







1.要注意,小端模式时,书写字节序列和书写数字序列的顺序是相反的。(p30)
2.强制类型转换:
注意,此时p的值并未改变(指向的数据的地址),即p的值仍然是一个占用四个字节的地址量,只不过被强制类型转换后如果想移动p的话(p+1),就变成了只移动了一个字节(char类型嘛),而非移动四个字节(int数据类型所占字节),所以强制类型转换可以用于把一个占用了多个字节的数据类型一个一个字节的输出,以测试机器是大端模式还是小端模式(最低位最先输出)。
3.计算机系统的一个基本概念就是从机器的角度来看,程序仅仅只是字节序列,机器没有关于原始源程序的任何信息,除了可能有些用来帮助调试的辅助表以外。
4.环:一种数据结构。比如若用Z来表示整数集合,则整数环为其中加法为求和运算,乘法为求积运算,负号作为加法的逆运算,而元素0和1作为加法和乘法的单位元。
它和布尔代数<{0,1},|,&,~,0,1>有相似的属性。
5.位向量的应用:可以表示有限集合。
例如,我么用位向量【![]() 】(0,1的序列组合)来表示任何子集
】(0,1的序列组合)来表示任何子集![]() ,其中ai=1当且仅当i
,其中ai=1当且仅当i![]() A,例如,(记住我们是把
A,例如,(记住我们是把![]() 写在左边,a0写在右边),我们有a=[01101001]表示集合A={0,3,5,6},而b=[01010101]表示集合B={0,2,4,6}。在这种解释中,布尔运算|和&分别相当于集合的并和交,而~相当于集合的补集。比如a&b=[01000001],而A
写在左边,a0写在右边),我们有a=[01101001]表示集合A={0,3,5,6},而b=[01010101]表示集合B={0,2,4,6}。在这种解释中,布尔运算|和&分别相当于集合的并和交,而~相当于集合的补集。比如a&b=[01000001],而A![]() B={0,6}.
B={0,6}.
6.扩展一个数字的位表示
在不同字长的整数之间转换而又不改变数值,要是从一个较大的数据类型转换成一个较小的数据类型,一般是不可能的(位的丢失),而从一个较小的数据类型转换成一个较大的数据类型则是可能的,其规则是:对于无符号,采用零扩展,即简单的在表示的开头添加0;而对于一个补码数字,采用的则是符号扩展,即在表示中添加最高有效位(补码的最高有效位)的值,比如我们原始位的表示是 。
。
这个是可以用数学方法证明的。(p51)
注:-12345的二进制补码(1100111111000111=0xcfc7)表示和53191的无符号表示在16位字长时是相同的,但在32位时却是不同的,因为此时-12345的十六进制表示为0xffffcfc7,而53191的十六进制表示为0x0000cfc7。前者使用的是符号扩展,后者使用的是零扩展。
7.截断数字(同6比较)
1) intx=53191;
2)
3) inty=sx;
8.有符号数和无符号数的相互转换(强制转换)
9.位运算
10.IA32(指令集):Intel32位体系结构——Intel Architecture32-bit,这个处理器系列也被俗称为“x86”.
11.10101001表示的有符号数值是多少?
1)《深入理解计算机系统》中并没有用补码的方法,不管是正数还是负数,统一用一个公式进行计算,即最高位是一个负的权值(不管是正数还是负数),则上述二进制数表示的实际数为-128+32+8+1=-87.
2)用补码的方法:由最高位是1,可知道此二进制数表示一个负值,因此要对其先求补码,即11010111,表示的数为-(64+16+4+2+1)=-87.
12.
在C语言标准中,只规定了无符号数的移位操作是采用逻辑移位——即左移、右移都是使用的逻辑左移和逻辑右移(前补0,后补0)。
而对于有符号数,其左移操作还是逻辑左移(低位补0),但右移操作是采用逻辑右移还是算术右移就取决于机器了(VC6.0和VS2008编译器采用算术右移)。
算术右移和逻辑右移的区别是:算术右移符号位右移,前面位加符号位;逻辑右移符号位右移,右移后前补0。
简记为:算术有符号,逻辑无符号。
13.关于汇编语言,读懂汇编指令,了解寄存器和存储器的应用。
关于指令的跳转,
(1)在产生目标代码文件时,汇编器会确定所有带标号指令的地址,并使跳转目标(目标指令的地址——即需要跳到的地方)编码为跳转指令的一部分。
(2)有几种不同的编码方式,最常用的一种是:目标编码=目标指令地址-紧跟在跳转指令后面那条指令的地址 可以是一、二、四个字节!
例1:下面jbe指令的目标是什么?
8048d1c : 76 da jbe xxxxxxx(目标指令地址)
8048d1e : eb 24 jmp 8048d44
很显然,可以看出跳转目标的编码为 0xda(一个字节的目标编码),紧跟在跳转指令后面那条指令的地址是0x8048d1e,由公式,可得 0xda=xxxxxxx-0x8048d1e,则目标指令地址为0x8048d1e+0xda=...
例2:在下面的代码中,跳转目标的编码是跟PC相关的,且是一个4字节的二进制补码数。字节是按照从最低位到最高位的顺序列出的,反映出IA32的小端法字节顺序。跳转目标的地址是什么?
8048902 : e9 cb 00 00 00 jmp xxxxxxx(目标指令地址)
8048907 : 90 nop
如题目所说,目标编码是四个字节的,又是小端模式的机器,则是0x000000cb,紧跟在跳转指令后面那条指令的地址是0x8048907,显然,目标指令地址为0x8048907+0x0000000cb=0x80489d2.
第二种目标编码方法是给出“绝对地址”,用四个字节直接指定目标。
例1:请解释右边的注释与左边的字符代码之间的关系。这两行都是jmp指令编码的一部分。
80483f0 : ff 25 e0 a2 04 jmp *0x804a2e0(目标指令地址)
80483f5 : 08
注:间接跳转的写法是“*”后面跟一个操作数指示符,如jmp*%eax 用寄存器%eax中的值作为跳转目标.
本题答:间接跳转是用指令代码ff 25表示的。将要被读出的跳转目标的地址是由下面4个字节明确编码的。因为机器是小端模式,所以反向顺序给出就是 e0 a2 04 08.
14.条件码:描述了最近的算术或逻辑操作的属性,对这些寄存器的检测,有助于执行条件分支指令。
值得注意的是,在GAS格式中,操作数的顺序是相反的,
如比较两个数(假设是双字类型)指令是cmpl s2,s1 但是基于的是s1-s2,而非s2-s1。
两种最常见的访问条件码的方式不是直接读取它们,而是根据条件码的某种组合,设置一个整数寄存器或是执行一条件分支指令。
如setl是有符号小于指令,则setl D 等价于条件码的组合是D←SF^|OF
例:
Note : a is in %edx,bis in %eax
1 cmpl %eax, %edx
2 setl %al
3 movzbl %al,%eax
这三条指令比较的是a:b,而非b:a!当a<b(setl就是小于指令,而不是其他,如果是setg指令,就是看a>b)时,就置al为1,同时把%eax的高三个字节置0。
15.栈帧:(1)为单个过程分配的那部分栈成为栈帧. 当一个过程P调用另一个过程Q时,Q的参数就放在P的栈帧中,但是P的返回地址被压入栈中,形成P的栈帧的末尾。
(2)栈帧的最顶端是以两个指针定界的,寄存器%ebp作为帧指针,而寄存器%esp作为栈指针。
(3)Q的栈帧从保存的栈指针的值(例如,新的%ebp,由%esp赋值)开始,后面是保存的寄存器、本地变量和临时变量的值。
从以上三条可以看出,顾名思义,帧指针是不随时移动的,它只在乎过程与过程的区别,指示的是一个过程的开始(因此每个过程开始时,都会把%esp的值传给%ebp,以建立新的帧栈——因为%esp是始终指向栈顶的),并不会随着信息的访问而随时移动,在没有开始新的过程之前,%ebp的值不会改变。而栈指针会随着每条指令移动,其始终指向栈顶——栈只有一个,而栈帧可以有很多个,其数目等于过程的数目。另外值得注意的是,下一个过程的参数是保存在上一个过程的栈帧中的,随后压入的是返回地址,接着入栈的是新过程的栈帧值%ebp(由%esp赋值)。ret指令从栈中弹出返回地址的值,并跳转到那个位置,相当于指令:
1 movl %ebp, %esp (让%esp指向过程的开始部分(由栈帧指示的),新的栈顶)
2 popl %ebp (%esp也会跟着移动,从而指向返回地址的位置)
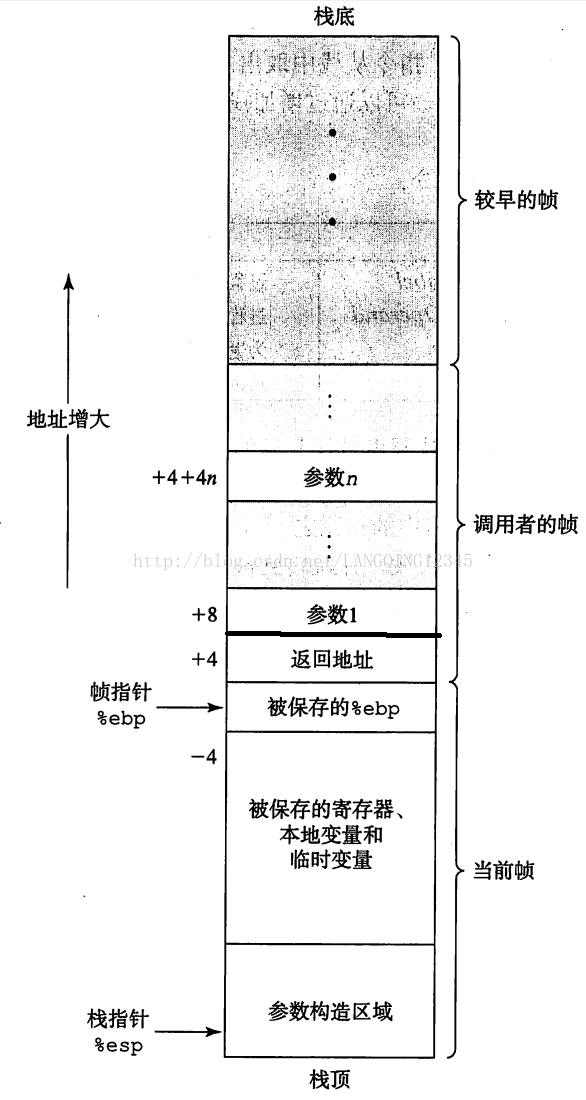
%ebp移动%esp一定移动,但%esp移动,%ebp一般不动(除非开始了一个新的过程)。
16.call指令的目标就是将返回地址入栈(如上图的+4地址的返回地址),并跳转到被调用过程的起始处。起始地址是紧跟在call后面的那条指令的地址,这样当被调用过程返回时,执行会从此处继续。
ret指令从栈中弹出地址,并跳转到那个位置。完整的调用过程如下:
.......(某调用函数)
call swap_add(某函数名) //返回地址入栈
pushl %ebp //栈帧值入栈,以备返回时用,实际上,执行完这条入栈指令后,%esp的值就减少了4,已经位于%ebp的下一个字节了,也可以认为 是%ebp四个字节的最后一个字节的末尾处。
movl %esp,%ebp //这时的%esp是指向“保存的%ebp”下的那条线处 ,上图的画法不准确
......(被调函数体)
movl %ebp,%esp //把%ebp的指向赋值给%esp,为下一步做准备
popl %ebp //此时的%esp应该是位于“返回地址”下的那条线处(上图的不准确),为下一条指令做准备
ret //弹出返回地址!!!!
......(继续执行调用函数)
17.妨碍程序优化的因素有两个:
(1)指针:如果编译器无法确定两个指针是否指向同一个位置,就必须假设什么情况都有可能(指向同一个位置或不是),限制了可能的优化策略。
(2)函数调用:有些函数有修改全局程序状态的一部分的副作用,因此任意函数都可能是优化的候选者,相反,编译器会假设最坏的情况,并保持所有的函数调用不变(即未优化)
18.上下文:
1.上下文(context)是指一个进程运行的环境和状态,也可以理解为进程的一个快照。从进程1切换到进程2的时候,内核就需要把进程1的当前状态和数据(也就是2楼提到的那一大堆东西)打个包保存到某个地方,再把以前保存的进程2的内容调出来。
上下文简单说来就是一个环境,相对于进程而言,就是进程执行时的环境。具体来说就是各个变量和数据,包括所有的寄存器变量、进程打开的文件、内存信息等。
2. 一个进程的上下文可以分为三个部分:用户级上下文、寄存器上下文以及系统级上下文。
用户级上下文: 正文、数据、用户堆栈以及共享存储区;
寄存器上下文: 通用寄存器、程序寄存器(IP)、处理器状态寄存器(EFLAGS)、栈指针(ESP);
系统级上下文: 进程控制块task_struct、内存管理信息(mm_struct、vm_area_struct、pgd、pte)、内核栈。
19.句柄:
句柄地址(稳定)→记载着对象在内存中的地址→对象在内存中的地址(不稳定)→实际对象。但是,必须注意的是程序每次从新启动,系统不能保证分配给这个程序的句柄还是原来的那个句柄,而且绝大多数情况的确不一样的。
20.WIN32 API
应用程序编程接口,于上个世纪90年代出现,它是Windows操作系统提供的一套C语言的编程接口,通过这一套编程接口(实质就是一系列专用函数)可以让操作系统来做我们想做的事情,比如弹出一个窗口,比如在窗口上画点东西。时隔多年,这套函数的核心没有变(虽然Windows操作系统更大更复杂了)。















 2524
2524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









