.根据用户的历史记录,给用户推荐物品
def recommandList(data, W, user, k=3, N=10):
rank = {}
for i, score in data[user].items(): # 获得用户user历史记录,如A用户的历史记录为{'a': '1', 'b': '1', 'd': '1'}
for j, w in sorted(W[i].items(), key=operator.itemgetter(1), reverse=True)[0:k]: # 获得与物品i相似的k个物品
if j not in data[user].keys(): # 该相似的物品不在用户user的记录里
rank.setdefault(j, 0)
rank[j] += float(score) * w
print("---4.推荐----")
print(sorted(rank.items(), key=operator.itemgetter(1), reverse=True)[0:N])
return sorted(rank.items(), key=operator.itemgetter(1), reverse=True)[0:N]
if __name__ == '__main__':
# 用户,兴趣度,物品
# 实例1
uid_score_bid = ['A,1,a', 'A,1,b', 'A,1,d', 'B,1,b', 'B,1,c', 'B,1,e', 'C,1,c', 'C,1,d', 'D,1,b', 'D,1,c', 'D,1,d',
'E,1,a', 'E,1,d']
data = loadData(uid_score_bid) # 获得数据
W = similarity(data) # 计算物品相似矩阵
recommandList(data, W, 'A', 3, 10) # 推荐
运行结果
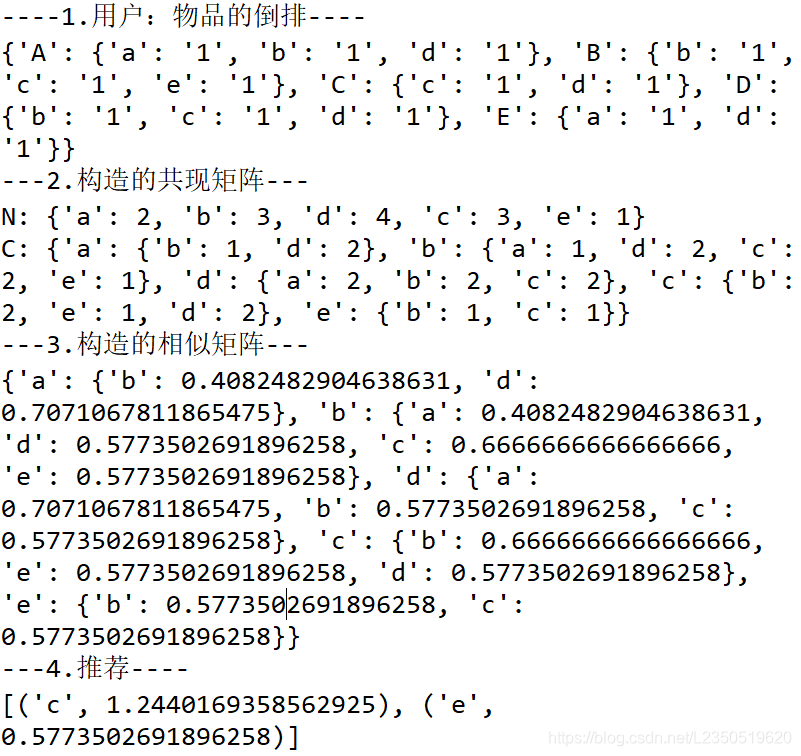
内容来自老师讲课,本人水平有限可能有些错误,见谅。

















 563
563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









