







本次笔记来源于Tensorflow官方教程的Basic regression: Predict fuel efficiency。主要针对数据内容进行一些简要说明。
原教程使用了经典的AUTO MPG数据集,构建了一个用来预测70年代末到80年代初汽车燃油效率的模型。模型的预测目标是燃油效率—MPG,参数包括:气缸数、排量、马力及重量等。
燃油效率数据集获取
#搭建环境,引入数据库
from __future__ import absolute_import, division, print_function, unicode_literals
import warnings
warnings.filterwarnings('ignore')
import pathlib
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers第一步,首先下载数据集
dataset_path = keras.utils.get_file("auto-mpg.data", "http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data")
dataset_path'C:\\Users\\DELL\\.keras\\datasets\\auto-mpg.data'
由于我之前下载过数据集,因此直接会显示数据集的存储位置,在用pandas导入数据集之前,我们可以先用VS打开我们下载的数据集,看一看数据集具体什么样子

如上图所示,我截取的是数据集的最后几行,截取最后几行的原因下文会有解释。现在我们用pandas导入数据集列的标签
column_names = ['MPG', 'Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin']#添加列标签
#读取csv文件,其中第一行引入列标签
raw_dataset = pd.read_csv(dataset_path, names=column_names,
na_values = "?", comment='\t',
sep=" ", skipinitialspace=True)
dataset = raw_dataset.copy()
dataset.tail()#显示最后五行数据 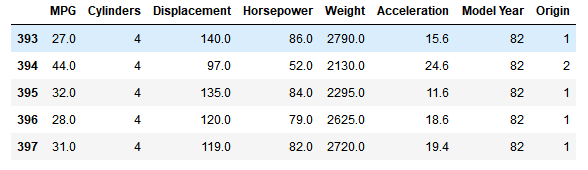
上图显示的就是数据集最后五行的数据,这是我们截图最后几行数据的原因~
清洗数据
数据集中包含一些错误数据,我们需要检测并清除掉
dataset.isna().sum()#ISNA函数,是用来检测一个值是否为#N/A,返回TRUE或FALSE上述代码中,ISNA函数,是用来检测一个值是否为#N/A,返回TRUE或FALSE
MPG 0
Cylinders 0
Displacement 0
Horsepower 6
Weight 0
Acceleration 0
Model Year 0
Origin 0
dtype: int64
为了保证这个初始示例的简单性,删除这些行。
dataset = dataset.dropna()其中,’Origin‘列实际代表了分类,而非一个数字。所以把它转换为独热码(one-hot)
origin = dataset.pop('Origin')#删除最后一列的数据,同时返回该列元素的数值
#把最后一列分别换成USA Europe 和 Japan
dataset['USA'] = (origin == 1)*1.0
dataset['Europe'] = (origin == 2)*1.0
dataset['Japan'] = (origin == 3)*1.0
dataset.tail()#显示最后五行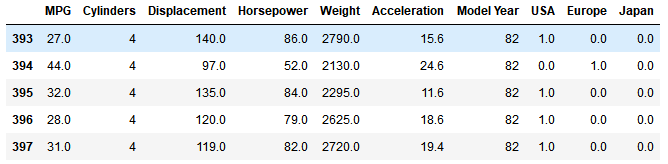
拆分训练数据集和测试数据集
由于原始数据集并未详细分为训练集和测试集,因此我们需要将原数据集重新拆解为训练集和数据集
训练集用于模型训练,用测试集测试模型的精度。
train_dataset = dataset.sample(frac=0.8,random_state=0)
test_dataset = dataset.drop(train_dataset.index)分离特征值
将特征值从目标或者‘标签’中分离,使得参数数据和标签数据分离开,是训练的前提。这个标签也是训练模型进行预测的值。
train_labels = train_dataset.pop('MPG')#删除训练集‘MPG’标签,并返回相应的值
test_labels = test_dataset.pop('MPG')#删除测试集‘MPG’标签,并返回相应的值数据规范化
def norm(x):
return (x - train_stats['mean']) / train_stats['std']
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)注意的是,归一化输出的数据统计(均值和标准差)需要反馈给模型,从而应用于任何其他数据,以及我们之前所获得独热码。
模型
建模的方式与之前几篇文章一样,依次是构建模型—即通过搭建网络层构建神经网络模型,训练模型,然后预测并评估模型。所有代码均来自官方教程。这里仅列出代码,不再做具体解释。
def build_model():
model = keras.Sequential([
layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse',optimizer=optimizer, metrics=['mae', 'mse'])
return model
model = build_model模型建好之后,我们检查一下整体结构
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 64) 640
_________________________________________________________________
dense_1 (Dense) (None, 64) 4160
_________________________________________________________________
dense_2 (Dense) (None, 1) 65
=================================================================
Total params: 4,865
Trainable params: 4,865
Non-trainable params: 0
训练模型
对模型进行1000个周期的训练,并记录训练和验证的准确性。
# 通过为每个完成的时期打印一个点来显示训练进度
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self, epoch, logs):
if epoch % 100 == 0: print('')
print('.', end='')
EPOCHS = 1000
history = model.fit(
normed_train_data, train_labels,
epochs=EPOCHS, validation_split = 0.2, verbose=0,
callbacks=[PrintDot()])....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
使用 history 对象中存储的统计信息可视化模型的训练进度。
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
hist.tail()#显示最后五条训练信息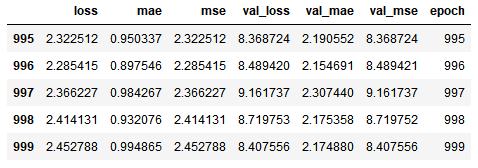
接下来通过图表方式显示误差随迭代进行的曲线变化
def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Abs Error [MPG]')
plt.plot(hist['epoch'], hist['mae'],
label='Train Error')
plt.plot(hist['epoch'], hist['val_mae'],
label = 'Val Error')
plt.ylim([0,5]
plt.legend()
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Square Error [$MPG^2$]')
plt.plot(hist['epoch'], hist['mse'],
label='Train Error')
plt.plot(hist['epoch'], hist['val_mse'],
label = 'Val Error')
plt.ylim([0,20])
plt.legend()
plt.show()
plot_history(history)

从图表发现,验证值在100个循环之后,开始恶化,现在我们调整model.fit,再次进行训练。我们将使用一个 EarlyStopping callback 来测试每个 epoch 的训练条件。如果经过一定数量的 epochs 后没有改进,则自动停止训练。
model = build_model()
# patience 值用来检查改进 epochs 的数量
early_stop = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10)
history = model.fit(normed_train_data, train_labels, epochs=EPOCHS,
validation_split = 0.2, verbose=0, callbacks=[early_stop, PrintDot()])
plot_history(history)
预测
现在使用测试集中的数据进行预测
test_predictions = model.predict(normed_test_data).flatten()
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
_ = plt.plot([-100, 100], [-100, 100])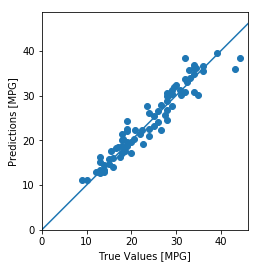
结论
均方误差(MSE)是用于回归问题的常见损失函数(分类问题中使用不同的损失函数)。
类似的,用于回归的评估指标与分类不同。 常见的回归指标是平均绝对误差(MAE)。
当数字输入数据特征的值存在不同范围时,每个特征应独立缩放到相同范围。
如果训练数据不多,一种方法是选择隐藏层较少的小网络,以避免过度拟合。
早期停止是一种防止过度拟合的有效技术。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











