







前言
此工作的主要贡献:
(1)开发了一种新型的基于网络的3D飞行模拟器,该模拟器在浏览器中运行,并与MTurk集成,以收集城市规模的大规模人类辅助生成的飞行轨迹;
(2)收集了一个新颖的无人机视觉语言导航数据集CityNav,包含32637种语言目标描述和人类演示,利用真实城市及其地理信息的3D扫描;
(3)提供了一个基线模型,其中包括一个表示地理信息的内部二维空间地图。
一、数据集收集
1.1 收集背景
目前的无人机VLN数据集或多或少都有一些问题:
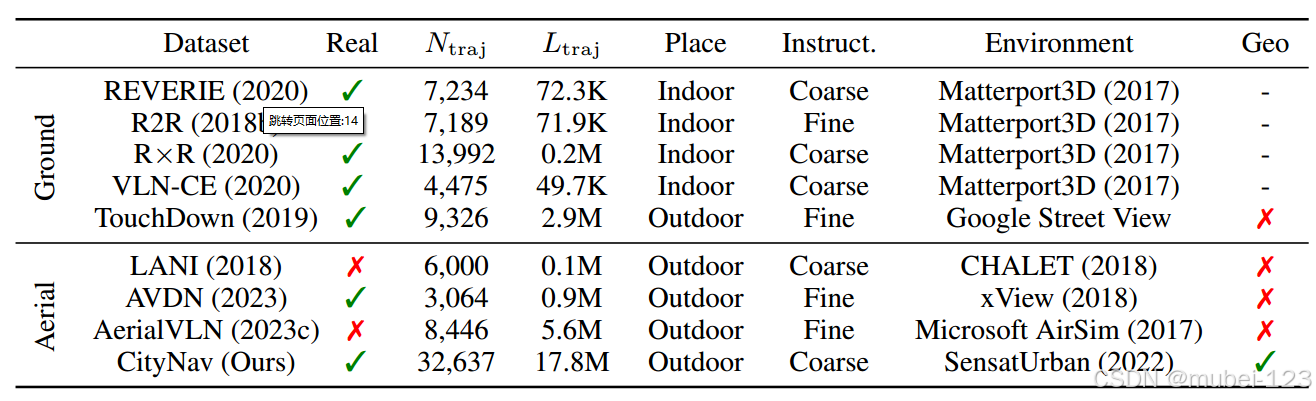
(1)LANI数据集由虚拟环境CHALET中获得的6000条轨迹组成,由于CHALET缺乏真实感,所以LANI提供了一个相对较小的导航环境;
(2)AVDN数据集利用卫星图像进行导航,忽略了代理在飞行过程中遇到的3D几何形状;
(3)AerialVLN数据集的图像数据来自虚拟环境,降低了现实世界中通常扫描的高密度点云中的复杂性和真实性。
1.2 收集策略
与之前的工作不同,本工作利用实际城市及其地理信息的3D扫描来收集人类辅助生成的轨迹。这些地理感知轨迹使无人机视觉语言导航模型能够有效地缩小探索空间。在开始之前,先介绍两个数据集:
(1)SensatUrban:城市规模的点云数据集,在本工作中主要提供视觉场景;
(2)CityRefer:城市规模,带有地理感知的点云数据集,在本工作中主要提供文本描述(选中的描述占总描述的92.8%)。
具体收集方法如下:
(1)在最初的一轮收集中,收集与CityRefer数据集中的每个描述相对应的轨迹。总共有包含5866个对象的35196条描述(每个对象对应6条描述),涉及34个场景;
(2)在第二轮收集过程中,首先剔除第一轮中质量不合格的轨迹,然后重新收集丢弃数据的轨迹,最后总共收集了包含5850个对象的32637条描述和相应的轨迹。
1.3 数据集结构
数据集构成如下表:
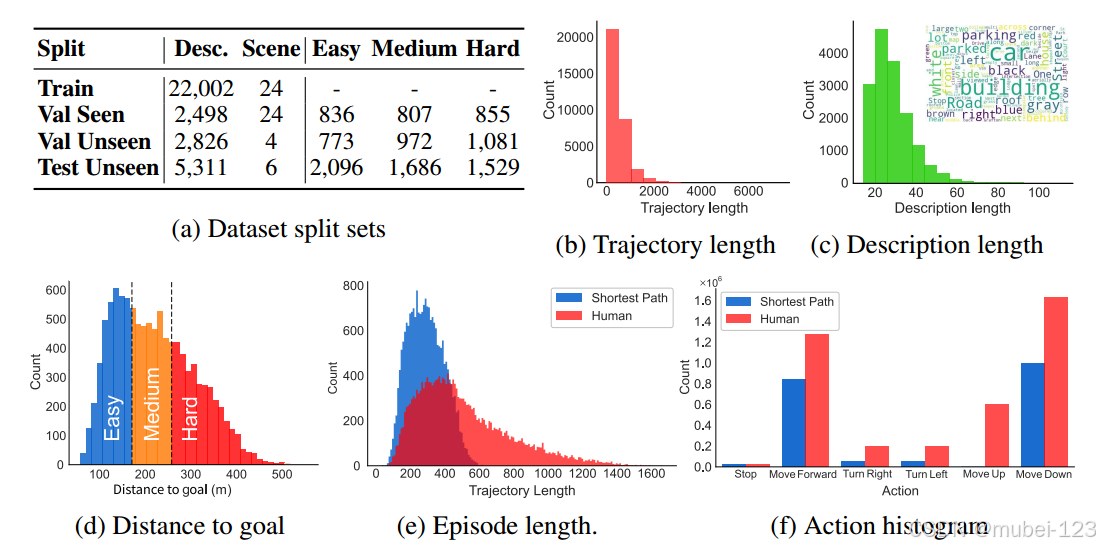
与之前的数据集相比,本工作的数据集的优势:
(1)CityNav数据集的指令是高级的,没有具体的分布指导,与现有的以细粒度指令为特征的空中导航任务相比,创造了一个更具挑战性和现实性的环境;
(2)是第一个利用真实世界3D城市数据的大规模3D航空导航数据集,其中包括大量人类收集的地理感知轨迹和文本描述。
二、任务整体框架
2.1 任务描述
该模型输出两个值:预测目标坐标和预测进度。预测的目标坐标基于先前的观测估计目标对象的位置,而预测的进度计算从起点到目标的剩余距离与总距离的比率:
(1)为了接近预测的坐标,代理根据新的观测值更新已经预测的坐标,并在每个时间步连续执行至多五个动作;
(2)当预测的进度超过设定的阈值时,代理停止迭代,直接前进到预测的目标坐标。
2.2 模型介绍
模型的整体框架如下图所示:
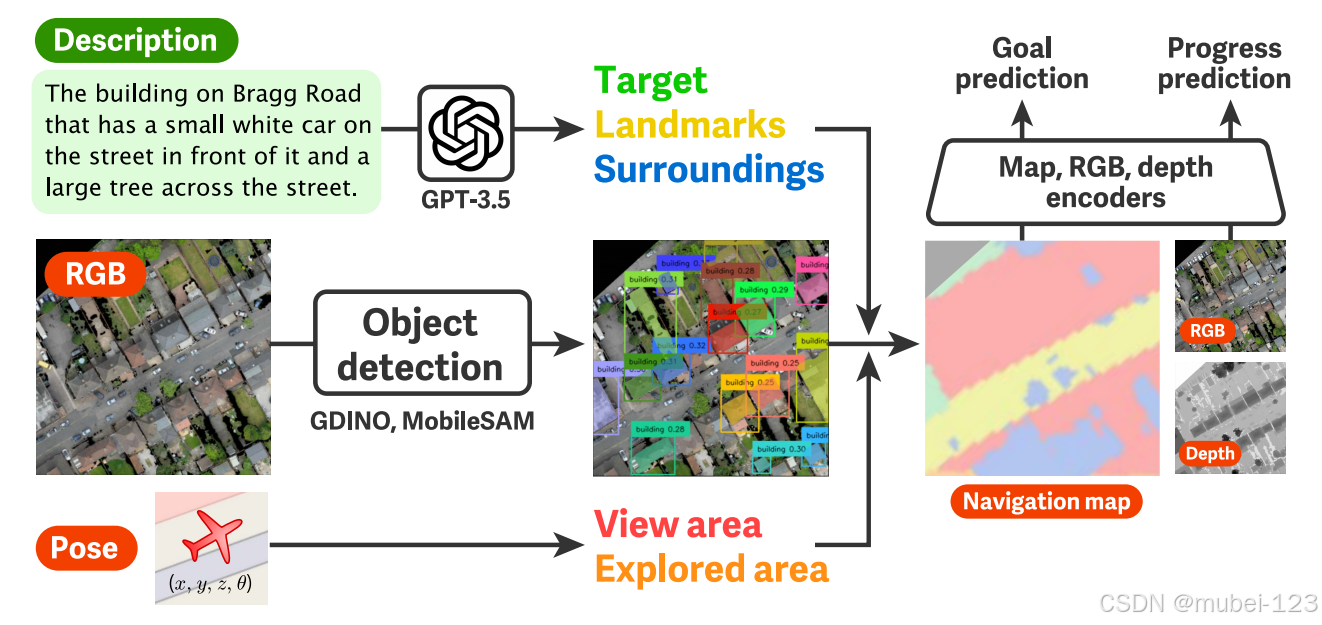
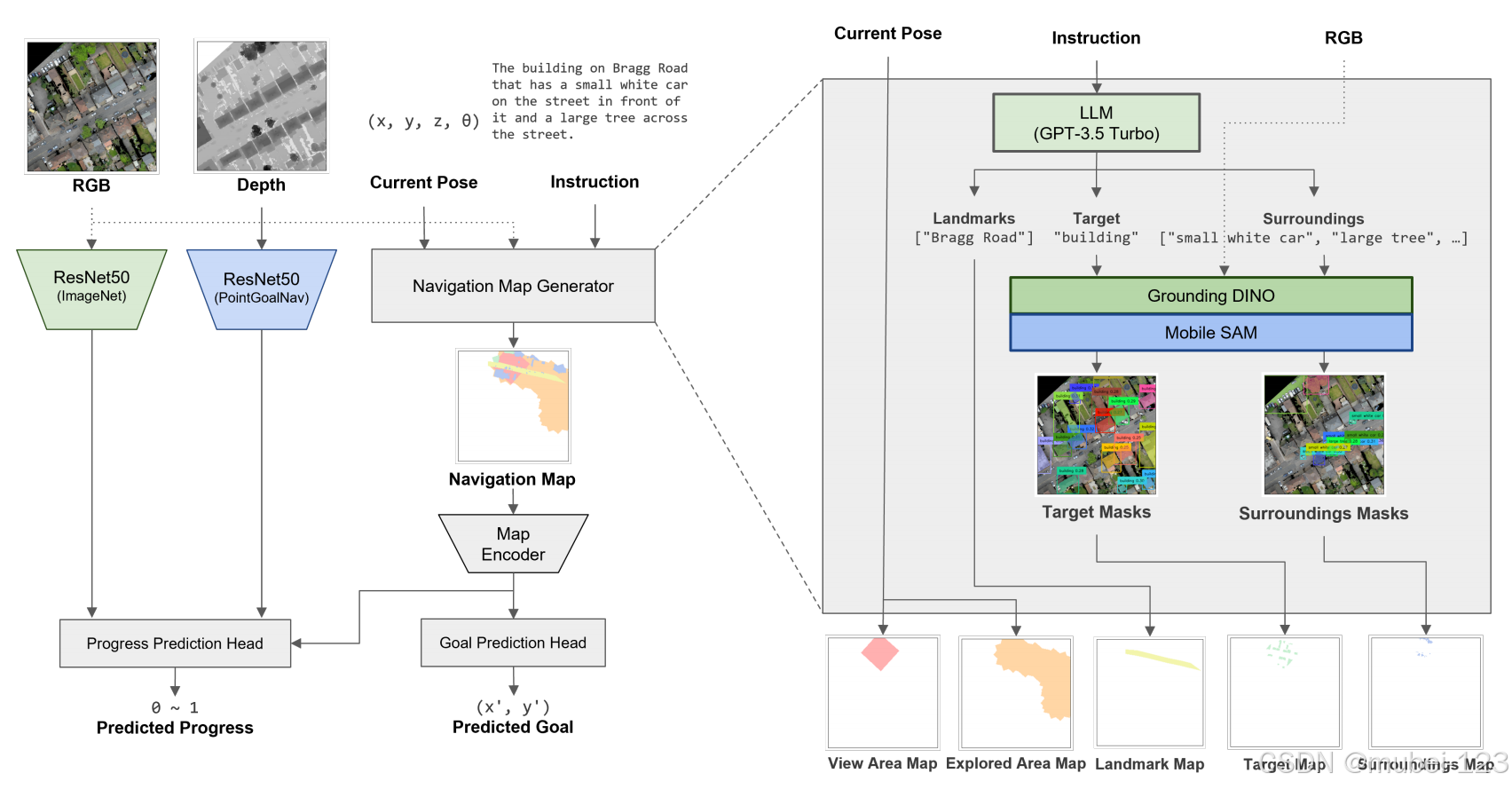
可以看出,主要由以下几部分组成:
(1)ResNet视觉编码器1:获取RGB图像的视觉特征,是在ImageNet上面预训练的ResNet;
(2)ResNet视觉编码器2:获取深度图像的视觉特征,是在PointGoalNav上面预训练的ResNet;
(3)关键指令提取器:负责提取地标、目标和环境等信息,是一个预训练的LLM,即GPT-3.5 Turbo;
(4)Grounding DINO目标检测器:检测描述的目标和周围环境,是已经预训练的大模型;
(5)Mobile SAM语义分割器:获取描述的目标和周围环境的掩码,是已经预训练的大模型;
(6)Map Encoder:集成地标地图、视觉和探索区域地图以及目标和周围环境地图。
三、难点
3.1 可选的坐标细化
该模块在目标检测和分割之后(在原论文的框架图中并没有体现)。作为最后的动作,代理必须从观察中确定目标的确切位置,并相应地定位自己。
(1)MGP对视觉提示进行标记集提示;
(2)RGB图像首先用Semantic SAM提供的分割掩码的标签进行注释;
(3)然后提示视觉语言模型LLaVA-1.6-34b选择标签;
(4)代理移动到与所选标签的分割掩码对应的边界框的中心;
(5)最后,代理下降到其当前位置的xy坐标处离地面5米的高度。
四、关键代码分析
4.1 训练
训练环节的整体代码如下所示:
def train(args: ExperimentArgs, device='cuda'):
random.seed(args.seed)
torch.manual_seed(args.seed)
# setup logger
logger.init(args)
for metric in GoalPredictorMetrics.names():
logger.define_metric('val_seen_' + metric, 'epoch')
logger.define_metric('val_unseen_' + metric, 'epoch')
# load data
start_epoch = 0
"""
将从objects.json文件中提到的object和processed_descriptions.json文件中对应的表述整合到一起
得到的objects的格式:
objects: CityReferObject(...)
│ ├─ map_name: "birmingham_block_1"
│ ├─ id: 11,即object的id
│ ├─ name: ""
│ ├─ object_type: ""
│ ├─ position: (x, y, z)
│ ├─ dimension: (l, h, w)
│ ├─ descriptions: List[ProcessedDescription],有好几条描述
│ └─ processed_descriptions: ""
│ ├─ target: string, 与descriptions的数量对应
│ ├─ landmarks: List[string], descriptions的数量对应
│ └─ surroundings: List[string], 与descriptions的数量对应
"""
objects = get_city_refer_objects()
"""
得到的train_episodes的数据格式:
Episode
├─ target_object: CityReferObject(...)
│ ├─ map_name: "birmingham_block_1"
│ ├─ id: 11
│ ├─ name: ""
│ ├─ object_type: ""
│ ├─ position: (x, y, z)
│ ├─ dimension: (l, h, w)
│ ├─ descriptions: List[ProcessedDescription],有好几条描述
│ └─ processed_descriptions: ""
│ ├─ target: string, 与descriptions的数量对应
│ ├─ landmarks: List[string], descriptions的数量对应
│ └─ surroundings: List[string], 与descriptions的数量对应
├─ description_id: 1 (或者2, 3,..., 最大数与descriptions的数量对应 )
├─ teacher_trajectory: [Pose4D(...), ...]
└─ teacher_actions: [2, 2, 1, 1, 1, ..., 0]
"""
train_episodes = _load_train_episodes(objects, args)
if args.train_episode_sample_size > 0:
train_episodes = random.sample(train_episodes, args.train_episode_sample_size)
#train_dataloader = DataLoader(train_episodes, args.train_batch_size, shuffle=True, collate_fn=lambda x: x)
train_dataloader = DataLoader(train_episodes, args.train_batch_size, shuffle=True, collate_fn=lambda x: x, num_workers=0)
#验证episodes
val_seen_episodes = generate_episodes_from_mturk_trajectories(objects, load_mturk_trajectories('val_seen', 'all', args.altitude))
val_unseen_episodes = generate_episodes_from_mturk_trajectories(objects, load_mturk_trajectories('val_unseen', 'all', args.altitude))
cropclient.load_image_cache()
#初始化模型和优化器
goal_predictor = GoalPredictor(args.map_size).to(device)
optimizer = AdamW(goal_predictor.parameters(), args.learning_rate)
if args.checkpoint:
start_epoch, goal_predictor, optimizer = _load_checkpoint(goal_predictor, optimizer, args)
#是否在训练前评估
if args.eval_at_start:
_eval_predictor_and_log_metrics(goal_predictor, val_seen_episodes, val_unseen_episodes, args, device)
#这里的episodes_batch表示一个小episopdes的全部数据
episodes_batch: list[Episode]
for epoch in trange(start_epoch, args.epochs, desc='epochs', unit='epoch', colour='#448844'):
for episodes_batch in tqdm(train_dataloader, desc='train episodes', unit='batch', colour='#88dd88'):
maps, rgbs, normalized_depths = prepare_inputs(episodes_batch, args, device)
normalized_goal_xys, progresses = prepare_labels(episodes_batch, args, device)
pred_normalized_goal_xys, pred_progresses = goal_predictor(maps, rgbs, normalized_depths, flip_depth=True)
goal_prediction_loss = F.mse_loss(pred_normalized_goal_xys, normalized_goal_xys)
progress_loss = F.mse_loss(pred_progresses, progresses)
loss = goal_prediction_loss + progress_loss
loss.backward()
logger.log({
'loss': loss.item(),
'goal_prediction_loss': goal_prediction_loss.item(),
'progress_loss': progress_loss.item()
})
optimizer.step()
optimizer.zero_grad()
logger.log({'epoch': epoch})
if (epoch + 1) % args.save_every == 0:
_save_checkpoint(epoch, goal_predictor, optimizer, args)
if (epoch + 1) % args.eval_every == 0:
_eval_predictor_and_log_metrics(goal_predictor, val_seen_episodes, val_unseen_episodes, args, device)
#将原始坐标归一化到地图的相对坐标系(范围 [0, 1])
def normalize_position(pos: Point2D, map_name: str, map_meters: float):
return (pos.x - MAP_BOUNDS[map_name].x_min) / map_meters, (MAP_BOUNDS[map_name].y_max - pos.y) / map_meters
def prepare_inputs(episodes_batch: list[Episode], args: ExperimentArgs, device: str):
#生成的maps的形状为(episodes_batch * len(trajectory), 5, 240, 240)
#generate_maps_for_an_episode的输出形状为(len(trajectory), 5, 240, 240),np.concatenate()默认沿第一个维度连接
maps = np.concatenate([
LandmarkNavMap.generate_maps_for_an_episode(
episode, args.map_shape, args.map_pixels_per_meter, args.map_update_interval, args.gsam_rgb_shape, args.gsam_params, args.gsam_use_map_cache
)
for episode in episodes_batch
])
#生成的rgbs的形状为(episodes_batch * len(trajectory), 3, 224, 224)
#crop_image的输出形状为(224, 224, 3),np.stack()沿新轴堆叠,新增一个维度
rgbs = np.stack([
cropclient.crop_image(episode.map_name, pose, (224, 224), 'rgb')
for episode in episodes_batch
for pose in episode.sample_trajectory(args.map_update_interval)
]).transpose(0, 3, 1, 2)
#生成的normalized_depths的形状为(episodes_batch * len(trajectory), 1, 256, 256)
normalized_depths = np.stack([
cropclient.crop_image(episode.map_name, pose, (256, 256), 'depth')
for episode in episodes_batch
for pose in episode.sample_trajectory(args.map_update_interval)
]).transpose(0, 3, 1, 2) / args.max_depth
if args.ablate == 'rgb':
rgbs = np.zeros_like(rgbs)
if args.ablate == 'depth':
normalized_depths = np.zeros_like(normalized_depths)
if args.ablate == 'tracking':
maps[:, :2] = 0
if args.ablate == 'landmark':
maps[:, 2] = 0
if args.ablate == 'gsam':
maps[:, 3:] = 0
maps = torch.tensor(maps, device=device)
rgbs = torch.tensor(rgbs, device=device)
normalized_depths = torch.tensor(normalized_depths, device=device, dtype=torch.float32)
return maps, rgbs, normalized_depths
#生成两个列表然后分别转换为二维张量,形状为(episodes_batch * len(trajectory), 2或1)
def prepare_labels(episodes_batch: list[Episode], args: ExperimentArgs, device: str):
#生成归一化的目标位置坐标
#最终得到一个列表 normalized_goal_xys,每个元素是目标位置的归一化坐标 (x, y),且每个采样点重复使用同一目标位置
#维度为(episodes_batch * len(trajectory), 2)
normalized_goal_xys = [
normalize_position(episode.target_position, episode.map_name, args.map_meters)
for episode in episodes_batch
for _ in episode.sample_trajectory(args.map_update_interval)
]
#生成归一化的导航进度
#维度为(episodes_batch * len(trajectory), 1)
progresses = [
np.clip(1 - episode.target_position.xy.dist_to(pose.xy) / episode.target_position.xy.dist_to(episode.start_pose.xy), 0, 1)
for episode in episodes_batch
for pose in episode.sample_trajectory(args.map_update_interval)
]
normalized_goal_xys = torch.tensor(normalized_goal_xys, device=device, dtype=torch.float32)
progresses = torch.tensor(progresses, device=device, dtype=torch.float32).reshape(-1, 1)
return normalized_goal_xys, progresses
def _load_train_episodes(objects: MultiMapObjects, args: ExperimentArgs) -> list[Episode]:
#通过load_mturk_trajectories下载全部轨迹,再通过generate_episodes_from_mturk_trajectories形成episodes
mturk_episodes = generate_episodes_from_mturk_trajectories(objects, load_mturk_trajectories('train_seen', 'all', args.altitude))
if args.train_trajectory_type == 'mturk':
return mturk_episodes
if args.train_trajectory_type == 'sp':
return [convert_trajectory_to_shortest_path(eps, 'linear_xy') for eps in tqdm(mturk_episodes, desc='converting to shortest path episode')]
if args.train_trajectory_type == 'both':
return mturk_episodes + [convert_trajectory_to_shortest_path(eps, 'linear_xy') for eps in tqdm(mturk_episodes, desc='converting to shortest path episode')]
def _eval_predictor_and_log_metrics(
goal_predictor: GoalPredictor,
val_seen_episodes: list[Episode],
val_unseen_episodes: list[Episode],
args: ExperimentArgs,
device: str,
):
#通过“字典推导式”隐式循环遍历指标字典的键值对,动态生成新键名(添加前缀)
#其中.items()用于获取字典的键值对集合
val_seen_metrics = eval_goal_predictor(args, val_seen_episodes, *run_episodes_batch(args, goal_predictor, val_seen_episodes, device))
val_unseen_metrics = eval_goal_predictor(args, val_unseen_episodes, *run_episodes_batch(args, goal_predictor, val_unseen_episodes, device))
logger.log({'val_seen_' + k: v for k, v in val_seen_metrics.to_dict().items()})
logger.log({'val_unseen_' + k: v for k, v in val_unseen_metrics.to_dict().items()})
def _load_checkpoint(
goal_predictor: GoalPredictor,
optimizer: torch.optim.Optimizer,
args: ExperimentArgs,
):
checkpoint = torch.load(args.checkpoint)
start_epoch: int = checkpoint['epoch'] + 1
goal_predictor.load_state_dict(checkpoint['predictor_state_dict'])
optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
return start_epoch, goal_predictor, optimizer
def _save_checkpoint(
epoch: int,
goal_predictor: GoalPredictor,
optimizer: torch.optim.Optimizer,
args: ExperimentArgs,
):
ablation = f"-{args.ablate}" if args.ablate else ''
train_size = '' if args.train_episode_sample_size < 0 else f"_{args.train_episode_sample_size}"
checkpoint_dir = GOAL_PREDICTOR_CHECKPOINT_DIR/f"{args.train_trajectory_type}_{args.altitude}_{args.gsam_box_threshold}{ablation}{train_size}"
checkpoint_dir.mkdir(exist_ok=True, parents=True)
torch.save(
{
'epoch': epoch,
'predictor_state_dict': goal_predictor.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
},
checkpoint_dir/f"{epoch:03d}.pth"细节部分如下:
4.1.1 训练输入
训练的输入有三部分组成,形状均为(episodes_batch * len(trajectory), C, H, W),即遍历episodes_batch个轨迹上的所有(采样后的)位置点,也就是每个轨迹的每个位置点都有(C, H, W)的输入。这episodes_batch * len(trajectory)个数据同时输入网络进行训练(并行):
(1)maps:主要包括五个子图,均为(1, 240, 240)大小的栅格地图。需要注意的是,对于每个区域地图(例如"birmingham_block_8"),论文将他们以超参数pixels_per_meter划分为大小差不多也是(240, 240)的栅格地图,由此保证了两个栅格地图行列索引的统一性。
a)当前视角区域地图:利用无人机的位姿得到世界坐标系的地面视野区域的四个角点坐标,计算相对于特定地图(例如"birmingham_block_8")的相对坐标后得到对应地图的栅格地图的行列索引,然后在大小为(240, 240)的空白地图上,将四个角点行列索引连接起来形成的凸多边形,颜色填充为1。此地图为当前视角区域地图。
b)已探索区域地图:通过元素级最大值操作累积前一位姿的已探索区域地图和当前视角区域地图,得到当前位姿的已探索区域地图。
c)地标地图:根据episode.target_processed_description.landmarks,提取“文本指令”中的地标(可能不止一个)及其全部属性,然后选择轮廓属性contour坐标,将其转化为栅格地图的行列索引后,连接起来形成的凸多边形,颜色填充为1。对于地标不止一个的情况,通过叠加的操作,将地标依次叠加到填充好的(240, 240)栅格地图中。此地图为地标地图。
d)导航目的地地图:根据episode.target_processed_description.target,从地图缓存map_cache中提取出“文本指令”中target的缓存栅格地图,然后利用无人机位姿得到的当前视角区域地图生成视野掩膜,与缓存的栅格地图匹配,得到当前位姿能看得到的target区域。通过元素级最大值操作累积前一位姿的target地图和当前位姿看得到的target区域地图,得到当前位姿的target地图。此地图为导航目的地地图。
e)导航背景地图:根据episode.target_processed_description.surroundings,从地图缓存map_cache中提取出“文本指令”中surroundings的缓存栅格地图(可能不止一个),然后利用无人机位姿得到的当前视角区域地图生成视野掩膜,与缓存的栅格地图匹配,得到当前位姿能看得到的surroundings区域。通过元素级最大值操作累积前一位姿的surroundings地图和当前位姿看得到的surroundings区域,得到当前位姿的surroundings地图。对于背景不止一个的情况,在当前位姿下,将每个保存在缓存中的特定surroundings的map_cache与当前已保存的gsam_map进行比较,取最大值(间接叠加)。此地图为导航背景地图。
(2)rgbs:得到无人机当前位姿在RGB图像(一张地图(例如"birmingham_block_8")对应一张RGB图像)中的行列索引,然后将行列索引构成的图像透视变换成大小为(224, 224)的图像;
(3)depth:得到无人机当前位姿在depth图像(一张地图(例如"birmingham_block_8")对应一张depth图像)中的行列索引,然后将行列索引构成的图像透视变换成大小为(256, 256)的图像。
def prepare_inputs(episodes_batch: list[Episode], args: ExperimentArgs, device: str):
#生成的maps的形状为(episodes_batch * len(trajectory), 5, 240, 240)
#generate_maps_for_an_episode的输出形状为(len(trajectory), 5, 240, 240),np.concatenate()默认沿第一个维度连接
maps = np.concatenate([
LandmarkNavMap.generate_maps_for_an_episode(
episode, args.map_shape, args.map_pixels_per_meter, args.map_update_interval, args.gsam_rgb_shape, args.gsam_params, args.gsam_use_map_cache
)
for episode in episodes_batch
])
#生成的rgbs的形状为(episodes_batch * len(trajectory), 3, 224, 224)
#crop_image的输出形状为(224, 224, 3),np.stack()沿新轴堆叠,新增一个维度
rgbs = np.stack([
cropclient.crop_image(episode.map_name, pose, (224, 224), 'rgb')
for episode in episodes_batch
for pose in episode.sample_trajectory(args.map_update_interval)
]).transpose(0, 3, 1, 2)
#生成的normalized_depths的形状为(episodes_batch * len(trajectory), 1, 256, 256)
normalized_depths = np.stack([
cropclient.crop_image(episode.map_name, pose, (256, 256), 'depth')
for episode in episodes_batch
for pose in episode.sample_trajectory(args.map_update_interval)
]).transpose(0, 3, 1, 2) / args.max_depth
if args.ablate == 'rgb':
rgbs = np.zeros_like(rgbs)
if args.ablate == 'depth':
normalized_depths = np.zeros_like(normalized_depths)
if args.ablate == 'tracking':
maps[:, :2] = 0
if args.ablate == 'landmark':
maps[:, 2] = 0
if args.ablate == 'gsam':
maps[:, 3:] = 0
maps = torch.tensor(maps, device=device)
rgbs = torch.tensor(rgbs, device=device)
normalized_depths = torch.tensor(normalized_depths, device=device, dtype=torch.float32)
return maps, rgbs, normalized_depths4.1.2 训练标签
生成两个列表然后分别转换为二维张量,形状为(episodes_batch * len(trajectory), 2或1)
def prepare_labels(episodes_batch: list[Episode], args: ExperimentArgs, device: str):
#生成归一化的目标位置坐标
#最终得到一个列表 normalized_goal_xys,每个元素是目标位置的归一化坐标 (x, y),且每个采样点重复使用同一目标位置
#维度为(episodes_batch * len(trajectory), 2)
normalized_goal_xys = [
normalize_position(episode.target_position, episode.map_name, args.map_meters)
for episode in episodes_batch
for _ in episode.sample_trajectory(args.map_update_interval)
]
#生成归一化的导航进度
#维度为(episodes_batch * len(trajectory), 1)
progresses = [
np.clip(1 - episode.target_position.xy.dist_to(pose.xy) / episode.target_position.xy.dist_to(episode.start_pose.xy), 0, 1)
for episode in episodes_batch
for pose in episode.sample_trajectory(args.map_update_interval)
]
normalized_goal_xys = torch.tensor(normalized_goal_xys, device=device, dtype=torch.float32)
progresses = torch.tensor(progresses, device=device, dtype=torch.float32).reshape(-1, 1)
return normalized_goal_xys, progresses4.1.3 训练模型
主要有两部分组成:
(1)目标预测器:输入maps特征,输出是归一化的预测坐标 (x, y) ∈ [0,1]。主要由Linear + ReLU + Linear + ReLU + Linear + Sigmoid构成。
(2)进度预测器:输入是maps特征,rgb特征和depth特征,输出是归一化的预测进度progress ∈ [0,1]。主要由Linear + ReLU + Linear + ReLU + Linear + Sigmoid构成。
模型的代码如下:
class GoalPredictor(nn.Module):
def __init__(self, map_size: int):
super(GoalPredictor, self).__init__()
#将(episodes_batch * len(trajectory), 5, 240, 240)编码成(episodes_batch * len(trajectory), 7200)
self.map_encoder = MapEncoder(map_size)
#将(episodes_batch * len(trajectory), 3, 224, 224)编码成(episodes_batch * len(trajectory), 256)
self.rgb_encoder = TorchVisionResNet50().eval()
#将(episodes_batch * len(trajectory), 1, 256, 256)编码成(eepisodes_batch * len(trajectory), 128)
self.depth_encoder = ResnetDepthEncoder().eval()
#(episodes_batch * len(trajectory), 7200)经过GoalPredictionHead后,得到(episodes_batch * len(trajectory), 2),即每个“采样后的轨迹点”的归一化的预测目标坐标 (x, y) ∈ [0,1]
self.goal_prediction_head = GoalPredictionHead(self.map_encoder.out_features)
#(episodes_batch * len(trajectory), 7584)经过ProgressPredictionHead后,得到(episodes_batch * len(trajectory), 1),即每个“采样后的轨迹点”的归一化的预测进度值 progress ∈ [0,1]
self.progress_prediction_head = ProgressPredictionHead(
self.map_encoder.out_features, self.rgb_encoder.out_features, self.depth_encoder.out_features
)
#调用模型实例默认会执行forward方法
def forward(self, maps: Tensor, rgbs: Tensor, depths: Tensor, flip_depth=True):
"""rgb & depth (B, C, H, W)"""
if flip_depth:
depths = depths.flip(-2) # flip vertically
map_features = self.map_encoder(maps)
rgb_features = self.rgb_encoder(rgbs)
depth_features = self.depth_encoder(depths)
pred_normalized_goal_xys = self.goal_prediction_head(map_features)
pred_progress = self.progress_prediction_head(map_features, rgb_features, depth_features)
return pred_normalized_goal_xys, pred_progress4.2 评估
评估环节的代码如下所示:
if args.mode == 'eval':
model_trajectory = args.checkpoint.split('/')[-2]
epoch = args.checkpoint.split('/')[-1].split('.')[0]
objects = get_city_refer_objects()
# load predictor
model : GoalPredictor | CMAwithMap | Seq2SeqwithMap = Model(args.map_size).to(DEVICE) #选取模型
if args.checkpoint:
model.load_state_dict(torch.load(args.checkpoint)['predictor_state_dict']) #加载checkpoint文件中的预测器权重到当前模型
for split in ('val_seen', 'val_unseen', 'test_unseen'):
"""
得到的episodes的数据格式:
Episode
├─ target_object: CityReferObject(...)
│ ├─ map_name: "birmingham_block_1"
│ ├─ id: 11
│ ├─ name: ""
│ ├─ object_type: ""
│ ├─ position: (x, y, z)
│ ├─ dimension: (l, h, w)
│ ├─ descriptions: List[ProcessedDescription],有好几条描述
│ └─ processed_descriptions: ""
│ ├─ target: string, 与descriptions的数量对应
│ ├─ landmarks: List[string], descriptions的数量对应
│ └─ surroundings: List[string], 与descriptions的数量对应
├─ description_id: 1 (或者2, 3,..., 最大数与descriptions的数量对应 )
├─ teacher_trajectory: [Pose4D(...), ...]
└─ teacher_actions: [2, 2, 1, 1, 1, ..., 0]
"""
#将原始的轨迹转化为可执行的轨迹,即teacher_trajectory
test_episodes = generate_episodes_from_mturk_trajectories(objects, load_mturk_trajectories(split, 'all', args.altitude))
"""
print(test_episodes[0].__dict__)
print(test_episodes[1].__dict__)
print(test_episodes[2].__dict__)
"""
# 新增代码:构建 teacher_trajectory_logs
teacher_trajectory_logs = {
f"{episode.target_object.map_name}_{episode.target_object.id}_{episode.description_id}": [
tuple(pose) for pose in episode.teacher_trajectory
]
for episode in test_episodes
}
trajectory_logs, pred_goal_logs, pred_progress_logs = run_episodes_batch(args, model, test_episodes, DEVICE) #这里输出的trajectory_logs是什么形状?是dict[EpisodeID, list[Pose4D]]?
predicted_positions = (goal_selection_gdino if args.eval_goal_selector == 'gdino' else goal_selection_llava)(args, pred_goal_logs)
for eps_id, pose in predicted_positions.items():
trajectory_logs[eps_id].append(pose) #这里的trajectory_logs又是什么形状?
metrics = eval_goal_predictor(args, test_episodes, trajectory_logs, pred_goal_logs, pred_progress_logs)
print(f"{split} -- {metrics.mean_final_pos_to_goal_dist: .1f}, {metrics.success_rate_final_pos_to_goal*100: .2f}, {metrics.success_rate_oracle_pos_to_goal*100: .2f}, {metrics.mean_spl*100: .2f}")
noise = f"noise_{args.gps_noise_scale}" if args.gps_noise_scale > 0 else ""
alt_env = f"_{args.alt_env}" if args.alt_env else ""
with open(f'{args.model}_{model_trajectory}_{split}_{args.progress_stop_val}{noise}{alt_env}_{args.eval_goal_selector}.json', 'w') as f:
json.dump({
'metrics': metrics.to_dict(),
'trajectory_logs': {str(eps_id): [tuple(pose) for pose in trajectory] for eps_id, trajectory in trajectory_logs.items()},
'pred_goal_logs': {str(eps_id): [tuple(pos) for pos in pred_goals] for eps_id, pred_goals in pred_goal_logs.items()},
'pred_progress_logs': {str(eps_id): pred_progresses for eps_id, pred_progresses in pred_progress_logs.items()},
'teacher_trajectory_logs': { # 新增字段
str(eps_id): [tuple(pose) for pose in trajectory]
for eps_id, trajectory in teacher_trajectory_logs.items()
}
}, f)@torch.no_grad()
def run_episodes_batch(
args: ExperimentArgs,
predictor: GoalPredictor,
episodes: list[Episode],
device: str,
):
cropclient.load_image_cache(alt_env=args.alt_env) #下载地图缓存
#dataloader = DataLoader(episodes, args.eval_batch_size, shuffle=False, collate_fn=lambda x: x)
dataloader = DataLoader(episodes, args.eval_batch_size, shuffle=False, collate_fn=lambda x: x, num_workers=0) #将全部的eposides分成固定batch_size的小eposides
pose_logs: dict[EpisodeID, list[Pose4D]] = defaultdict(list) #记录位姿序列
pred_goal_logs: dict[EpisodeID, list[Point2D]] = defaultdict(list)
pred_progress_logs: dict[EpisodeID, list[float]] = defaultdict(list)
episodes_batch: list[Episode]
for episodes_batch in tqdm(dataloader, desc='eval episodes', unit='batch', colour='#88dd88', position=1): #这里的episodes_batch表示一个小episopdes的全部数据
batch_size = len(episodes_batch) #计算这个小episodes的长度
poses = [eps.start_pose for eps in episodes_batch] #取小episodes中的每一个epiosede的起始位姿,构成一个列表,这里的eps代表一个episode
dones = np.zeros(batch_size, dtype=bool)
#取小episodes中的每一个epiosede,生成每个episode对应的导航地图(五类),构成一个列表,这里的eps代表一个episode
nav_maps = [
LandmarkNavMap(
eps.map_name, args.map_shape, args.map_pixels_per_meter,
eps.description_landmarks, eps.description_target, eps.description_surroundings, args.gsam_params
) for eps in episodes_batch
]
#更新(走)了20次
for t in trange(args.eval_max_timestep, desc='eval timestep', unit='step', colour='#66aa66', position=2, leave=False):
gps_noise_batch = np.random.normal(scale=args.gps_noise_scale, size=(batch_size, 2))
noisy_poses = [Pose4D(x + n_x, y + n_y, z, yaw) for (x, y, z, yaw), (n_x, n_y) in zip(poses, gps_noise_batch)] #将一个小episodes中的个每一个episode的x,y两个维度添加噪声
# update map
#通过zip将五个可索引对象按索引对齐,逐个提取对应位置的元素
#在每一个时间步t循环batch_size次,更新episodes_batch全部批量(即更新每一个episode)的gsam_rgb、nav_map和pose_logs
for eps, pose, noisy_pose, nav_map, done in tqdm(zip(episodes_batch, poses, noisy_poses, nav_maps, dones), desc='updating maps', unit='map', colour='#448844', position=3, leave=False):
if not done: #导航完成的标记。如果还没有完成:
gsam_rgb = cropclient.crop_image(eps.map_name, pose, args.gsam_rgb_shape, 'rgb')
nav_map.update_observations(noisy_pose, gsam_rgb, None, args.gsam_use_map_cache)
pose_logs[eps.id].append(pose) #记录位姿
# prepare inputs
#调用每个nav_map的to_array()方法,将地图转为数值数组,再堆叠成一个batch
maps = np.stack([nav_map.to_array() for nav_map in nav_maps])
#从地图中按当前位姿截取尺寸为224×224的RGB图像;transpose(0, 3, 1, 2)用于调整张量维度以符合模型输入格式(通常为批次、通道、高、宽)
rgbs = np.stack([cropclient.crop_image(eps.map_name, pose, (224, 224), 'rgb') for eps, pose in zip(episodes_batch, poses)]).transpose(0, 3, 1, 2)
#截取尺寸为256×256的深度图像,并归一化(除以args.max_depth)
normalized_depths = np.stack([cropclient.crop_image(eps.map_name, pose, (256, 256), 'depth') for eps, pose in zip(episodes_batch, poses)]).transpose(0, 3, 1, 2) / args.max_depth
if args.ablate == 'rgb':
rgbs = np.zeros_like(rgbs)
if args.ablate == 'depth':
normalized_depths = np.zeros_like(normalized_depths)
if args.ablate == 'tracking':
maps[:, :2] = 0
if args.ablate == 'landmark':
maps[:, 2] = 0
if args.ablate == 'gsam':
maps[:, 3:] = 0
#转换为张量
maps = torch.tensor(maps, device=device)
rgbs = torch.tensor(rgbs, device=device)
normalized_depths = torch.tensor(normalized_depths, device=device, dtype=torch.float32)
# predict
#得到的pred_normalized_goal_xys维度:(episodes_batch, 2)
#得到的pred_progresses维度:(episodes_batch, 1)
pred_normalized_goal_xys, pred_progresses = predictor(maps, rgbs, normalized_depths, flip_depth=True)
#将归一化的坐标转化为实际坐标,得到的pred_goal_xys的格式为[(,), (,),...]
pred_goal_xys = [unnormalize_position(xy.tolist(), eps.map_name, args.map_meters) for eps, xy in zip(episodes_batch, pred_normalized_goal_xys)]
#记录预测目标和进度日志
for eps, done, xy, progress in zip(episodes_batch, dones, pred_goal_xys, pred_progresses.flatten().tolist()):
if not done:
pred_goal_logs[eps.id].append(xy)
pred_progress_logs[eps.id].append(progress)
#判断是否完成导航
dones = dones | (pred_progresses.cpu().numpy().flatten() >= args.progress_stop_val)
if dones.all():
break
# move
#利用生成的预测点,生成一系列可执行的动作和航路点
#如果 done 为 False,则执行 move ,否则不做更新,直接保留当前的 pose
poses = [
move(pose, xy, args.move_iteration, noisy_pose) if not done else pose
for pose, noisy_pose, xy, done in zip(poses, noisy_poses, pred_goal_xys, dones)
]
return dict(pose_logs), dict(pred_goal_logs), dict(pred_progress_logs)4.2.1 评估输入
评估的输入有三部分组成,形状均为(episodes_batch, C, H, W)。与训练将轨迹的所有位姿点同时输入模型不同,评估是一个逐时间步(逐位姿)的过程。
(1)maps:主要包括五个子图,均为(1, 240, 240)大小的栅格地图。需要注意的是,每个map均只有已走过的位姿和当前位姿的信息,是一个随着时间步 t 累加的过程;
(2)rgbs:当前位姿的RGB图像;
(3)depth:当前位姿的depth图像。
4.2.2 评估模型
与训练模型大体相同,细微不同之处如下:
(1)输入的批次有所改变,训练是episodes_batch * len(trajectory),评估是episodes_batch;
(2)训练一次性预测episodes_batch * len(trajectory)个归一化的坐标,而评估一次性预测episodes_batch个归一化的坐标;
(3)训练没有用到路径规划模块,而评估通过使用路径规划模块,将预测的坐标转换为可执行的动作,然后执行动作,到达新的位姿。
五、总结
(1)可选的坐标细化究竟是怎么工作的?
(2)能不能在某处添加一个注意力模块,从而改进性能?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









