






目录
1、URI与URL
URI是统一资源标志符(URL是URI的子集,URI还包括一个子类为URN统一资源名称,它只命名资源而不指定如何定位资源)
URL统一资源定位符(如:https://baidu.com/wd=leebeloved是一个URL同样也是一个URI,拆解后为:访问协议https,访问路径baidu.com,资源名称wd=leebeloved)
2、超文本hypertext,浏览器所展现的网页为超文本解析而来的,网页源码为HTML代码。
3、HTTP和HTTPS
HTTP称为超文本传输协议,是从网络传输超文本数据到本地浏览器的协议。而HTTPS为安全版的HTTP,在HTTP下加入ssl层,HTTPS传输内容都是经过ssl加密的。
HTTPS作用分为:1、建立安全的信息通道;2、保证网站的真实性
4、HTTP请求过程
HTTP请求过程:从输入URL到网页呈现的过程是:浏览器→发送请求→网站所在服务器→网站处理、解析请求→返回相应的响应→传回浏览器(一个网站的请求在开发者工具中的参数:name请求名称,通常为URL最后一部分;status响应状态码;type请求的文档类型;initiator请求源,用来标记求情是由哪个对象或者进程发起的;size从服务器下载或者请求的资源大小;time请求发起到获取响应所用的时间;waterfall网络请求的可视化瀑布流)
网页开发者工具栏:General部分,request url为请求URL,request method为请求方法,status source为响应状态码,remote address为远程服务器地址和端口,referrer policy为referrer判别策略,response headers为响应头,request headers为请求头(请求头中包含有浏览器标识、cookies、host等)

5、请求方法
客户端向服务端发送请求分为4部分:请求方法、网址、头、体。常用的请求方法是get和post。
5.1、get请求中的参数包含在URL里面,数据可以在URL中看到,而POST请求的URL不会包含这些数据,数据都是通过表单形式传输的,会包含在请求体中(URL中看不到)。
5.2、GET请求提交的数据最多只有1024字节,而POST方式没有限制。
6、请求头包含的信息
用于说明服务器要使用的附加信息,比较重要的信息有 Cookie、 Referrer、user-agent等。
6.1、 Accept:请求报头域,用于指定客户端可接受哪些类型的信息;
6.2、Accept-language:指定客户端可接受的言类型;
6.3、Accept- Encoding:指定客户端可接受的内容编码;
6.4、Host:用于指定请求资源的主机IP和端口号,其内容为请求URL的原始务器或网关的位置;
6.5、Cookie:也常用复数形式 Cookies,网站为了辨别用户进行会话跟踪面存储在用户本地的数据。它的主每功能是维持当前访问会话。 Cookies里有信息标识了我们所对应的服务器
的会话,每次测览器在请求该站点的页面时,都会在请求头中加上 Cookies并将其发送给服务器,服务器通过 Cookies识别出是我们自己,并且查出当前状态是登录状态。所以返同结果就是登录之后才能看到的网项内容。
6.6、Referer:此内容用来标识这个请求是从哪个页面发过来的,服务器可以拿到这一信息并做相应的处理,如做来源统计、防盗链处理等。
6.7、User- Agent:简称UA,它是一个特殊的字符事头,可以使服务器识别客户使用的操作系统及版本,浏览器及版本等信息。在做爬虫时加上此信息,可以伪装为览器;如果不加,很容易被识别出是爬虫。
7、请求体:一般承载的内容是post请求中的表单数据,get请求的请求体为空
8、响应:服务端返回到客户端,分为响应状态码、头、体
响应状态码:200表示服务器正常响应,404表示页面未找到,500代表服务器内部发生错误,403服务器拒绝此访问请求,禁止访问。
响应体:做爬虫时候主要通过响应体得到网页源码、json数据等。
9、网页基础
9.1 网页组成:
html描述网页的语言,网页包括文字、图片、视频、按钮等。(不同类型文字通过不同类型标签表示,img图片、video视频、p段落、div布局标签,整个网页框架是各种标签不同的排列和嵌套的组合);
JavaScript:脚本语言,html与css配合使用提供给用户的只是静态信息,缺乏交互性;
css:层叠样式表,层叠指在HTML中引用了数个样式文件,并且样式发生冲突时,浏览器可依据层叠顺序处理,样式指网页中文字大小、颜色、元素间距、排列等格式。
9.2 节点树及节点间关系
DOM文档对象模型,它定义了访问HTML和XML的标准。
HTML DOM将HTML文档视为树结构:
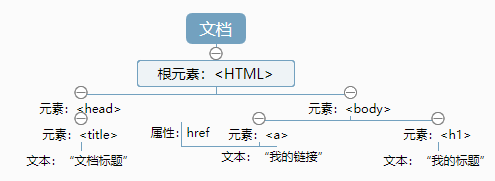
节点有层级关系,父节点、子节点、兄弟节点,节点树中顶端节点称为根,每个节点都有父节点,同时可以拥有任意数量子节点或者兄弟节点。
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











