







 本文深入解析AE自编码器,涵盖自编码器的工作原理、关键概念如稀疏性、隐含层、过拟合及优化函数,并介绍常见类型如欠完备、稀疏和栈式自编码器。
本文深入解析AE自编码器,涵盖自编码器的工作原理、关键概念如稀疏性、隐含层、过拟合及优化函数,并介绍常见类型如欠完备、稀疏和栈式自编码器。
深度学习:AE自编码器详细解读(图文并茂,值得一看)
本文参照了大量的网上文献,提取出了关于AE自编码器最重要的概念部分整理而成,为了增加文章的可读性,文章搭配了大量的插图。
参考文章如下:
自编码器是什么?有什么用?这里有一份入门指南(附代码)
TensorFlow实战之实现自编码器过程
深度学习之自编码器
首先跟大家展示一下本文的流程:

如上所示,本文分为三个大的段落,其中每个大段落又包含详细的分支,且看下面详细分解。


自编码的过程简单的说可以分为两部分:输入到隐层的编码过程和隐层到输出的解码过程。

那么这个过程有什么意义呢?我们接着看:

 在学习自编码器之前,我们还需要再了解一下AE自编码器的相关概念。
在学习自编码器之前,我们还需要再了解一下AE自编码器的相关概念。

稀疏性:
Sparsity 是当今机器学习领域中的一个重要话题。
Sparsity 的最重要的“客户”大概要属 high dimensional data 了吧。现在的机器学习问题中,具有非常高维度的数据随处可见。例如,在文档或图片分类中常用的 bag of words 模型里,如果词典的大小是一百万,那么每个文档将由一百万维的向量来表示。高维度带来的的一个问题就是计算量:在一百万维的空间中,即使计算向量的内积这样的基本操作也会是非常费力的。不过,如果向量是稀疏的的话(事实上在 bag of words 模型中文档向量通常都是非常稀疏的),例如两个向量分别只有 L 1 L1 L1和 L 2 L2 L2 两个非零元素,那么计算内积可以只使用 m i n ( L 1 , L 2 ) min(L1,L2) min(L1,L2) 次乘法完成。因此稀疏性对于解决高维度数据的计算量问题是非常有效的。
稀疏编码(Sparse Coding)算法是一种无监督学习方法,它用来寻找一组“超完备”基向量来更高效地表示样本数据。稀疏编码算法的目的就是找到一组基向量
ϕ
i
\phi _{i}
ϕi ,使得我们能将输入向量
X
X
X表示为这些基向量的线性组合:
X
=
∑
i
=
1
k
a
i
ϕ
i
X=\sum_{i=1}^{k}a_{i}\phi _{i}
X=∑i=1kaiϕi
自编码(AutoEncoder):
顾名思义,即可以使用自身的高阶特征编码自己。自编码器其实也是一种神经网络,它的输入和输出是一致的,它借助稀疏编码的思想,目标是使用稀疏的一些高阶特征重新组合来重构自己,即 :对所有的自编码器来讲,目标都是样本重构。
在机器学习中,自编码器的使用十分广泛。自编码器首先通过编码层,将高维空间的向量,压缩成低维的向量(潜在变量),然后通过解码层将低维向量解压重构出原始样本。
隐含层:
指输入层和输出层以外,中间的那些层。输入层和输出层是可见的,且层的结构是相对固定的,而隐含层结构不固定,相当于不可见。只要隐含的节点足够多,即是只有一个隐含层的神经网络也可以拟合任意函数。隐含层层数越多,越容易拟合复杂的函数。拟合复杂函数需要的隐含节点数目随着层数的增多而呈指数下降。即层数越深,概念越抽象,这就是深度学习。
过拟合:
指模型预测准确率在训练集上升高,但在测试集上反而下降。这是模型的泛化性不好,只记住了当前数据的特征。
Dropout:
Dropout:防止过拟合的一种方法。将神经网络某一层的输出节点数据随机丢弃一部分。可以理解为是对特征的采样。
优化函数:
优化调试网络中的参数。一般情况下,在调参时,学习率的设置会导致最后结果差异很大。神经网络通常不是凸优化,充满局部最优,但是神经网络可能有很多个局部最优都能达到良好效果,反而全局最优容易出现过拟合。
对于SGD,通常一开始学习率大一些,可以快速收敛,但是训练的后期,希望学习率可以小一些,可以比较稳定地落到一个局部最优解。
除SGD之外,还有自适应调节学习率的Adagrad、Adam、Adadelta等优化函数.
激活函数:
Sigmoid函数的输出在(0,1),最符合概率输出的定义,但局限性较大。
ReLU,当x<=0时,y=0;当x>0时,y=x。这非常类似于人类的阈值响应机制。ReLU的3个显著特点:单侧抑制;相对宽阔的兴奋边界;稀疏激活性。它是目前最符合实际神经元的模型。

了解以上基本概念后,我们现在研究一下自编码器的基本算法原理:
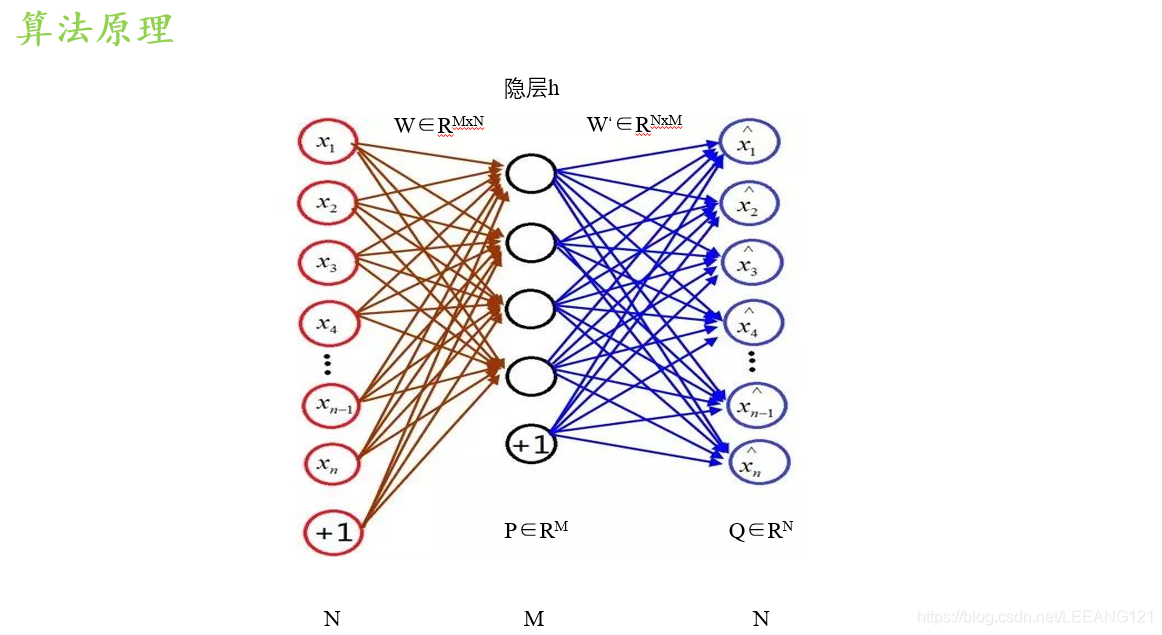
AE的模型结构如上图所示:
Auto-Encoder(AE)是20世纪80年代晚期提出的,简单讲,AE可以被视为一个三层神经网络结构:一个输入层、一个隐藏层和一个输出层,从数据规模上讲,输入层与输出层具有相同的规模。
其中,N表示输入层(同时也是作为输出层)的规模;M表示隐藏层的规模; x i ∈ R n , h ∈ R m , x i ^ ∈ R n x_{i}\in R^{n},h\in R^{m},\hat{x_{i}}\in R^{n} xi∈Rn,h∈Rm,xi^∈Rn,分别表示输入层、隐藏层和输出层上的向量,也是各层上对应的数据个数,这里隐藏层 h h h的数据低于输入层和输出层的数据,即 x > h < x ^ x>h<\hat{x} x>h<x^且 x = x ^ x=\hat{x} x=x^。根据输入层 x x x到隐藏层 h h h的映射矩阵求出 h h h,再根据隐藏层h到输出层的映射矩阵求出 x ^ \hat{x} x^。 P ∈ R m , Q ∈ R n P\in R^{m},Q\in R^{n} P∈Rm,Q∈Rn分别表示隐藏层和输出层上的偏置向量。 W ∈ R M × N W\in R^{M\times N} W∈RM×N表示输入层与隐藏层之间的权值矩阵,即 x x x到 h h h的映射矩阵,是 n n n乘 m m m阶矩阵; W ′ ∈ R N × M W^{'}\in R^{N\times M} W′∈RN×M表示隐藏层与输出层之间的权值矩阵,即 h h h到 x ^ \hat{x} x^的映射矩阵,是 m m m乘 n n n阶矩阵,也是 W W W的逆矩阵。
常见的自编码器有如下图所示几种:

欠完备自编码器:
欠完备自编码器就是将输出层中神经元的个数设置为小于输入层中神经元的个数,以达到非线性降维的效果(在神经网络的传递过程中由于激活函数的存在,因此是非线性的传递)。
稀疏自编码器:
稀疏自编码就是对隐层的神经元加入稀疏约束,以便约束隐层中神经元不为0的个数,我们希望达到用尽可能少的神经元来表示数据X,以达到稀疏降维。稀疏自编码有加速网络训练的功能。
收缩自编码器:
收缩自编码是在损失函数中加入一项平方Frobenius范数的正则项,其表达式如下:
ȷ
C
A
E
(
θ
)
=
∑
x
∈
D
n
(
L
(
x
,
g
(
f
(
x
)
)
)
+
λ
∥
J
f
(
x
)
∥
F
2
)
\jmath _{CAE}(\theta )=\sum _{x\in D_{n}}(L(x,g(f(x)))+\lambda \left \| J_{f}(x) \right \|_{F}^{2})
ȷCAE(θ)=∑x∈Dn(L(x,g(f(x)))+λ∥Jf(x)∥F2)
∥
J
f
(
x
)
∥
F
2
=
∑
i
=
1
d
h
(
h
i
(
1
−
h
i
)
)
2
∑
j
=
1
d
x
W
i
j
2
\left \| J_{f}(x) \right \|_{F}^{2}=\sum _{i=1}^{d_{h}}(h_{i}(1-h_{i}))^{2}\sum _{j=1}^{d_{x}}W_{ij}^{2}
∥Jf(x)∥F2=∑i=1dh(hi(1−hi))2∑j=1dxWij2
栈式自编码:
栈式自编码主要是用来实现深度学习的无监督预训练的,其无监督预训练过程如下
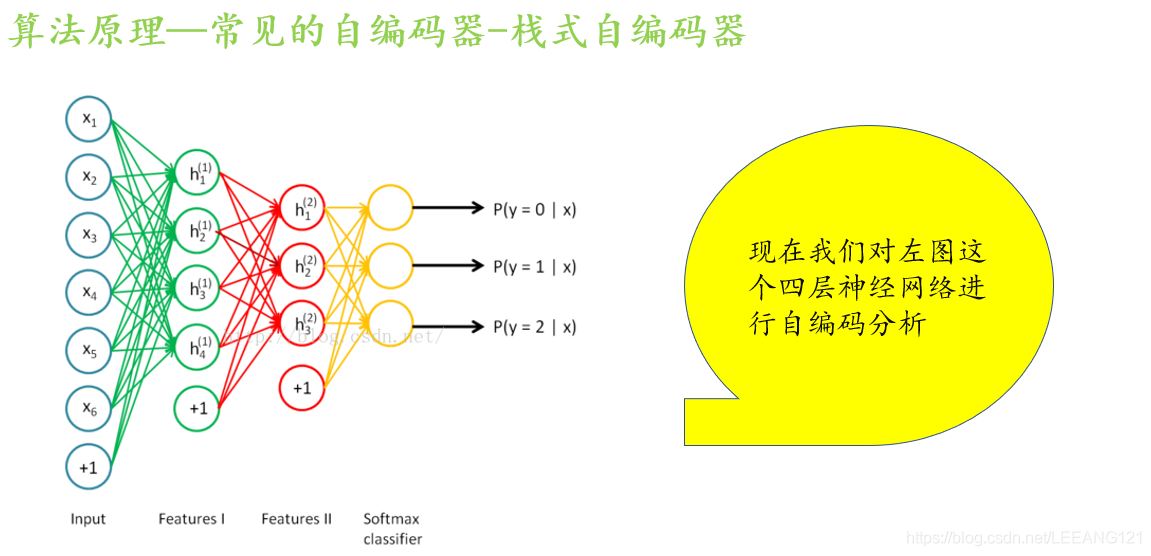
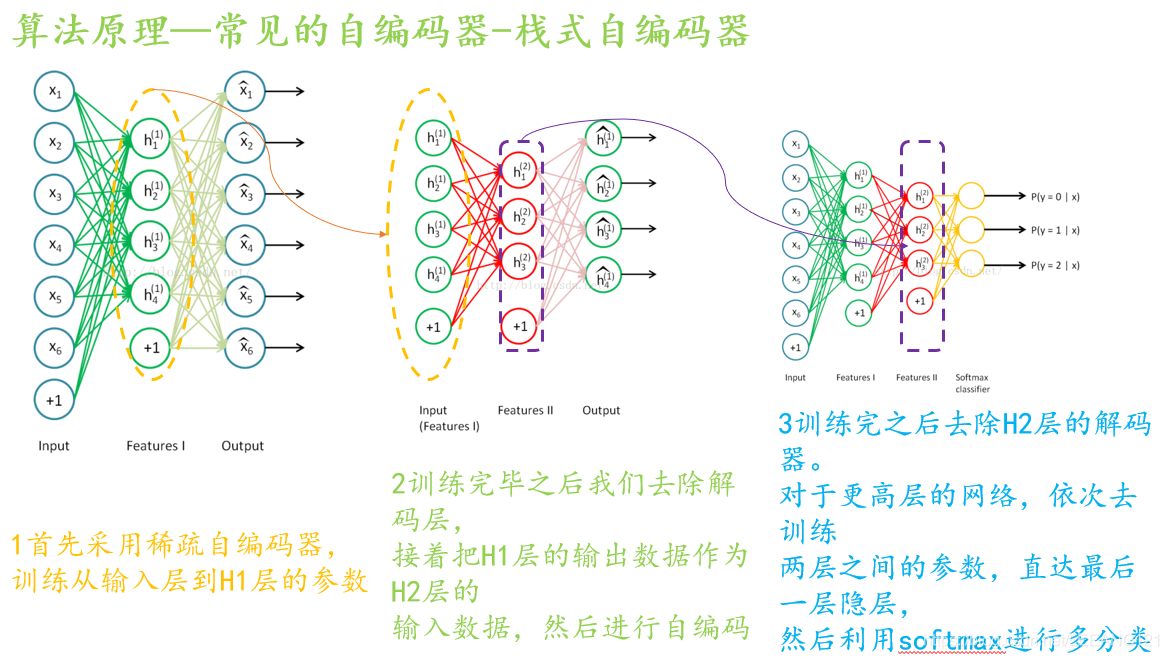

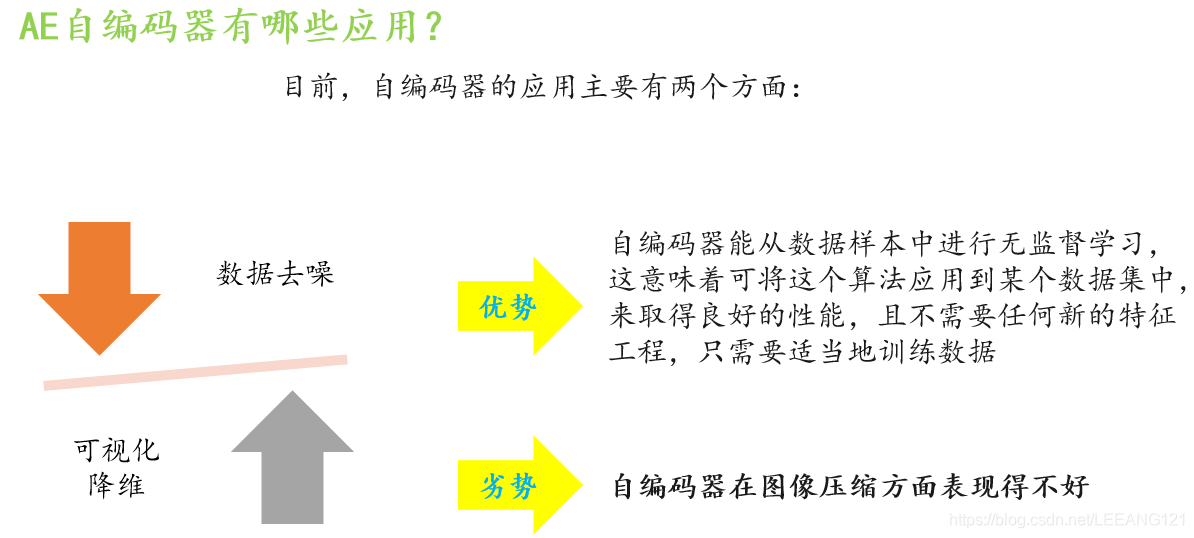
文章最后我们简单的说一下AE自编码器有哪些应用吧。请看大屏幕:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











